

01 Elasticsearch 广泛使用带来的成本问题
Elasticsearch(下文简称“ES”)是一个分布式的搜索引擎,还可作为分布式数据库来使用,常用于日志处理、分析和搜索等场景;在运维排障层面,ES 组成的 ELK(Elasticsearch+ Logstash+ Kibana)解决方案,简单易用、响应速度快,并且提供了丰富的报表;高可用方面, ES 提供了分布式和横向扩展;数据层面,支持分片和多副本。
ES 的使用便捷,生态完整,在企业之中得到了广泛的应用。随之而来的是物理资源和费用的增加,如何降低 ES 场景的成本成为了大家普遍关心的话题。
如何降低 ES 的成本
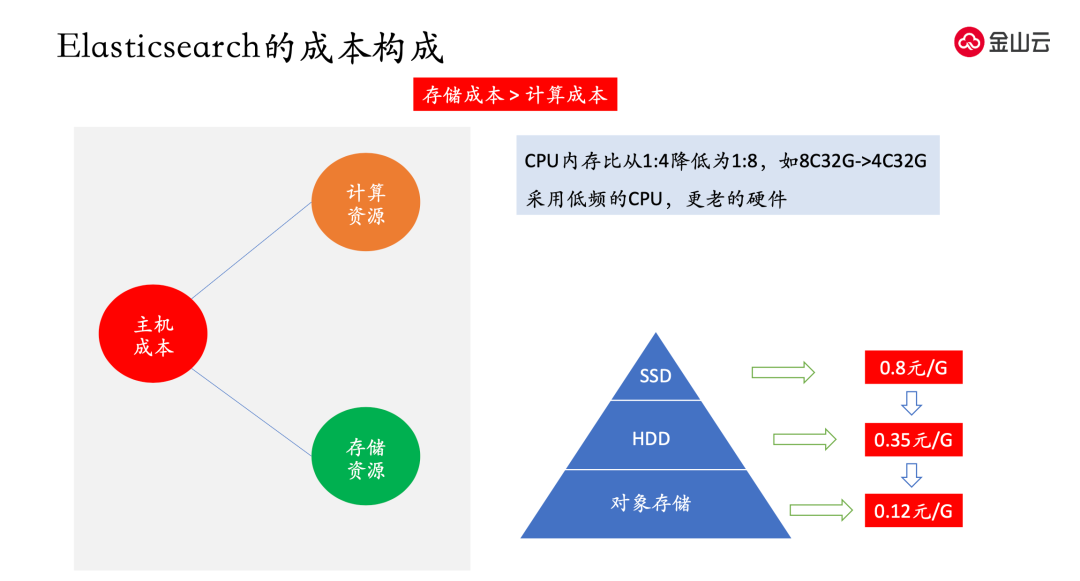
ES 的主要的成本是主机成本,主机成本又分为计算资源和存储资源。
计算资源简单理解就是 CPU 和内存,如果降低 CPU 和主机的数量,意味着计算能力会下降,因此通常会采用冷热节点;热节点使用高配的机器,冷节点使用低配的机器;比如 CPU 内存比从 1:4 降低为 1:8,如 8C32G->4C32G。但是没有降低内存,因为 ES 对内存有更高的需求,来提高响应速度。或者采用低频的 CPU,更老的硬件。
存储成本是远大于计算成本的,是要重点考虑的成本。现在的存储介质通常是 SSD 和 HDD 这种两种介质,在云厂商 SSD 的成本是 0.8 元/G,HDD 的成本是 0.35 元/G,对象存储的价格是 0.12 元/G。但前两种设备是块设备,提供的是文件系统的协议,但对象存储支持是 S3 协议的,彼此之间不兼容。
如何将对象存储和 ES 结合起来,我们调研了两种方案。
第一种方案,修改 ES 存储引擎,适配对象存储调用。这种方式需要修改 ES 的源码,团队要投入很多的人力来做开发设计调研以及最后的验证,投入产出比是非常低的。
第二种方案是将对象存储作为磁盘来使用,将其挂载到操作系统。把 ES 分为 hot 和 warm 节点。hot 节点存储热数据,挂载的是块设备。warm 节点使用对象存储。
02 对象存储文件系统选型
