

这次向大家分享的工作是阿里定向广告团队在 DLP-KDD 2020 发表的文章:COLD: Towards the Next Generation of Pre-Ranking System。COLD 是我们新一代粗排排序系统,目前已经在阿里定向广告各主要业务落地并取得了巨大的线上效果提升。
论文地址:https://arxiv.org/abs/2007.16122
01 粗排简介
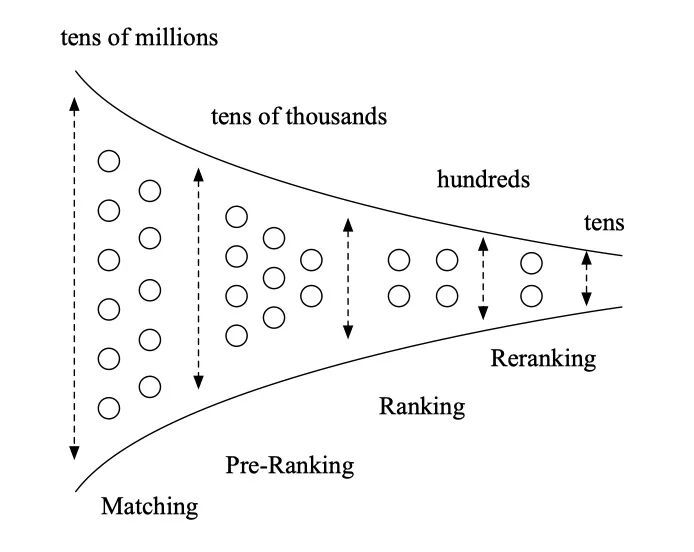
在搜索,推荐,广告等需要进行大规模排序的场景,级联排序架构得到了非常广泛的应用。以阿里的在线广告系统为例,按顺序一般包含召回,粗排,精排,重排序等模块。粗排在召回和精排之间,一般需要从上万个广告集合中选择出几百个符合后链路目标的候选广告,并送给后面的精排模块。粗排有很严格的时间要求,一般需要在 10~20ms 内完成打分。
02 发展历程
粗排在工业界的发展历程可以分成下面几个阶段:
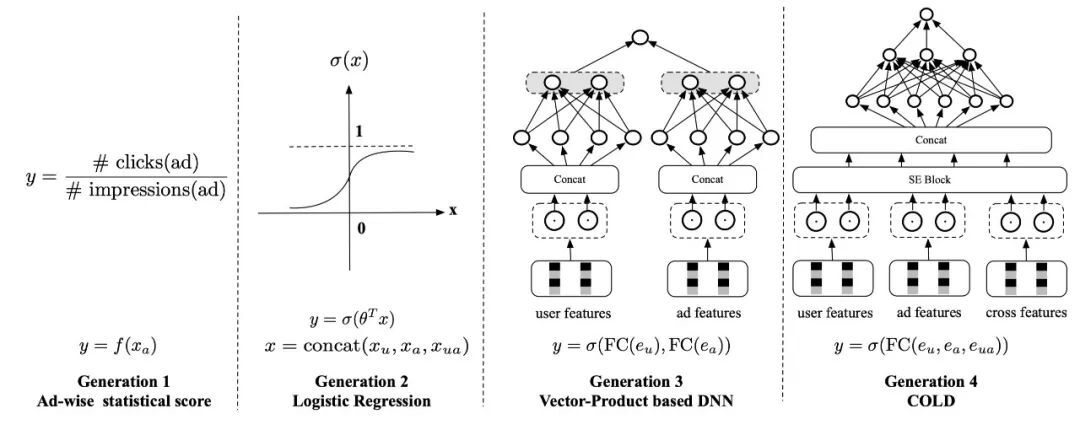
最早期的第一代粗排是静态质量分,一般基于广告的历史平均CTR,只使用了广告侧的信息,表达能力有限,但是更新上可以做到很快。
第二代粗排是以LR为代表的早期机器学习模型,模型结构比较简单,有一定的个性化表达能力,可以在线更新和服务。
