

1 背景
1.1 什么是用户偏好挖掘
用户偏好,即对用户内在需求的具体刻画。通过用户的历史行为和数据,对用户进行多角度全方位的刻画与描述,利用统计分析或算法,来挖掘出用户潜在的需求倾向。
用户在平台有多种多样的行为,用户的行为都是有内在的驱动因素的,而挖掘用户偏好可以帮助我们从杂乱的信息中抽象出对用户需求的具体描述,从而指导搜索、推荐、push 等策略的制定,圈定用户群,进行精准营销与精细化运营。
1.2 偏好挖掘工作面临的挑战
准确表达:用户偏好挖掘工作对准确的要求是天然存在的,有两点需要考虑:首先,用户偏好的准确应当如何度量,决定了我们以何为目标;其次,用户的偏好可能存在多峰的情况,因此在挖掘任务中需要对多峰的特性做出准确反映。
可理解:本质上我们希望对用户的偏好信息进行编码和传递,基于贝壳的业态,下游不止有规则与算法,还有运营与经纪人等‘人’,这对偏好挖掘输出的可理解提出了要求。
高维的偏好:在偏好挖掘工作中,另一个重点是,存在部分高维非序数偏好,比如房产场景下的地理位置属性。如何有效的对高维偏好进行挖掘,是我们要面临的第三个问题。
2 常见的偏好挖掘思路
偏好的挖掘是通过用户的历史行为来判断一个用户在各种属性的不同维度上的偏好程度,进而挖掘出用户的潜在需求。比如,在贝壳的场景下,衡量一个用户偏好 200 万还是偏好 300 万、喜欢二居室还是三居室。常见的偏好挖掘的方法可以分为统计和模型两类。
2.1 基于统计的偏好挖掘
通过统计的方法挖掘用户偏好的思想是基于一定的业务假设的,即用户行为越多则偏好越重、距当前时间越近越偏好。
技术方案:
用户偏好通过用户在不同属性的维度上行为次数的带衰减的线性加权求和,再进行归一化得到。
这里有两个关键点:
第一个关键点是:不同行为的权重如何衡量
用户有着多种不同的行为,例如,在购物网站,用户可能发生浏览、收藏、加购物车、下单等行为,显然,下单的成本要比普通的浏览成本要高,即在不同行为上花费的成本是存在差异的,在数据上的反映是不同行为的权重差异很大,如何定义、衡量并验证不同行为的权重是一件并不容易的事情。
我们采用的权重计算方法有:
后验转化率的方法,转化率的倒数作为权重;
有监督的方法,bagging+LR 模型,可以将成交或者下单作为 label,模型得到的特征重要性作为权重;
