

1 背景
随着线上平台业务快速发展,数据价值越来越高,使用越来越频繁,数据以多种形式散落在公司内部,如何将存在关联的数据,更方便的汇总、计算,并打通数据孤岛,让异构数据源快速跨平台集成显得非常重要。目前贝壳有近 1000 个数据库,业务数据表 2 万 5 千个,将这么大量的数据库表数据快速准确导入到指定源目的地显得尤为重要,接下来让我们一起探讨下这个问题。
2 现状及痛点
2.1 数据获取周期长且滞后
业务方需要将某个业务数据库表信息建立到 Hive 离线数仓时,需要通过 sqoop 每日 T+1 全量导入到 Hive 数据仓库中,目前数据延迟为 T+1,无法实现实时或准实时同步建立 Hive 数据仓库。
sqoop 导数据耗时较长,并需要读取线上库,这样对线上数据库压力较大,会对线上业务造成一定影响。
2.2 无法实时同步元数据信息
业务数据库表新增或者表结构变化后,无法第一时间同步元数据变化等信息,需要人工干预,这样可能会导致无法继续准确的同步离线数仓数据,造成数据分析不准确甚至无法分析。
2.3 缺少数据订阅功能
无法满足业务方订阅某些库表数据实时变化的通知,并希望保证准确性,顺序性接收到这些通知,进而执行其后续业务流程操作。
2.4 数据变化轨迹无法追踪
当用户希望查询某些数据变化历史信息时,无法实时查看想要的数据变化详情和轨迹。
3DATABUS 目前所拥有的能力
3.1 数据对接能力
可将业务库表数据源小时级别,T+1 全量,增量同步到 hive 数据仓库。减少了冗余数据的产生,缩短了数据获取周期。
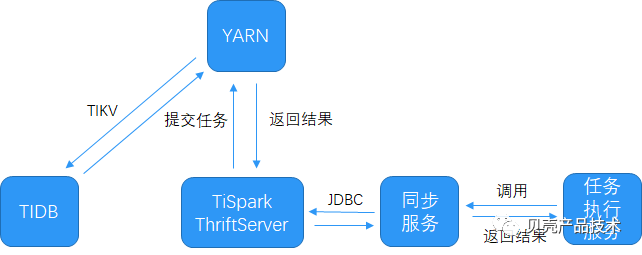
3.2 元数据自动更新与同步
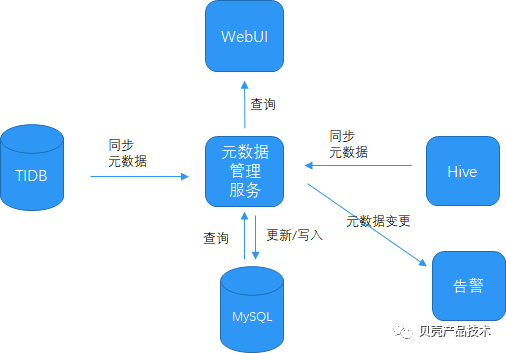
DATABUS 通过读取 TiDB 的 binlog,实时更新元数据库表结构信息,并做到同步更新 Hive 数据仓库表结构信息。
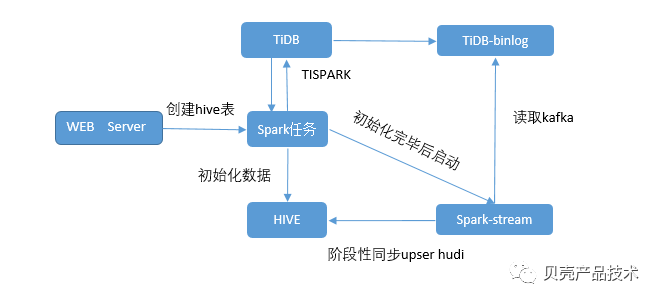
3.3 实时数据仓库建设能力
