

2019 年天猫 618 大促,蚂蚁金服首次在大促中对调度系统和技术栈全面应用 Kubernetes,突破了 Kubernetes 单集群万节点的规模,总节点数达到数十万个,这是世界最大规模的 Kubernetes 集群之一,而这距离开发团队下载 Kubernetes 代码仅一年之久。

背景
去年 6 月份,蚂蚁金服的 Kubernetes 开发团队刚刚下载 Kubernetes 代码,从零开始尝试在内部落地 Kubernetes 集群,并推动云原生实践。2019 年天猫 618 大促,蚂蚁金服首次在调度系统和技术栈全量应用 Kubernetes,平稳度过大促并突破 Kubernetes 单集群万节点规模,机房和集群数量达到数十个,总节点达到数十万个,这是世界最大规模的 Kubernetes 集群之一。
蚂蚁金服的 Kubernetes 开发团队是一个仅有十几人组成的小团队,他们用短短一年时间,通过扩展 Kubernetes 的方式将蚂蚁金服老的调度系统的功能对齐,还将一系列 Kubernetes 功能带回并落地到蚂蚁金服。开发团队能在如此短时间内取得如此成绩,所依靠的正是云原生技术:开发团队使用云原生技术让开发和迭代敏捷化,同时让一切过程自动化。在落地 Kubernetes 的过程中,开发团队已经尝试将云原生的理念实践并执行,取得的成果将为整个蚂蚁金服后续的全面云原生化提供范本。
本文将分享蚂蚁金服的 Kubernetes 开发团队如何使用云原生技术推进 Kubernetes 在蚂蚁金服的大规模落地,同时也会分享一些对于大规模 Kubernetes 集群性能优化的经验。
将 Kubernetes 运行在 Kubernetes 上
云原生的核心理念是让应用无差别运行在任何一朵云上,即将应用变成云的 “原住民”。而蚂蚁金服的 Kubernetes 开发团队在项目开始时需要思考的是如何将 Kubernetes 云原生化的运行在各个机房,并在没有任何基础设施的云机房也能无差别运行 Kubernetes。
首先,新建一个 Kubernetes 是一项繁琐的事情:初始化一堆证书,包括安全的存储证书;有序拉起二十几个组件,同时组织好彼此之间的引用关系,保证后续能够方便地升级;最后还要做自动化故障恢复。
一旦拥有 Kubernetes,如果某个应用提出应用发布、自动化运维等需求,可以很简单的完成。但是,如何才能让 Kubernetes 本身也享受到 Kubernetes 带来的强大功能呢?
那么,这句话应该如何理解呢?在蚂蚁金服启动落地 Kubernetes 时,就已经预见内部对“自动化运维和交付”的巨大依赖。蚂蚁金服需要管理几十个集群、几十万计算节点。同时,随着迭代的进行,扩展组件越来越多(到目前已经有三十多个)。
因此,在经过一系列讨论之后,蚂蚁金服决定将 Kubernetes 运行在 Kubernetes 之上,并且将组件和节点的交付过程封装成 Operator。有了 Kubernetes 和 Operator 之后,想要交付一个 Kubernetes 集群给应用方就像提交 Pod 一样容易,并且集群的各种组件都能自动故障自愈。这可以理解为,用 Operator 这种云原生的方式交付整个基础设施。如果不是当初的这个决定,很难想象组件和节点在离开 Kubernetes 之后如何运维和自动化恢复。
为此,开发团队设计出了 Kube-on-Kube-Operator,它的用途是将各个机房交付给用户的 Kubernetes 集群 (称为 “业务集群”) 的组件和服务也都跑在一个 Kubernetes (称为 “元集群”) 上。下图是 Kube-on-Kube-Operator 的核心架构图:
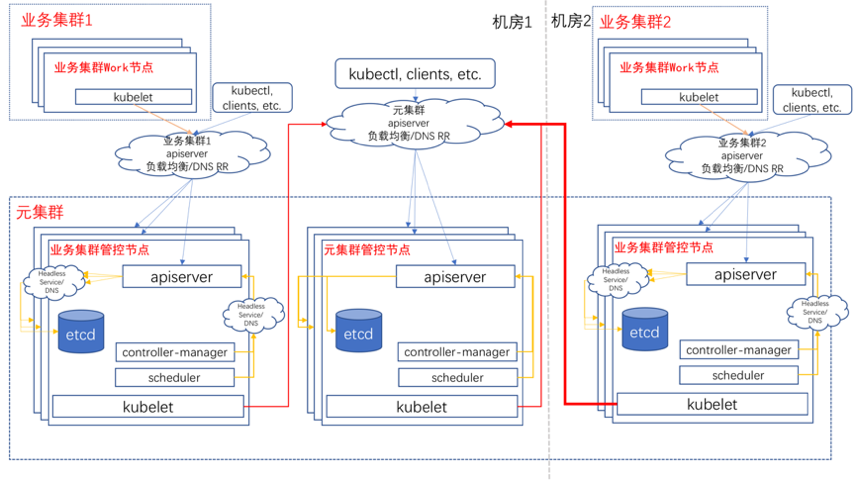
在拥有 Kube-on-Kube-Operator 之后,蚂蚁金服能在分钟级甚至秒级创建一个 Kubernetes 集群。同时,所有业务集群 Kubernetes Master 组件都运行在元集群 Kubernetes 上,凭借 Kubernetes 的能力可以做到秒级故障恢复。
Kube-on-Kube-Operator 用云原生方式搞定了 Kubernetes Master 组件,那么 kubelet 和 Worker 节点呢?