文件系统选型的时候主要考虑了三个方面。第一个是功能,首先要满足最基本的功能需求,第二个是性能,第三个是可靠性。我们调研了 s3fs、 goofys 和 JuiceFS。
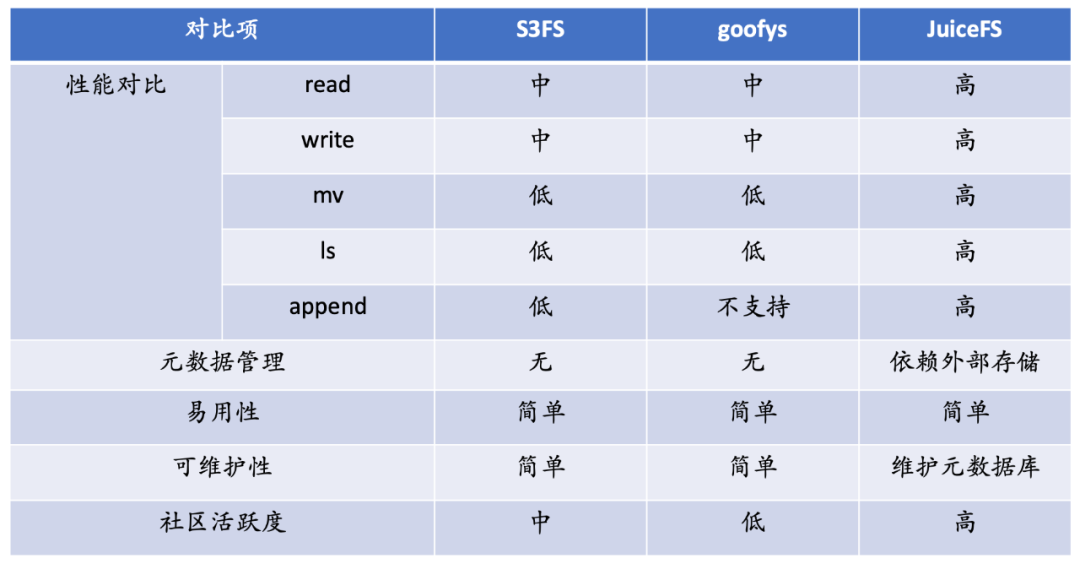
性能方面, s3fs 和 goofys 在 read 和 write 方面没有本地缓存,其性能是依靠 s3 的性能来支撑的,这两个文件系统整体的性能相比 JuiceFS 会低一些。
最明显的是 mv,对象存储没有 rename 操作,在对象存储中进行 rename 操作就是一个 copy 加 delete,性能代价是非常大的。
ls 方面,对象存储的存储类型是 kv 存储,不具备目录语义,所以 ls 整个目录结构对于 s3 来说,其实是对整个元数据的遍历,调用代价非常大。在大数据的场景下,性能是非常低的,并且有一些特性功能是不支持的。
元数据方面,s3fs 和 goofys 没有自己独立的元数据,所有的元数据都是依赖于 s3 的,JuiceFS 有自己的独立的元数据存储,
易用性方面,这几个产品都是非常简单易用,通过一个简单的命令就可以实现 s3 的挂载;从可维护性来说,JuiceFS 有自己的独立的元数据引擎,我们需要对元数据服务进行运维;从社区的角度来说,JuiceFS 的社区活跃度是最高的。基于以上综合考虑,金山云选择了 JuiceFS。
基于 JuiceFS 的测试
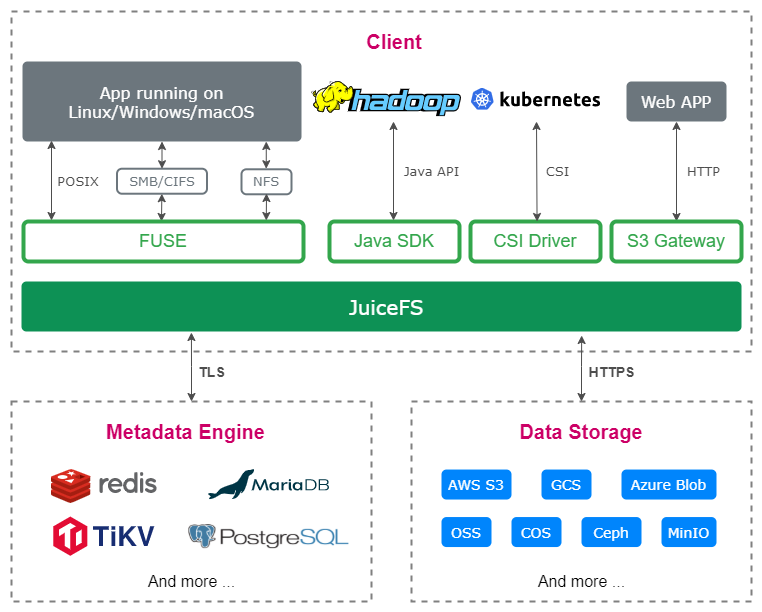
JuiceFS 产品介绍中第一句话就是 “像本地盘一样使用对象存储”,恰恰是我们做 ES 时所需要的功能。JuiceFS 已经集成了很多种对象存储,金山云的 KS3 也已经完整兼容,只需要再选一个元数据库即可。
第二功能验证。元数据库常用的有 Redis,关系型据库、 KV 数据库等。我们从这三个层面,元数据库支撑的数据量、响应速度、可运维性来做判断。

从数据量上来说,TiKV 无疑是最高的,但是我们的设计初衷是让每套 ES 集群独立一个元数据库实例,因此不同集群之间的元数据是不进行共享的,为了高可用彼此间需要互相隔离。
