
本文最初发布于Pinterest Engineering技术博客,InfoQ 经翻译授权发布。
迁移背景与动机
在Pinterest,Hbase 一直是我们最关键的存储后端之一,持续为众多线上存储服务提供支持,涵盖 Zen(图数据库)、UMS(宽列数据存储)和Ixia(近实时二级索引服务)。HBase 生态系统具备一系列突出优势,例如在大容量请求中保障行级强一致性、灵活的模式选项、低延迟数据访问、Hadoop集成等,但也由于运营成本高、过于复杂和缺少二级索引/事务支持等问题,而明显无法满足未来三到五年内的客户实际需求。
在评估了十余种不同的存储后端选项,向三种入围方案导入影子流量(将生产流量异步复制至非生产环境)并开展深入性能评估之后,我们最终决定将 TiDB 选为这场统一存储服务角逐的胜出者。
如何将统一存储服务的支持职责顺利移交给TiDB,无疑是一项需要数个季度才能完成的艰难挑战。我们需要将数据从 HBase 迁移至 TiDB,重新设计并实现统一存储服务,将 Ixia/Zen/UMS 的 API 迁移至统一存储服务,再把各类离线作业由 HBase/Hadoop 生态系统迁移至 TiSpark 生态系统——而且整个过程中,现有业务的可用性和延迟 SLA 均不能受到影响。
在本篇博文中,我们将首先探讨不同数据迁移方法及其各自利弊。之后,我们再深入探究如何将数据从 HBase 迁移至 TiDB,这也是 Pinterest 第一次以零停机方式迁移一个每秒 14,000 次读取查询、400 次写入查询的 4 TB 大表。最后,我们将共同验证这套新方案能否实现 99.999%的数据一致性,并了解如何衡量两个表之间的数据一致性。
数据迁移策略
一般来讲,零停机时间数据迁移的实施策略可以概括为以下几点:
假定已有数据库 A,需要将数据迁移至数据库 B,则首先开始对数据库 A 和 B 进行双重写入。
将数据库 A 的转储数据导入至数据库 B,并解决与实时写入间的冲突。
对两套数据集进行验证。
停止向数据库 A 写入。
当然,具体用例肯定各有不同,所以实际项目中往往会包含一些独特的挑战。
我们综合考量了各种数据迁移方法,并通过以下权衡筛选最适合我们需求的选项:
这种方式最简单也最易行。但 TiDB 后端模式提供的传输速率仅为每小时 50 GB,因此只适合对较小的表进行数据迁移。
获取 HBase 表的快照转储,并将来自 HBase cdc(变更数据捕捉)的数据流实时写入至 Kafka 主题,而后使用 Lightning 工具中的本地模式对该转储执行数据摄取。接下来,即可从服务层执行双重写入,并应用来自 Kafka 主题的全部更新。
应用 cdc 更新时往往会引发复杂冲突,因此这种方法的实施难度较高。另外,我们此前负责捕捉 HBase cdc 的自制工具只能存储键,所以还需要额外的开发工作才能满足需求。
另一种替代方案,就是直接从 cdc 中读取键,并将存储在另一数据存储内。接下来,在面向两个表的双重写入启动后,我们从数据源(HBase)读取各键的最新值并写入 TiDB。这种方法实施难度很低,不过一旦通过 cdc 存储各键的异步路径发生可用性故障,则可能引发更新丢失风险。
在评估了各项策略的利弊优劣之后,我们决定采取下面这种更加稳妥可靠的方法。
迁移工作流
术语定义
客户端:与 Thrift 服务对话的下游服务/库。
服务:用于支持在线流量的 Thrift 服务;在本次迁移用例中,服务指的是 Ixia。
