

Open Distro for Elasticsearch 的 Performance Analyzer 插件显示从 Elasticsearch 集群返回指标的 REST API。要充分利用这些指标,您可以将它们存储在 Elasticsearch 中,并使用 Kibana 对其进行可视化。尽管您可以使用 Open Distro for Elasticsearch 的 PerfTop 来构建可视化效果,但 PerfTop 不会保留数据,这意味着它为轻量级。
在本博文中,我将通过一个代码示例探索 Performance Analyzer 的 API,该代码读取 Performance Analyzer 的指标并将其写入 Elasticsearch。您可能会想知道为什么 Performance Analyzer 还没有这样做(欢迎您发起 Pull Request!)。Performance Analyzer 设计为 Elasticsearch 的轻量级协同进程。如果您的 Elasticsearch 集群有问题,则它可能无法响应请求,并且 Kibana 可能无法正常工作。如果采用示例代码,建议将数据发送到不同的 Open Distro for Elasticsearch 集群以避免出现此问题。
您可以遵循我在 GitHub 社区存储库中发布的示例代码。当您克隆存储库时,代码位于 pa-to-es 文件夹中。有关其他代码示例的信息,请参阅往期博客文章。
代码概述
pa-to-es 文件夹包含三个 Python 文件(需要 Python 版本 3.x)和一个 Elasticsearch 模板,该模板将 @timestamp 字段的类型设置为 date。main.py 是一个应用程序,包含调用 Performance Analyzer 的无限循环,以进行提取指标、解析这些指标并将其发送到 Elasticsearch:
如您所见,main.py 提供 MetricGatherer 和 MetricWriter 两个类别,以与 Elasticsearch 进行通信。MetricGatherer.get_all_metrics() 将遍历 metric_descriptions.py(每个都调用 get_metric())中的运行指标说明。
要获取指标,MetricGatherer 将生成表单的 URL:
http://localhost:9600/_opendistro/_performanceanalyzer/metrics?metrics=&dim=&agg=&nodes=all
(您可以在我们的文档中获取有关 Performance Analyzer API 的更多详细信息。) 指标说明是 namedtuple,提供指标/维度/聚合三元组。发送多个项目的效率会更高,但我发现解析结果要复杂得多,这使得任何性能提升都不那么重要。为了确定指标说明,我生成了指标/维度/聚合的所有可能组合,测试运行说明并将其保留在 metric_descriptions.py 中。比较好的做法是构建可显示有效组合的 API,而不是从静态描述集进行运行(正如我前面提到的,我们欢迎大家发起 Pull Request)。
MetricGatherer 使用 result_parse.ResultParser 解释对 Performance Analyzer 的调用的输出。输出 JSON 的每个节点包含一个元素。在该元素中,它返回 fields 列表,后跟一组 records:
ResultParser 将分离的字段名称和值压缩在一起,生成一个 dict,跳过空值。records 生成器函数使用此 dict 作为其返回的基础,添加来自原始返回正文的时间戳。records 还将节点名称和聚合作为字段添加到 dict 中,以便在 Kibana 中可视化数据。