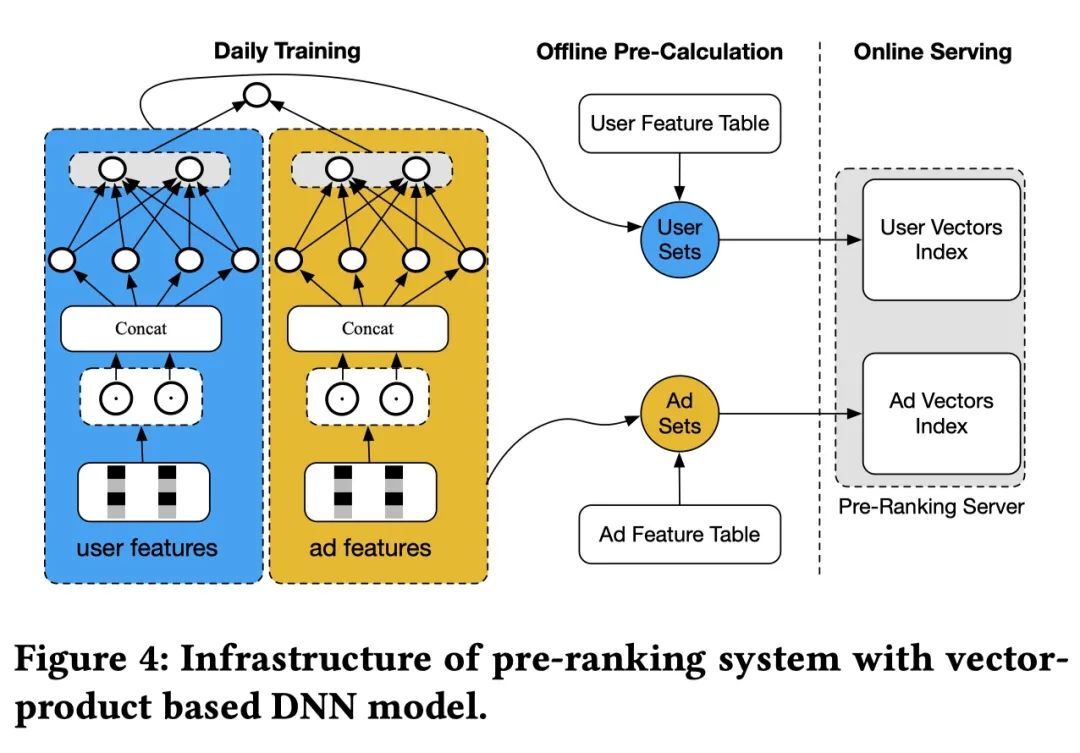
当前最广泛应用的第三代粗排模型,是基于向量内积的深度模型。一般为双塔结构,两侧分别输入用户特征和广告特征,经过深度网络计算后,分别产出用户向量和广告向量,再通过内积等运算计算得到排序分数:

向量内积模型相比之前的粗排模型,表达能力有了显著提升,但是仍然有很多问题:
模型的表达能力仍然受限:向量内积结构虽然极大的提升了运算速度,节省了算力,但是也导致模型无法使用交叉特征,能力受到极大限制。
模型实时性较差:因为用户向量和广告向量一般需要提前计算好,而这种提前计算的时间会拖慢整个系统的更新速度,导致系统难以对数据分布的快速变化做出及时响应,这个问题在双十一等场景尤为明显。
03 COLD 模型
前面粗排的相关工作仅仅把算力看做系统的一个常量,模型和算力的优化是分离的。我们重新思考了模型和算力的关系,从两者联合设计优化的视角出发,提出了新一代的粗排架构 COLD(Computing power cost-aware Online and Lightweight Deep pre-ranking system)。它可以灵活对模型效果和算力进行平衡。COLD 没有对模型进行限制,可以支持任意复杂的深度模型。这里我们把 GwEN ( group-wise embedding network) 作为我们的初始模型结构。