通过贝叶斯模型计算权重。
第二个关键点是:衰减系数的定义
用户的需求并不是持续稳定的,会随时间会发生变化和转移,这种需求的变化需要被偏好捕捉到,因此,距离当前越近的行为越能反映现在的需求。对于衰减形式,我们采取了指数衰减以及阶跃形式衰减。
指数形式
用户行为对未来偏好的影响程度,随着时间的拉长呈指数型下降,对于 t 天前的行为,衰减因子为λ的 t 次方;
阶跃形式
将时间人为划分成若干不同的时间区间,同一个时间区间内的行为的衰减因子是相同的。
因此,增加了衰减系数和行为权重的偏好计算公式为:
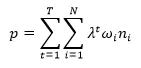
挑战:
很难证明什么样的行为权重是最优的,且很难找到优化方向;
人为选定的衰减方式以及衰减因子的选取具有主观因素,并不适用于所有的偏好;
基于统计的偏好挖掘难以优化。
2.2 基于模型的偏好计算
基于统计的偏好计算方法的优点是直观,可解释性强,但缺点是难以优化,因此我们考虑通过有监督模型的方式解决偏好预估的优化问题。
技术方案:
对于低维且等长的偏好,可以通过有监督的多分类模型。利用用户过去发生不同行为所对应的属性,预测未来在不同属性上发生重行为的概率。需要解决的问题主要是历史行为的时间窗口的划分,这类低维、行为相对稠密、长度统一的偏好,可以采用有监督模型 XGBoost、DNN,以及时序模型 LSTM 和 GRU 等。
然而,对于枚举值较多的属性的用户偏好,例如地理位置相关的属性,用户在不同枚举值上的行为稀疏,且用户过去行为覆盖的位置 Item 数目不同,导致召回的候选集长度不统一,因此使用传统意义上的多分类模型很难去完成。
对于这类偏好,常见的方法是 embedding,通过用户近期交互过的物品,将偏好预估视为 top-n 推荐,使用 pair-wise 训练策略训练模型,得到个性化的用户偏好向量。
虽然用 embedding 表征用户偏好在推荐系统中取的了很好的效果,然而这种向量化的偏好表征方法不可解释,在需要人去理解不同偏好意义的场景中具有局限性。
挑战:
高维、稀疏的偏好,很难预估;
输出需要是可解释的。
3 偏好挖掘在贝壳找房的实践
