
看一下 eBay 如何创建优化的 SQL 解决方案,它可以为新的基于开源的分析平台提供更高的速度、稳定性和可扩展性。
最近,eBay 完成了把超过 20PB 的数据从一个提供商的分析平台迁移到内部构建的基于开源的 Hadoop 系统。这次迁移使得 eBay 以技术为主导的重新构想与第三方服务提供商脱钩。与此同时,它也给 eBay 提供了一个机会,建立一套相互补充的开源系统来支持对用户体验的分析。
这个迁移过程中面临的一个挑战是设计一个能够反映之前平台的速度、稳定性和可扩展性的 SQL 执行引擎。定制的 Spark SQL 引擎有一个性能差距,尤其是 SQL 的大规模执行速度。举例来说,在旧工具上,有多个 Join 的查询可以在几秒内执行,而相同的查询在新的 SQL-on-Hadoop 引擎中可能要花费几分钟,尤其是在多个用户并发执行查询时。
为弥补这一差距,eBay 优化的 SQL-on-Hadoop 引擎提供了结合高可用性、安全性和可靠性的速度。其核心组件是一个定制的 Spark SQL 引擎,其构建于 Apache Spark 2.3.1,具有丰富的安全特性,例如基于软件的安全而非物理防火墙、基于视图的数据访问控制和 TLS1.2 协议。为保证新的 SQL-on-Hadoop 引擎能够在先前的专有软件和 eBay 自己的内部分析平台之间提供一个无缝的桥梁,eBay 进行了大量的优化和定制。
架构
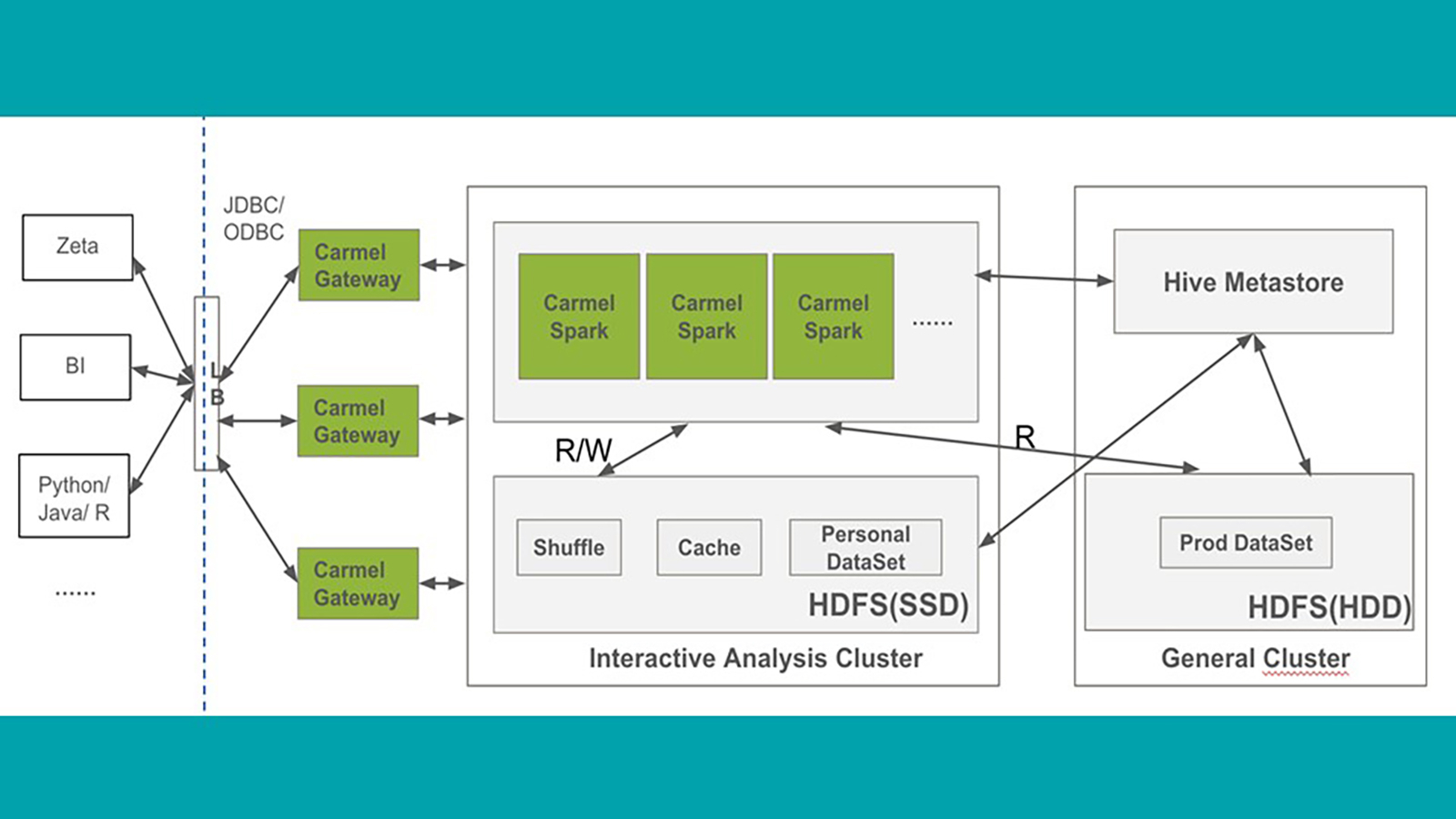
图 1
图 1 表示整体架构。Gateway 是由 Tess 部署的系统接入点。Tableau、Microstrategy 或 R 等商业智能工具,以及其他任何分析应用,都可以使用 jdbc/odbc 协议与系统连接,并运行 SQL 命令。这个 Gateway 是符合 Hive thrift 协议的,它负责客户端连接认证和流量分配。