众所周知,将一个 Worker 节点加入集群也需要一堆复杂的事情:生成随机证书,安装 Runtime 以及各种底层软件,设置 kubelet 启动参数等。对此,蚂蚁金服团队在思考能否像 Kubernetes 自动化维护 Pod 一样自动化维护 Worker 节点呢?
Node-Operator 正是在这样的背景下诞生的,其使用声明式编程、面向终态的特性去管理 Worker 节点。Node-Operator 的职责涵盖从云厂商购买计算节点开始到接管 Kubenertes 节点整个生命周期:从初始化证书、kubelet 以及节点必要组件,到自动化升级组件版本,再到最后的节点下线。同时,Node-Opeator 也会订阅 NPD(Node Problem Detector) 上报的节点故障信息,进行一系列自动化修复。下图是 Node-Operator 的核心架构图:
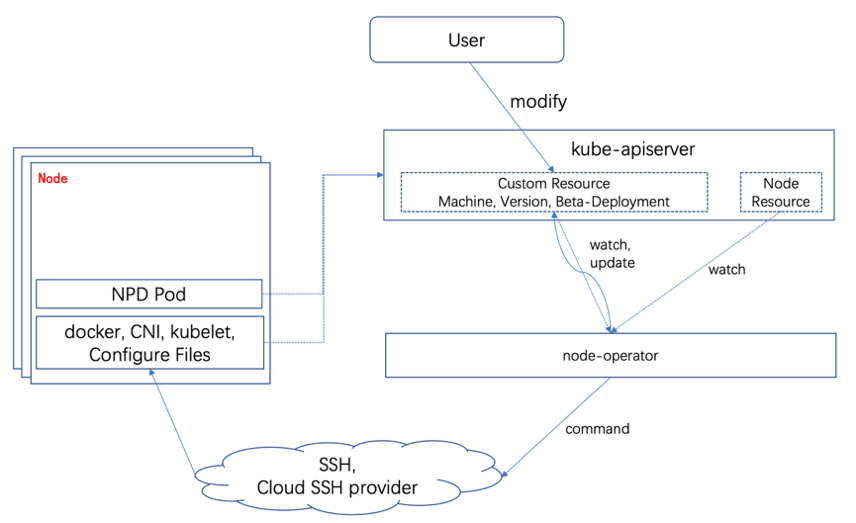
Kube-on-Kube-Operator 和 Node-Operator 在生产环境中表现稳定,经历了数十个大迭代以及无数小迭代。同时,Kube-on-Kube-Operator 自动化运维了数十个生产集群,为每日自动化功能测试和回归测试快速创建和销毁临时测试集群。Node-Operator 接管了几乎整个蚂蚁金服的物理机生命周期,这种思想也继承到了下一代运维管控系统。
除了 Kube-on-Kube-Operator 和 Node-Operator,在 “automate everything”信念的驱动下,蚂蚁金服还开发出了各种 Operator 去交付蚂蚁金服的所有基础设施和应用。
自动化流水线与 GitOps
自动化和 CI/CD 是云原生非常重视的理念,蚂蚁金服开发团队将其应用到研发过程中,让研发、测试和发布的一系列过程都自动化。
上线 Kubernetes 初期,在保持飞速迭代的情况下,也需要确保代码质量,团队的规定是:任何组件都要有单独的 e2e 测试集或者测试用例,同时每天晚上都会将最新代码放入全新的沙箱集群测试,另外还会定期或者触发式在生产集群运行功能验证测试。
为了提高效率并更好完成测试,开发团队建立了自动化流水线。最开始的自动化流水线是为了服务测试,在自动化流水线建立工作集,几乎所有工作集都通过调用 Kube-on-Kube-Operator 和 Node-Operator 建立了全新的沙箱集群,然后开始运行各自测试集的测试,最后销毁集群发送测试结果。
为了在自动化流水线上更方便的建立工作集,团队将所有组件和测试集都进行镜像化,使用 Kube-on-Kube-Operator 和 Kubernetes 元集群可以方便、快速地建立测试用的沙箱集群,然后使用容器和配置注入的方式让测试集 (Job on Kubernetes) 运行在任何环境、指定任何集群跑测试。
后来,团队在流水线加上自动化发布:流水线将期望的组件发布完成,然后自动触发功能验证测试。如果发布或者测试失败,通过钉钉机器人通知对应负责人,如果成功,几乎可以做到无人值守发布。
Kubernetes 一个令人兴奋的特性就是将各种部署资源的声明统一和标准化:如果需要一个在线无状态服务,只需向 Kubernetes 提交一个 Deployment;如果需要负载均衡,只需提交一个 Service;如果需要持久化存储卷,就提交一个 PVC(PersistentVolumeClaim);如果需要保存配置文件或者密码存储,只需提交 ConfigMap 或者 Secret,然后在 Pod 里面引用就可以。Kube-on-Kube-Operator 就是用这些标准的资源定义 Kubernetes 元集群发布各个 Kubernetes 业务集群的组件。