贝壳找房作为一个居住服务类的平台,将用户、经纪人和房源链接在一起,帮助用户找到更满意的居住环境,帮助经纪人更好地服务用户,对用户的偏好进行挖掘可以帮助平台更好的了解用户。
偏好挖掘在贝壳找房主要有两类的应用场景,一方面是对业务赋能,有助于平台算法和策略的制定,如个性化推荐、定向 push 等场景;另一方面是给人传达可理解的用户需求,比如帮助运营人员圈人群包,进行精细化运营和定向推送,或者在用户从线上转线下的过程中,将用户的需求无损地传递给经纪人,更快地了解用户。
3.1 基于多分类的偏好挖掘
3.1.1 问题抽象
问题定义 :
在用户信息交互中,如果用户对某一属性的 Item 付出了较大成本,则说明用户对 Item 背后的属性有较强的偏好,基于此假设,在已知用户过去发生不同行为及行为对应的属性维度,将偏好预估问题定义为预测未来时间段内发生重行为所对应的属性维度。
样本构造 :
我们需要思考偏好的主要应用场景,以及环境对动作的解释能力。如果我们对线上行为的采集能力明显高于线下环节,那么我们在思考“重行为”时,就要考虑如果使用大量生命周期末端的线下行为,基于线上的特征是否可以很好的解释。
优化目标 :
模型的目标为预估用户在不同属性的 Item 上发生重行为的概率。这里我们要考虑用户的偏好是 multi-hot 还是 one-hot,基于这两种形式,我们需要考虑对输出层的构造方法。但需要强调的是,使用 one-hot 并不意味着否定用户多峰偏好的事实。
离线后验 :
这是一个被高频提问的点,即偏好的质量如何评估,自然我们可以从下游应用的角度进行评估,但该评估方式存在实验难、效果回收慢、影响因素多等诸多不便。
从中台角度我们更希望建立中间指标实现对偏好质量的独立可衡量,建立小闭环。我们通过预估向量与真实行为向量的内积或交叉熵来衡量预估的效果,内积越大、交叉熵越小,则预估越准确。
如何选择适合自己的指标建议从下游应用出发,例如下游使用内积的方式进行排序操作,那么内积可能更为合适。但使用内积的方式进行评价可能存在与模型的优化方向不一致的问题,需要在模型评价时考虑进来。
3.1.2 树模型、DNN 模型
思想 :
通过用户的行为,构建一个有监督的分类模型,预估用户的各维度的偏好。
特征工程 :