定制的 SQL-on-Hadoop 引擎是 Spark thrift 服务器,运行在 yarn 集群中。eBay 域组织有专门的 yarn 队列,以执行各自的工作负载,从而避免资源争用。在 Spark thrift 服务器启动时,将在队列中分配和启动指定数量的执行器。thrift 服务器和执行器是帮助服务到队列来访问所有 SQL 请求的长期服务。全部表元数据存储在共享的 Hive 元存储中,该元存储驻留在一个独立的“通用集群”上,系统的执行者可以对表进行存取。
特征
存取管理
在 Gateway 中进行身份验证和集群/队列访问权限检查。当前支持两种认证机制:Keystone(eBay 的内部认证服务)和 Kerberos。另外,对于数据库或表级别的存取,该引擎具有基于 SQL 的存取控制,可由单个表所有者管理,他们可以使用查询来授予或撤销对其数据库的存取权限(下面的示例)。最后,底层的 Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)不能直接被个人用户存取。
GRANT SELECT ON table1 TO USER user1;GRANT SELECT ON DATABASE db1 TO USER user1;GRANT SELECT ON table1 TO ROLE role1;GRANT INSERT ON table1 TO USER user2;
update/delete 命令
Apache Spark 默认不支持 update/delete SQL 命令。但是,这一功能在供应商平台上被 eBay 广泛使用。用 Delta Lake 的 Spark SQL 语法更新了新的 SQL-on-Hadoop 引擎来支持这些操作。除了基本的 update/delete 外,它还支持使用 join 进行 update/delete(下面的示例)。
UPDATE eFROM events e, transaction tSET e.eventDate = t.transactionDate, e.tid = t.idWHERE e.id = t.id;
Download/Upload API
eBay 用户经常需要将大型 CSV 文件上传到现有的数据库表中,或者将大型数据集从表中下载到本地计算机。此外,与 Microstrategy 和 Tableau 等商业智能工具的整合也需要有下载大型数据集的能力。