DATABUS 通过 spark-streaming 读取 TiDB 的 binlog,并将数据处理后,基于 HUDI 将数据同步到 hdfs 文件中,进而实现准实时 hive 表。
3.4 数据订阅能力
数据需求方可在 DATABUS 平台选择需要准实时监控数据变化的库表进行配置订阅任务,DATABUS 会准实时并保证顺序的写入对应 kafka 的 topic,这样需求方就可以通过消费来 kafka 的数据,快速获取业务库表的数据变化。
3.5 数据变化实时查询能力
DATABUS 通过读取 TiDB 的 binlog,实时将所有业务库表的 DML 操作同步到 elasticsearch,并提供了实时查询数据变化情况。
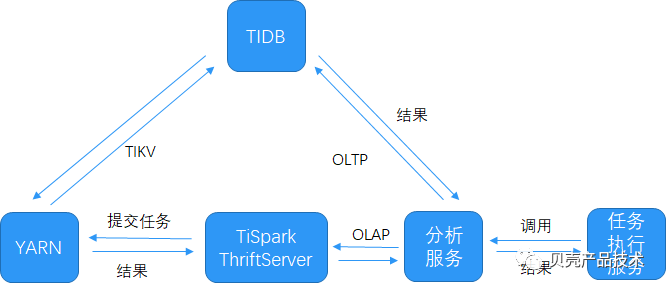
3.6 DATABUS 的整体架构图
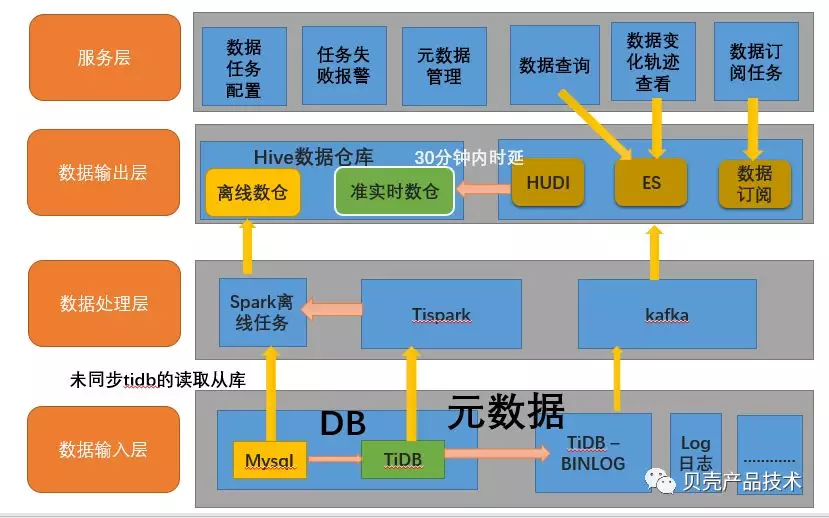
DATABUS 数据平台架构图
4TiDB 生态
4.1 引入 TiDB 目的
与线上从库解耦(之前通过 sqoop 同步线上业务从库到数据仓库,影响线上业务);
将业务元数据统一存储,统一管理,并支持水平扩展(TiDB 支持 mysql 协议,并可以模拟成 mysql 的 slave,通过 syncer 实时同步数据);
元数据数据结构变化,实时感知,实时更新离线数据仓库数据结构;
元数据 DML 操作实时同步给下游需求方,提高效率;
未来希望通过消费 binlog 消息,建立实时 hive 数仓;
能够既满足 T+1 离线业务,又能支持实时绝大部分 OLAP、OLTP 业务,TiSpark 已经很大程度上可以满足这个需求。
4.2 简介
TiDB 是 PingCAP 设计的开源分布式数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性(https://github.com/pingcap/tidb),这里简单介绍下其具备的核心特性:
SQL 支持(TiDB 与 Mysql 兼容);
水平弹性扩展,可以通过新增节点来实现 TiDB 的水平扩展,进而提高可用性;
支持分布式事务,TiDB 100% 支持标准的 ACID 事务;