特征工程的原问题是什么可以反应用户的偏好,需要考虑两个层面,一是,基于用户历史与属性 Item 交互反应用户愿为什么属性付出成本;二是考虑用户当前的业务进程,反应了用户的偏好是否在未来发生发幅度的迁移和改变,即用户的偏好预估多大程度上依托历史交互行为。基于这两点思考,我们将两类信息编码进特征中:
用户历史与不同 Item 交互,例如,用户在某个属性上访问次数、频率、转化率等;
用户的生命周期,例如,用户当前各类行为的带衰减线性加权,或用户最重行为的 one-hot 都可以表达用户的生命周期。
优化点 :
特征工程实际上是对用户个体与用户历史交互序列进行了编码,编码的过程中引入了较多的人工先验知识,例如人为划分行为聚合时间的长度。
3.1.3 在模型中引入用户行为序列
思想 :
用户偏好是个复杂且不稳定的问题,当前偏好与过去的不同阶段的行为量及偏好有关系,而传统的神经网络很难去捕捉不同时间对当前阶段的偏好的影响,因此我们把将偏好预估问题抽象为一个多变量时间序列预测的问题,将用户行为按照时间划分成不同周期,根据每个周期内的行为,预估下一周期用户发生重行为所在的属性维度。这样,模型可以感知到过去偏好的变化情况,通过时序模型学习到过去对未来偏好的影响。
LSTM 时序模型:
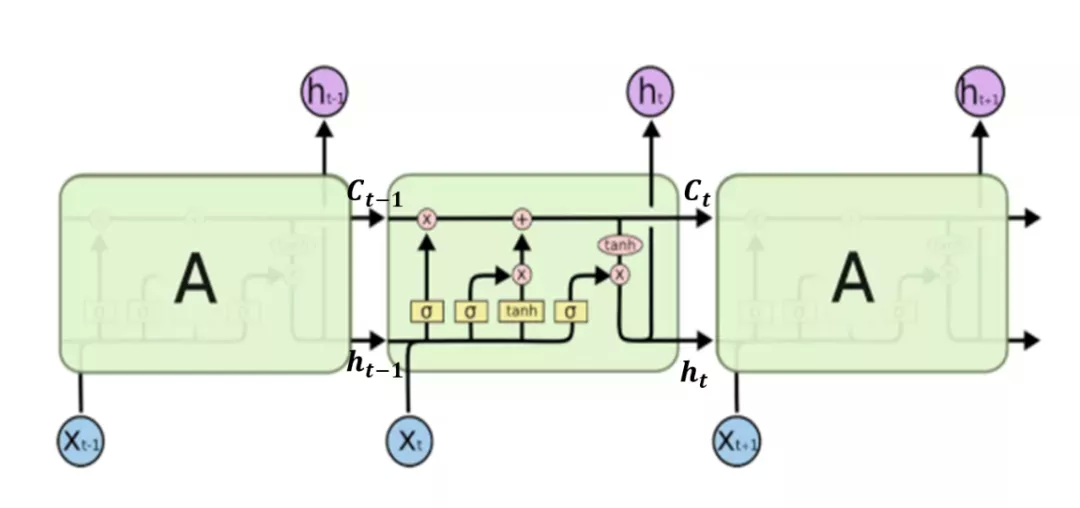
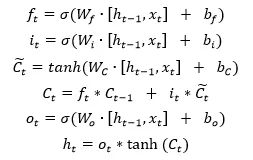
图 3.1 LSTM 结构及计算公式
LSTM 是一种特殊的循环神经网络,可以将过去的信息与当前的目标之间建立连接,例如,在空气质量预测中,用过去每个时间点的天气状况、气温、风速等特征,来帮助推测下一个时间点的空气质量。
LSTM 有两个传输状态,一个 cell state(C_t),一个 hidden state(h_t),其中 C_t 改变较为缓慢,作为贯穿整个 cell 的传送带,保存长期记忆,而 h_t 在每个 cell 内的区别相对较大。
LSTM 通过“门”来决定将哪些信息保留、哪些信息删除,forget gate 决定了上一时刻的单元状态 C_t-1 有多少保留到当前时刻 C_t;input gate 决定了当前时刻网络的输入 x_t 有多少保存到单元状态 C_t,output gate 控制单元状态 C_t 有多少输出到 LSTM 的当前输出值 h_t。其网络结构和前向计算公式如图 3.1 所示。
