
背景
我们的 HAProxy1 日志又叫流量日志,当前存储在两台 SQL Server 上,一台在纽约,一台在科罗拉多州。在 2019 年初,我们有约 4.5 年的数据,总计约 38TB。最初,数据库设计为每天只存一个表。也就是说在 2019 年初,单个数据库中大约有 1600 个表,其中包含多个数据库文件(因为数据文件的大小限制为 16TB)。每个表都有一个集群化的列存储索引,其中包含 100-400 百万行。
我必须将数据从现有的每日表中移到一个新结构中——每个月一个表。这需要同时在 NY(纽约)和 CO(科罗拉多州)服务器上完成,并且数据是存储在机械硬盘上的,所以迁移会非常缓慢而痛苦。
此外,迁移工作只能用现有服务器上仅剩的一点磁盘空间来完成。这些服务器有一个 44TB 的机械硬盘分区,而我们已经用掉了 36-38TB 不等。所以,我得这么做:
将数据迁移到新格式
删除旧数据
压缩旧的数据库文件
不断重复
我以为只要几个月就能搞定,没想到,最后整个项目花了 11 个月的时间。
一些要点
先提一些项目要点:
我是完全远程工作的,所以无法从本地计算机运行任何进程。一切任务都需要在一台永久在线的计算机上执行,因此出现任何 VPN 故障都不行。
我需要在两台单独的机器上完成工作。我当时是分别在两个数据中心的 SQL Server 上进行迁移的,所以需要在两个地点各准备一台机器,以避免网络速度问题。
我们在 Stack Overflow 中有用于各种用途的跳转盒(jump box),在 NY 和 CO 各有一个,非常适合迁移工作。
旧数据库仍在实时生产环境中运行,这意味着在我移动数据时,每天都会添加一个新表。换句话说,我的迁移对象是动态的。
数据库处于
simple recovery状态,因此我们不必处理事务日志。我们的备份是原始的源日志文件,而两地的 SQL Server(NY 和 CO)是彼此的副本。
这些就是整个项目的痛点。与 VPN 断开连接意味着我必须重新连接才能监视迁移进度。从跳转盒启动意味着经过一些清理后,所有进程都需要重新启动。由于我们仍在插入新数据,因此我一直在和目标赛跑,花费的时间越长,我需要移动的数据就越多。
为什么要这样做?
这样做有很多原因,其中之一就是技术债务。我们意识到原始的每日表结构并不理想。如果我们需要查询跨越几天或几个月的数据,它会很慢。
为什么不删除或清除某些数据?
如前所述,我们在两台服务器上只剩下很少的可用空间。我们清除了一些数据,但对数据团队来说,数据越多越好。
我们迟早要购买新硬件,目标是将数据迁移到新格式,然后当我们获得新服务器时把硬盘挪过去就行。
开始工作
每台服务器的硬盘状态如下:
一个 230GB 的 C 盘,只安装 Windows;
一个 3.64TB 的 NVMe D 盘,包含 tempdb、一个数据文件和现有 HAProxyLogs 数据库的日志文件,大约 85%已用;
一个 44TB 的 E 盘,HAProxyLogs 数据库的其余 3 个数据文件,85-90%已用。
因此,可用的中转空间很小。
经过研究,我们决定在两个服务器中同时安装几个额外的 NVMe SSD。服务器中只有 PCIe 插槽可用,所以最后把 U.2 接口的 NVMe SSD 通过转换卡装到了这些插槽上。最后,我们得到了一个 14TB 的空白 F 盘,这至少给了我一点空间。
现在,我们有了一些自由空间,是时候设置新数据库并开始迁移。我编写了脚本来创建新数据库:
CREATE DATABASE [TrafficLogs] CONTAINMENT = NONEON PRIMARY( NAME = N'TrafficLogs_Current', FILENAME = N'F:\Data\TrafficLogs_Current.mdf', SIZE = 102400000KB, FILEGROWTH = 5120000KB),FILEGROUP [TrafficLogs_Archive]( NAME = N'TrafficLogs_Archive1', FILENAME = N'E:\Data\TrafficLogs_Archive1.ndf' , SIZE = 102400000KB, FILEGROWTH = 5120000KB),( NAME = N'TrafficLogs_Archive2', FILENAME = N'E:\Data\TrafficLogs_Archive2.ndf', SIZE = 102400000KB , FILEGROWTH = 5120000KB),( NAME = N'TrafficLogs_Archive3', FILENAME = N'E:\Data\TrafficLogs_Archive3.ndf', SIZE = 102400000KB, FILEGROWTH = 5120000KB)LOG ON( NAME = N'TrafficLogs_log', FILENAME = N'F:\Data\TrafficLogs_log.ldf', SIZE = 5120000KB, MAXSIZE = 2048GB, FILEGROWTH = 102400000KB);它将所有旧的历史表(40TB 的那个)存储在TrafficLogs_Archive文件组中,我们将使用PRIMARY和TrafficLogs_Current来添加新数据。
你会注意到,TrafficLogs_Archive文件组位于快塞满的 E 盘上,而不是新的 F 盘上——稍后将详细介绍该错误。
移动所有数据
我们有了一个数据库,所以是时候开始迁移了。需要明确的是,我实际上是接管了一个从几年前就开始、停止,然后不断重复的过程。在我成为 Stack Overflow 的 DBA 之前,这个项目已经积压了很多工作。那时,大家都意识到这将是一个非常耗时的项目,并且由于我们没有足够的资源,结果不断碰壁。每天都有新表加入,任务也越来越庞大。
由于这是一个曾被废弃的项目,因此我并不是完全从头开始的。我拿到了一些脚本来:
1.创建所有新的月度表
-- written by Nick CraverDeclare @month datetime = '2015-08-01';Declare @endmonth datetime = '2021-01-01'WHILE @month < @endmonthBEGINSet NoCount On;Declare @prevMonth datetime = DateAdd(Month, -1, @month);Declare @nextMonth datetime = DateAdd(Month, 1, @month);Declare @monthTable sysname = 'Logs_' + Cast(DatePart(Year, @month) as varchar) + '_' + Right('0' + Cast(DatePart(Month, @month) as varchar), 2);Begin Try If Object_Id(@monthTable, 'U') Is Not Null Begin Declare @error nvarchar(400) = 'Month ' + Convert(varchar(10), @month, 120) + ' has already been moved to ' + @monthTable + ', aborting.'; Throw 501337, @error, 1; Return; End -- Table Creation Declare @tableTemplate nvarchar(4000) = ' Create Table {Name} ( [CreationDate] datetime Not Null, <insert all the columns>, Constraint CK_{Name}_Low Check (CreationDate >= ''{LowerDate}''), Constraint CK_{Name}_High Check (CreationDate < ''{UpperDate}'') ) On {Filegroup}; Create Clustered Columnstore Index CCI_{Name} On {Name} With (Data_Compression = {Compression}) On {Filegroup};'; -- Constraints exist for metadata swap Declare @table nvarchar(4000) = @tableTemplate; Set @table = Replace(@table, '{Name}', @monthTable); Set @table = Replace(@table, '{Filegroup}', 'Logs_Archive'); Set @table = Replace(@table, '{LowerDate}', Convert(varchar(20), @month, 120)); Set @table = Replace(@table, '{UpperDate}', Convert(varchar(20), @nextMonth, 120)); Set @table = Replace(@table, '{Compression}', 'ColumnStore_Archive'); Print @table; Exec sp_executesql @table; Declare @moveSql nvarchar(4000) = 'Create Clustered Columnstore Index CCI_{Name} On {Name} With (Drop_Existing = On, Data_Compression = Columnstore_Archive) On Logs_Archive;'; Set @moveSql = Replace(@moveSql, '{Name}', @monthTable); Print @moveSql; Exec sp_executesql @moveSql;End TryBegin Catch Select Error_Number() ErrorNumber, Error_Severity() ErrorSeverity, Error_State() ErrorState, Error_Procedure() ErrorProcedure, Error_Line() ErrorLine, Error_Message() ErrorMessage; Throw;End Catchset @month = dateadd(month, 1, @month)ENDGO2.一个 LINQPad 脚本,从最早的一天开始遍历,并将数据插入到新表中
-- written by Nick Craver<Query Kind="Program"><NuGetReference>Dapper</NuGetReference><Namespace>Dapper</Namespace></Query>void Main(){ MoveDate(new DateTime(2015, 08, 1)); DateTime date = new DateTime(2015, 08, 1); while (date < DateTime.UtcNow) { MoveDate(date); date = date.AddDays(1); }}static readonly List<string> cols = new List<string> { "<col list>" };public void MoveDate(DateTime date){ var tableName = GetTableName(date); var destTable = GetDestTableName(date); $"Attempting to migrate {date:yyyy-MM-dd} f from {tableName} to {destTable}".Dump($"{date:yyyy-MM-dd}"); using (var conn = GetConn()) { int rowCount; try { rowCount = conn.QuerySingle<int>($"Select Count(*) From HAProxyLogs.dbo.{tableName};"); } catch (SqlException e) { (" Error migrating: " + e.Message).Dump(); return; } $" Summary for {date:yyyy-MM-dd}".Dump(); $" {rowCount:n0} row(s) in {tableName}".Dump(); var pb = new Util.ProgressBar($"{tableName} (0/{rowCount})"); pb.Dump(tableName + " copy"); Func<int> GetDestRowCount = () => conn.QuerySingle<int>($"Select Count(*) From {destTable} Where CreationDate >= @date And CreationDate < @date + 1;", new { date }); Action<long, int> UpdatePB = (copied, total) => { pb.Fraction = (double)copied / total; pb.Caption = $"{tableName} ({copied}/{total})"; }; var destRowCount = GetDestRowCount(); $" {destRowCount:n0} row(s) in {destTable}".Dump(); if (destRowCount > 0) { $"Rows found in destiation table - aborting!".Dump(); return; } var reader = conn.ExecuteReader($"Select {string.Join(",", cols)} From HAProxyLogs.dbo.{tableName};"); using (SqlConnection dest = GetConn()) { dest.Open(); using (SqlBulkCopy bc = new SqlBulkCopy(dest)) { bc.BulkCopyTimeout = 5*60; bc.BatchSize = 1048576; bc.NotifyAfter = 100000; bc.DestinationTableName = GetDestTableName(date); bc.SqlRowsCopied += (e, s) => UpdatePB(s.RowsCopied, rowCount); foreach (var c in cols) { bc.ColumnMappings.Add(c, c); } try { bc.WriteToServer(reader); } catch (Exception ex) { Console.WriteLine(ex.Message); } finally { reader.Close(); } } var destFinalCount = GetDestRowCount(); } }}public SqlConnection GetConn() => new SqlConnection(new SqlConnectionStringBuilder { DataSource = "servername", InitialCatalog = "TrafficLogs", IntegratedSecurity = true}.ToString());public string GetTableName(DateTime dt) => $"Log_{dt:yyyy_MM_dd}";public string GetDestTableName(DateTime dt) => $"HAProxyLogs_{dt:yyyy_MM}";理想情况下,这是很简单的事情,但现实总是没那么完美的。