一站式 HTAP 解决方案,即支持典型的 OLTP 行式存储,同时也兼具强大的 OLAP 性能,配合 TiSpark,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
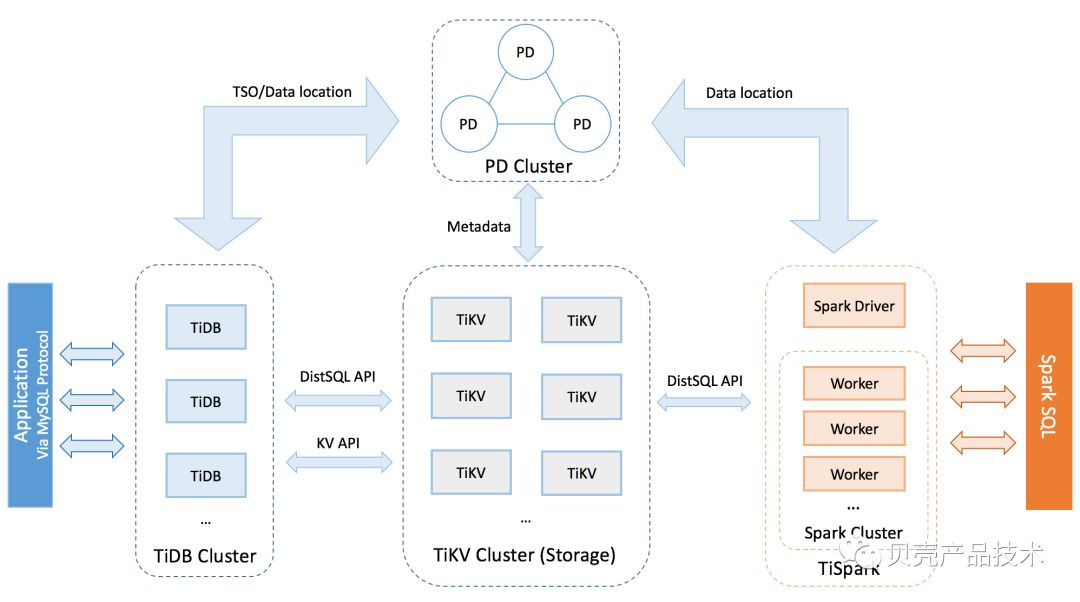
TiDB 架构图
4.3 组件简介
4.3.1 TiDB
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
目前我们的TiDB有3个集群,承载了线上业务一半的业务数据量,并还在持续接入中。
4.3.2 TiSpark
TiSpark是基于TiDB用来解决复杂OLAP需求的衍生组件,基于其融合TiKV分布式集群的优势,借助Spark平台,可以很方便的执行Spark SQL来完成80%的数据分析。
Databus利用TiSpark将TiDB的数据定时全量导入到Hive表中。由于TiDB会将数据天然的分成多个小分区,这样能够很好的利用spark的分布式特性,快速执行导入操作,经实际应用,1千万行数据导入大约在1-3分钟内完成。

Spark配置TiSpark的使用
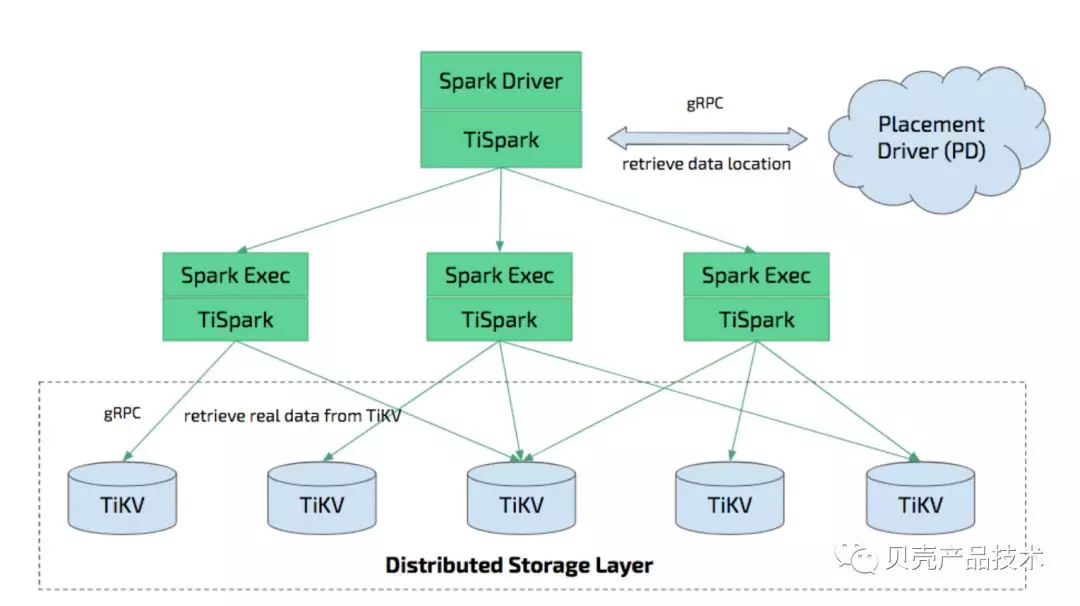
TiSpark架构图
4.3.3 TiDB-Binlog
TiDB-Binlog是用于收集TiDB产生的Binlog,并提供同步功能的组件。
DATABUS目前通过将binlog信息以protobuf的数据格式同步到kafka,并消费kafka来进行实时数仓,动态更新元数据信息,数据订阅,数据变化实时查询等功能的支撑。
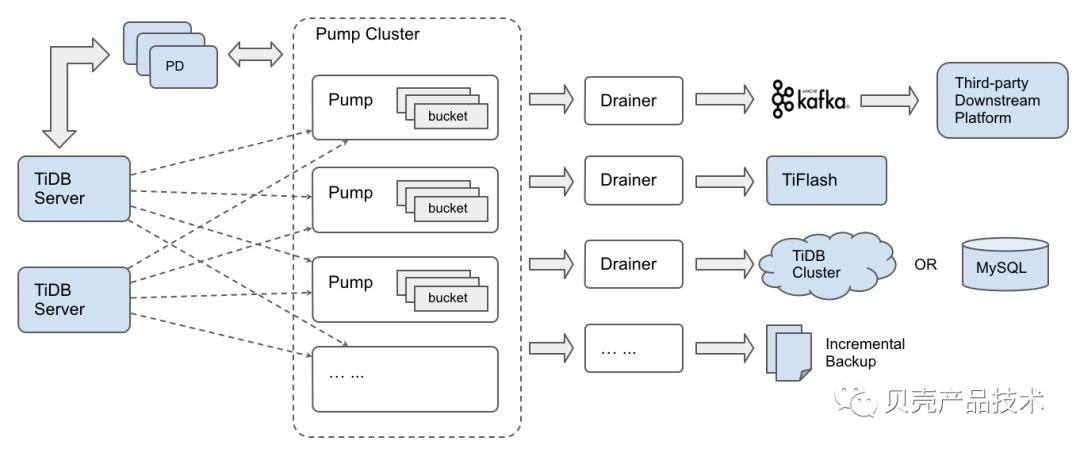
TiDB Binlog 架构图
4.4 TiDB的一些总结
1)基于贝壳存在库表重名问题,我们通过将原业务数据库映射为“端口号_库名”的方式,避免重名需要放到不同集群中的尴尬局面,进而提高了服务器使用效率(TiDB一个实例中是不允许有重名数据库出现的)。