特征工程 :
划定周期,将一个周期内的行为次数与属性 Item、行为类别进行交叉聚合。周期的选择根据下游场景的需求和业务类型,选择不同长度的周期,对于用户需求相对稳定、下游场景不需要紧随用户当前实时偏好的场景中,可以选择周为周期粒度,反之,如果需要实时关注用户当前的偏好变化,可以以天为周期粒度。
优化点 :
在贝壳平台,由于城市对用户偏好的影响很大,所以我们加入城市作为特征,先将城市进行 embedding,再将 embedding 后的结果与 sequence 特征经过 LSTM 的结果进行拼接,进入全连接层。
技术路线:
获取用户每个周期内的行为次数与属性 Item、行为类别作交叉得到的序列特征,以及城市的编码结果或 one-hot 结果;
序列特征经过 LSTM,得到用户的历史行为表达;
城市特征经过 Embedding 层,得到的向量作为城市属性表达;
历史行为表达与城市属性表达进行拼接,经过全连接层输出概率向量。
整体的架构如下图:
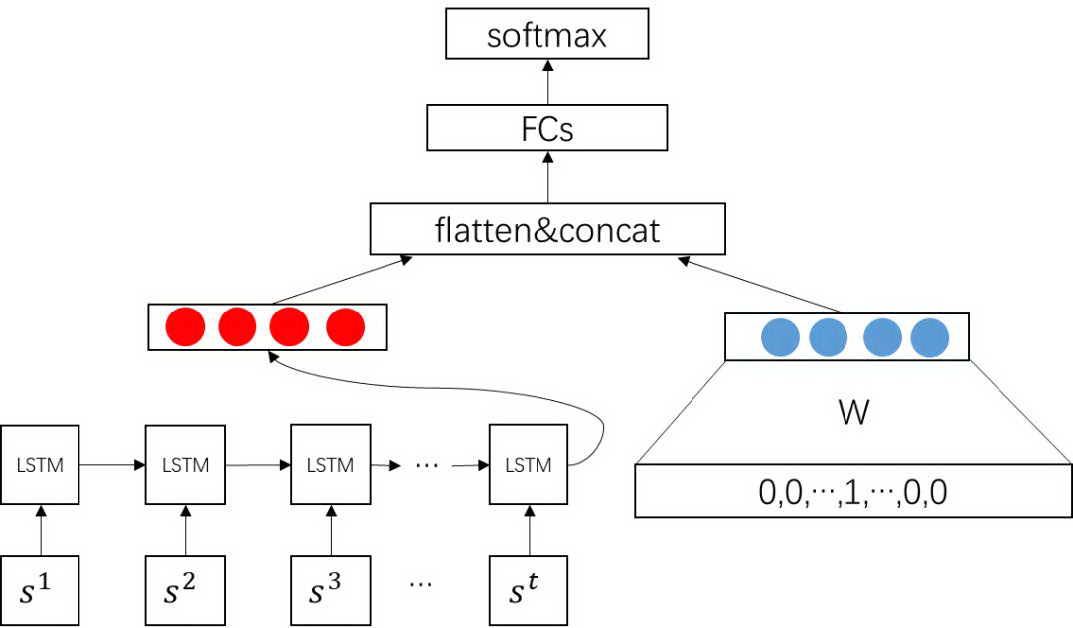
图 3.2 基于行为序列的偏好预估架构图
3.2 基于二分类的偏好挖掘
对于 Item 数目较多的属性,多分类的方法存在局限性,一是构造特征时,属性 Item 与行为进行交叉会导致特征维度爆炸;二是用户的行为稀疏,绝大部分 Item 上没有行为;三是当类别较多时多分类模型表现不够好。因此,为了在高维稀疏的偏好预估问题中取得更好的效果,我们对模型进行了进一步的优化,将多分类问题转化为二分类问题。
3.2.1 Seq4Rec 模型
思考 :
实际上,对于 Item 数量较多的属性,我们只需要关注用户对其访问过的 Item 的偏好情况,我们可将问题简化为预估用户对其访问过的属性的 Item 的偏好情况,这样大大缩减了问题的难度。但是每个用户访问过的 Item 不同、Item 数量不一,依然无法使用多分类模型。