我于 2019 年 1 月 14 日在科罗拉多州开始进行迁移。从机械硬盘中提取数百万行数据,然后将其重新插入到同样硬盘上的新表中,这个速度太慢了。我原打算先完成这边迁移工作,然后再做纽约的迁移工作,但是大约一周后,我就开始了纽约服务器的数据迁移,以节省时间。
数据迁移问题
我遇到了很多问题,有的很简单,而有的就很难了。
脚本超时
第一个问题是 C#脚本。在查询数据库时,脚本会定期超时。调整设置后,我希望它在大多数情况下都能继续工作。
随机脚本错误
接下来,我遇到一个问题:如果出现错误,脚本将继续到下一张表,也就是下一天的表上。这很糟糕,因为我们希望按日期顺序为集群的列存储索引插入数据。如果脚本出错并转移到下一天,则需要对尚未结束的那一天执行清理。然后,我必须为了那么一天而重新开始。
你可能想知道我所说的“清理”是什么意思。
原始的表结构(也称为每日表)是具有通用标识(ID)列的行存储,以确保每一行都是唯一的。14 天后,我们将从表中删除主键,并添加集群的列存储索引。即使发生了向集群化列存储的迁移,ID 列也将保留。
在新表中,我们删除了 ID 列。这就是说试图弄清在故障前插入的行的唯一性会非常困难。发生故障时,还不如删除当天表中的所有内容以及该日之后的所有内容(如果已移动到另一个表中),然后重新启动该过程,结果会容易很多。
数据验证
我需要验证插入新表中的总行数是否与旧的每日表中的总行数匹配。
原始表是按天记录的,但是在某些情况下,表中可能不包含date 00:00-23:59的数据,而可能包含date+1的某些行。这是一个已知问题(来自 HAProxy 的日志延迟),我被告知总数不必完全匹配——如果我们丢失了一些行,也不是大问题。可当你负责将数据从一个系统移至另一个系统时,你确实希望一切都能完美匹配。
由于来自不同日期的混乱情况,我不能只查询旧表中的总行并验证新表是否包含相同的计数。我必须想出一种按天查询计数的方法。为此,我向新表中添加了一个名为OriginalLogTable的列,然后使用旧表的名称填充它,例如Log_2019_07_01。这样,我就可以按OriginalLogTable分组来对比旧表和新表中的行数。这解决了我的问题,当我完成一个月的迁移后,可以使用以下脚本轻松地验证新旧表之间的每一天是否匹配:
if object_id('tempdb..#NewTableDetails') is not null drop table #NewTableDetails create table #NewTableDetails ( TrafficLogOrigTable varchar(50), TrafficLogTotalRows bigint, OriginalLogDate date) if object_id('tempdb..#LogDetails') is not null drop table #LogDetails create table #LogDetails (LogDate date, OriginalTotalRows bigint) declare @sql nvarchar(max) = ''declare @startdate datetime = '2019-10-01' declare @enddate datetime = '2019-11-01' if object_id('tempdb..#dates') is not null drop table #dates; CREATE TABLE #dates( [Date] DATE PRIMARY KEY, FirstOfMonth AS CONVERT(DATE, DATEADD(MONTH, DATEDIFF(MONTH, 0, [Date]), 0)), OldTableName as concat('Log_', year([date]), '_', right('0' + rtrim(month([date])), 2), '_', right('0' + rtrim(day([date])), 2)), NewTableName as concat('HAProxyLogs_', year([date]), '_', right('0' + rtrim(month([date])), 2))); INSERT #dates([Date]) SELECT dFROM( SELECT d = DATEADD(DAY, rn - 1, @StartDate) FROM ( SELECT TOP (DATEDIFF(DAY, @StartDate, @enddate)) rn = ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id] ) AS x) AS y; -- for each new table name get the count of rows, get list of OldTables -- Imported and then get the counts for each onedeclare @newtablename nvarchar(100)declare @date datetimedeclare newtable_cursor cursor for select distinct NewTableName from #dates where [date] < @enddateopen newtable_cursor fetch next from newtable_cursor into @newtablename while @@FETCH_STATUS = 0begin set @sql = 'insert into #NewTableDetails (TrafficLogOrigTable, TrafficLogTotalRows) select TrafficLogOrigTable = OriginalLogTable, TrafficLogTotalRows = count(*) from TrafficLogs.dbo.[' + @newtablename +'] group by OriginalLogTable '; exec sp_executesql @sql FETCH NEXT FROM newtable_cursor INTO @newtablenameendCLOSE newtable_cursor DEALLOCATE newtable_cursor update #NewTableDetailsset OriginalLogDate = Cast(Replace(Replace(TrafficLogOrigTable, 'Log_', ''), '_', '-') as date) declare @oldTableName nvarchar(100)declare @oldtabledate datedeclare table_cursor cursor for select OriginalLogDate, TrafficLogOrigTable from #NewTableDetailsopen table_cursor fetch next from table_cursor into @oldtabledate, @oldTableName while @@FETCH_STATUS = 0begin set @sql = 'insert into #LogDetails (LogDate, OriginalTotalRows) select LogDate = '''+ convert(varchar(10), @oldtabledate, 23) +''', OriginalTotalRows = count(*) from HAProxyLogs.dbo.[' + @oldTableName +']'; exec sp_executesql @sql FETCH NEXT FROM table_cursor INTO @oldtabledate, @oldTableNameendCLOSE table_cursor DEALLOCATE table_cursor select nt.OriginalLogDate, nt.TrafficLogOrigTable, nt.TrafficLogTotalRows, ot.OriginalTotalRows, ot.LogDate, IsMatch = case when nt.TrafficLogTotalRows = ot.OriginalTotalRows then 'Y' else 'N' endfrom #NewTableDetails ntfull join #LogDetails ot on nt.OriginalLogDate = ot.LogDateorder by nt.OriginalLogDate列更改