2)由于为了保证事物顺序性,目前只会写入kafka一个分区,这样降低了消费效率,DATABUS目前的解决方案是根据库表hash,写入了不同分区,即保证了顺序性又提高了消费效率。与TiDB-Binlog组件作者沟通,后续PingCAP有计划优化写入下游kafka的效率。
3)业务元数据表结构变化可能会导致TiDB同步失败,目前遇到类似问题暂时采取重新同步数据的办法来处理,后续TiDB会不断优化并支持,以下是一些会导致同步失败的情况举例:
varchar类型 修改成 long类型 这类跨类型修改;
varchar(32) 改成 varhcar(16) 这种字段长度变小;
mysql表包含外键或分区表。
4)使用TiSpark时,目前不支持enum等特殊类型处理,日后会很快支持!
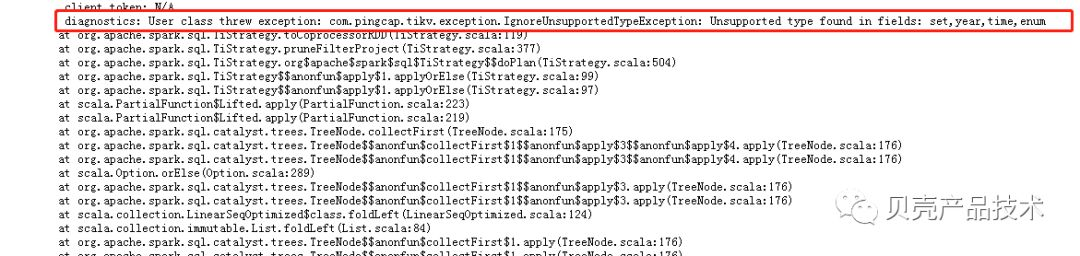
类型不支持
5HUDI简介
5.1 为什么使用HUDI
建设准实时的数仓是DATABUS的一个愿景,DATABUS通过读取TiDB-binlog的数据,对业务库表进行建立准实时,一致性的hive数据仓库,并通过hudi 对Hadoop文件进行更新、插入和删除hive表中的数据。这样提高了数据的实时性,也降低了维护不同分区全量数据的硬件支出。下面是hudi的设计架构:
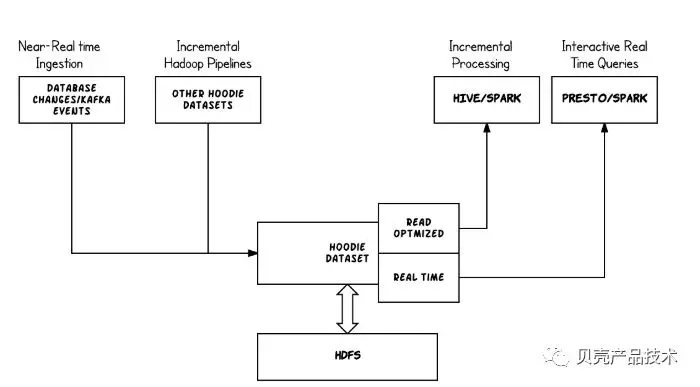
HUDI Upser Data
6总结&展望
DATABUS平台自从8月立项以来,目前已经做到支持公司99%业务库表元数据管理及配置全量,增量T+1,小时级别hive离线数仓同步任务;每日单TiDB集群3-4亿数据采集,支持40%业务库表数据配置订阅任务和数据变化实时查询。
我们还将持续提高支持率,开发多种异构数据对接能力,并尽快上线实时数仓能力(运用hudi等大数据技术),提高数据分析时效性和准确性。
作者介绍:
雅诺达(企业代号名),目前负责贝壳找房数据直通车项目。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/-p1B9ggFD7H8V-Y0Qc5dKA

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 1 条评论