它以拼接好的特征 embedding 作为输入,后面是多层全连接网络,支持交叉特征。当然,如果特征和模型过于复杂,算力和延时都会难以接受。因此我们一方面设计了一个灵活的网络架构可以进行效果和算力的平衡。另一方面进行了很多工程上的优化以节省算力。
1. 网络结构
精简网络的方法有很多,例如网络剪枝 ( network pruning),特征筛选 ( feature selection),网络结构搜索 ( neural architecture search)等。我们选择了特征筛选以实现效果和算力的平衡。当然其他技术也可以进行尝试。具体来说,我们把 SE (Squeeze-and-Excitation) block 引入到了特征筛选过程中,它最初被用于计算机视觉领域以便对不同通道间的内部关系进行建模。这里我们用 SE block 来得到特征重要性分数。假设一共有 M 个特征,ei 表示第 i 个特征的 embedding 向量,SE block 把 ei 压缩成一个实数 si。具体来说先将 M 个特征的 embedding 拼接在一起,经过全连接层并用 sigmoid 函数激活以后,得到 M 维的向量 s:

这里向量 s 的第 i 维对应第 i 个特征的重要得分,然后再将 si 乘回到 ei,得到新的加权后的特征向量用于后续计算。
在得到特征的重要性得分之后,我们把所有特征按重要性排序,选择 K 组不同的候选特征,并基于 GAUC,QPS 和 RT 指标等离线指标,对效果和算力进行平衡,最终在满足 QPS 和 RT 要求情况下,选择 GAUC 最高的一组特征组合,作为 COLD 最终使用的特征。后续的训练和线上打分都基于选择出来的特征组合。通过这种方式,可以灵活的进行效果和算力的平衡。
2. 工程优化
为了给 COLD 使用更复杂的特征模型打开空间,工程上也进行了很多优化。在阿里定向广告系统中,粗排的线上打分主要包含两部分:特征计算和网络计算。特征计算部分主要负责从索引中拉取用户和广告的特征并且进行交叉特征的相关计算。而网络计算部分,会将特征转成 embedding 向量,并将它们拼接进行网络计算。
① 并行化
为了实时低延时高吞吐的目标,并行计算是非常重要的。而粗排对于不同广告的计算是相互独立的,因此可以将计算拆分成并行的多个请求以同时进行计算,并在最后进行结果合并。特征计算部分使用了多线程方式以进一步加速,网络计算部分使用了 GPU。
② 列计算转换
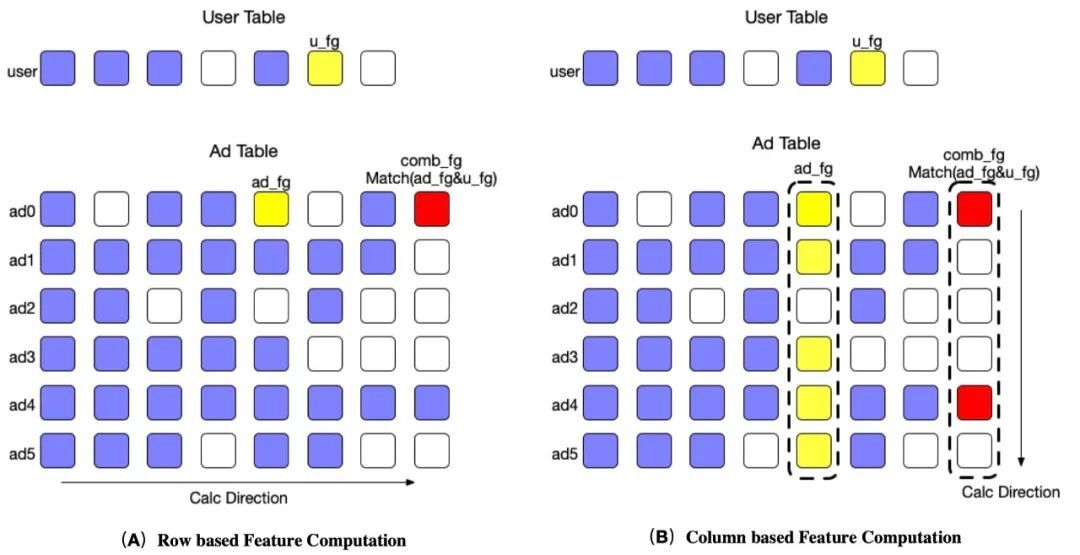
特征计算的过程可以抽象看做两个稀疏矩阵的计算,一个是用户矩阵,另一个是广告矩阵。矩阵的行是 batch_size,对于用户矩阵来说 batch_size 为 1,对于广告矩阵来说 batch_size 为广告数。矩阵的列是 featue group 的数目。