

本文要点
Azure 数据湖分析与数据湖存储是微软 Azure 数据湖解决方案中的关键组件。
Azure 数据湖分析当前只适用于批处理工作负载。对于流数据处理和事件处理工作负载,可使用 Azure 提供的其它数据分析解决方案,例如 HDInsight、Azure Databricks 等。
Azure 数据湖分析提供了一种新的大数据查询和处理语言,称为 U-SQL。
U-SQL 结合了 SQL 和 C#的理念和结构。U-SQL 强大之处来自于 SQL 的简单和声明性本质,以及 C#提供的具有丰富类型和表达式的编程能力。
U-SQL 提供了模式化视图,可操作存储在文件中的非结构化数据。与由关系数据库管理的结构化数据非常类似,U-SQL 也提供了通用的元数据目录系统。
目前大数据和Hadoop技术已历经十多年的发展,大数据和大数据分析受到前所未有的重视。Hadoop 的最初版本仅支持批处理工作负载,现在 Hadoop 生态已具有处理结构化数据、流数据、事件处理、机器学习等工作负载以及处理图数据的工具。
尽管 Hadoop 生态中具有大量的工具,提供了完整的特性集,例如Hive、Impala, Pig、Storm和Mahout等。但 Spark 等新兴数据分析工具的出现,为处理多类型复杂工作提供了集成解决方案。
Azure 数据湖分析(简称 ADLA)是一种新推出的大数据分析引擎。ADLA 是由微软Azure cloud完全托管和提供的按需分析服务。ALDA 与Azure 数据湖存储及HDInsight一并形成了微软基于云的数据湖和分析工具集。ADLA 提供了一种新的大数据查询和处理语言,称为U-SQL。下面本文将介绍 U-SQL 语言,以及如何在应用中使用该语言。
Azure 数据湖
Azure 数据湖是微软基于 Azure 公有云提供的数据湖工具集,其中包括多种服务,涉及数据存储、数据处理、数据分析,以及 NoSQL 存储、关系数据库、数据仓库和 ETL 工具等相关配套服务。
数据存储服务
Azure 数据湖存储(简称 ADLS):一种基于开放 HDFS 标准的可扩展云存储,针对数据分析应用。
Azure Blob Storage:一种用于 Azure 的通用托管对象存储。
数据分析和处理服务
Azure 数据湖分析(简称 ADLA):一种 Azure 云上的完全托管按需分析服务。ADLA不仅支持.NET、R 和 Python 语言,还支持一种称为 U-SQL 的全新大数据处理语言。
HDInsight:运行在 Azure 云上,提供基于Hortonworks Data Platform(HDP)Hadoop 发行版的托管 Hadoop 集群。HDInsight 支持包括 Spark、Hive、Map Reduce、HBase、Storm 和 Kafka 等多种 Hadoop 生态系统工具。
Azure Databricks:一种基于 Azure Spark 的托管无服务器分析服务。其提供 Jupyter/ iPython/Zeppelin 等风格的 Notebook 交互特性,并支持 Scala、Python、R 和 SQL 等语言。