MR Job:在 MapReduce 框架上运行的应用程序。
异步写入:服务向客户端返回 OK 响应,无需等待数据库响应。
同步写入:仅在收到数据库响应后,服务才向客户端返回响应。
双重写入:服务以同步或异步方式同时写入两个基础表。
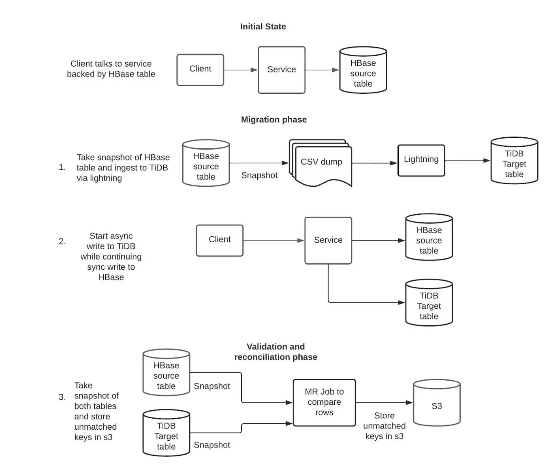
实施细节
由于 HBase 为无模式(schemaless),而 TiDB 使用严格模式,因此在着手迁移之前,需要先设计一个包含正确数据类型和索引的 schema。对于我们这个 4 TB 大小的表,HBase 和 TiDB schema 之间为 1:1 映射,也就是说 TiDB 架构会通过 MapReduce 作业来分析 HBase 行中的所有列和最大列大小,之后再分析查询以创建正确的索引。下面来看具体步骤。
我们使用 HBase SnapshotManager获取 HBase 快照,并将其以 csv 格式存储在 S3 内。各 CSV 行使用 Base64 编码,以解决特殊字符受限的问题。接下来,我们在本地模式下使用 TiDB Lightning 对这一 csv 转储执行摄取,而后进行 base64 解码,并将行存储至 TiDB 内。摄取完成且 TiDB 表上线后,即可启动对 TiDB 的异步双写。异步双写能够既保障 TiDB 的 SLA,又不影响服务 SLA。虽然我们也为 TiDB 设置了监控和分页,但此时 TiDB 仍然以影子模式运行。
使用 MapReduce 作业对 HBase 和 TiDB 表执行快照保存。各行会首先被转换为一个通用对象,再以 SequenceFile 的形式存储在 S3 内。我们使用 MR Connector 开发了一款自定义 TiDB 快照管理器,并在 HBase 中使用 SnapshotManager。
使用 MapReduce 作业读取各 SequenceFile,再将不匹配的行写回至 S3。
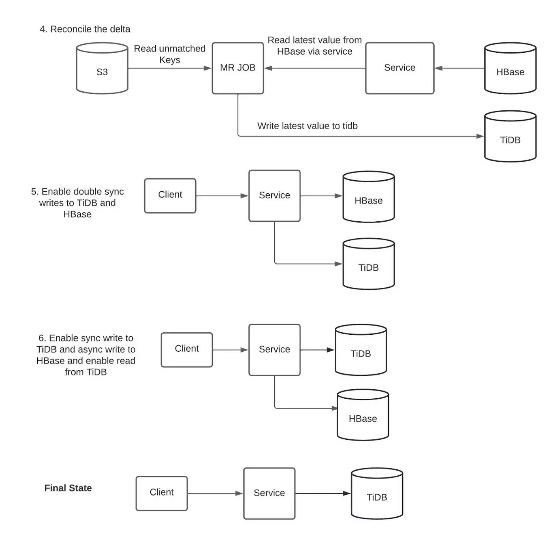
从 S3 中读取这些不匹配的行,从服务中读取其最新值(来自 HBase),再将这些值写入至辅数据库(TiDB)。
启用双重同步写入,同时向 HBase 和 TiDB 执行写入。运行步骤 3、4、5 中的协调作业,每天比较 TiDB 与 HBase 内的数据奇偶性,借此获取 TiDB 与 HBase 间数据不匹配的统计信息并进行协调。双重同步写入机制不具备回滚功能,无法解决对某一数据库的写入失败。因此必须定期运行协调作业,确保两个表间数据一致。
继续保持对 TiDB 同步写入,同时对 HBase 启用异步写入。启用对 TiDB 的读取,此阶段中的服务 SLA 将完全取决于 TiDB 的可用性。我们将继续保持对 HBase 的异步写入,尽可能继续保持双方的数据一致性,以备发生回滚需求。
彻底停止写入 HBase,弃用 HBase 表。
如何处理不一致问题
由后端不可用导致的不一致。
在 Ixia 服务层构建的双写框架无法回滚写入操作,这是为了防止因任一数据库不可用而导致局部故障。在这种情况下,就需要定期运行协调作业以保持 HBase 与 TiDB 双表同步。在修复此类不一致时,主数据库 HBase 为数据源,因此一旦出现 HBase 表写入失败、但 TiDB 表写入成功的情况,则协调过程会将这部分数据从 TiDB 中删除。
双重写入和协调过程中,因竞态条件引发的不一致。