常规计算广告矩阵的方法是逐个广告计算在不同 feature group 下特征的结果,这个方法符合通常的计算习惯,组合特征实现也比较简单,但是这种计算方式是访存不连续的,有冗余遍历,查找的问题。事实上,因为同一个 feature group 的计算方法相同,因此可以利用这个特性,将行计算重构成列计算,对同一列上的稀疏数据进行连续存储,之后利用 MKL 优化单特征计算,使用 SIMD (Single Instruction Multiple Data)优化组合特征算子,以达到加速的目的。
③ Float16 加速
对于 COLD 来说,绝大部分网络计算都是矩阵乘法,而 NVIDIA 的 Turning 架构对 Float16 和 Int8 的矩阵乘法有额外的加速,因此引入 Float16 计算对提升性能非常必要 。但是 Float16 会损失计算精度,特别是在 sum-pooling 的情况下,数值有可能超出 Floa16 的范围。为了解决这个问题,一种方式是使用 BN。但是 BN 本身的参数范围也有可能超过 Float16. 因此只能使用混合精度的方式,对于 BN 层使用 Float32,而后面的层使用 Float16。另一种方式是使用参数无关的归一化方式,例如 log 函数。但是 log 函数不能处理负数,并且输入值接近 0 的时候会输出绝对值较大的数字。因此我们设计了一种分段平滑函数,我们叫做 linear-log 来解决这个问题:
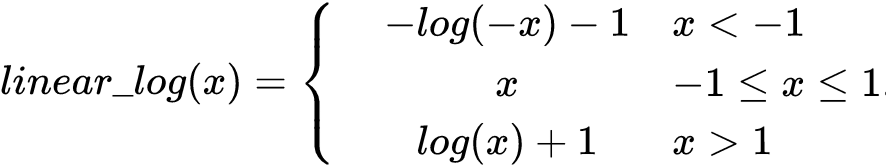
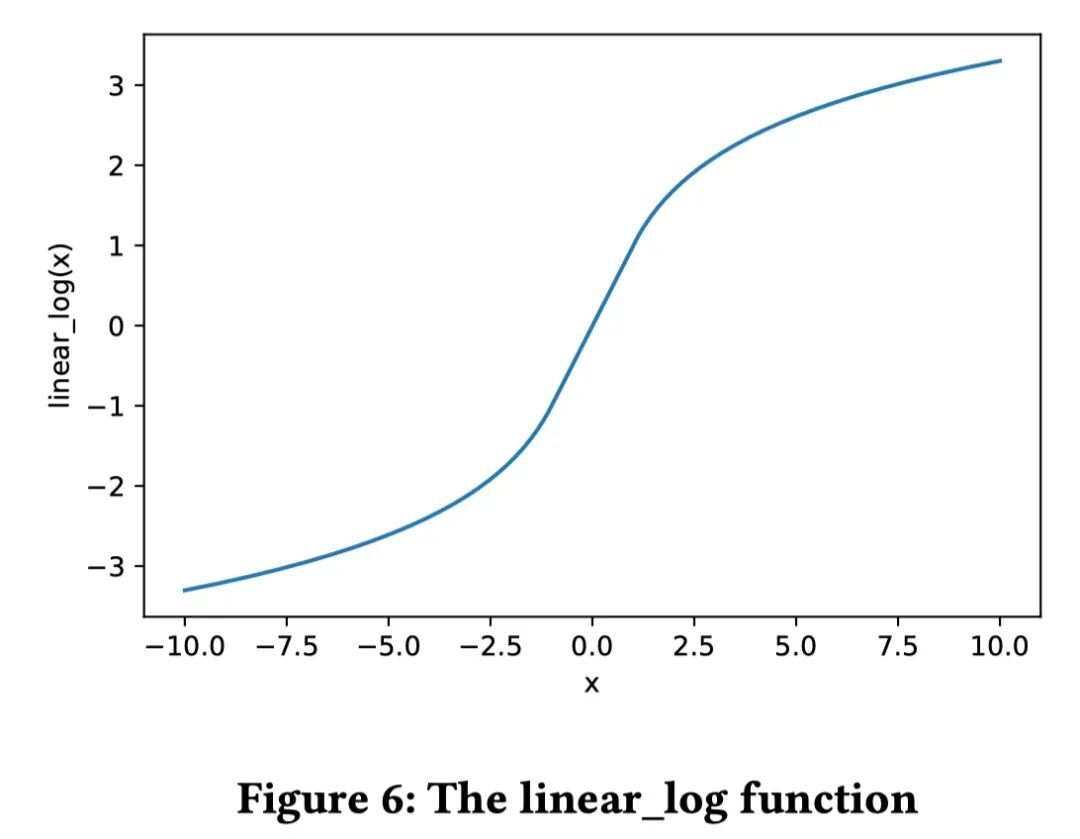
从函数图像可以看出,linear_log 函数可以将 Float32 的数值处理到一个比较合适的范围。所以如果我们将 linear_log 函数放到第一层,那么就可以保证网络的输入参数在一个比较小的范围内。具体实践上,linear_log 函数对 COLD 模型的效果基本没有影响。使用 Float16 以后,CUDA kernel 的运行性能有显著提升,同时 kernel 的启动时间成为了瓶颈。为了解决这个问题,我们使用了 MPS (Multi-Process Service)来解决 kernel 启动的开销。Float16 和 MPS 技术,可以带来接近 2 倍的 QPS 提升。
3. 在线服务架构
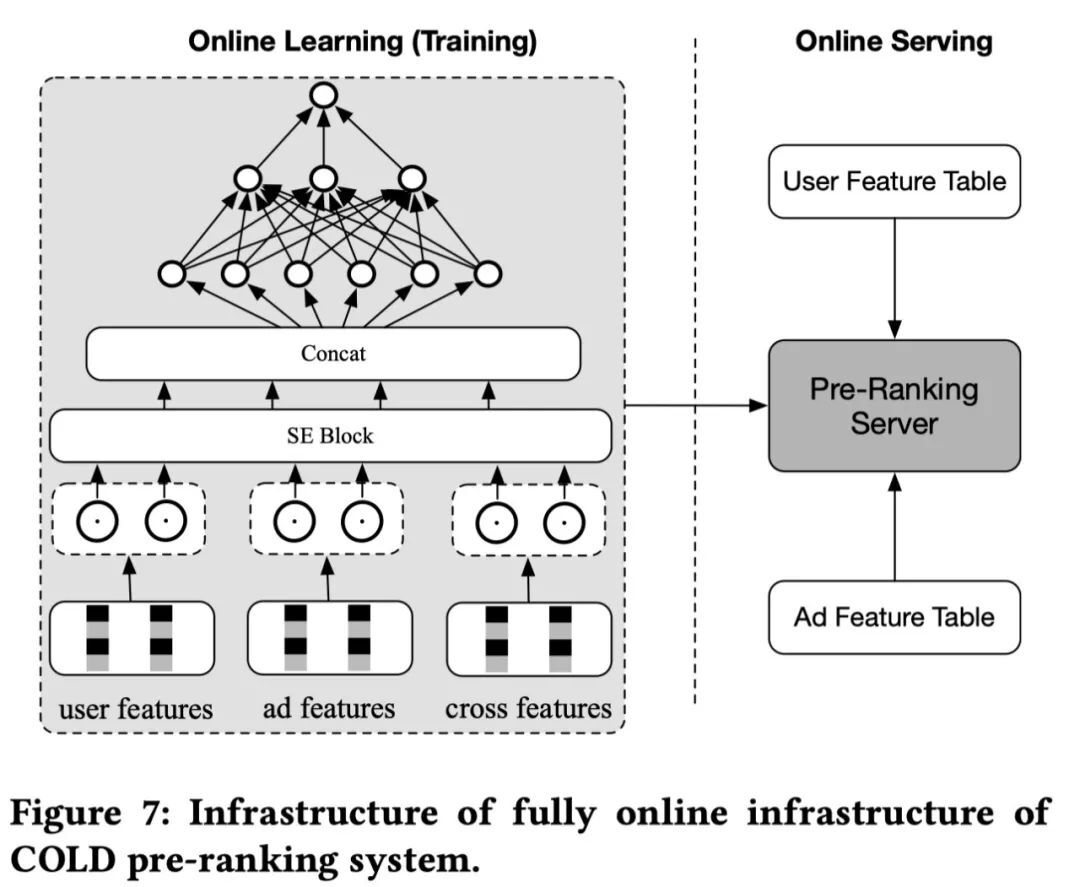
COLD 没有限制模型的结构,训练和在线打分都是实时化的,可以带来以下两个优点:
在线学习的引入使COLD与向量内积模型相比,可以更及时的响应数据分布的变化,对新广告冷启动也更为友好。
实时架构对于模型迭代和在线A/B测试都更有利。向量内积模型由于用户向量和广告向量需要提前计算好,在线A/B测试也更为困难。实时架构也使COLD模型可以更快的更新,避免了向量内积模型的更新延迟问题。