通过为大型数据集提供强大的下载 API,新引擎可以做到这一点。这个 API 允许用户可以选择将 SQL 结果以 Parquet 或 CSV 格式保存到 HDFS,然后用户可以直接下载原始数据到客户端。与典型的 JDBC 检索 API 相比,这个 API 不需要来回的 thrift 远程过程调用(RPC)。这个引擎的新 API 支持下载超过 200GB 的文件,速度是标准 JDBC API 的四倍。
Volatile 表
eBay 用户常常在开发个人数据集或测试新的数据管道时创建大量临时表。使用“临时视图”来创建这样的临时表将导致大量复杂的 SQL 执行计划,这在用户希望分析或优化执行计划时会产生问题。为解决这一问题,对新平台进行了升级,以支持创建 “Volatile”表。Volatile 表相对于“临时视图”而言是物化的,这意味着当会话关闭时,这些表会自动丢弃,这样就可以避免用户的 SQL 执行计划变得更加复杂,同时还使他们能够快速简便地创建临时表。
其他
除上述特性外,SQL-on-Hadoop 引擎还升级了 Spark SQL 的新语法,使用户更容易编写 SQL。
Like Any/All:匹配各种模式或部分文本的函数;
用表达式删除分区:支持删除分区的特定范围或部分;
支持 Compact 表:用于将 HDFS 中的小文件合并为大文件,避免因小文件过多而影响扫描性能;以及
在“insert into”语句中 Supporting column 列表规范:语法使其能够与第三方工具(如 Adobe)进行集成。
查询加速
SQL 执行性能是这次迁移的一个重要组成部分。要求用户提供执行速度,以满足供应商系统性能。为达到这个目的,我们采用了多种查询加速的功能和技术。
透明数据缓存
生产数据集存储在共享的 Hadoop 集群中,而大多数生产数据集都很庞大。这个集群由所有域的团队共享,并且总是非常忙碌。所以,当用户希望存取生产数据集时,新的 SQL-on-Hadoop 引擎无法扫描共享集群的 HDFS,因为共享集群的不稳定会影响扫描性能。