其次在响应速度方面, ES 把 JuiceFS 作为冷节点存储,冷节点存储的数据 IO 要比元数据的调用性能损耗更大,所以我们认为元数据的调用性能不是核心考虑的点。
从运维的角度来说,关系型数据库大家都比较熟,开发人员都可以很轻松的上手,其次公司是有公司有 RDS For MySQL 产品,有专业的 DBA 团队来负责运维,所以最终是选择了 MySQL 作为的元数据引擎。
JuiceFS 可靠性测试
元数据选型完以后,我们对 JuiceFS 进行了可靠性测试,JuiceFS 挂载到主机上只需要三步:第一步,创建文件系统,我们要指定 bucket 来确定它的 AK、SK 以及元数据库;第二步,把文件系统 mount 到磁盘上;第三步,把 ES 软链到 JuiceFS 的 mount 目录上。
虽然设计初衷是将 JuiceFS 作为冷节点,但是在测试的过程中,我们想用一种极限的方式来压测 JuiceFS。我们设计了两种极限压测。
第一个:将 JuiceFS + KS3 挂载到 hot 节上,把数据实时写到 JuiceFS 。
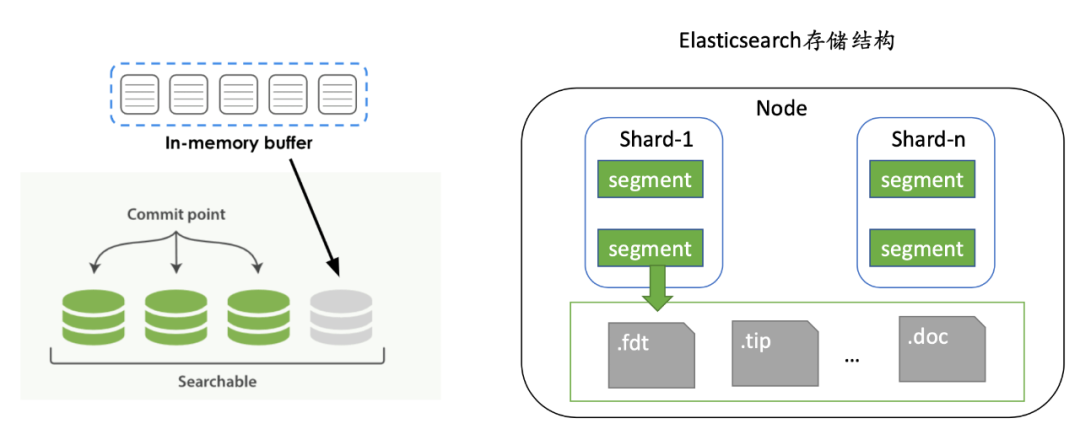
ES 的写入流程是先写到 buffer 中也就是内存里面,当内存满或者是到达索引设定的时间阈值以后,会刷新到磁盘上,这时候会生成 ES 的 segment。它是由一堆的数据和元数据文件来构成的,每次刷新就会生成一系列的 segment,这时候就会产生频繁的 IO 调用。
我们通过这种压测的方式来测试 JuiceFS 整体的可靠性,同时 ES 本身它会有一些 segment merge。这些场景在 warm 节点是不具备的,所以我们是想用一种极限的方式来压测。
第二种策略,通过生命周期管理来做热数据到冷数据的迁移。
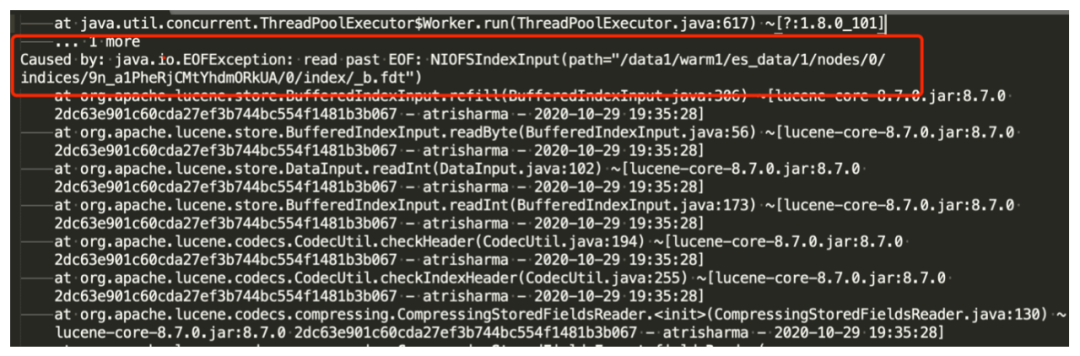
测试的时候 JuiceFS1.0 还没有发布,测试的过程中确实发现了问题,在实时写的过程中会出现了数据损坏的情况,跟社区沟通后可以通过修改缓存的大小来避免:
--attr-cache=0.1 属性缓存时长,单位秒 (默认值: 1)
--entry-cache=0.1 文件项缓存时长,单位秒 (默认值: 1)
--dir-entry-cache=0.1 目录项缓存时长,单位秒 (默认值: 1)
这三个参数的缓存默认是 1,把时长改成 0.1,它确实解决了索引损坏的问题,但是会带来一些新的问题,因为元数据的缓存和数据缓存的时间变短,会导致在执行系统命令的时候,比如 curl 一个系统命令,查看索引数量或者集群状态,正常的情况下,调用可能在秒级,而这种变化可能导致需要数 10 秒才能够完成。
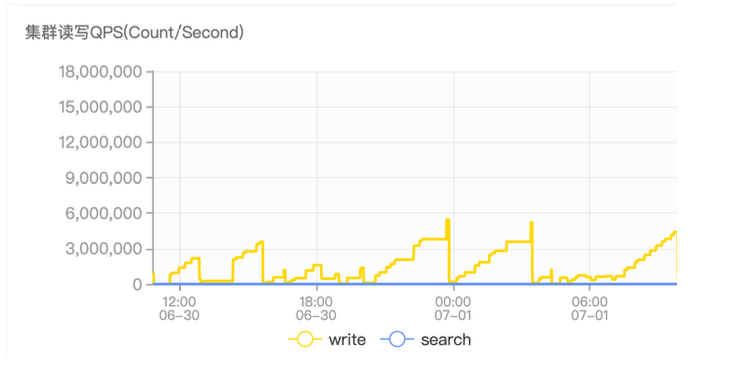
第二个问题就是写入的 QPS 有明显下降。我们可以看到监控图中 Write QPS 非常不稳定,这并不代表 ES 真实的 QPS,因为监控图中的 QPS 是通过两次得到的 documents 数量来做差得到的,由于旧版 JuiceFS 存在一些内核缓存问题,导致 ES 读到了一些旧数据。我们把该问题反馈给了社区, JuiceFS 1.0 正式发布后问题得到解决。
我们就进行了新一轮的测试,新一轮的测试确定了 hot 节点 3 台,8C16G 500G SSD, warm 节点 2 台,4C16G 200G SSD,测试时长 1 周,每天写入数据量 1TB(1 副本),1 天后转到 warm 节点 。没有再出现索引数据损坏情况,通过这次压测没有再出现之前遇到的问题,这就给了我们信心,接下来我们把整个的 ES 逐渐的往这方面来做迁移。
JuiceFS 数据存储和对象存储的差异
JuiceFS 有自己的元数据,所以在对象存储上和 JuiceFS 当中看到的目录结构是不一样的。
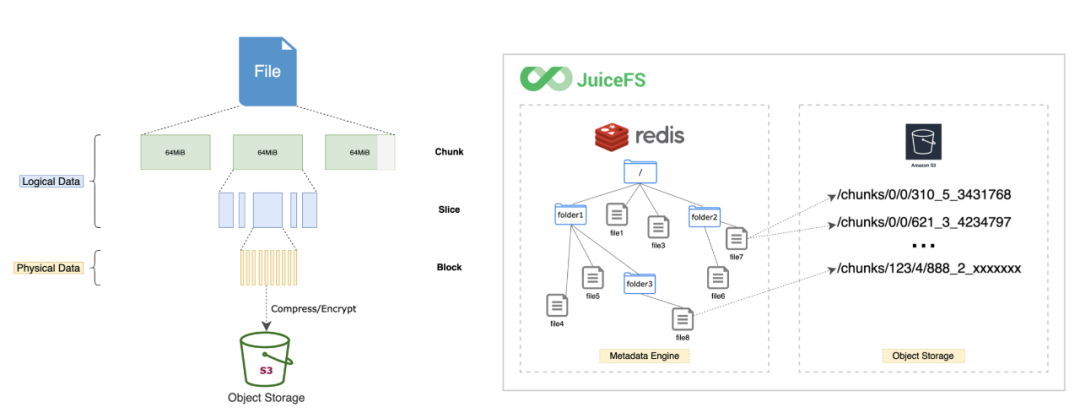
JuiceFS 分为三层结构,chunk、slice、block,因此我们在对象存储上面看到的是 JuiceFS 对文件做拆分之后的数据块。但是所有的数据是通过 ES 来管理,所以这一点用户不需要关注,只需要通过 ES 来执行所有的文件系统操作即可。JuiceFS 会恰当管理对象存储中的数据块。
