

本文来自“深度推荐系统”专栏,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要介绍 Google 在大规模深度推荐模型上关于特征嵌入的最新论文。
一、背景
大部分的深度学习模型主要包含如下的两大模块:输入模块以及表示学习模块。自从 NAS[1]的出现以来,神经网络架构的设计上正在往数据驱动的自动机器学习方向演进。不过之前更多的研究都是聚焦在如何自动设计表示学习模块而不是输入模块,主要原因是在计算机视觉等成熟领域原始输入(图像像素)已经是浮点数了。
输入模块:负责将原始输入转换为浮点数;
表示学习模块:根据输入模块的浮点值,计算得到模型的最终输出;
而在推荐、搜索以及广告工业界的大规模深度模型上,情况却完全不同。因为包含大量高维稀疏的离散特征(譬如商品 id,视频 id 或者文章 id)需要将这些类别特征通过 embedding 嵌入技术将离散的 id 转换为连续的向量。而这些向量的维度大小往往被当做一个超参手动进行设定。
一个简单的数据分析就能告诉我们嵌入向量维度设定的合理与否非常影响模型的效果。以 YoutubeDNN[2]为例,其中使用到的 VideoId 的特征词典大小是 100 万,每一个特征值嵌入向量大小是 256。仅仅一个 VideoId 的特征就包含了 2.56 亿的超参,考虑到其他更多的离散类特征输入模块的需要学习的超参数量可想而知。相应地,表示学习模块主要包含三层全连接层。也就是说大部分的超参其实聚集在了输入模块,那自然就会对模型的效果有着举足轻重的影响。
二、主要工作
Google 的研究者们在最新的一篇论文[3]中提出了 NIS 技术(Neural Input Search),可以自动学习大规模深度推荐模型中每个类别特征最优化的词典大小以及嵌入向量维度大小。目的就是为了在节省性能的同时尽可能地最大化深度模型的效果。
并且,他们发现传统的 Single-size Embedding 方式(所有特征值共享同样的嵌入向量维度)其实并不能够让模型充分学习训练数据。因此与之对应地,提出了 Multi-size Embedding 方式让不同的特征值可以拥有不同的嵌入向量维度。
在实际训练中,他们使用强化学习来寻找每个特征值最优化的词典大小和嵌入向量维度。通过在两大大规模推荐问题(检索、排序)上的实验验证,NIS 技术能够自动学习到更优化的特征词典大小和嵌入维度并且带来在 Recall@1 以及 AUC 等指标上的显著提升。
三、Neural Input Search 问题
NIS-SE 问题:SE(Single-size Embedding)方式是目前常用的特征嵌入方式,所有特征值共享同样的特征嵌入维度。NIS-SE 问题就是在给定资源条件下,对于每个离散特征找到最优化的词典大小 v 和嵌入向量维度 d。
这里面其实包含了两部分的 trade-off:一方面是各特征之间,更有用的特征应该给予更多的资源;另一方面是每个特征内部,词典大小和嵌入向量维度之间。对于一个特征来说,更大的词典可以有更大的覆盖度,包含更多长尾的 item;更多的嵌入向量维度则可以提升 head item 的嵌入质量,因为 head item 拥有充分的训练数据。而 SE 在资源限制下无法同时做到高覆盖度和高质量的特征嵌入。所以需要引入 ME(Multi-size Embedding)。
