

Amazon EMR 发行版 5.24.0 包含了多项 Spark 优化,提升了查询性能。为了评估性能的提升,我们使用了 3TB 级的 TPC-DS 基准查询,在一个 6 节点 c4.8xlarge EMR 集群上运行,数据存储在 Amazon S3 中。我们观察到,在以类似的配置运行时,EMR 5.24 上的查询性能要比 EMR 5.16 高 13 倍。客户将 Spark 用于多种分析使用案例,包括从大规模数据格式转换到流式处理、数据科学以及机器学习等。客户选择在 EMR 上运行 Spark,是因为 EMR 提供了稳定的最新开源社区创新,Amazon S3 高性能存储,以及 Spot 实例和 Auto Scaling 功能具有的独特节省成本优势。每个月度 EMR 发行版都提供最新的开源软件包,以及多主节点和集群重配置等新功能。该团队还通过每个发新版增加性能改进。
EMR 5.17 包含了对 S3 Select 的支持,从而允许 Spark 将数据筛选功能直接下推至 S3。
EMR 5.19 包含了经 S3 优化的提交程序,提高了 S3 文件系统操作的性能。
EMR 5.22 默认采用更大型号和更高性能的 EBS 卷,以提高性能并增加 IOPS。
所有这些优化都有利于您提高运行速度和降低成本。EMR 5.24 也推出了多项新的优化,本博文中将详细介绍三项关键优化。
设置
要开始使用 EMR,请登录控制台,启动集群,然后处理数据。
要复制基准查询的设置,请使用如下配置:
在集群上安装应用程序:Ganglia、Hive、Spark、Hadoop(默认安装)。
EMR 发行版:EMR 5.24.0
集群配置
主实例组:1 个 c4.8xlarge 实例,配 512GiB GP2 EBS 存储(4 个 128GiB 的卷)
核心实例组:5 个 c4.8xlarge 实例,配 512GiB GP2 EBS 存储(4 个 128GiB 的卷)
使用 TPC-DS 基准查询观测到的结果
下面的两张图比较了两个 EMR 发行版运行 TPC-DS 3TB 查询数据集中全部查询的总累计运行时和几何均值。
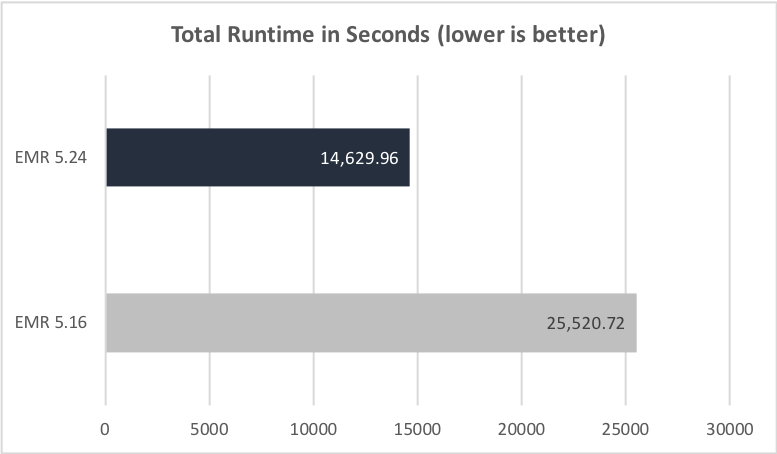
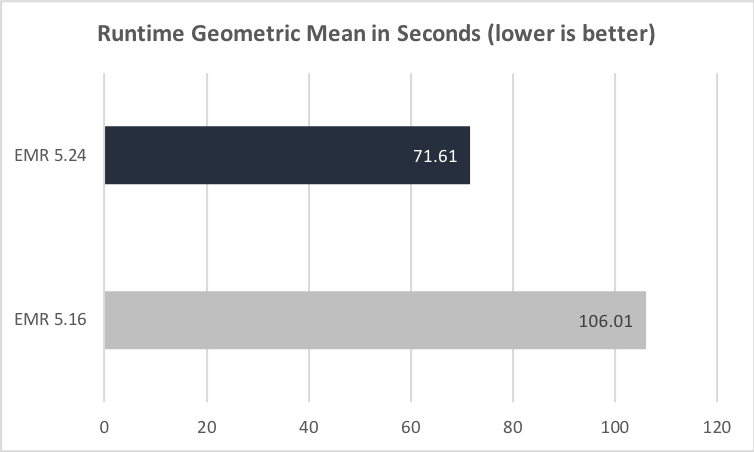
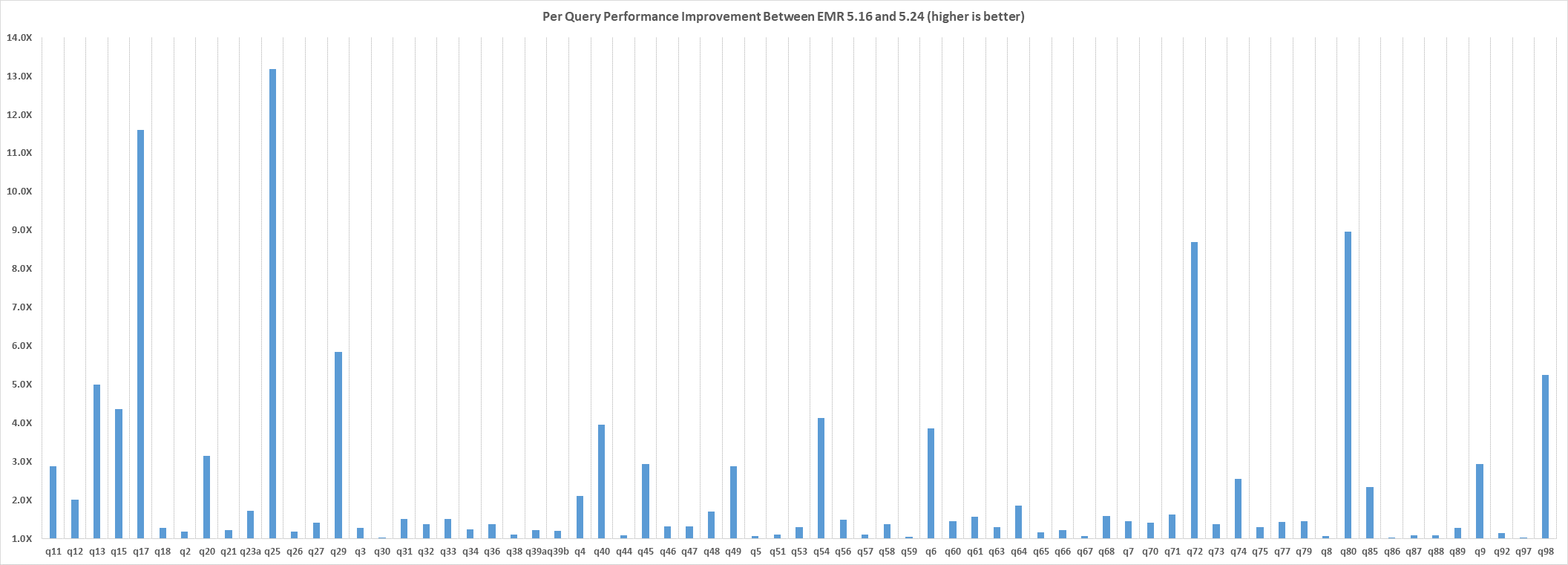
下面的插图也显示了 EMR 5.16 和 EMR 5.24 之间的查询前运行时改进。横轴为 TPC-DS 3 TB 基准中的每个查询。纵轴为按照查询时间衡量,EMR 5.24.0 相比于 EMR 5.16.0 的性能提升量级。其中 26 个查询的性能提升最大。对于每个这些查询,性能至少比 EMR 5.16 提高了 2 倍。
EMR 5.24 中的性能优化
总体速度的提升是 AWS 多次增量性能改进的结果,本博文介绍了 EMR 5.24 中对最常用客户工作负载有影响的三项重要改进:
动态分区修整
扁平化标量子查询
求交集前先去重
动态分区修整
动态分区修整通过选择表内必须为某个查询读取和处理的特定分区来提高作业性能。由于减少了读取和处理的数据量,查询运行的速度更快。开源版 Spark (2.4.2) 仅支持下推可以在计划时解析的静态断言。以下几个都是静态断言下推的例子:
partition_col = 5
partition_col IN (1,3,5)
partition_col BETWEEN 1 AND 3
partition_col = 1 + 3
开启动态分区修整时,EMR 上的 Spark 将会推断必须在运行时读取的分区。动态分区修整功能会默认禁用,可以从 Spark 中或在创建集群时通过设置 Spark 属性 spark.sql.dynamicPartitionPruning.enabled 启用。有关更多信息,请参阅配置 Spark。
下面的示例将两张表合并,同时依靠动态分区修整来提升性能。store_sales 表包含按区域分隔的总销售数据,store_regions 表包含了各个国家/地区的区域映射。在此代表性的查询中,您仅需要获得某个特定国家/地区的数据。
如果没有启用动态分区修整,此查询会读取所有区域,然后筛选与子查询结果匹配的区域子集。启用动态分区修整后,将仅读取和处理子查询中返回的区域的分区。这将减少从存储读取的数据量以及处理的记录量,从而节省了时间和资源。
下图显示了我们使用 3TB 数据对 TPC-DS 套件进行测试时,查询 72、80、17 和 25 的性能改进结果。
扁平化标量子查询
通过这项优化,必须将多个条件应用到特定表的行,从而提高了查询性能。采用这项优化后,不再需要为每个条件多次读取表。这项优化会检测到此类情形,并对查询进行优化以确保仅读取表一次。
扁平化标量子查询功能会默认禁用,可以从 Spark 中或在创建集群时通过设置 Spark 属性 spark.sql.optimizer.flattenScalarSubqueriesWithAggregates.enabled 启用。
为了演示此项优化的工作原理,我们使用了与上一项优化相同的 total_sales 表。在此例中,您需要在门店的平均销售额介于特定的范围内时,按照平均销售额对门店进行分组。
禁用此项优化时,每个子查询都会读取 total_sales 表。启用此项优化后,会按如下方式重写查询,从而将每个条件应用到返回的行,仅读取该表一次。
这项优化减少了从存储读取的数据量以及处理的记录量,从而节省了时间和资源。
为帮助说明,我们以 TPCDS 套件的 Q9 为例。在启用相关 Spark 属性时,5.24 版的查询运行速度比 5.16 版提高了 2.9 倍。
求交集前先去重