04 实验结果
这里 COLD 模型使用了 7 层全连接的网络结构。离线评估指标除了 GAUC 之外,还包含了 top-k recall,用于评估粗排和精排的对齐程度。

这里 top k 候选集合和 top m 候选集合均为粗排的输入打分集合。top k 集合是粗排选出的,而 top m 集合是精排选出的,排序指标是 eCPM(eCPM = pCTR*bid)。这里的精排模型是 DIEN。我们使用 QPS (Queries Per Seconds, which measures the throughput of themodel) 和 RT (return time, which measures the latency of model)来评估系统性能的影响。
1. 模型效果评估
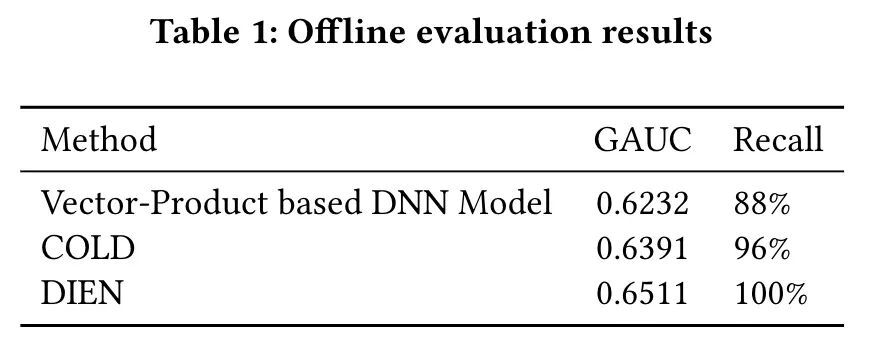
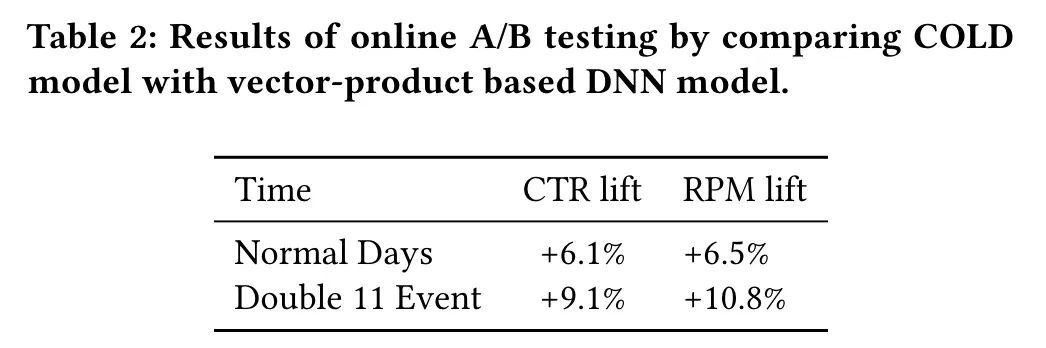
离线效果评估可以看到 COLD 在 GAUC 和 Recall 上都优于向量内积模型。在线效果上,COLD 与向量内积模型相比在日常 CTR +6.1%,RPM + 6.5%。双十一 CTR+9.1%,RPM+10.8%,提升显著。
2. 系统性能评估