配套服务
Cosmos DB:Azure 上托管的无服务器数据库服务,提供多模 NoSQL 服务。
Azure SQL Database:Azure 上托管的关系数据库即服务(DBaaS)
Azure SQL Datawarehouse:基于云的企业数据仓库(EDW,Enterprise Data Warehouse)服务。它使用了为用户熟知的分布式系统和数据仓库理念,例如 MPP、列存储、压缩等,确保了服务对复杂查询的高性能。
Azure Analysis Service :Azure 上完全托管的数据分析引擎,用于构建云上的语义模型。它基于为用户熟悉的 SQL Server Analysis Server(基于 SQL Sever 的本地部署分析引擎)构建。目前,Azure Analysis Servives 仅支持二维表模型,不支持多维模型(即数据立方体)。
Azure Data Factory:一种基于云的无服务器 ETL 和数据集成服务,为 50 多种云和本地部署系统与服务提供开箱即可用的连接器,包括 Azure Blob Storage、Cosmos DB、Azure SQL Database,以及本地部署的 SQL Server、MySQL、PostgreSQL 数据库,甚至支持 SFDC、Dropbox 等第三方服务。它实现了数据在云服务器间的移动,并支持数据在本地部署系统和云间的相互移动。
图 1 给出了微软在 Azure Cloud 上提供的各种云服务。
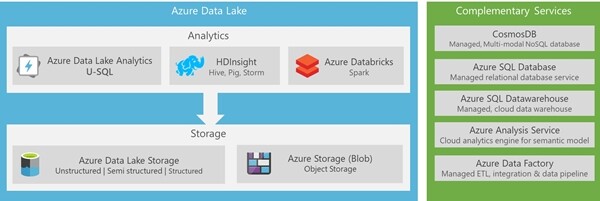
图 1:Azure 数据湖提供的各种服务
图 2 给出了 Azure 云平台上提供的基于大数据和数据湖的应用架构。
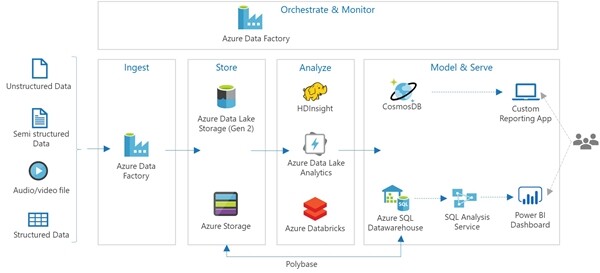
图 2:Azure 上的典型大数据/数据湖/ETL/数据分析架构
U-SQL 简介
U-SQL 是 Azure 数据湖分析提供的大数据查询和处理语言。 它是微软专为 Azure 数据湖分析创建的一种新语言。U-SQL 结合了类 SQL 的声明性语言与 C#提供的包括丰富类型和表达式在内的编程功能,提供了为用户所熟知的大数据处理概念,例如“读取时模式”(Schema on Read)、“惰性计算”(Lazy Evaluation)、自定义处理器和 Reducer 等。熟悉 Pig、Hive 和 Spark 等开发的数据工程师会触类旁通。同时,具有 C#和 SQL 知识的开发人员也会感觉 U-SQL 易于学习,并由此入手。
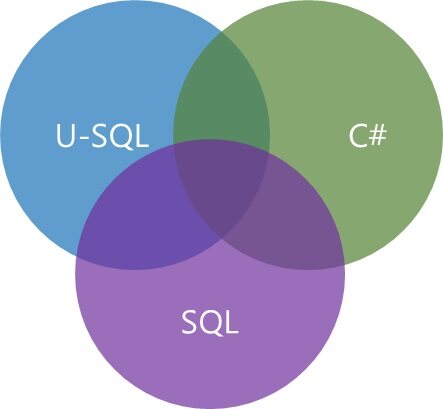
图 3:U-SQL 与 C#、SQL 间的相互关系
尽管 U-SQL 使用了 SQL 中的多个概念和关键词,但是它并非 ANSI SQL 兼容的。它定义了关键字 EXTRACT and OUTPUT,增加了对非结构化文件的处理能力。
当前,ADLA 和 U-SQL 仅支持批处理,并不支持流数据分析或事件分析。