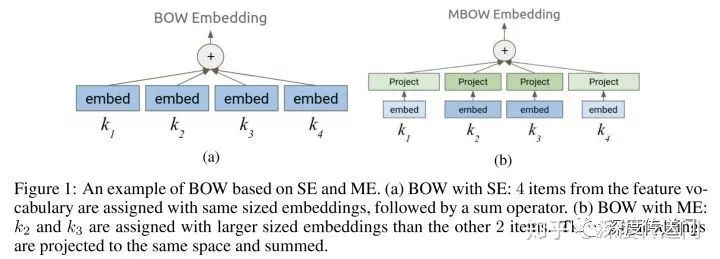
NIS-ME 问题:ME 允许每个特征词典内不同的特征值可以有不同的嵌入向量维度。其实就是为了实现越频繁的特征值拥有更大的嵌入特征维度,因为有更多的训练数据;而长尾的特征值则用更小的嵌入特征维度。引入 ME 为每一个类别离散特征找到最优化的词典大小和嵌入向量维度,就可以实现在长尾特征值上的高覆盖度以及在频繁特征值上的高质量嵌入向量。下图给出了 embedding 使用的场景例子中,SE 和 ME 使用上的区别。
四、NIS 解决方案
要想为每个类别离散特征手动找到最优化的词典大小和嵌入向量维度是很难的,因为推荐广告工业界的大规模深度模型的训练时很昂贵的。为了达到在一次训练中就能自动找到最优化的词典大小和嵌入向量维度,他们改造了经典的 ENAS[4]:
首先针对深度模型的输入模块提出了一个新颖的搜索空间;
然后有一个单独的 Controller 针对每一个离散特征选择 SE 或者 ME;
其次可以根据 Controller 决策后考虑模型准确度和资源消耗计算得到 reward;
最后可以根据 reward 使用强化学习 A3C[5]训练 Controller 进行迭代。
搜索空间
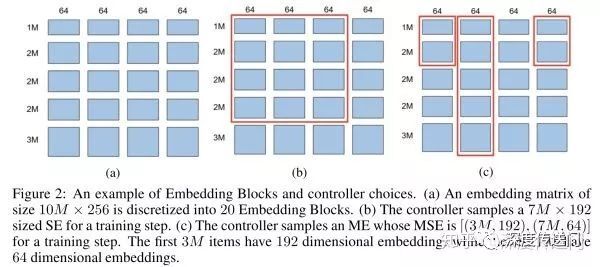
Embedding Block 的概念实际上就是原始 Embedding 矩阵的分块。如下图所示,假设原始 Embedding 矩阵大小是(10M,256),图 a 将其分成了 20 个 Embedding Block。Controller 为每个特征有两种选择:图 b 所示的 SE 以及图 c 的所示的 ME。
Reward 函数
主模型是随着 Controller 的选择进行训练的,因此 Controller 的参数实际上是根据在验证集上前向计算的 reward 通过 RL 追求收益最大化而来。考虑到在限定资源下的深度模型训练,这里的 reward 函数设计为同时考虑业务目标与资源消耗。对于推荐领域的两大主要任务:信息检索和排序,信息检索的目标可以使用 Sampled Recall@1;而排序的目标则可以使用 AUC。
五、实验结果
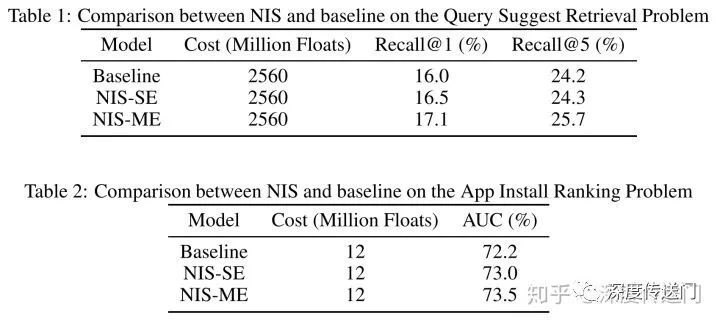
他们在两大大规模推荐模型问题:检索和排序上进行了实验。在同等资源消耗的情况下,NIS 可以获得显著提升,详细数据如下图所示。
参考文献
[1] Neural Architecture Search with Reinforcement Learning
[2] Deep Neural Networks for Youtube Recommendations
[3] Neural Input Search for Large Scale Recommendation Models
[4] Efficient Neural Architecture Search via Parameters Sharing
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/p/73369087

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论