在求两个集合的交集时,该交集的结果是在两个集合都中找到的唯一值的集。在处理大型集合时,必须处理并在主机之间清理许多重复的记录,从而最终计算交集。这项优化在计算交集前去除每个集合中的重复值,通过减少要在主机之间清理的数据量来提高性能。
此项优化会默认禁用,可以从 Spark 中或在创建集群时通过设置 Spark 属性 spark.sql.optimizer.distinctBeforeIntersect.enabled 启用。
例如(TPC-DS 查询 14 简化),您需要找到在门店以及目录销售渠道同时出售的所有品牌。在此例中,store_sales 表包含通过门店渠道完成的销售,catalog_sales 表包含通过目录渠道完成的销售,而 item 表包含了每个独特产品的参数(例如品牌、制造商)。
禁用这项优化时,第一个 SELECT 语句会生成 2600000 条记录(与 store_sales 表的记录数相同),但仅有 1200 个独特品牌。第二个 SELECT 语句生成了 1500000 条记录(与 catalog_sales 表的记录数相同),包含 300 个独特品牌。这会将全部 4100000 行注入求交集运算中,以得出两个结果中都存在的 200 个品牌。
启用这项优化后,每个集合将首先执行去重运算,然后再注入求交集运算,结果只有 1200 + 300 条记录注入求交集运算。这项优化通过减少主机之间清理的数据量来节省时间和资源。
小结
借助对 Apache Spark 实施的各项性能优化,EMR 5.24 将为您提供比 EMR 5.16 更好的查询性能。我们欢迎大家就这些优化如何让您的真实工作负载受益提供反馈。
我们将不断通过新的更新以改进 EMR 上的 Apache Spark 性能,请随时关注。要随时掌握最新动态,请订阅大数据博客的 RSS 源,了解更多强大的 Apache Spark 优化、配置最佳实践和调整建议。另外也不要错过以前 EMR 发行版的其他强大优化功能,例如将 S3 Select 与 Spark 结合使用以及经 EMRFS S3 优化的提交程序。
作者介绍:
Paul Codding 是 Amazon Web Services 负责 EMR 的高级产品经理。
Peter Gvozdjak 是 Amazon Web Services 负责 EMR 的高级产品经理。
Joseph Marques 是 Amazon Web Services 负责 EMR 的首席工程师。
Yuzhou Sun 是 Amazon Web Services 负责 EMR 的软件开发工程师。
Atul Payapilly 是 Amazon Web Services 负责 EMR 的软件开发工程师。
Surya Vadan Akivikolanu 是 Amazon Web Services 负责 EMR 的软件开发工程师。
本文转载自 AWS 博客。
原文链接:


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论