
作为首批入选印度“IndiaAI Mission”国家级项目、承担构建印度主权基础大模型任务的公司之一,Sarvam AI 近日发布了名为 Sarvam-M 的模型。这是一个基于 Mistral Small 构建的 240 亿参数、权重开放的混合语言模型。
该模型被视为印度本土 AI 研究的一项突破,甚至有开发者称赞为“印度人工智能的里程碑”。据悉,该模型支持包括印地语、孟加拉语、古吉拉特语、卡纳达语和马拉雅拉姆语等 10 种印度本地语言。然而,模型上线后反响平平:在 Hugging Face 平台上线两天仅获得 334 次下载,因此受到了部分业内人士的批评。截至目前,该模型获得 718 次下载。
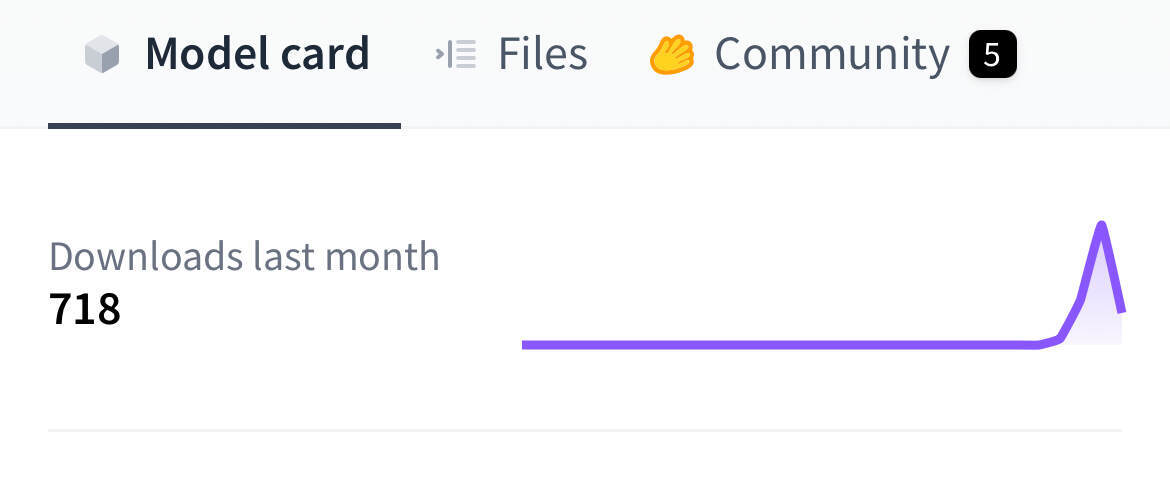
风投公司 Menlo Ventures 投资人 Deedy Das 直言该成绩“令人尴尬”,并表示这种“渐进式成果”根本没有真正的受众。Das 还将 Sarvam-M 与一款由两名韩国大学生开发的开源模型 Dia 进行对比,后者在 Hugging Face 上获得了约 20 万次下载。
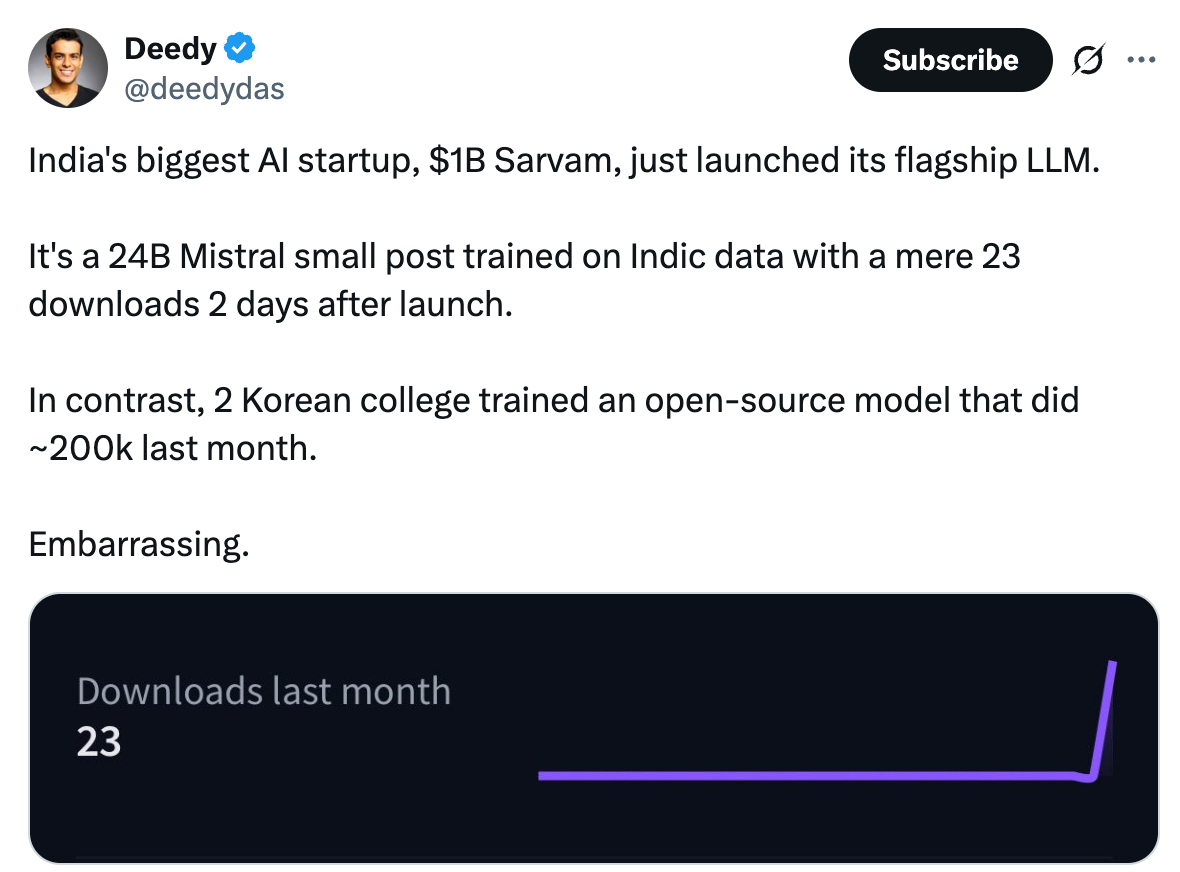
Das 对 Sarvam 的直接评价引发了印度 AI 社区的激烈争论和质疑。
实际上,Sarvam 并非个例。由印度政府支持的 BharatGen 推出的 Param-1 模型,上周在 AIKosh 平台上线后,截至发稿时也仅获得了 12 次下载。
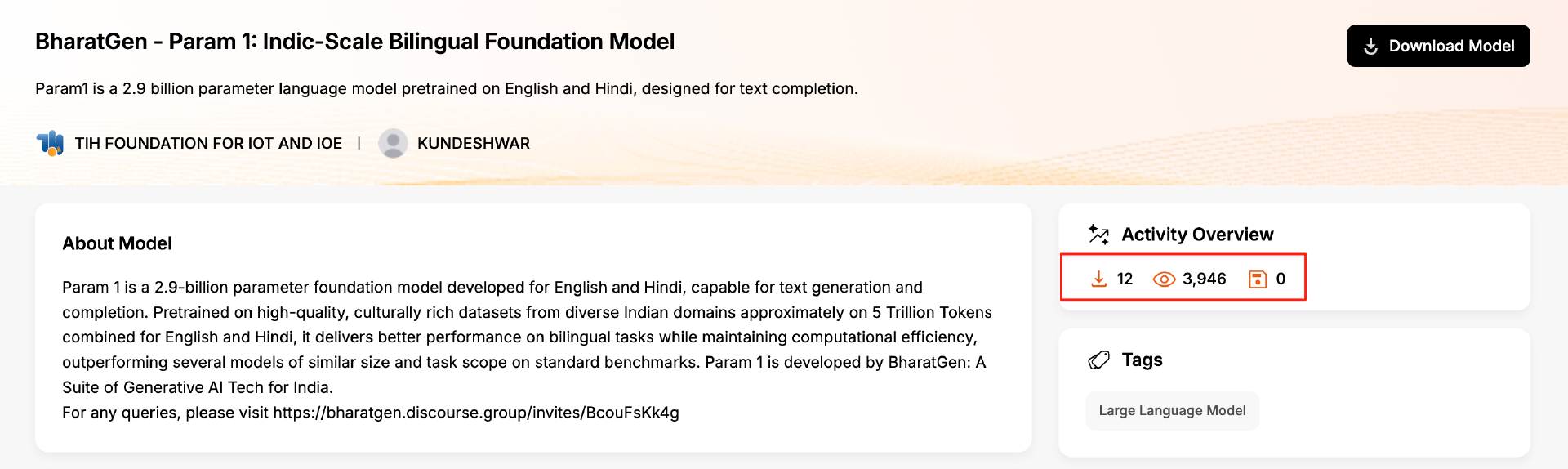
说好的“印度自己的 AI 技术栈”呢?
Sarvam AI 成立于 2023 年 7 月,由 Vivek Raghavan 和 Pratyush Kumar 联合创办,目标是在印度大规模普及生成式 AI。两位创始人此前都参与了专注于印度语言开源 AI 的研究项目 AI4Bharat。Raghavan 曾长期在 UIDAI(主管 Aadhaar 的机构)任职,Kumar 毕业于 ETH 苏黎世并拥有 IIT 孟买背景,是 AI4Bharat 的联合创始人,专注于推进印度本土语言 AI 应用。
Kumar 的愿景非常明确:印度需要属于自己的基础 AI 模型——不仅仅是对西方模型的“适配”,而是真正从零构建、使用印度本地数据训练,并在本土环境中安全部署。他接受媒体采访时表示,“到了 2040 年,印度必须拥有可以独立训练和部署基础模型的公司。”
“DeepSeek 证明,训练强大的模型不需要几十亿美元。这改变了 AI 竞争的基本规则。”Kumar 说道。对于 Sarvam 而言,这是一次重大战略机遇。
Kumar 认为,AI 主权不只是构建基础模型,更是要拥有从数据生成到模型部署的完整技术链。与许多仅对现有模型进行微调的初创公司不同,Sarvam 决心打造自己的模型。它最初与 Meta 合作,对 Llama 模型进行印度语言方向的优化,但很快意识到自身的真正使命是:打造属于印度自己的 AI 技术栈。
但这次发布的 Sarvam-M 却是基于法国 AI 初创公司的 Mistral Small 构建。据悉,目前 Sarvam 正筹备开发一个 700 亿参数的模型,预估成本为 4000–5000 万美元。
根据 Sarvam 的技术报告,Sarvam-M 在性能上已超越 Llama-4 Scout,并且在与更大规模模型(如 Llama-3.3 70B 和 Gemma 3 27B)对比时也表现稳健。“原始的 Mistral Small 模型在印度语言方面存在明显提升空间。”不过,模型在英文知识评估(如 MMLU)上出现了 1% 的小幅下降。
该公司对这一进展感到自豪。该公司联合创始人 Vivek Raghavan 表示,“Sarvam-M 是我们为印度打造自主 AI 的重要基石。”
“为了发布而发布?”
Das 的批评不仅仅针对下载量。他认为,Sarvam 的做法反映出了它“错位的雄心”。
“很明显,没人需要一个稍微好点的 240 亿参数印度本地语言模型。如果你想训练模型,那应该有一个非常充分的理由。”Google 和 TWO.ai 已推出覆盖所有这些语言但更便宜、表现更佳的模型,Das 补充道,“我并不是反对 Sarvam,只是认为现在他们的成果远远配不上他们获得的融资。”
根据公开信息,Sarvam 目前已获得 4100 万美元融资,投资方包括 Lightspeed India Partners、Peak XV Partners、Lightspeed Venture Partners 和 Khosla Ventures 等主流机构。根据 Tracxn 数据,截至 2025 年 3 月,公司估值达到 1.11 亿美元。
尽管如此,一些 X(原 Twitter)用户指出,Sarvam-M 表现不错,有不少实际应用场景,但确实还需要进一步优化。
有用户分享了使用 Sarvam 最新模型的用途,列举了模型可以如何帮助农民、老年人、小店主、法律从业者等人群,并强调这是围绕印度本土的真实问题做的技术落地。
不过,网友 Whiteye 指出,那些用例都围绕本国较为弱势的群体。但问题在于,在那些经济条件较差的地区,人们几乎不使用科技产品,让他们使用“语音指令”和“人工智能”毫无意义。其强调,这不是说他们不应接触科技,而是应该先让他们熟悉科技产品,再将科技融入日常生活,最后才是人工智能的应用。
“印度语言模型固然很棒,但根本不存在产品市场匹配度(PMF)。像 LLaMA 和 GPT 这样的基础模型已经覆盖了足够多的语言,能够满足有能力使用它们的人群的需求。”Whiteye 与 Das 有相似的观点。
有维护 Sarvam 的网友则表示,“问题不在于产品/技术/模型,而在于分发。”对此,Das 回应道,“如果 ChatGPT 现在在其产品中为 10 亿用户提供使用 240 亿 Sarvam-M 的选项,那么只有不到 0.1% 的人会长期使用它。这不是分发问题,而是实用性不足的问题。”
为了发布而发布,还是为了解决问题而发布?是真的想解决问题,还是只是为了开源贡献而发起 PR?这些疑问成为社区讨论的重点。
无论如何,Das 给出的建议是,Sarvam 应该对软硬件基础设施进行更为根本性的重构,并以中国的 DeepSeek 项目为参考。“(Sarvam )应该聚焦于大规模的印度本地语言及通用语料数据收集,这才是驱动前沿模型的关键。”
当然,不乏站在 Sarvam 一边的网友提出,“Sarvam 既没有足够的资金,也没有足够的人才来满足要求。”有网友辩道。对此,Das 表示,“Sarvam 融资 4100 万美元,而我可以明确指出,至少有 10 家公司融资更少,但交付成果却更多。”
AI4Bharat 的用户“cneuralnetwork”则将关注点放在了建模方法论上,“模型本身不是最关键的,真正让我欣赏的是他们构建模型的过程。这个过程为其他开发者提供了基础,说明了后训练该怎么做,甚至有可能做得更好。”
许多人对 Sarvam 的努力表示肯定,并强调创新并非总是能瞬间爆红。不过,也有人指出,这背后更大的问题是:外界预期与实际成果之间的落差,以及这场印度寄希望于本土 AI 技术的豪赌,能否拿出与其浩大声势匹配的成果。
Sarvam AI 的 Harveen Singh Chadha 面对 Das 的批评则反驳道,“有着九万粉丝的人,会在周六早上发表很多‘高见’,却连花 10 分钟试用一下模型再给出反馈都不愿意。这正是为什么很多人不关心这件事的原因——如果你只用自己的影响力去批评、却从不亲自尝试,那你就是问题的一部分。”
与此同时,Sarvam AI 的机器学习工程师 Kurain Benoy 表达了更多的乐观情绪和民族自豪感。不过,Reliance Jio 副总裁兼首席 AI 科学家 Gaurav Aggarwal 就质疑围绕 Sarvam 的“民族主义情绪”,指出它实际上是由西方投资者支持的公司。
开发印度本土模型,有意义吗?
“在 Sarvam-M 问世之前,人们抱怨缺少印度本土大模型。Sarvam-M 发布后之后,人们仍在抱怨。”谷歌高级研究科学家、IndicTrans2 开发者之一的 Raj Dabre 说道。
印度有 6 亿智能手机用户,相当一部分人喜欢使用印度本土语言键盘。
例如,由 CoRover.ai 开发、部署在印度铁路餐饮和旅游公司(IRCTC)网站上的人工智能聊天机器人 AskDisha,就是一个典型案例 —— 它支持用户使用印度本土语言来预订车票。像 AI4Bharat 开发的 IndicTrans2 等模型,则是为更广泛的印度本土人群设计的。
“为印度开发 AI”的需求早就被多次强调。许多印度智能手机用户是首次接触这类设备,他们尽可能使用母语操作。英语用户和印度本土语言用户之间的这种差异,给弥合技术与多元用户之间的鸿沟带来了独特的挑战。
印度许多初创企业和开发人员致力于解决本土需求,而 Sarvam 等公司需要重点推广其瞄准的应用场景。Together Fund 负责人 Pratyush Choudhury 解释说道,大多数印度以外的人既不了解这些挑战,也意识不到算力其实是一道隐形的天花板。
他反驳 Das 的观点时补充道:“此外,在许多印度语言的应用场景中,本土自主开发的模型比使用任何其他开源权重模型的效果都要好得多。”
这或许表明了为什么有人要开发印度本土 AI 模型。这一趋势始于两年前,当时开发者们正在 Llama 的基础上为卡纳达语、泰米尔语和马拉雅拉姆语等语言构建模型。
参考链接:
https://analyticsindiamag.com/ai-features/sarvam-ais-backlash-exposes-the-sad-state-of-indian-ai/