我还发现,原始的每日表的设计不是一成不变的,后来还添加了新列。这意味着在数据迁移过程中表结构将发生变化。我调整了 LinqPad 脚本,以便在需要时根据日期添加新列,这将确保它能正常运行下去和我们不会跳过新列。
还有更多涉及脚本调试的问题,到最后解决所有问题的新脚本变成这个样子:
<Query Kind="Program"> <NuGetReference>Dapper</NuGetReference> <Namespace>Dapper</Namespace></Query> void Main(){ DateTime date = new DateTime(2016, 07, 26); while (date < DateTime.UtcNow) { MoveDate(date); date = date.AddDays(1); }} static readonly List<string> cols = new List<string> { "<col list>" }; public void MoveDate(DateTime date){ var tableName = GetTableName(date); var destTable = GetDestTableName(date); $"Attempting to migrate {date:yyyy-MM-dd} from {tableName} to {destTable}".Dump($"{date:yyyy-MM-dd}"); if (date >= new DateTime(2017, 01, 12)) { cols.Add("new col1"); cols.Add("new col2"); } using (var conn = GetConn()) { int rowCount; try { rowCount = conn.QuerySingle<int>($"Select Count(*) From HAProxyLogs.dbo.{tableName};"); } catch (SqlException e) { (" Error migrating: " + e.Message).Dump(); return; } $" Summary for {date:yyyy-MM-dd}".Dump(); $" {rowCount:n0} row(s) in {tableName}".Dump(); var pb = new Util.ProgressBar($"{tableName} (0/{rowCount})"); pb.Dump(tableName + " copy"); Func<int> GetDestRowCount = () => conn.QuerySingle<int>($"Select Count(*) From {destTable} Where CreationDate >= @date And OriginalLogTable = '{tableName}';", new { date }); Action<long, int> UpdatePB = (copied, total) => { pb.Fraction = (double)copied / total; pb.Caption = $"{tableName} ({copied}/{total})"; }; var destRowCount = GetDestRowCount(); $"There are {destRowCount:n0} row(s) for table: {destTable}".Dump(); if (destRowCount > 0) { $"Rows found in destination table - aborting!".Dump(); return; } var sqlString = $"Select {string.Join(",", cols)}, OriginalLogTable = '{tableName}' From HAProxyLogs.dbo.{tableName};"; var reader = conn.ExecuteReader(sqlString); using (SqlConnection dest = GetConn()) { dest.Open(); using (SqlBulkCopy bc = new SqlBulkCopy(dest)) { bc.BulkCopyTimeout = 15*60; bc.BatchSize = 1048576; bc.NotifyAfter = 100000; bc.DestinationTableName = GetDestTableName(date); bc.SqlRowsCopied += (e, s) => UpdatePB(s.RowsCopied, rowCount); foreach (var c in cols) { bc.ColumnMappings.Add(c, c); } try { bc.ColumnMappings.Add("OriginalLogTable", "OriginalLogTable"); bc.WriteToServer(reader); } catch (Exception ex) { Console.WriteLine(ex.Message); } finally { reader.Close(); } } // try updating stats after full dump to see if that stops time-outs var statsString = $"waitfor delay '00:00:05'; update statistics dbo.[{destTable}] [{destTable}_OriginalLogTable];"; conn.Query(statsString); var destFinalCount = GetDestRowCount(); $"After migration there are {destFinalCount:n0} row(s) in {destTable}".Dump(); } }} public SqlConnection GetConn() => new SqlConnection("Data Source=servername;Initial Catalog=TrafficLogs;Trusted_Connection=True;Connection Timeout = 1500;"); public string GetTableName(DateTime dt) => $"Log_{dt:yyyy_MM_dd}";public string GetDestTableName(DateTime dt) => $"HAProxyLogs_{dt:yyyy_MM}";太慢了
我们都知道这将是一个缓慢的过程,可那也太慢了。
将每个旧表插入新表大约需要 2-2.5 个小时。到 2 月中旬,我还剩:
纽约的 1332 个表要迁移;