概念和 U-SQL 脚本
U-SQL 的查询和处理逻辑需编写在“U-SQL 脚本”,是扩展名“.usql”的文本文件。脚本文件可使用 Visual Studio IDE 或 Azure Portal 编写。在 Visual Studio 中,U-SQL 项目除了了一些相关文件引用组件之外,还可包含多个脚本和代码。
图 4 给出了 Visual Studio IDE 中的 U-SQL 项目截图。
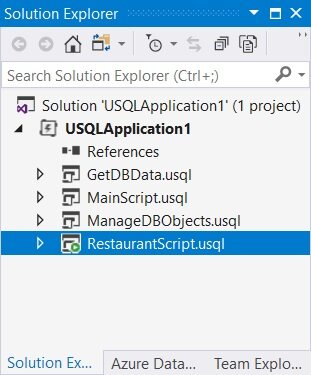
图 4:Visual Studio 中的 U-SQL 项目
U-SQL 脚本遵循 Pig、Spark 等大数据语言所使用的 ETL 和加载/输出模式,支持从文本文件(包括非结构化文本文件和 JSON、XML 等半结构化文件)和数据库表中抽取数据。
U-SQL 在从文件中抽取非结构化数据时会形成模式,这有助于对所抽取数据执行类 SQL 操作。
Rowset 类型是 U-SQL 中的重要数据结构,适用于从输入文件和数据库表中抽取数据、执行数据格式转换、写入目的地等操作。Rowset 是无序结构,支持 Azure 数据分析引擎中使用多个节点的并发处理。
U-SQL 脚本支持使用 C#的类型、操作符和表达式。
U-SQL 脚本支持使用大多数 SQL 结构体,包括 SELECT、WHERE、JOIN 等数据定义语言(DDL)和数据操作语言(DML),注意所有关键字必须大写。
U-SQL 支持 IF/ELSE 等程序控制流结构,但不支持 While 和 For 循环。
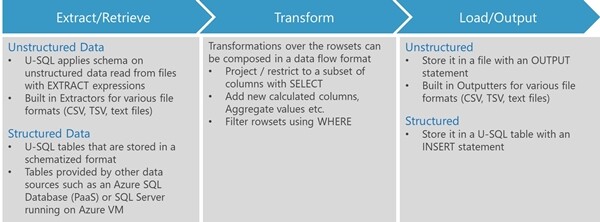
图 5:U-SQL 脚本中的数据流
U-SQL 本地开发环境
为支持在本地机器和笔记本电脑上使用 U-SQL 和 Azure 数据湖,微软提供了类模拟器安装程序。开发环境需要下列组件:
Visual Studio 2017 或 2019;
Azure SDK 2.7.1 及更高版本。其与客户端 SDK 一并支持与 Azure 云服务器的交互,存储和计算等服务会需要它。
Azure 数据湖和 Stream Analytics Tools for Visual Studio(2.4 版)。它们是本地 U-SQL 和 Azure 数据湖开发的插件。开发人员一旦安装它们,Visual Studio 中就会添加相关 Azure 数据湖分析及相关项目模板。开发人员可以通过选择 U-SQL Project 着手开发。
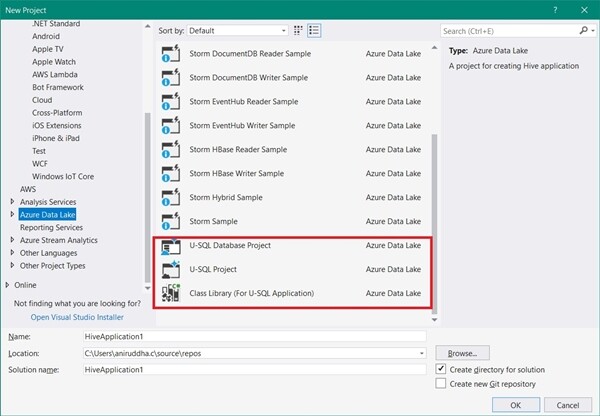
图 6:新建项目模板的截图
首个 U-SQL 脚本
为构建首个 U-SQL 脚本,所使用的数据集是班加罗尔餐馆评分数据。原数据是 CSV 文件格式,其中各数据列定义如下:
rest_id:餐馆的唯一标识符;
name:餐馆名称;
address:餐馆地址;
online_order:餐馆是否提供在线订餐服务;
book_table:餐馆是否提供预定;
rate:餐馆总体评分,按 1-5 级给出;