与此相反,用于临时分析的集群是具有 SSD 存储的专用 Hadoop 集群,因此比共享集群更加稳定和快速。透明的数据缓存层被引入到专用的分析集群,以便对经常存取的数据集进行缓存。airflow 作业定期检查从共享集群复制的底层生产数据集的更改。当作业检测到一个缓存数据集有更改时,使用 DISTCP 命令将变化的数据复制到缓存的 HDFS 中。
对用户来说,数据缓存层是透明的。这样就保证了用户总是能检索到最新的数据,同时也将扫描速度提高了 4 倍,使得新平台更稳定。
索引
SQL 用户需要能够扫描大型数据集的一小部分,举例来说,分析用户的事务行为或者收集用户访问页面的统计数据。这类情况下,扫描整个数据集可能效率低下,并且浪费宝贵的系统资源。
Spark 提供了创建 bucket/partition 表的选项来解决这个问题,但是它仍然缺乏灵活性,因为 bucket/partition 在表创建之后就被固定了。新的 SQL-on-Hadoop 引擎升级了索引功能,以支持这类用例。索引与数据文件无关,因此可以根据需要应用或删除它们。
目前,新平台支持布隆过滤器(Bloom filter)类型的索引。布隆过滤器是一种节省空间的数据结构,用于测试一个元素是否是一个集合的成员。有可能出现假阳性匹配,但不可能出现假阴性。这个新引擎支持以 SQL 为 Parquet 格式的表创建和删除布隆过滤器索引,以及文件级和行组级的布隆过滤器。
索引数据由两部分组成:索引文件和索引元数据文件。为了避免过多的 HDFS 小文件,为一组数据文件创建一个索引文件,索引元数据文件描述了索引文件。索引文件和元数据文件的格式如下:

在用户的 SQL 语句命中索引后,新引擎向 Spark 执行器端传递索引元数据,以供任务执行,而任务会相应地裁剪文件或行组。
自适应查询执行
在 Spark 3.0 中,自适应查询执行(Adaptive Query Execution,AQE)是一项非常高效的特性。许多情况下,它可以显著地改善 SQL 性能。(AQE 介绍和实现文档可以在这个博客中找到)。这个新平台将向后移植到 AQE,并对代码进行了修改,使其与我们的 Hadoop-Spark 系统所基于的 Spark 2.3 版本相兼容。另外,AQE 也做了一些改进,使 Skew Join 处理得更好。