那么,既然不能多分类,能否将多分类的问题转化为二分类呢?沿着这个思路,我们将多分类中的不同属性信息作为召回项加入到特征中,将后续是否在召回项上发生重行为作为目标。这样,序列特征作为用户表达,召回项特征作为 Item 表达,这种方法我们称其为 Seq4Rec。
特征工程 :
Seq4Rec 方法的用户序列特征不是基于时间的行为交叉聚合,而是用户的每次交互,序列特征包含序列类型的编码,以及行为所在的属性 Item 的编码,最后加上召回项 Item 的编码。特征构造的主要步骤如下:
首先,获取用户交互过的属性 Item 编码以及行为类型编码,构造基于行为的 sequence,作为用户的表达;
第二步,获取召回集,用户历史访问过的 Item 作为其召回集;
第三步,将召回集中的每个 Item 作为属性表达;
最后,属性表达与用户表达的 sequence 拼接到一起。
Item 的 Embedding :
在模型训练过程中,为了降低维度,并且更好地表达属性信息,需要对 sequence 中的 Item 以及召回的 Item 进行 embedding,将高维稀疏的离散特征转化为低维稠密的向量特征。为此将我们采取预训练的方式,先进行 embedding,再用得到的向量对 Item 进行替换。对 Item 进行 embedding 的技术路线为:
根据用户在每个 session 中浏览的房源的时间顺序,构建去重的属性 Item 的序列;
根据曝光次数,对 Item 编码成字典;
根据时间序列,生成样本;
skip-gram 模型得到属性的 Item 的 embedding 值。
模型架构 :
整体的架构流程图如下。首先将用户交互行为的 Item 编码替换成与训练的 embedding 向量,与行为类型编码共同形成用户行为 sequence,经过 LSTM,与召回项 Item 的 embedding 向量进行 concat,进入全连接层,最终输出 0 到 1 范围内的概率值。
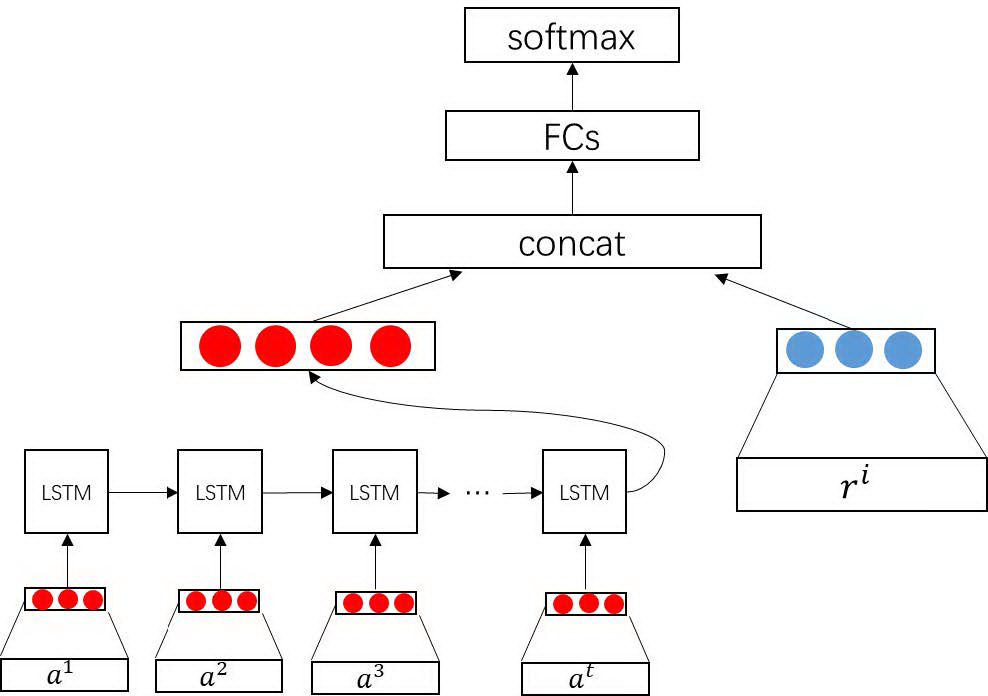
图 3.3 Seq4Rec 模型架构
3.2.2 优化用户侧表达
思考 :