经过这一系列的测试后, 金山云将 JuiceFS 应用在日志服务( Klog)中,为企业用户提供一站式日志类数据服务,实现了云上的数据可以不出云,直接就完成数据采集,存储分析以及告警的一站式服务;云下的数据提供了 SDK 客户端,通过采集工具来实现数据上云的整个整条链路,最后可以把数据投递到 KS3 和 KMR,来实现数据的加工计算。
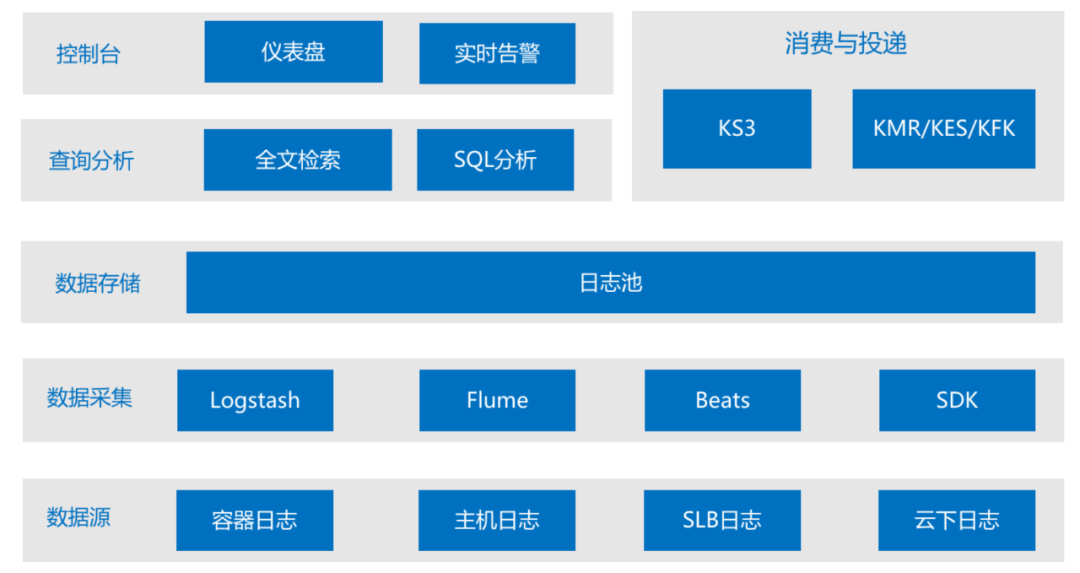
(金山云日志服务 Klog)
03 Elasticsearch 冷热数据管理
ES 有几个常用概念:Node Role 、Index Lifecycle Management 、 Data Stream。
Node Role,节点角色。每一个 ES 节点会分配不同的角色,比如 master、data、ingest。重点介绍一下 data 节点,老版本是分为三种,就是 hot、warm、cold 节点,在最新的版本里面增加了 freeze ,冷冻节点。
Index Lifecycle Management(ILM)我们分为了 4 个阶段:
• hot: 索引正在被频繁更新和查询。
• warm:索引不再被更新,但查询量一般。
• cold: 索引不再被更新,并且很少被查询。这些信息仍然需要可搜索,但如果查询速度较慢也没关系。
• delete: 索引不再需要,可以安全地删除。
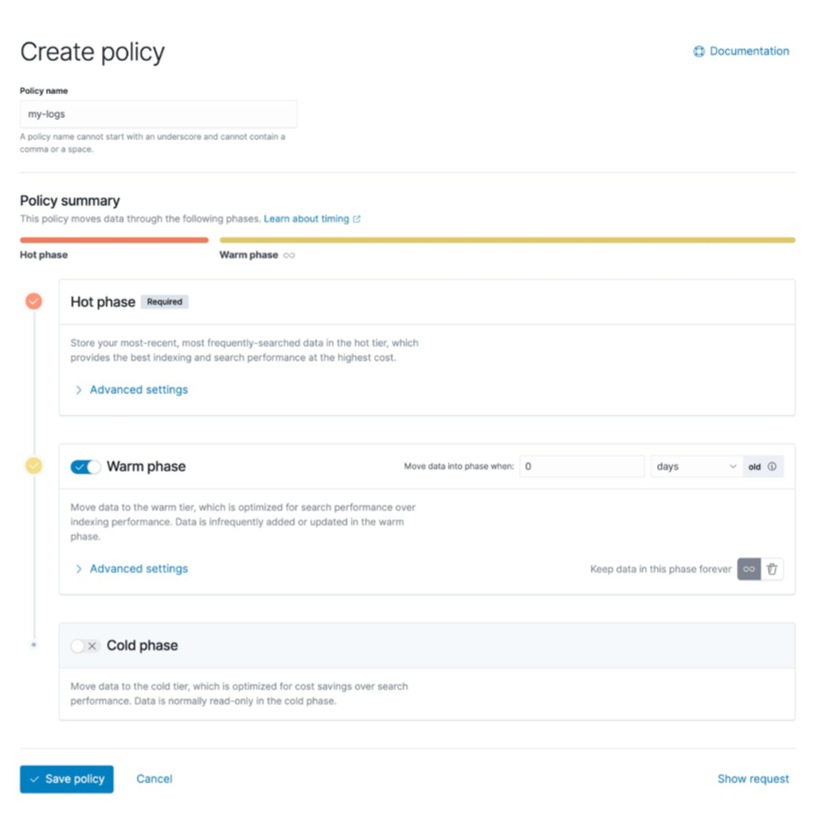
ES 官方提供了一个生命周期的管理工具,我们可以基于索引的大小,docs 数量的大小以及时间策略,把一个大的索引拆分成成多个小索引。一个大索引从管理运维查询,它的开销的代价是非常大的。生命周期管理功能方便我们更灵活地管理索引。
Data Stream 是在 7.9 版本提出推出了一个新功能,它是基于索引生命周期管理来实现了一个数据流写入,可以很方便地处理时间序列数据。
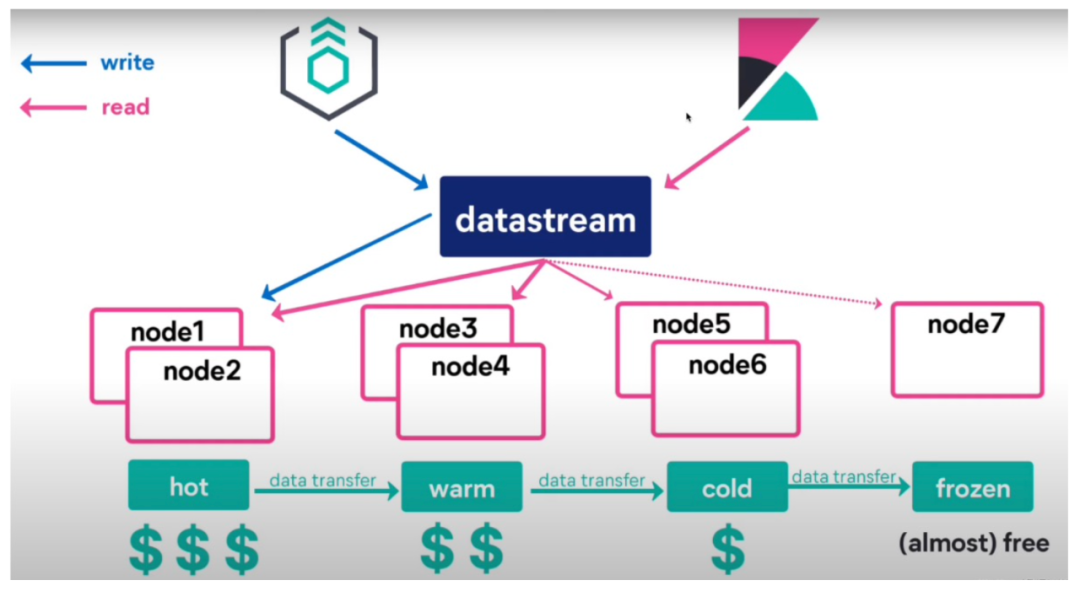