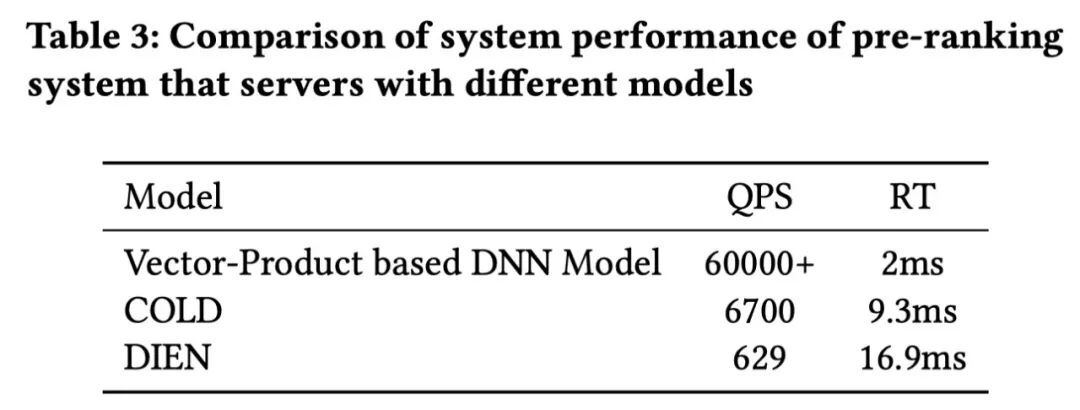
从 Table 3 可以看到,向量内积模型的系统性能最好,而精排的 DIEN 的系统性能最差,COLD 则在两者之间取得了平衡。
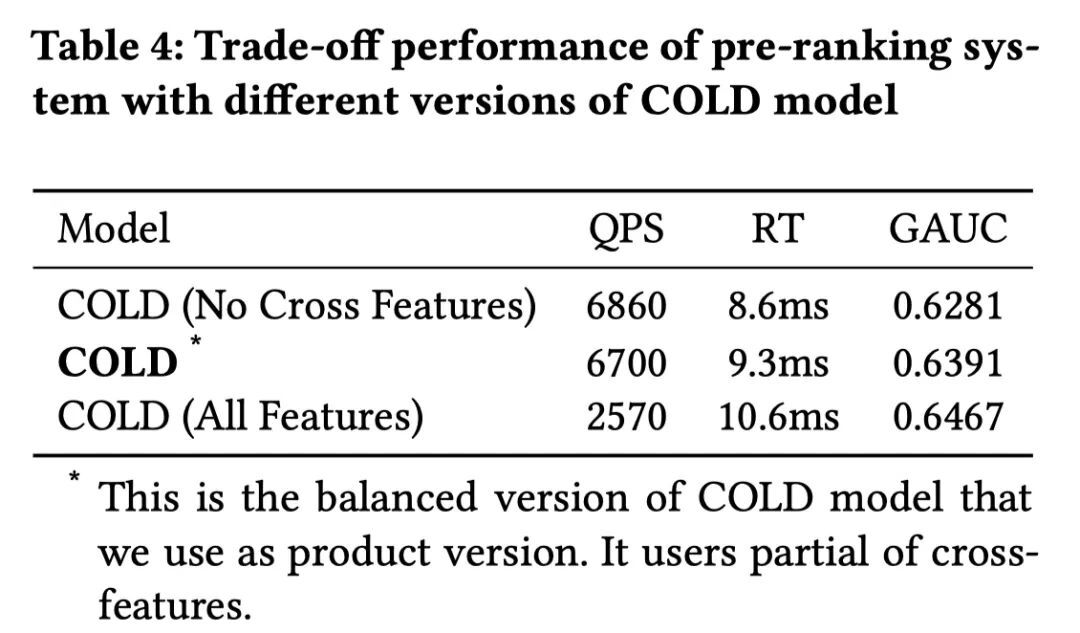
COLD 在得到特征重要性分数以后,会选出不同的候选特征,并基于离线指标进行特征选择。Table 4 列了几组供选择的特征,可以看到 COLD 是考虑效果和系统性能以后的折中。
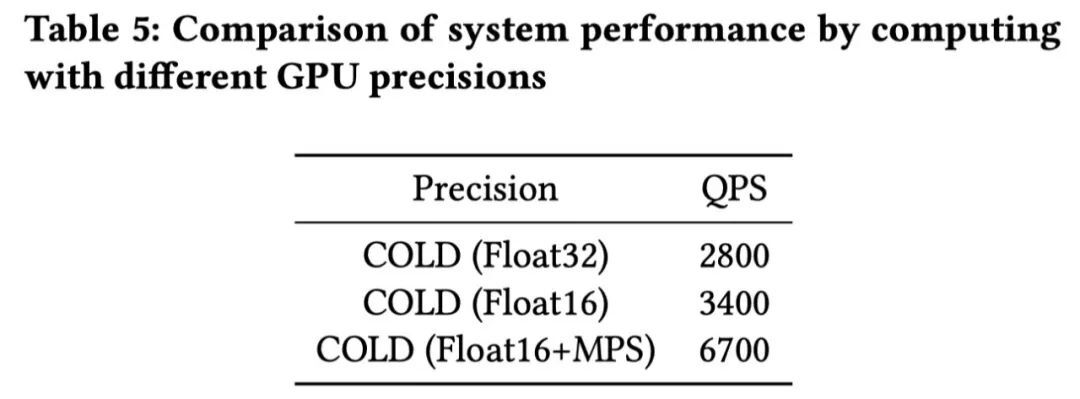
Table 5 表明,工程优化上引入 Float16 和 MPS 优化以后,QPS 提升了 1 倍,效果显著。
05 总结
这里我们向大家详细介绍了阿里定向广告的新一代粗排架构 COLD。它是新的算法和算力联合迭代视角下的产物。COLD 把算力作为一个变量进行优化,提供了一种更灵活的方式可以实现效果和算力的平衡。COLD 的训练和在线打分都是实时的,可以更好的适用数据分布的变化。2019 年以来,COLD 已经在阿里定向广告的各主要业务上得到广泛应用并取得了显著的效果提升。
原文链接:
https://zhuanlan.zhihu.com/p/186320100

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论