原始的 Skwe Join 只能处理基本的 sort-merge join 情况。join 操作符的左右子项必须是 sort-and-shuffle 操作符,如下图 2 所示:
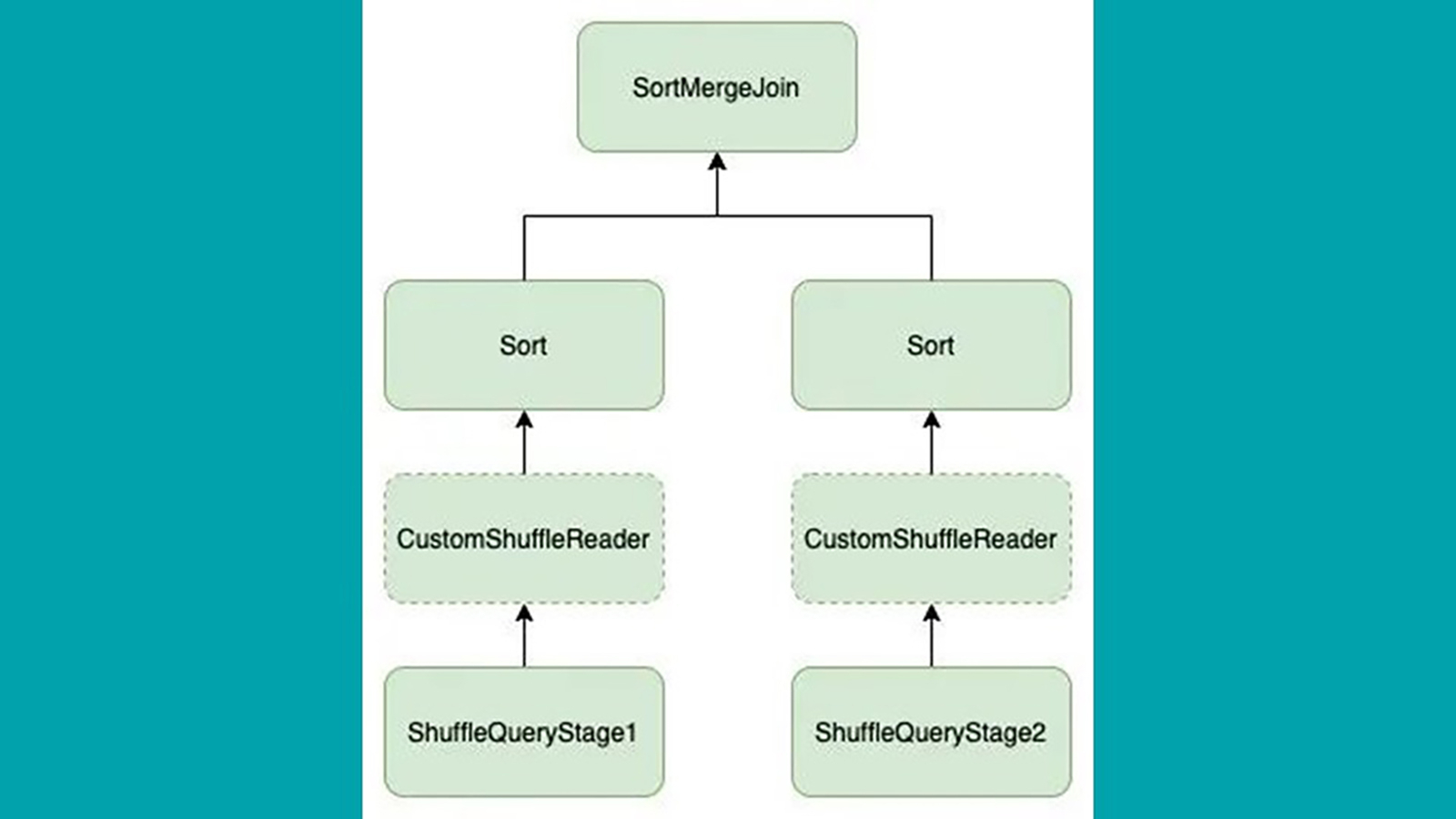
图 2
但是,在新引擎中,SQL 会遇到不符合上述模式的 Skwe Join。AQE 被扩展以适应更多的情况:
支持 Join,其中一边是 bucket 表:
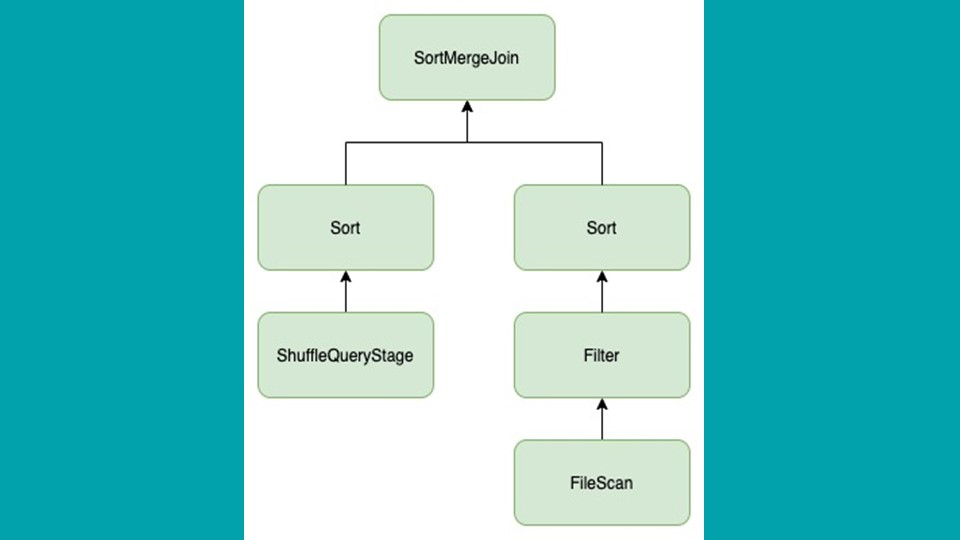
将新的操作符添加到 bucket 表端: PartitionRecombinationExec,以及在进行 Skew Join 处理时需要多次读取的重复分区。
支持聚合:
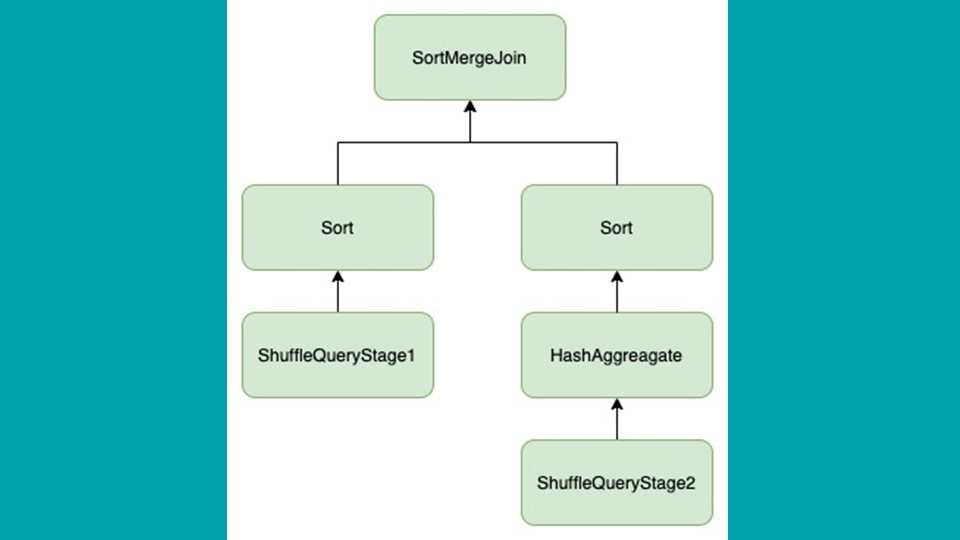
Skew Join 处理并不能保证每个操作符的结果都是正确的。举例来说,在上面的执行计划中,当左侧是 Skew 时,应用 Skew Join 后,HashAggregate 的结果可能不正确,因为它会在某些分区上重复读操作。使用 SortMergeJoin 后,结果将是正确的,因为在 SortMergeJoin 操作符中会删除重复记录。
Bucket 改进
eBay 的大多数数据表都有一个 Bucket 布局,更适合于“sort-merge join”,因为它们不需要额外的 shuffle-and-sort 操作。但是,如果表有不同的 Bucket 大小,或者 Join 键与 Bucket 键不同,会发生什么?新的 SQL-on-Hadoop 引擎可以通过 “MergeSort”或“Re-bucketing”优化特性处理这种情况。