在查询多个索引时,通常是把这些索引合并在一起来查询,我们可以使用 Data Stream,他就像一个别名一样,可以自行路由到不同的索引里面。Data Stream 对时序数据的存储管理和查询来说更友好,这个是来对 ES 的冷热管理上面是来更近了一步,方便整个的运维管理。
合理规划冷节点大小 当我们把冷数据放到对象存储上时,会涉及到冷节点的管理,主要是分为三个方面:
第一:内存和 CPU 以及存储空间。内存的大小决定了分片的数量。我们通常会在 hot 节点会把物理内存按照一半一半进行划分: 一半给 ES 的 JVM,另外一半是给 Lucene。Lucene 是 ES 的检索引擎,为其分配足够的内存,能提升 ES 查询表现。因此相应地,我们在冷数据节点可以适当的把 JVM 内存,然后减少 Lucene 内存,不过 JVM 的内存不要超过 31G。
第二:CPU/内存比从前面提到的 1:4 降到 1:8。在存储空间上使用了 JuiceFS 和对象存储可以认为存储空间是无限的,但因为它是挂在冷节点上的,虽然有无限的空间可以使用,但是受限于内存大小,所以这就决定了无限存储空间的只是理想状态。如果再扩大,整个 ES 的在冷节点的稳定性上面就会有比较大的隐患。
第三:存储空间。以 32G 内存 为例,合理的存储空间为 6.4 TB。可以通过扩大分片的数量来扩大空间,但在 hot 节点,分片数量是要严格控制的,因为需要考虑到 hot 节点的稳定性,在冷节点适当放大这个比例是可以的。
这里需要重点考虑的因素有两个,就是一个是稳定性,第二个数据恢复时长。因为当节点挂掉,比如 JuiceFS 进程挂掉,或者冷节点挂掉,或者运维的时候需要重新挂载,这时候就需要把所有的数据重新加载到 ES 里面,将会在 KS3 产生大量的频繁读数据请求,如果数据量越多,那么整个的 ES 的分片时间恢复时长会越长。
常用的索引分片管理方法
管理方法主要考虑三个方面:
• shard 过大: 导致集群故障后恢复缓慢;容易造成数据写热点,导致 bulk queue 打满,拒绝率上升;