但是,在 Kube-on-Kube-Operator 的使用过程中,团队发现 Kubernetes 发布还是不够透明:Kube-on-Kube-Operator 承包了发布过程,即使它是一个非常轻量的触发器,用来将业务集群部署资源文件提交到 Kubernetes 元集群,但执行一次发布也需要比较繁琐的操作。这在快速的迭代团队中,教会新同事使用 Kube-on-Kube-Operator 声明版本、修改 Cluster(代表一个集群的 CRD) 版本引用,看起来不够 “敏捷”。Kube-on-Kube-Operator 俨然变成了一个 PaaS,但业务团队为什么要花精力学习一个 “非标准 PaaS” 的使用呢?
事实上,Kubernetes 已经将一切标准化,使用 Git 自带的版本管理、 PR Review 功能就可以实现部署资源文件管理系统。
因此,开发团队引入 GitOps 理念, GitOps 基于经过验证的 DevOps 技术——大体类似于 CI/CD 和声明式基础设施即代码,而构建为 Kubernetes 应用程序提供了一套联合的、可自动生成的生命周期框架。
GitOps 将原先包裹在 PaaS 或者 Kube-on-Kube-Operator 的黑盒全部公开化和民主化。每个人都能从名为 kubernetes-resources 的 Git 仓库看到 Kubernets 组件目前在线上的部署状态:版本、规格、副本数、引用的资源。每个人都能参与发布,只要提交 PR,经过事先设定的管理员 Review 和 Approve 之后,就可以自动发布到线上并开始跑测试。团队使用 kustomize 的 base/overlays 功能做到各集群的差异化部署,同时又能避免同一个组件在各个 Kubernetes 集群重复编写。
开发团队还将 GitOps 能力开放给业务方,为此建立了名为 partner-resources 的 Git 仓库,任何业务应用的开发同学都能访问该仓库并提交 PR,经过 Review 合并到 Master 后,自动化流水线会将部署资源生效到指定 Kubernetes 集群,从而进行业务应用的云原生实践和落地。
可能很多开发者会不由自主的将透明、民主和 “不安全”挂上钩。恰恰相反,kubernetes-resources 和 partner-resources 里面没有任何一个秘钥文件,只有权限声明 (RBAC) 文件。权限声明需要 Review 才能合入,而身份识别使用了 Kubernetes 自动注入秘钥 (ServiceAccount) 功能。在 ServiceMesh 普及之后,秘钥文件更加被弱化,所有身份识别都依赖 Mesh。同时,蚂蚁金服运行的 Kubernetes 集群采用了最高的安全标准,所有链路都使用 TLS 双向加密和身份认证。
在云原生时代,Kubernetes 集群其实已经是最好的元数据系统。同时,Kubernetes 各种 Workload 配合工作让用户提交的部署资源一直维持在期望状态;而 GitOps 拥有的版本记录、PR Review 功能等是最好的部署资源文件管理系统。即使目前还有一些路要走,比如目前 Kubernetes 缺少灰度发布等更高级功能的 Workload,但是在不久的将来肯定能看到这些特性被放入 Workload。
全面云原生化
Kubernetes 是云原生的基础,蚂蚁金服在过去一年从零到全面落地 Kubernetes ,并在期望的规模下做到优秀的吞吐量。可以说,过去一年完成了云原生的基础建设。
同时,非常多其它云原生技术在 Kubernetes 集群内并行探索和落地,达到生产级别,甚至支持大促,比如 ServiceMesh 等。简单来看,蚂蚁金服落地云原生的目的可以总结为三点:标准化交付、提高研发效率和提高资源利用率。
其中,标准化交付比较好理解,蚂蚁金服围绕 Kubernetes 建设 PaaS 和应用交付体系,使用 Kubernetes 统一的资源声明方式交付所有应用,同时让所有应用自动化注入基础服务,如 ServiceMesh,统一日志,Tracing 等;提高研发效率注重提高每个应用开发者的工作效率,让其使用 Serverless、CI/CD 展开日常工作,让开发者背靠云原生技术栈做更敏捷的开发和迭代;最后,使用 Kubernetes 统一资源和调度,让所有的应用、Job、GPU 调度都使用 Kubernetes 集群统一的资源池。开发团队在 Kubernetes 统一资源池内做了一系列调度优化和混布技术,让资源利用率有质的提升。