如果表 A 的 Bucket 大小为 100,而表 B 的 Bucket 大小为 500,那么这两个表在被连接之前都需要进行 shuffle。“MergeSort”特性将确定表 A 和表 B 的 Bucket 大小的比值为 1:5,并将表 B 中的每五个 Bucket 合并为一个,从而使其总体 Bucket 大小达到 100—,与表 A 的 Bucket 大小相匹配。同理,重新 Bucketing 将采用 Bucket 大小较小的表(表 A),并将每个 Bucket 进一步划分为五个 Bucket,从而将其 Bucket 大小增加到 500,并在执行 Join 操作之前与表 B 的 Bucket 大小相匹配。
Parquet 读取优化
eBay 的大部分数据都是以 Parquet 格式存储的。新引擎为读取 Parquet 文件提供了许多优化机会,例如:
减少 parquet read RPC 的调用:社区版的 Spark 在读取 Parquet 文件时需要对 Hadoop namenode 进行多次调用,包括读取页脚、获取文件状态、读取文件内容等。在这个新的平台上,整个读取过程都被优化,namenode 的 RPC 调用减少了三分之一。
引入多线程的文件扫描:在 Spark 中,当扫描表为 Bucket 表时,任务号通常与 Bucket 号相同。有些表非常大,但是 Bucket 号没有足够大来避免在 HDFS 中创建过多的小文件。举例来说,表 A 是一个分区和 Bucket 表,按照日期列进行分区,有超过 7000 分区可以存储 20 年的数据。如果 Bucket 号设置为 10000,那么这个表在 HDFS 中将拥有超过 70000000 个文件。因此,解决方案是让 Bucket 号变小,这样一个任务就需要扫描多个大文件。如果文件位于共享的 HDFS 中,数据读取会成为 SQL 执行的瓶颈。因此 eBay 开发了多线程文件扫描功能。如果任务需要扫描多个文件,那么可以将多个线程配置为扫描。有时,它能使表的扫描速度提高三到四倍。
向 Parquet 下推更多的过滤器:新的 SQL-on-Hadoop 引擎的 Spark 将更多的过滤器推送到 Parquet,以减少从 HDFS 提取的数据。
动态分区裁剪与运行时过滤器