在 LSTM 的方案中,我们将用户历史属性交互序列用于用户的编码,取得了一定的效果提升。接下来,我们进一步探索序列的更优表达形式。在前述版本中,用户的行为序列被压缩编码到了一个定长向量中参与后续计算,是否会成为瓶颈。其次对于一个属性枚举而言,用户行为序列是否等权重,等作用的影响特定属性。最后,在匹配逻辑上,历史访问序列与目标属性的关系,应当被如何表达与强调。我们尝试结合深度兴趣网络思路,对偏好挖掘任务进行优化。
对深度兴趣网络的借鉴 :
从思想上,深度兴趣网络框架提出在基于用户序列进行用户编码过程中考虑目标 Item,而不是对用户的多峰偏好进行等重表达。公式表达如下:
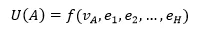
其中 U(A)为用户表达,e_1,e_2,…,e_H 为用户序列,v_A 为目标 Item。
从实践上,深度兴趣网络相比 BaseModel 增加了 Activation Unit,通过用户序列与目标 Item 的 element-wise minus 以及用户序列 Item 与目标 Item 成对输入 FCs 的方法,计算用户 Seq 中每个节点相对于目标 Item 的权重,内积用户 Seq 的 Embedding 从而实现目标影响用户编码的目的。
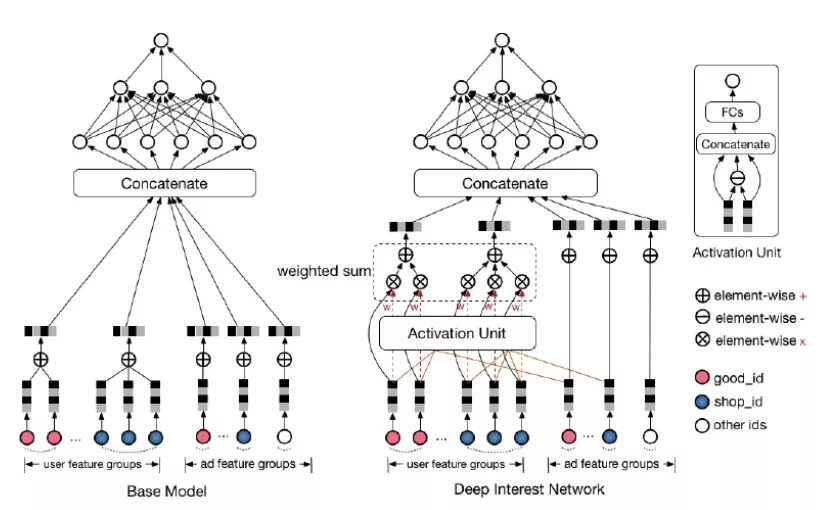
图 3.4 深度兴趣网络模型
用户偏好多峰的理解 :
在购房场景下,满足用户需求的方案存在多种,以北京为例,可以购买高价地段的中户型获得优质的配套资源,也可以购买远郊房产选择大空间接父母来居住,更可以以较低价格购买小户型、将剩余的钱留做他用。不同居住方案,产生了用户的复杂偏好,当用户浏览一个内环高单价中户型时,对用户的编码应当更加关注历史对相似高价地段方案产生的序列。而非关注其在京郊别墅方案中对容积率的要求。
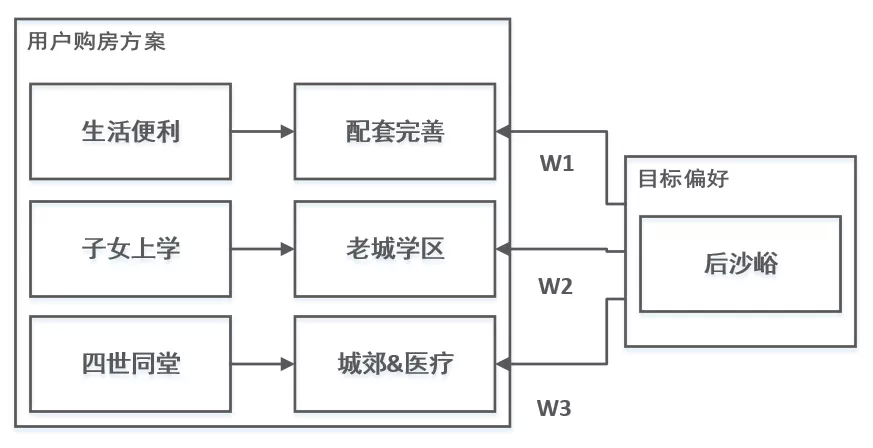
图 3.5 用户不同的购房方案
用户偏好序列构造 :
在偏好挖掘场景中,我们将其抽象为偏好推荐问题,因此用户的访问序列由用户访问房源的偏好组合构成,其中组合的概念我们可以理解为多通道。
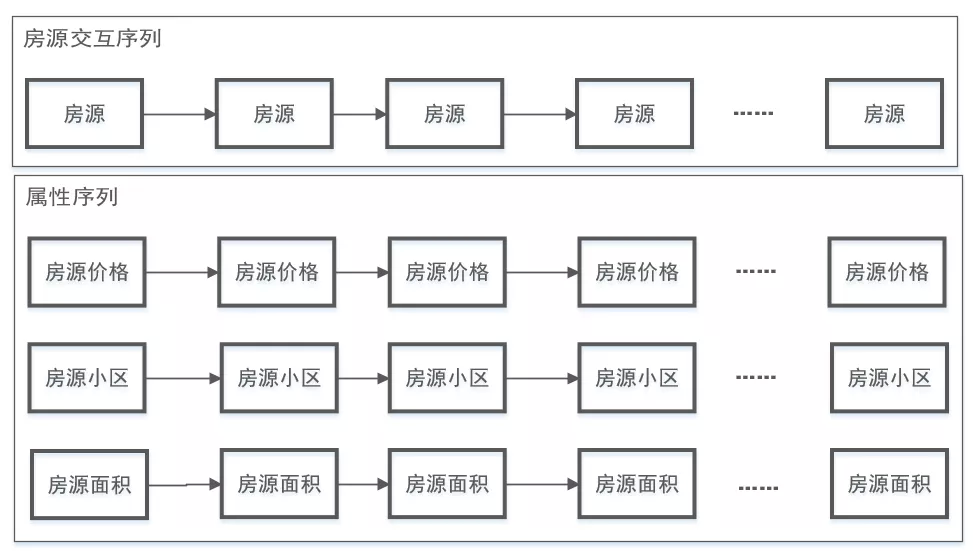
图 3.6 用户偏好序列
偏好挖掘网络结构 :