在科罗拉多州还剩 782 张表
这样下去,我还要花几个月的时间才能完成。
我想做点什么来更快地移动数据。步骤是不变的——插入旧数据,验证行数匹配,移至第二天,重复。我尝试了很多不同的方法,但都没有很快:
一个 SSIS 包——这个速度甚至更慢;
使用动态 SQL 的 SQL 脚本——这也相当慢;
declare @startDate datetime = '2015-11-01'declare @endDate datetime = '2015-12-01'declare @OldTableName varchar(100)declare @NewTableName varchar(100)declare @cols varchar(max) = 'comma, separated, col, list'declare @originalrowcount intdeclare @newrowcount intdeclare @finalrowcount intdeclare @rowcountsql nvarchar(max)declare @insertsql nvarchar(max)declare @statssql nvarchar(max)while @startDate < @endDatebeginset @OldTableName = concat('Log_', year(@startDate), '_' , right('0' + rtrim(month(@startDate)), 2), '_' , right('0' + rtrim(day(@startDate)), 2))set @NewTableName = concat('HAProxyLogs_', year(@startDate), '_' , right('0' + rtrim(month(@startDate)), 2))print concat('Attempting to migrate ', convert(varchar(10), @startDate, 120) , ' from ', @OldTableName, ' to ', @NewTableName)print ' 'if @startDate >= '2017-01-12' begin if (charindex('new col1', @cols) = 0) begin set @cols = concat(@cols, ', new col1') end if (charindex('new col2', @cols) = 0) begin set @cols = concat(@cols, ', new col2') end endset @rowcountsql = concat('select @cnt = count(*) from HAProxyLogs.dbo.[', @OldTableName, ']');exec sp_executesql @rowcountsql, N'@cnt int output', @cnt = @originalrowcount output;/*print concat('Summary for ', convert(varchar(10), @startDate, 120) , ' ', @originalrowcount, ' rows in ', @OldTableName);print ' 'print concat('Starting copy of ', @OldTableName);print ' '*/-- check if the new table has any rows in itset @rowcountsql = concat('select @cnt = count(*) from ', @NewTableName , ' where CreationDate >= ''', convert(varchar(10), @startDate, 120) , ''' and OriginalLogTable = ''', @OldTableName, ''';')--print @rowcountsqlexec sp_executesql @rowcountsql, N'@cnt int output', @cnt = @newrowcount output;print concat('There are ', @newrowcount, ' row(s) for table: ', @NewTableName);print ' 'If @newrowcount > 0 begin print 'Rows found in the destination table - aborting' print ' ' break; endset @insertsql = concat('insert into TrafficLogs.dbo.', @NewTableName, '(', @cols, ', OriginalLogTable) select ', @cols, ', OriginalLogTable = ''', @OldTableName, ''' from HAProxyLogs.dbo.', @OldTableName);print @insertsqlprint ' 'exec sp_executesql @insertsql;set @statssql = concat('update statistics TrafficLogs.dbo.', @NewTableName , ' ', @NewTableName, '_OriginalLogTable');print @statssqlprint ' 'exec sp_executesql @statssqlset @rowcountsql = concat('select @cnt = count(*) from ', @NewTableName , ' where CreationDate >= ''', convert(varchar(10), @startDate, 120) , ''' and OriginalLogTable = ''', @OldTableName, ''';')exec sp_executesql @rowcountsql, N'@cnt int output', @cnt = @finalrowcount output;print concat('After migration there are ', @finalrowcount, ' row(s) in the ', @NewTableName);If @originalrowcount <> @finalrowcount begin print 'final row does not match original stopping operation'; print ' ' break; endset @startDate = dateadd(day, 1, @startDate)ENDPowerShell 版本——也很慢,但似乎比原始的 C#脚本更稳定;