大规模集群性能优化
如果按照 Kubernetes 最新版本提供的能力,做到单集群万节点并不是特别困难。但是,在这种背景下,让整个集群保持较高吞吐量和性能,并在 618 大促时依旧对各种响应做到及时反馈是不容易的。
蚂蚁金服通过系列压测和迭代将单集群做到了上万规模。然而,在这个过程中,整个团队发现不能太迷信压测数据,压测场景其实非常片面,而生产环境和压测环境有非常大差异,主要体现在 Kubernetes 扩展组件的客户端行为和一些极端情况。
举例来说,一个是 Daemonset,蚂蚁金服内部一个集群已经拥有十个左右的 Daemonset 系统 Agent,在如此大规模集群内上线一个使用 Kubernetes 客户端的不规范 Daemonset 都可能使 API Server 陷入崩溃状态;另一个是 Webhook,蚂蚁金服拥有一系列 Webhook Server 扩展功能,它们的响应速度都会影响到 API Server 的性能,甚至引起内存和 goruntine 泄露。从上述示例不难发现,其实要将大规模集群维持在健康状态需要全链路优化和调优,而不仅仅局限于 API Server 和 etcd,更不是仅仅停留在压测数据。
开发团队将集群节点规模上升到万级别的时候,发现更多的瓶颈在 Kubernetes API Server。相对来说,etcd 的表现比较稳定。团队做了系列优化和调整,来让 API Server 满足性能需求。
1、优先满足和保证 API Server 计算资源需求
在常规部署模式下,API Server 会和 Controller Manager、Scheduler 等核心组件一起部署在一台节点上,在 Kube-on-Kube 架构下也是采用这种部署模式,以达到合理使用资源的目的。在这种部署架构下,将 API Server 的资源优先级设置到最高级别,也就是在 Kubernetes 资源级别表达里的 Guaranteed 级别,并且尽可能将物理节点所有资源都占用;同时将其他组件的优先级相对降低,即将其设置成 Burstable 级别,以保证 API Server 的资源需求。
2、均衡 API Server 负载
在 Kubernetes 架构下,所有组件均面向 API Server 展开工作,因此组件对 API Server 的请求链路健康非常敏感,只要 API Server 发生升级、重启,所有组件几乎都会在秒级内发起新的一系列 List/Watch 请求。如果使用滚动升级模式逐个升级 API Server 的模式去升级 API Server,那么很有可能在升级之后,绝大多数客户端请求都会打在一个 API Server 实例上。
如果负载不均衡,使得 API Server 进入 “一人工作,多人围观” 的场面,那么很可能导致 API Server 发生雪崩效应。更糟糕的情况是,因为 Kubernetes 的 client-go 代码库使用了 TLS 链路复用的特性,客户端不会随着运行时间增长,因为链接重建将负载均衡掉。
开发团队研究后发现,这个问题可以通过优化客户端将请求平衡掉来解决,当前正在着手研发,成功后也会回馈给开源社区。在这个特性还未发布之前,可以通过设置升级 API Server 的策略使用 “先扩后缩” 来缓解该问题,即先将新版本的 API Server 全部创建出来,然后再下线老版本的 API Server。使用 Kubernetes 的 Deployment 表达三副本的 API Server 升级策略如下:
3、开启 NodeLease Feature
对于提升 Kubernetes 集群规模来说,NodeLease 是一个非常重要的 Feature 。在没有开启 NodeLease 之前,Kubelet 会使用 Update Node Status 的方式更新节点心跳,而一次这样的心跳会向 API Server 发送大约 10 KB 数据量。