• shard 过小: 造成更多的 shard,占用更多的元数据,影响集群稳定性;降低集群吞吐;
• shard 过多: 造成更多的 segment,IO 资源浪费严重,降低查询速度;占用更多内存,影响稳定性。
数据在写入的时候,整个的数据大小是不确定的,通常会先创建模板,先确定固定的分片的大小,确定分片的数量,然后再创建 mapping 以及创建索引。
这时候就可能会出现两个问题,第一个就是分片过多,因为在预期的时候不知道到底要写入到多少数据,有可能我创建的分片多,但是没有更多的数据进来。
第二个就是创建的分片数量过少,会导致索引过大,这时候会需要把小的分片进行合并,需要把采用更长的时间做数据的 rotate,再把一些小的 segment 合并成更大的 segment,避免占用更多的 IO 和内存。同时还需要删除一些空索引,空索引虽然没有数据,但是它会占用内存。建议合理的分片大小是控制在 20~50g。
04 JuiceFS 使用效果及注意事项
以某线上集群为例,数据规模:每天写入 5TB,数据储存 30 天,热数据储存一周,节点数量:5 个热节点,15 个冷节点。
采用 JuiceFS 后,热节点保持不变,冷节点从 15 个降到了 10 个,同时我们用了一个 1TB 的机械硬盘做给 JuiceFS 来做缓存。
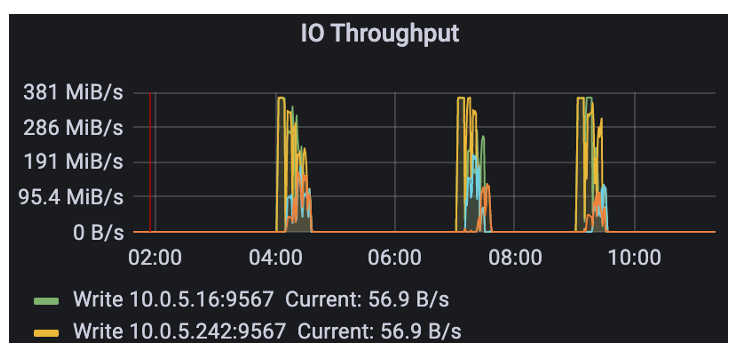
可以看到在凌晨的时候会有大量对象存储调用,这因为我们把整个的生命周期的管理操作放到了低峰期来运行。
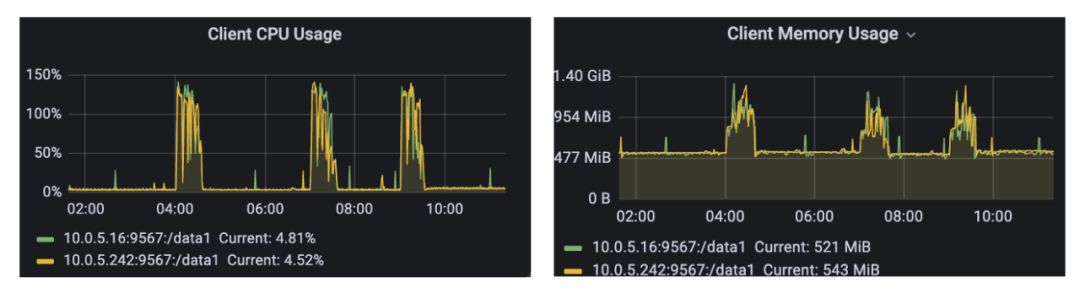
JuiceFS 内存占用通常会在几百 MB,它在高峰期调用的时候会在不到 1.5G 以及它的 CPU 的占用,表现无异常。
以下是 JuiceFS 的使用注意事项:
第一:不共用文件系统。因为我们把 JuiceFS 挂载到冷节点上,那么每一台机器上所看到的是一个全量的数据,更友好的方式是采用多个文件系统,每一个 ES 节点采用一个文件系统,这样能做到隔离,但是会带来相应的管理问题。
我们最终选定的是一套 ES 对应一个文件系统的模式,这个实践带来的问题是:每一个节点都会看到全量数据,这时候就会容易有一些误操作。如果用户要在上面做一些 rm ,有可能会把其他机器上的数据删掉了,但是综合考虑我们是在不同集群之间不共享文件系统,而在同一个集群里,我们还是应该平衡管理和运维,所以采用了一套 ES 对应一个 JuiceFS 文件系统 的模式。
第二:手动迁移数据到 warm 节点。在索引生命周期管理,ES 会有一些策略,会把热节点的数据迁到冷节点。策略在执行时,有可能是在业务高峰期,这时候会对热节点产生 IO, 然后把数据 copy 到冷节点,再把热节点的数据删除,整个热节点的系统的代价是比较大的,所以我们是采用的手动,来控制哪些索引什么时间迁移到冷节点。
第三:低峰错期进行索引迁移。
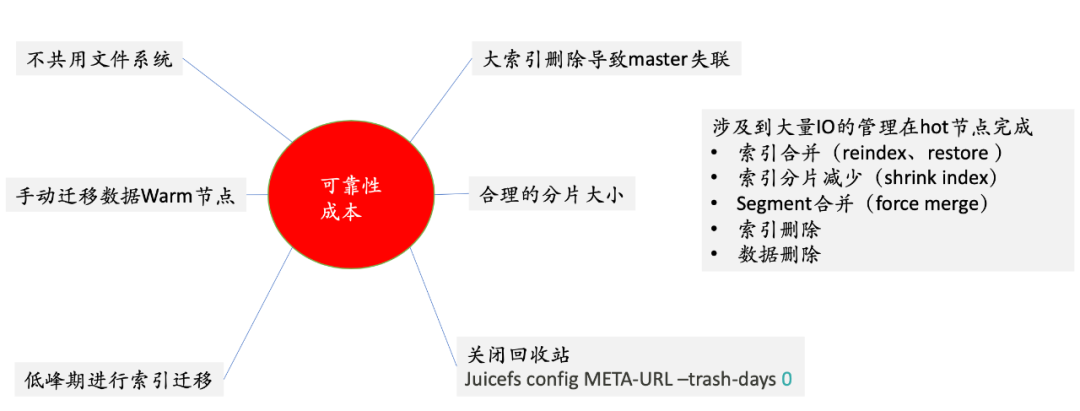
第四:避免大索引。在删除大索引时,它的 CPU 以及 IO 性能要比热节点要差一些,这时候会导致冷节点和 master 失联,失联以后就会出现了重新加载数据,然后重新恢复数据,整个就相当于 ES 故障了,节点故障了,这个代价是非常大的。
第五:合理的分片大小。
第六:关闭回收站。在对象存储上, JuiceFS 默认保存一天的数据,但在 ES 的场景下是不需要的。
还有一些其他涉及到一些大量 IO 的操作,要在 hot 节点完成。比如索引的合并、快照的恢复、以及分片的减少、索引以及数据的删除等,这些操作如果发生在冷节点,会导致 master 节点失联。虽然对象存储成本比较低,但是频繁的 IO 调用成本会升高,对象存储会要按照 put 和 get 的调用次数来收费,因此需要把这些大量的操作来放到热节点上,只供业务侧冷节点来做一些查询。
本文作者:
侯雪峰,金山云研发专家,2017 加入金山云,目前负责云存储大数据方面的研发,曾就职于百度,对大数据架构有着深入的研究与学习,云原生时代对计算、存储计算分离、流计算、消息队列方面有着深入学习和成功案例。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论