<# .SYNOPSIS Traffic Log Data Migration .EXAMPLE .\DataMigration.ps1 -ServerName name -StartDate 2019-01-01 -EndDate 2019-02-01#>[CmdletBinding()] #See http://technet.microsoft.com/en-us/library/hh847884(v=wps.620).aspx for CmdletBinding common parametersparam( [parameter(Mandatory = $true)] [string]$ServerName, [parameter(Mandatory = $true)] [DateTime]$StartDate, [parameter(Mandatory = $true)] [DateTime]$EndDate)# taken from https://blog.netnerds.net/2015/05/getting-total-number-of-rows-copied-in-sqlbulkcopy-using-powershell/$source = 'namespace System.Data.SqlClient{ using Reflection; public static class SqlBulkCopyExtension { const String _rowsCopiedFieldName = "_rowsCopied"; static FieldInfo _rowsCopiedField = null; public static int RowsCopiedCount(this SqlBulkCopy bulkCopy) { if (_rowsCopiedField == null) _rowsCopiedField = typeof(SqlBulkCopy).GetField(_rowsCopiedFieldName, BindingFlags.NonPublic | BindingFlags.GetField | BindingFlags.Instance); return (int)_rowsCopiedField.GetValue(bulkCopy); } }}'Add-Type -ReferencedAssemblies 'System.Data.dll' -TypeDefinition $source$null = [Reflection.Assembly]::LoadWithPartialName("System.Data")Function ConnectionString([string] $ServerName, [string] $DbName){ "Data Source=$ServerName;Initial Catalog=TrafficLogs;Trusted_Connection=True;Connection Timeout = 2000;"}Function GetOriginalTableRowCount($sqlConnection, $table){ $sqlConnection.open(); $OriginalRowCountCmd = "select OriginalCount = count(*) from " + $table; $SqlCmd = New-Object System.Data.SqlClient.SqlCommand($OriginalRowCountCmd, $sqlConnection) $SqlCmd.CommandTimeout = 0; $row_count = [Int64] $SqlCmd.ExecuteScalar() $sqlConnection.Close(); return $row_count}Function GetNewTableRowCount($sqlConnection, $table){ $sqlConnection.open(); $RowCountCmd = "select NewCount = count(*) from " + $table + " where CreationDate >= '"+($i.ToString("yyyy-MM-dd")) +"' and OriginalLogTable = 'Log_"+($i.ToString("yyyy_MM_dd"))+"'"; $SqlCmd = New-Object System.Data.SqlClient.SqlCommand($RowCountCmd, $sqlConnection) $SqlCmd.CommandTimeout = 0; $row_count = [Int64] $SqlCmd.ExecuteScalar() $sqlConnection.Close(); return $row_count}$cols = "col1", "col2", "col3", "...";for ($i = $StartDate; $i -lt $EndDate; $i = $i.AddDays(1)){ $MigrationStart = Get-Date Write-Host "Migration started at: $MigrationStart" $OldTableName = "HAProxyLogs.dbo.Log_"+($i.ToString("yyyy_MM_dd")) $NewTableName = "TrafficLogs.dbo.HAProxyLogs_"+($i.ToString("yyyy_MM")) Write-Host "Attempting to migrate "($i.ToString("yyyy_MM_dd"))" from " $OldTableName " to " $NewTableName; # build the connection string and open it $SrcConnStr = ConnectionString $ServerName $SrcConn = New-Object System.Data.SqlClient.SQLConnection($SrcConnStr) # whats the row count on the original table in HAProxyLogs $originalRowCount = GetOriginalTableRowCount $SrcConn $OldTableName Write-Host "Summary for " ($i.ToString("yyyy-MM-dd"))": There are "$originalRowCount" rows in table "$OldTableName # make sure there is no data in the table currently for the day $newRowCount = GetNewTableRowCount $SrcConn $NewTableName if($newRowCount -gt 0){ Write-Host "Rows found in the destination table - aborting migration" break; } else { Write-Host "No data for the date in the destination table - continuing migration" } # select the data we need from the original table $selectCmdText = "select "+ ($cols -join ', ') +", OriginalLogTable = 'Log_"+($i.ToString("yyyy_MM_dd")) +"' from "+$OldTableName; $SqlCommand = New-Object system.Data.SqlClient.SqlCommand($selectCmdText, $SrcConn) $SqlCommand.CommandTimeout = 0; $SrcConn.Open() [System.Data.SqlClient.SqlDataReader] $SqlReader = $SqlCommand.ExecuteReader() $destConnection = ConnectionString $ServerName $bulkCopy = New-Object Data.SqlClient.SqlBulkCopy($destConnection) $bulkCopy.BatchSize = 1048576 $bulkCopy.BulkCopyTimeout = 0 # 20*60 $bulkCopy.DestinationTableName = $NewTableName $bulkCopy.NotifyAfter = 500000 # taken from https://blog.netnerds.net/2015/05/getting-total-number-of-rows-copied-in-sqlbulkcopy-using-powershell/ $bulkCopy.Add_SqlRowscopied( {Write-Host "$($args[1].RowsCopied)/$originalRowCount rows copied from $OldTableName to $NewTableName" }) foreach ($col in $cols){ $bulkCopy.ColumnMappings.Add($col,$col) } try { Write-Host "Starting Migration" $bulkCopy.ColumnMappings.Add("OriginalLogTable", "OriginalLogTable"); $bulkCopy.WriteToServer($SqlReader) $total = [System.Data.SqlClient.SqlBulkCopyExtension]::RowsCopiedCount($bulkcopy) Write-Host "$total total rows written" } catch { $ex = $_.Exception Write-Error $ex.Message While($ex.InnerException) { $ex = $ex.InnerException Write-Error $ex.Message } } Finally { $SqlReader.Close() $bulkCopy.Close() $SrcConn.Close() } # once done update statistics on the new table $statsCmdText = "update statistics "+$NewTableName +" HAProxyLogs_"+($i.ToString("yyyy_MM"))+"_OriginalLogTable"; Invoke-DbaQuery -SqlInstance $ServerName -Query $statsCmdText; Write-Host "After migration there are $total rows were written to $NewTableName table from $OldTableName"; if($originalRowCount -ne $total){ Write-Host "total rows migrated does not match. Stopping operation" break; } $total = 0;}我所有的选项都很慢。
最终,我使用了 PowerShell 选项,它可以很容易地并行执行多个月份的迁移。我有 3 个 PowerShell 会话,同时处理 3 个月的表。利用 PowerShell,我可以在更短时间内获取更多数据。它仍然很慢——每个会话用大约一个星期移动了大约一个月的表,但起码比以前快了。
虽然 PowerShell 脚本并不完美,我也还是会遇到超时和错误的问题,但总体上来说效果更好。现在,我有了一个不需要每天手动处理的工作流程,该关注一下迁移中的其他一些问题了。
没有可用磁盘空间的问题
我必须尽量释放空间,同时继续将所有数据移动到新格式。
删除和缩小
我们的新硬件还没到,而这些是生产型 SQL Server,意味着旧数据库仍在接收新数据,我们每天都在添加新表。当我将表移到新数据库时,旧数据库还在添加新表,其中有数以亿行的数据。服务器都是一样的,硬盘空间捉襟见肘。
每迁移一个月的表后,我会进行最后一次验证,然后做一些清理。这包括删除刚迁移的月份的所有每日表,以及从新数据库的月度表中删除OriginalLogTable列,腾出点空间。
我只是在同一硬盘上倒腾数据,所以腾出的空间很少。我们将格式从每日表更改为月度表,虽然新表获得了更好的压缩效果,但可用空间并没有增加很多。我们在更少的表中存储了相同数量的数据行,从长远来看这意味着更少的空间,但是为了多腾地方,我不得不缩小它们。

从旧文件中移出数据时,我也在增加新数据文件的大小。这都是在 E 盘上完成的,该分区已满 85-90%。
这就是像在走钢丝。
每个月的数据大小从 300GB 到 1TB 不等,三个旧数据文件每个大约 12TB。在每次迁移结束时,我都尝试将旧数据库文件缩小一些,减掉刚删除的部分。
一开始,我天真地尝试运行DBCC SHRINKFILE(FileName, TRUNCATEONLY)以释放空间。如我所料,没用。
接下来,我尝试在每个文件上运行DBCCSHRINKFILE(FileName, CurrentFileSize-SizeOfDataJustDeleted)。也不起作用。当你运行DBCCSHRINKFILE并想将文件缩小 300GB 时,需要同样大小的中转空间才行。由于我们已经限制了存储 t 日志的分区空间,因此我无法缩小文件,毕竟 D 盘已经没地方了。
我有几个选择来释放 D 盘上的空间——移动tempdb或将其他日志/数据库文件移动到我们新配置的具有 14TB 可用空间的 F 盘上。我决定移动tempdb,只需执行以下命令并重新启动 SQL 服务即可。
alter database tempdb modify file (NAME = tempdev, FILENAME = 'F:\Data\tempdev.mdf', SIZE = 20000MB);alter database tempdb modify file (NAME = templog, FILENAME = 'F:\Data\templog.ldf', SIZE = 1000MB);alter database tempdb modify file (NAME = tempdev2, FILENAME = 'F:\Data\tempdev2.mdf', SIZE = 20000MB);alter database tempdb modify file (NAME = tempdev3, FILENAME = 'F:\Data\tempdev3.mdf', SIZE = 20000MB);alter database tempdb modify file (NAME = tempdev4, FILENAME = 'F:\Data\tempdev4.mdf', SIZE = 1000MB);移动tempdb不需要很多停机时间,我获得了大约 122GB 的可用空间,只是还不够。尝试将文件压缩为 300GB 或更大的块会很慢,还会影响生产。我找到了一种看似有希望的方案,类似这个样子:
declare @from int declare @leap int declare @to int declare @datafile varchar(128)declare @cmd varchar (512)declare @starttime datetimedeclare @endtime datetime /*settings*/ set @from = 13533200 /*Current size in MB*/set @to = 11600000 /*Goal size in MB*/ set @datafile = 'HAProxyLogs1' /*Datafile name*/set @leap = 10000 /*Size of leaps in MB*/ while ((@from - @leap) > @to) begin set @starttime = getdate() print concat('started: ', @starttime) set @from = @from - @leap set @cmd = 'DBCC SHRINKFILE (' + @datafile +', ' + cast(@from as varchar(20)) + ')' print @cmd exec(@cmd) print '==> SHRINK SCRIPT - '+ cast ((@from-@to) as varchar (20)) + 'MB LEFT' set @endtime = getdate() print concat('ended: ', getdate(), ' took :' , datediff(minute, @starttime, @endtime)) end set @cmd = 'DBCC SHRINKFILE (' + @datafile +', ' + cast(@to as varchar(20)) + ')'print @cmdexec(@cmd)我分别针对每个文件运行脚本,以从已删除月份中完全恢复磁盘空间。它很慢,但是有效。