在大规模场景下,API Server 处理心跳请求是非常大的开销。而开启 NodeLease 之后,Kubelet 会使用非常轻量的 NodeLease 对象 (0.1 KB) 更新请求替换老的 Update Node Status 方式,这大大减轻了 API Server 的负担。在上线 NodeLease 功能之后,集群 API Server 开销的 CPU 大约降低了一半。
4、修复请求链路中丢失 Context 的场景
众所周知,Go 语言标准库的 HTTP 请求使用 request.Context() 方法获取的 Context 来判断客户端请求是否结束。如果客户端已经退出请求,而 API Server 还在处理请求,那么就可能导致请求处理 goruntine 残留和积压。
在 API Server 陷入性能瓶颈时,API Server 已经来不及处理请求,而客户端发起的重试请求,会将 API Server 带入雪崩效应:处理已取消请求的 goruntine 会积压的越多,直到 API Server 陷入 OOM。开发团队找出了一系列在处理请求没有使用 Context 的场景,并向上游社区提交了修复方案,包括使用 client-go 可能导致的 goruntine;Admission 和 Webhook 可能引起的 goruntine 积压。
5、优化客户端行为
目前,API Server 限流功能只限制最大读和写并发数,而没有限制特定客户端请求并发量的功能。因此,API Server 其实是比较脆弱的,一个客户端频繁的 List 数目较大资源(如 Pod, Node 等)都有可能会让 API Server 陷入性能瓶颈。开发团队强制要求所有客户端使用 Informer 去 List/Watch 资源,并且禁止在处理逻辑里面直接调用 Client 去向 API Server List 资源。而社区开始重视这方面,通过引入 Priority and Fairness 特性去更加细粒度的控制客户端的请求限制。
在后续越来越多的系统 Daemonset 上线之后,团队发现,即使做到了所有客户端使用 Informer,集群内的 List Pod 请求依旧很多。这主要是 Kubelet 和 Daemonset 带来的,可以用 Bookmark 特性来解决这个问题,在未上线 Bookmark 的集群内,可以调整 API Server 对资源的更新事件缓存量来缓解该问题 (如 --watch-cache-sizes=node#1000,pod#5000),同时调整 Daemonset Re-Watch 的时间间隔:
结束语
在蚂蚁金服云原生实践和落地的过程,开发团队认识到,项目顺利实践与开源社区的帮助密切相关。除了 Kubernetes, 蚂蚁金服团队还使用了其它开源项目,比如 Prometheus。Prometheus 的意义在于标准化 Metrics 和其查询语句,任何应用都可以使用 Prometheus 埋点并记录 Metrics,而蚂蚁金服通过自研采集任务调度系统,以及数据持久化方案,使得 Prometheus 数据不会有任何 “断点” ,同时还支持永久历史数据查询。
目前,蚂蚁金服已向 Kubernetes 社区提交了许多大规模场景下的性能提升和优化方案,上面提到在 Kubernetes API Server 性能优化过程中发现的问题,以及修复最新 Kubernetes 版本中的许多 Daemonset 的 bug ,将 Daemonset 的生产可用性提高一个层级。同时,蚂蚁金服也将众多技术开源给社区,包括金融级分布式框架 SOFAStack。
可以说,全面实现云原生是每个开发者都需要参与的“革命”,而蚂蚁金服将作为发起者和分享者参与其中。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 1 条评论