MetricWriter 关闭循环,同时收集 dict 并将其作为文档写入 Elasticsearch,构建 _bulk 正文,然后通过 POST 请求批量写入 Elasticsearch。编写时,代码为硬连线,以将 _bulk 发送至 https://localhost:9200。实际上,您需要更改输出以转到不同的 Elasticsearch 集群。POST 请求的身份验证为 admin:admin,请确保在更改 Open Distro for Elasticsearch 的密码时对其进行更改。
将模板添加到集群
您可以按如上所述方式运行代码,您将看到数据流入 Open Distro for Elasticsearch 集群。但是,Performance Analyzer 返回的时间戳是长整数,Elasticsearch 会将映射设置为 number,您将无法对索引使用 Kibana 基于时间的函数。我可以截取时间戳或重写时间戳,以便自动检测映射。我选择了设置模板。
以下模板(pa-to-es 文件夹中的 template.json)将 @timestamp 的字段类型设置为 date。在发送任何数据、自动创建索引之前,您需要将此模板发送到 Elasticsearch。(如果您已经运行了 pa-to-es,请不要担心,只需删除它创建的任何索引。) 您可以使用 Kibana 开发人员窗格将模板发送到 Elasticsearch。
导航至 https://localhost:5601。登录、关闭启动画面,然后选择 DevTools 选项卡。单击 Get to work。复制以下文本并粘贴到交互式窗格中,然后单击右侧的三角形。(根据您运行的 Elasticsearch 版本,您可能会收到有关类型删除的警告。您可以忽略此警告。)
监控 Elasticsearch
我运行 esrally,通过 http_logs 跟踪我的 Open Distro for Elasticsearch,还运行 main.py 来收集指标。然后,我使用这些数据构建了一个 Kibana 控制面板,用于监控我的集群。
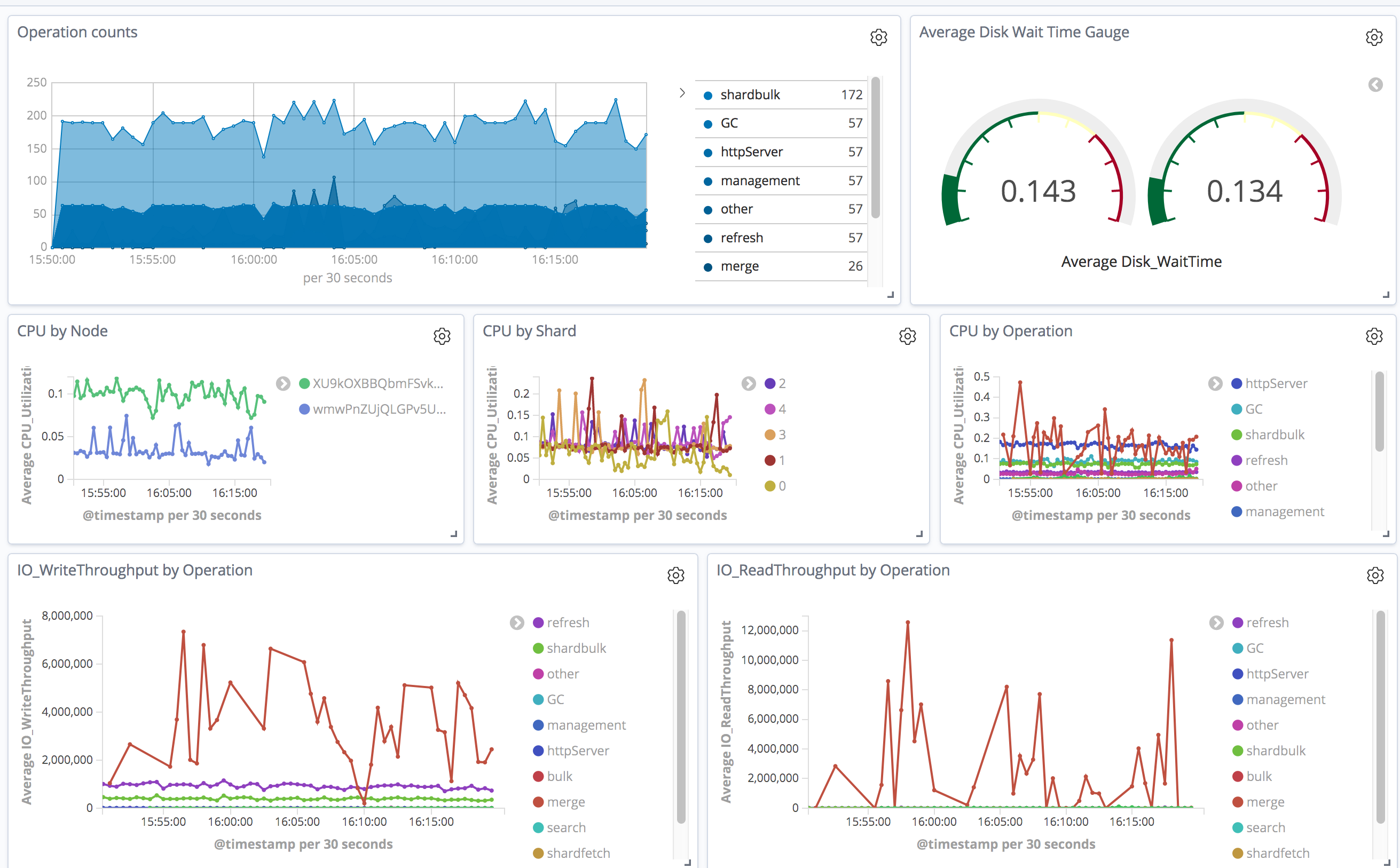
显示 Open Distro for Elasticsearch Performance Analyzer 插件收集的指标的 Kibana 控制面板
小结
Elasticsearch 文档中存储的指标具有单个指标/维度/聚合组合,让您可以自由地以最精细的粒度构建 Kibana 可视化效果。例如,我的控制面板将 CPU 利用率细化到 Elasticsearch 操作级别、每个节点上的磁盘等待时间,以及每个操作的读写吞吐量。在随后的博文中,我将深入探讨如何使用 Performance Analyzer 数据构建控制面板和其他可视化效果。
作者介绍:
Jon Handler
Jon Handler (@_searchgeek) 是总部位于加利福尼亚州帕罗奥图市的 Amazon Web Services 的首席解决方案架构师。Jon 与 CloudSearch 和 Elasticsearch 团队密切合作,为想要将搜索工作负载迁移到 AWS 云的广大客户提供帮助和指导。在加入 AWS 之前,Jon 作为一名软件开发人员,曾为某个大型电子商务搜索引擎编写代码长达四年。Jon 拥有宾夕法尼亚大学的文学学士学位,以及西北大学计算机科学和人工智能理学硕士和博士学位。
本文转载自 AWS 技术博客
文章链接:


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论