动态分区裁剪(Dynamic Partition Pruning,DPP)是 Spark 3.0 的一个新特性。它是通过在有分区表和维度表的过滤器的情况下添加一个动态分区裁剪过滤器来实现的。(详细的介绍和实现描述可以在这篇文章中找到)。这个特性提高了分区表在 Join 条件下使用分区列的 Join 查询的性能,并为新的 SQL-on-Hadoop 引擎的 Spark 版本进行了向后移植。
DPP 和 AQE 在社区版本中不能同时存在,这意味着在启用 AQE 时,DPP 将无法工作,但是新的 SQL-on-Hadoop 引擎需要这两个特性。因此,对 DPP 代码进行了重构,以使其在启用 AQE 时工作。
为了提高查询性能,新的 SQL-on-Hadoop 引擎也实现了运行时过滤器。这个实现类似于 DPP。当一个大表与一个小表进行 Join 时,从小表收集结果和统计数据,并用于扫描大表,以便在执行 Join 之前执行数据过滤器。这在某些情况下可以极大地减少 Join 记录。在下面的图 3 中,你可以看到示例说明:
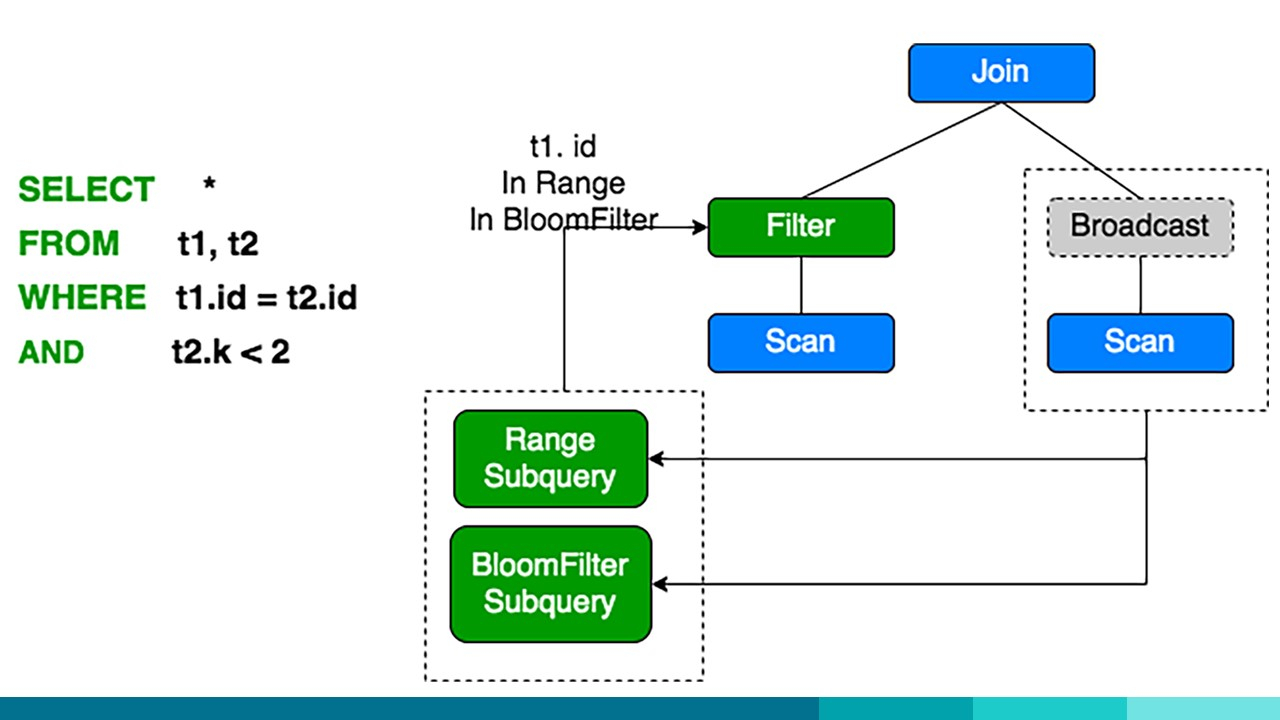
图 3
除了上述特性和策略外,还通过调度器更改、驱动程序中的锁优化、物化视图和范围分区,对查询性能进行了许多其他改进。
结果
通过本文所述的优化和定制,新引擎已经投入生产,为 eBay 的所有交互查询分析流量提供服务。它每天有超过 1200 个不同的用户,有超过 26 万个查询在新平台上运行,80% 的 SQLs 在 27 秒或更短时间内得到回答,如下图 4 所示。
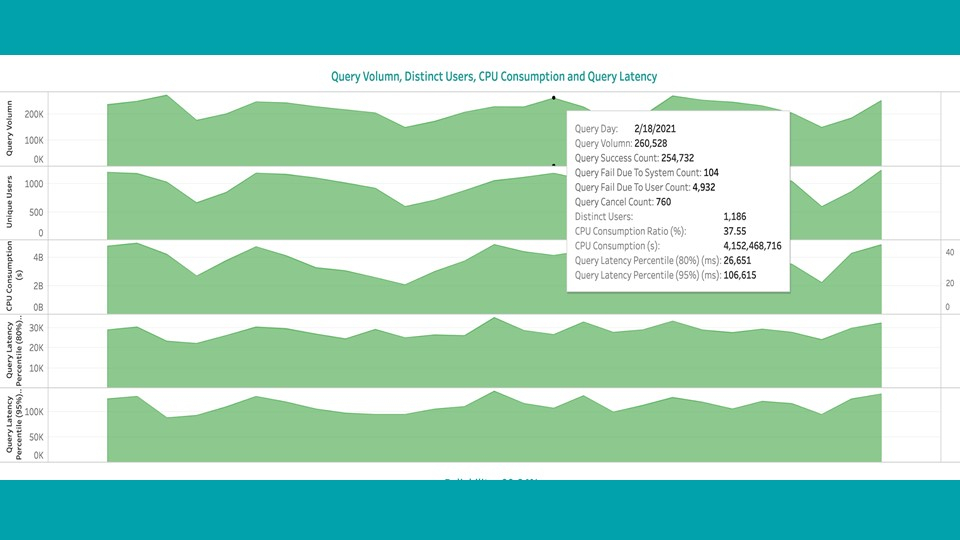
新的 SQL-on-Hadoop 引擎的强大性能是 Hadoop 在整个 eBay 顺利推广的关键因素。随着我们继续通过数据来推动 eBay 技术主导的重新构想,建立我们自己的内部解决方案,使我们处于不断增强和创新的制高点。请继续关注本系列的其他博文,其中重点介绍了我们如何建立自己的分析生态系统。
作者介绍:
本文作者为 Gang Ma、Lisa Li 和 Naveen Dhanpal。
原文链接:




