

Amazon Redshift 是一款可以扩展到 EB 级的数据仓库。如今,数以万计的 AWS 客户(包括 NTT DOCOMO、Finra 和强生)使用 Redshift 来运行任务关键性的商业智能 (BI) 控制面板、分析实时流式处理数据以及运行预测性的分析作业。
但在高峰时刻,并发查询数量猛增,这时出现了一个问题。当许多业务分析师全部打开他们的 BI 控制面板,或者长时间运行的数据学工作负载与其他工作负载竞争资源时,Redshift 将会排队执行查询,直到集群中有足够的计算资源可用。这确保了所有工作都能够完成,但也可能意味着高峰时刻的性能会受到影响。系统本身提供了两种应对方案:
超额预置集群以满足高峰需求。这种方案虽然解决了眼前的问题,但使用的资源和成本超过所需,形成了浪费。
针对典型的工作负载优化集群。采用这种方案,您在高峰时刻必须花更长的时间等待结果,可能会延误重要的商业决策。
新推出并发扩展功能
今天,我想向大家介绍第三种方案。现在,您可以配置 Redshift 以根据需要增加查询处理能力。其过程十分透明并且可在几秒钟内完成,即使工作负载增加到数百条并发查询时,也能为您提供快速、稳定的性能。增加的处理能力可以在几秒钟内准备就绪,无需预热或提前预置。您只需为实际使用的处理能力付费,账单精确至秒,并且您的主集群每运行 24 小时还将赠送一小时的并发扩展集群抵扣时间。额外的处理能力将在不再需要时取消,这种方式非常适合解决我在上文描述的突增性使用案例。
您可以将突增处理能力分配给特定的用户或队列,并且可以继续使用现有的 BI 和 ETL 应用程序。并发扩展集群用于处理多种形式的只读请求,并且在工作负载上还有更多的灵活性,请参阅并发扩展以了解更多信息。
并发扩展功能的使用
您可以在几分钟内为现有的集群启用此功能! 我们建议首先使用全新的 Redshift 参数组来进行测试,因此我首先创建了一个参数组:
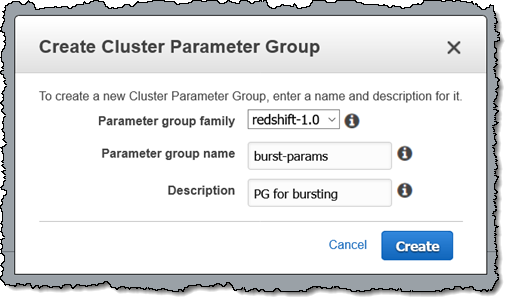
然后我编辑集群的工作负载管理配置,选中该新参数组,将 Concurrency Scaling Mode (并发扩展模式) 设置为自动,然后单击保存:
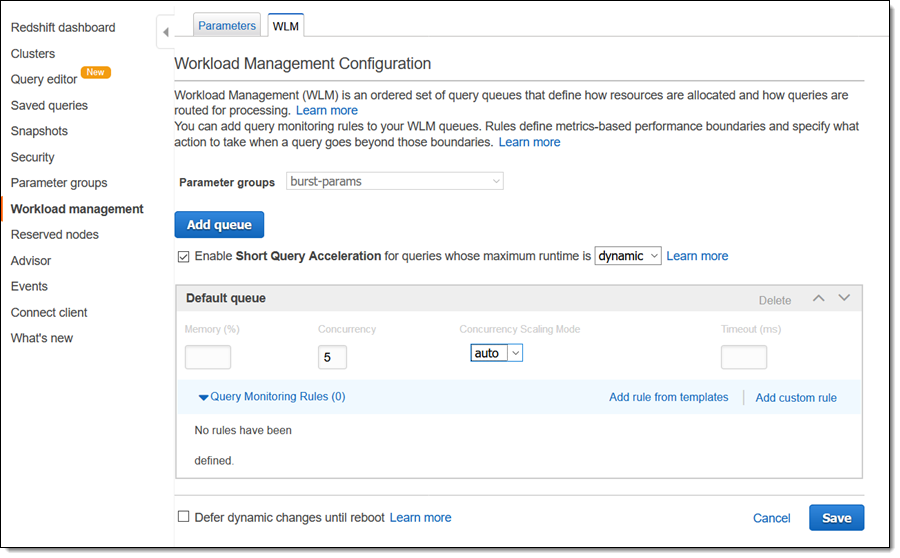
我将衍生自 TPC-DS 的云数据仓库基准作为测试数据和测试队列的源。我下载了 DDL 并使用我的 AWS 凭证进行自定义,然后使用 psql 来连接到我的集群并创建测试数据:
DDL 会创建表和负载,然后使用存储在 S3 存储桶中的数据进行填充:
然后我下载了查询并打开了一组 PuTTY 窗口,以便可以为我的 Redshift 集群生成有意义的负载:
我运行了初始的并行查询集,然后逐步增加,我可以在集群的 Cluster Performance (集群性能) 选项卡中看到它们:
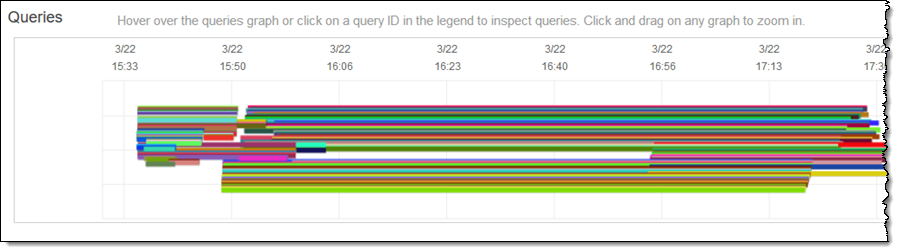
我可以在 Database Performance (数据库性能) 选项卡中看到有额外的处理能力在需要时上线,然后在不再需要时下线:
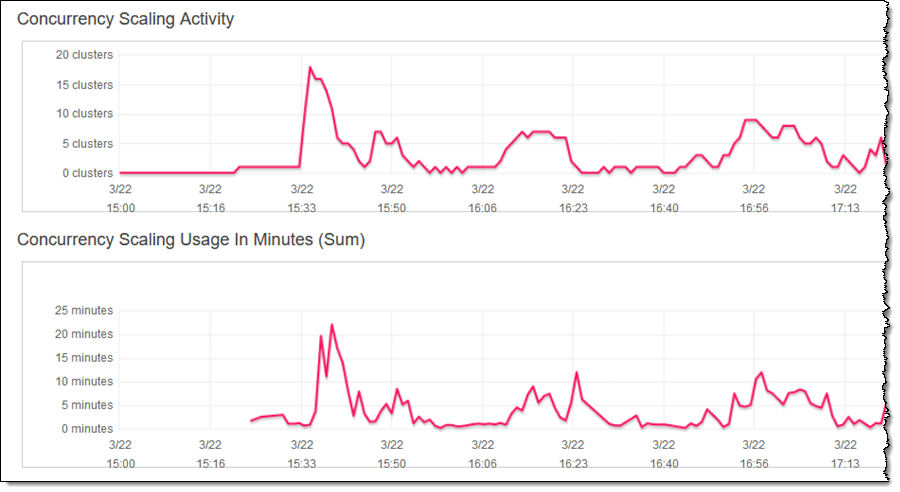
正如您可以看到,我的集群根据需要进行扩展,以尽快处理所有查询。“Concurrency Scaling Usage (并发扩展使用量)”显示了我使用额外处理能力的分钟数(正如我之前所提到,每个集群每 24 小时会累积一小时的并发扩展抵扣时间)。
我可以使用参数 max_concurrency_scaling_clusters 来控制可以使用的并发扩展集群数量(默认限制为 10,但您在需要时可以请求增加限制)。
现已推出
您现在可以立即在美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、欧洲(爱尔兰)以及亚太地区(东京)等区域使用并发扩展集群,今年还将在更多区域陆续推出。
作者介绍:
Jeff Barr
AWS 首席布道师; 2004 年开始发布博客,此后便笔耕不辍。
本文转载自 AWS 技术博客。
原文链接:


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论