votes:餐馆的总评价数;
phone:餐馆联系电话;
location:餐馆所在商圈;
rest_type:餐馆类型(例如:便餐、快餐、外卖、烘焙、甜品店等);
favorite_dish_id:餐馆最受欢迎菜品的标识符;
下图中给出了部分示例数据。

图 7:餐馆评级表中的部分示例数据
下面的脚本实现从 CSV 文件读取餐馆评分数据,并将同一数据写入到一个 TSV 文件中。该脚本中并未执行数据转换操作。
该脚本读取整个餐馆数据到 Rowset 变量,并以制表符分隔的格式写入到输出文件。
注意,上例中使用了字符串等 C#数据类型,而非 SQL 中通常使用的 char/varchar 类型。其中不仅使用了 C#的数据类型,而且利用了表达式及其它所有表述性编程语言的优点。
执行数据转换操作的 U-SQL 脚本
使用自定义代码扩展 U-SQL 表达式
U-SQL 支持 C#语言编写的自定义表达式。C#代码形成独立于脚本的文件。注意,下图展示的.usql 文件,具有关联的.usql.cs 文件,存储相关的自定义 C#代码。
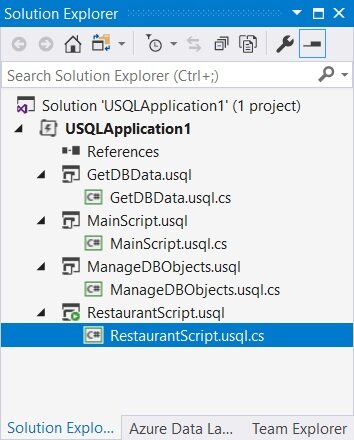
图 8:具有多个脚本和相关代码文件的 U-SQL 项目
执行连接运算的 U-SQL 脚本
U-SQL 支持对两个不同数据集执行连接运算,可实现内连接、外连接、交叉连接等运算。
在下面的示例代码段中,执行了餐馆数据集和菜品食材数据集间的内连接运算。
现在,我们需要的是菜品及其中食材的数据。尽管这些数据通常可从外部数据源抽取,但在该代码中使用了内存中的 Rowset 变量。
该代码返回高评分的餐馆和其最受欢迎菜品的食材清单。这是通过对餐馆数据和菜品食材 Rowset 数据间执行内连接运算得到的。

图 9:具有多个脚本和相关代码文件的 U-SQL 项目
使用内建函数的 U-SQL 脚本
U-SQL 提供了大量内建函数,包括聚合、分析函数、分级函数等。以下仅列出部分示例:
下面的示例脚本对餐馆数据集使用内建聚合函数,包括 MIN、MAX、AVG 和 STDEV。
U-SQL 目录
上面介绍主要关注的是如何从文件中读写非结构化和半结构化数据。当然,U-SQL 的强大之处在于操作存储在文件中的非结构化数据,并对所抽取数据构建模式化视图,但是 U-SQL 同样可管理结构化数据。它提供了类似于 Hive 的通用元数据目录系统。下面列出了 U-SQL 支持的主要对象:
数据库:和 Hive 等大数据系统一样,U-SQL 同样支持数据库。
数据库模式:和关系数据库一样,按数据库方式表示模式相关对象。
数据库表和索引:数据库表是管理结构化数据的容器,实现按列存储不同类型的数据。数据库表中,数据是存储在文件中的。除了对非结构数据的模式化视图之外,数据库表还提供其它一些优点,包括支持索引,以及将数据按桶(bucket)分布在多个分区表中,分别以独立文件形式存储。
视图:U-SQL 视图分为两类:一类是基于 U-SQL 表的视图,另一类是指向文件的视图,需使用 EXTRACT 获取数据。
函数:支持标量和数据库表赋值.