使用新硬盘
设置新的 TrafficLogs 数据库时,我将带有存档文件(正在迁移的旧文件)的数据文件放到了机械硬盘分区上。我们没有考虑使用有 14TB 可用空间的新 F 盘,主要是因为它不足以完成整个迁移。但是几周后,出于以下几个原因,我决定使用这个硬盘:
它们是 NVMe SSD,速度比机械硬盘快很多;
它大约有 14TB 的可用空间,这样,我可以移动大量数据,无需当时就缩小。我可以用磁盘空间来避免一些麻烦。
不幸的是,这样做的唯一问题是,一旦我填满了 14TB 的磁盘空间,我就不得不将数据文件全部迁移回机械硬盘。2019 年 3 月末,我就这么干了。
硬盘,请坚持住
在 2019 年 5 月初,我还在努力迁移数据。这时我的流程回到了原点——从机械硬盘上的旧数据库复制数据,将其插入新数据库,删除旧数据,然后缩小文件,一切工作都在同样的硬盘上完成。
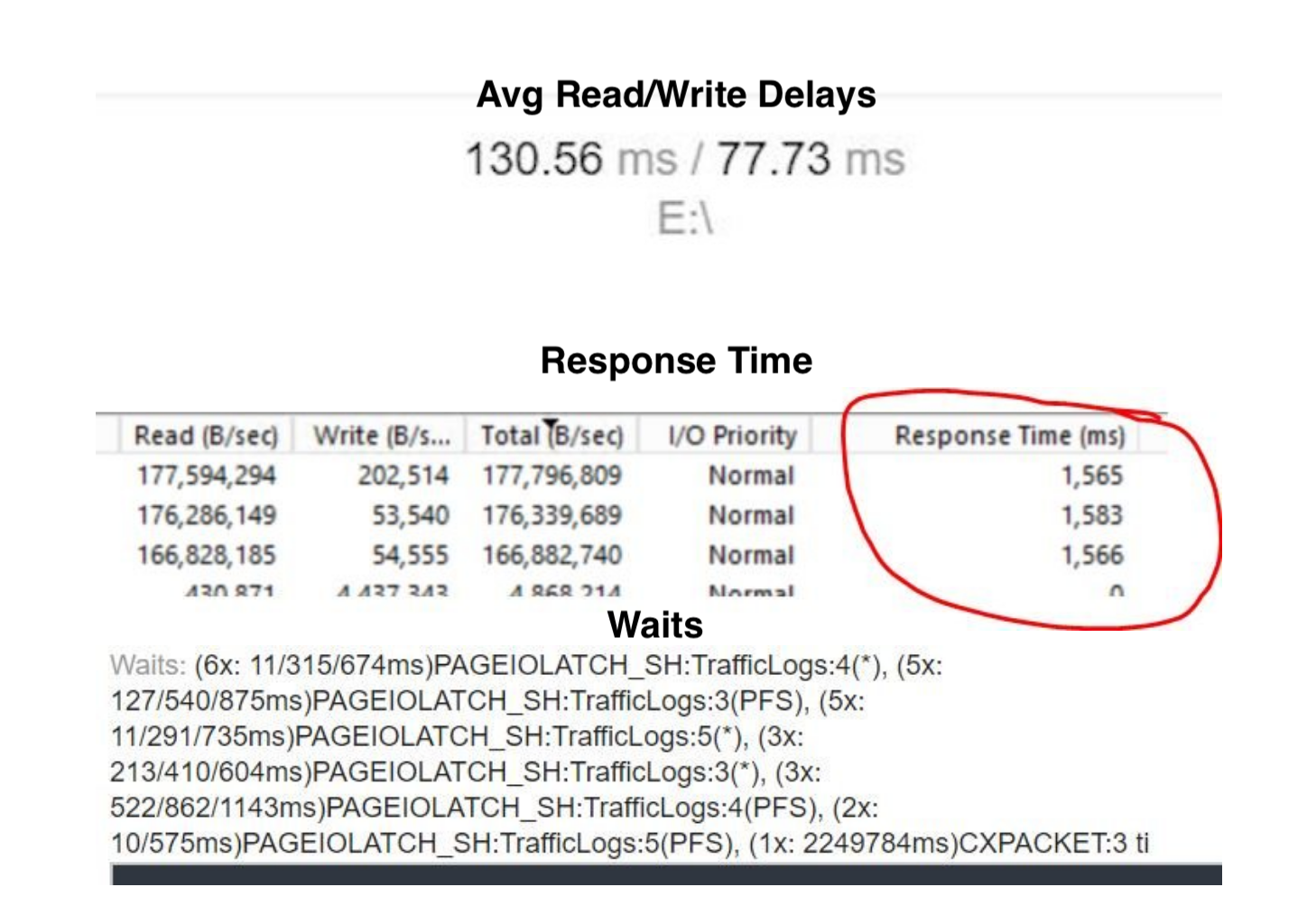
几个月来,我发现这一过程明显减慢了。自一月份以来,硬盘上的读/写延迟有所增加。读取的平均延迟超过 100 毫秒,而写入大约为 80 毫秒。
总体响应时间非常糟糕。
当我尝试将数据插入新表时,总会遇到PAGEIOLATCH_SH等待。
我们使用那些机械硬盘已有数年之久,而 4 个月的迁移工作让它们不堪重负。我非常担心硬盘在完成所有数据迁移之前会出现故障。
所幸,坏事没发生。全部迁移工作用了 6 个月时间。
但事情还没完。我们还是没有新的服务器,这意味着新服务器和数据库到位后,前面创建的每个表都需要迁移。
新硬件终于来了
原计划是在 6 月/7 月获得新服务器,但结果推迟了几个月。为尽量简化新硬件的迁移任务,从 6 月到 9 月底,我每天迁移一个表以保持最新状态。
在 10 月初,新服务器已经准备好安装 SQL Server,任务快完成了。
最后两台机器都安装了 SQL Server 2017。现在是时候将巨型数据库迁移过去了。
备份和还原失败
当然,将数据库从旧服务器移动到新服务器的最直接方法是备份然后还原。我也这么尝试了,在备份时设置了脚本以将其写到新服务器上。但不幸的是,备份占用了大部分空间,结果我没有足够的临时空间还原它,太尴尬了。
再一次复制表
由于我无法做备份和还原,因此我只能一个个迁移表,像之前一年所做的一样。
我将在同一数据中心和机架中的服务器之间进行迁移,因此我想看看将数据从旧数据库批量插入到新数据库中有多快。我尝试了各种方法:
SSIS 版本——2.5 天
OPENROWSET——用 16 小时移动了 6.5 亿行
PowerShell 胜出。
是时候尝试可用性组了
我非常不想再次迁移几百个表,因此我提出了一个想法,使用可用性组(availability group)将数据库自动播种到新服务器。我们在整个基础架构中有了 AG,因此很熟悉它的用法,但我不确定它是否可以成功用于这么大规模的数据库。
我决定首先在科罗拉多服务器上设置 AG,如果成功就在纽约复制经验。需要完成以下步骤:
对两台服务器设置新的 Windows 故障转移群集
再备份一次,因为数据库处于简单恢复状态而不是完全恢复状态,所以我无法使用第一个备份。这意味着还要等待 11.5 个小时来完成科罗拉多州 33TB 数据库的备份。
设置 AG 并等待它播种
启动故障转移到新服务器
销毁 AG 并关闭旧服务器
在科罗拉多州完成备份后,我意识到尝试自动播种时可能会有一个小问题。文档说:
自动播种要求参与可用性组的每个 SQL Server 实例上的数据和日志文件路径都相同
旧服务器的数据分别在 E 盘和 F 盘上,而新服务器用的是 D 盘。为了避免出问题,我迅速将新服务器上的分区重命名为 E,并使用以下命令将文件移到了上面:
use [master]alter database [TrafficLogs] modify file(name= TrafficLogs_Current, filename = 'E:\Data\TrafficLogs_Current.mdf');alter database [TrafficLogs] modify file(name= TrafficLogs_log, filename = 'E:\Data\TrafficLogs_log.ldf');于是我还必须将tempdb移至新分区,完成所有操作后就该尝试设置 AG 了。
我在科罗拉多州建立了临时 AG,等待 SQL Server。我一直在检查两个 DMV:sys.dm_hadr_automatic_seeding和sys.dm_hadr_physical_seeding_stats,以查看播种过程的状态。大约 6 个小时后,我们播种了大约 17TB 的数据库。
从对网络流量的 SignalFX 监控中,我们还可以看到正在发生某些事情。下面的 SignalFX 图表显示,我们到一个盒的平均流量为 150-180Mb/sec,全都是数据库播种。
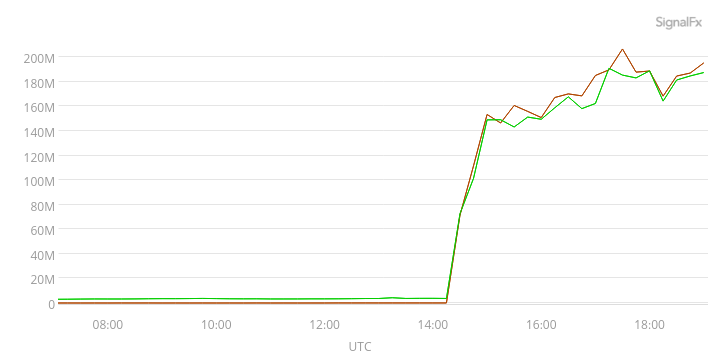
到第二天早上,播种工作已经结束,我们在新的科罗拉多服务器上有了一个包含所有表的数据库。
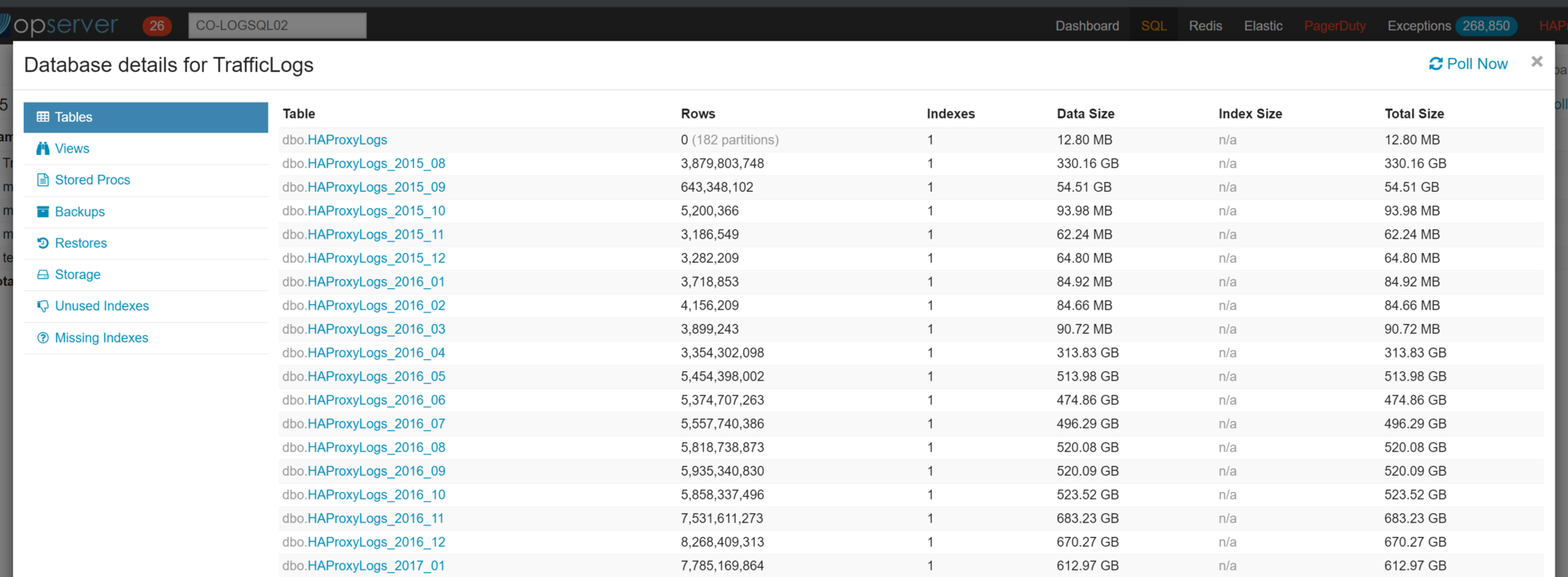
在启动故障转移之前,我在 AG 中的新服务器(也称为第二服务器)上运行了DBCCCHECKDB,以确保数据库处于良好状态。22 小时后报告完成,未遇到任何问题。
是时候进行故障转移了。
所有这些工作在科罗拉多州进行时,我在纽约服务器上也启动了该过程。在花了 41 个小时备份 40TB 数据库后,我准备在纽约服务器上执行所有相同的步骤。我设置了群集、可用性组,播种数据库,运行了很长的 DBCCCHECKDB,并成功完成了故障转移。
最艰难的部分已经完成,但还有一些收尾工作要做。
最终清理
我们终于在数据库中安装了新服务器,但是还没有新的流量日志数据流到新服务器。发送流量日志的服务(流量处理服务,又称为 TPS)仍指向旧数据库。这样做是有目的的,以免打断任何使用数据的团队。我们的想法是,一旦服务器就位,我们就可以并行发布新版本,在一段时间段内在两个位置推送数据(从 HAProxy 向两个服务器发送系统日志流量)。这将允许团队逐步将其流程移植到新的数据库和表结构。
故障转移后的一周,我们发布了新的流量处理服务,而我又从旧服务器迁移了几天的数据。我还销毁了可用性组和 Windows 故障转移群集。完成所有步骤后,终于可以庆祝了。
总结
在 Stack Overflow 担任 DBA 的这段时间里,我有机会从事各种大型项目,但只有这个花了这么长时间。所有的迁移、验证、删除和调整空间工作总计花费了大约 11 个月的时间。
老实说,我喜欢接手这些大项目。计划整个项目,并从头到尾完成任务是非常激动人心的。虽然我将大部分工作都自动化了,但这个项目还是太累人了,我绝对不想在近期内再做一次(除非我有足够的硬盘空间,用不着花 11 个月的时间干杂事)。这个项目在许多方面都具有挑战性,考虑到我必须在两台服务器上做同样的工作,这就变成了双重挑战。最后,我很高兴能成功使用一个可用性组将数据库播种到新服务器上,并且很高兴最后所有数据都完成了迁移。
原文链接:
https://www.tarynpivots.com/post/migrating-40tb-sql-server-database/