用户对房源的访问实际是与偏好的组合做了交互,这里我们假设,用户对小区属性的偏好会受到其包括价格、面积等多维度偏好的影响。从另一个层面看,目标属性对用户交互序列的多属性的信息提取都会产生影响,而非单独影响对应属性。因此注意力对用户 Seq 的房源属性组合生效,拼接后送入 FCs 中进行关系学习并输出。
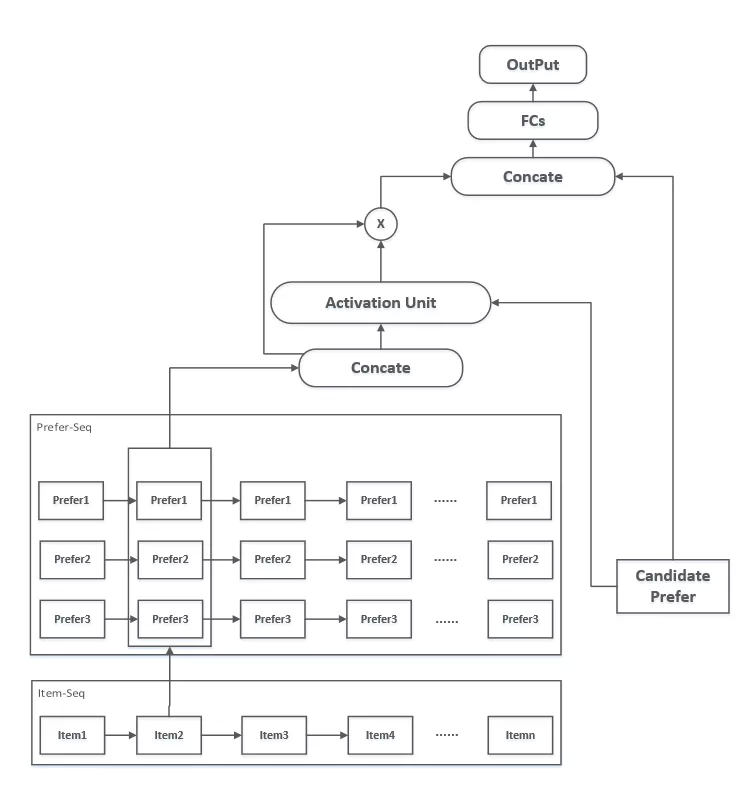
图 3.7 偏好挖掘网络结构图
Activation Unit 的设计 :
如何求取用户 Seq 中一个房源对应偏好组合的注意力权重,是 AU 模块要解决的问题,即目标偏好与用户 Seq 偏好组合的相关性,其核心的关系计算由 FCs 完成,FCs 的输入包含 Seq 对应房源的偏好组合的 Embedding 向量,目标属性的 embedding 向量,以及用户 Seq 房源各属性 Embedding 与目标属性 Embedding 向量的 Element Wise Minus。
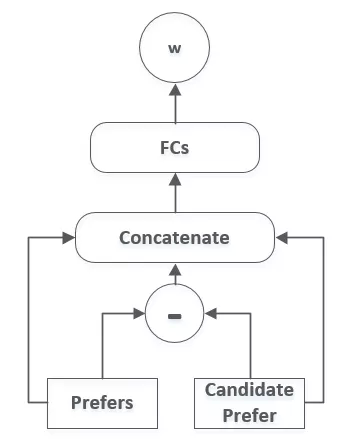
图 3.8 Active Unit 的结构
4 写在最后
本文介绍了偏好模型在贝壳的应用,包括 XGBoost/神经网络、时序模型。为了解决高维稀疏问题,将多分类转化为基于召回集的二分类问题,为了解决多峰偏好问题,采用深度兴趣网络,并引入基于偏好的 attention 机制。
通过几个版本的迭代,在后验内积和交叉熵上进行验证,提高了模型的性能。我们的模型还在不断尝试与优化中,有后续进展会持续更新。
5 引用资料
[1] Beyond User Embedding Matrix: Learning to Hash for Modeling Large-Scale Users in Recommendation
[2] Deep Interest Network for Click-Through Rate Prediction
[3] Real-time Personalization using Embeddings for Search Ranking at Airbnb
本文转载自公众号贝壳产品技术(ID:beikeTC)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论