过程:类似于函数,但不返回任何值。
程序集(Assemblies):U-SQL 支持存储.NET 程序集,实现扩展 U-SQL 脚本形成自定义表达式。
现在回到上面的餐馆评分示例。我们希望进一步分析那些低评分的餐馆。为实现此,我们需要抽取所有评分低于四级的餐馆到一张表中,以做进一步分析。
U-SQL 数据库、数据库表和索引
示例代码在数据库中创建了一个具有模式和索引键的 U-SQL 数据库。代码中并未指定创建的模式,因此类似于 SQL Sever 中的操作,数据库表创建使用的是数据库内置的缺省模式“dbo”。
下面给出创建数据库表的示例代码。
U-SQL 视图
类似于数据库视图,U-SQL 视图也不对数据做物理保存,只是对存储在数据库表或文件中的数据提供一种视图。视图可以基于数据库表,也可以基于文件的抽取数据。
下面的示例脚本展示了如何基于所抽取的数据创建视图。
视图操作代码如下:
U-SQL 表值函数(TVF,table valued functions)
U-SQL 支持标量函数和表值函数(TVF)。函数可输入 0 到多个参数,返回单个标量值,或是一个数据库表,其为一个由列和行组成的数据集。
下面的示例代码片段首先展示了如何创建 TVF,进而展示了如何调用该 TVF 函数。函数接收单个参数输入,返回一个数据库表。
调用该 TVF,只需创建并传递“Bakery”参数。该 TVF 函数将返回所有类型为“Bakery”的餐馆。
研究实例
下面给出一个研究实例,重点关注如何在一个已运作多年的大型数字转换战略计划中使用 Azure 数据湖分析和 U-SQL 语言。实例的客户是一家大型保险专业机构,在过去一年中收购了多家保险公司和经纪商。因此,客户使用了多个客户系统,以电子邮件、文本短消息、Web、移动聊天和呼叫(入站和出站)等方式与其顾客交互。由于采用了多种折衷方案,分析客户交互数据是非常困难的。
由此,该客户考虑着手建立全渠道平台和整合的客服中心,希望通过多种联系渠道(包括电子邮件、文本、聊天机器人、联络中心语音呼叫等)为顾客提供服务。客户最直接的技术选择是去分析来自不同来源的数据,包括电子邮件,文本短信、聊天和通话记录等。
为解决如何对来自各系统不同格式数据分析的迫切需求,该研究实例中开发了一个基于 Azure 数据湖的解决方案,将多源系统迁移到 Azure 数据湖存储,进而使用 Azure 数据湖分析和 U-SQL 进行分析。
摄取(Ingest)阶段:在接收阶段,使用 Azure Data Factory ETL 服务将来自不同来源的非结构化和结构化数据(电子邮件/文本/聊天数据以及呼叫日志)迁移到 Azure 中。
存储(Store)阶段:原始数据以纯文本文件存储在 Azure 数据湖存储(ADLS)中。
分析(Analyze)阶段:使用 U-SQL 执行各种类型的分析,包括过滤、联接、聚合、窗口操作等。
模型和提供服务(Model and Serve)阶段:经分析的数据存储在结构化表中,供用户以后从 Power BI 或自定义的报告中使用。
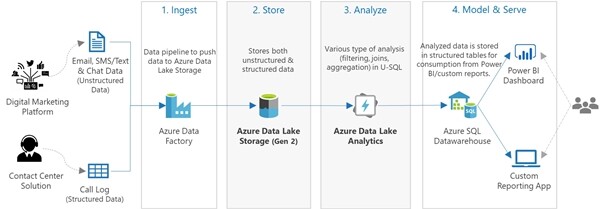
图 10:Azure Data Analytics 流水线
总结
Azure 数据湖存储和分析与 Azure HDInsight 和 Azure Databricks 一并,已成为执行大数据和分析工作负载的强大工具。尽管该服务集仍处于起步阶段,尚不支持流数据和事件处理功能,但新的 U-SQL 提供了强大的功能。U-SQL 语言将 SQL 的简单性和普遍性与 Mirosoft 的旗舰产品,即强大的 C#语言,结合在一起。此外,Microsoft 的开发工具(例如 Visual Studio)和本地开发/测试功能,支持 U-SQL 在大数据和分析领域具有强大的竞争力。
作者简介
Aniruddha Chakrabarti 已在策略,咨询,产品开发和 IT 服务等领域深耕 19 年,在包括解决方案体系结构、售前、技术体系结构、交付领导力和计划管理等职能部门具有丰富的工作经验。作为 Mphasis 的数字化高级副总裁,Chakrabarti 负责大型数字交易和计划的预售、解决方案、RFP/RFI 和技术架构。在加入 Mphasis 之前,他曾在埃森哲、微软、Target、Misys 和 Cognizant 担任过多种领导职务,以及围绕架构的多种职务。他的关注重点包括云、大数据及其分析、AI/ML、NLP、IoT、分布式系统、微服务和 DevOps。
原文链接:
Azure Data Lake Analytics and U-SQL

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论