如果事件按以下顺序发生,则可能导致将旧数据写入 TiDB:(1)协调作业从 HBase 表读取;(2)实时写入将数据同步写入至 HBase,异步写入至 TiDB;(3)协调作业将之前读取的值写入 TiDB。
此类问题可以通过多次运行协调作业来解决,每次协调都能显著减少此类不一致数量。在实践中,对于支持每秒 400 次写入查询的 4 TB 表,只需要运行一次协调作业即可在 HBase 与 TiDB 之间达成 99.999%的一致性。这项一致性指标的验证源自对 HBase 和 TiDB 表转储值的二次比较。在逐行比较之后,我们发现两表的一致性为 99.999%。
成效
我们看到,第 99 百分位处的读取延迟降低至三分之一到五分之一。在本用例中,第 99 百分位的查询延迟从 500 毫秒下降至 60 毫秒。
实现了写后读取一致性,这也是我们希望通过替换 Ixia 达成的重要目标之一。
迁移完成后,整个架构更简单、涉及的组件数量更少。这将极大改善对生产问题的调试流程。
挑战与心得
内部 TiDB 部署
由于我们没有使用 TiUP(TiDB 的一站式部署工具),所以 Pinterest 基础设施中的整个 TiDB 部署流程成了我们一次宝贵的学习经历。之所以没有选择 TiUP,是因为它有很多功能都跟 Pinterest 内部系统相互重叠(例如部署系统、运营工具自动化服务、量化管道、TLS 证书管理等),而综合二者间差异的成本会超出使用收益。
因此,我们决定继续维护自己的 TiDB 版本代码仓库和构建、发布与部署管道。集群的安全管理绝非易事、涉及大量细节,如果我们自己不努力探索,就只能把这些工作一股脑交给 TiUP。
现在我们拥有了自己的 TiDB 平台,构建在 Pinterest 的 AWS 基础设施之上。我们可以在其中实现版本升级、实例类型升级和集群扩展等操作,且不会引发任何停机。
数据摄取
在数据摄取和协调过程中,我们也遇到了不少现实问题。感谢 Pingcap 在各个环节中提供的全力支持。我们也为 TiDB 代码库贡献了一些补丁,这些成果已经由上游社区完成了合并。
TiDB Lightning 5.3.0 版本不支持自动刷新 TLS 证书,而且由于缺少相关日志而难以调试。Pinterest 的内部证书管理服务则每 12 小时刷新一次证书,所以期间总会发生一些失败的摄取操作,只能依靠 pingcap 来解决。好在证书自动刷新功能现已在 TiDB 5.4.0 版本中正式发布。
Lightning 的本地模式会在数据摄取阶段消耗大量资源,并影响到同一集群上运行的其他表的在线流量。为此,Pingcap 与我们开展合作,对 Placement Rules 做出了短期和长期修复,因此支持在线流量的副本已经不会受到本地模式的影响。
TiDB MR Connector需要进行可扩展性修复,才能把 4 TB 表的快照保存时间控制在合理范围。此外,MR Connector 的 TLS 也有改进空间,目前这些改进贡献已经完成了提交及合并。
在调优和修复之后,我们已经能够在约八小时之内摄取 4 TB 数据,且每轮协调和验证运行只需要七小时左右。
Ixia
在本轮迁移中,我们的表由 Ixia 负责支持。期间,我们在异步/同步双重写入和查询模式变更中遇到了几个可靠性问题。由于 Ixia 本身的分布式系统架构非常复杂,导致 Thrift 服务(Ixia)极难进行调试。感兴趣的朋友请参阅我们的其他博文以了解更多细节。
鸣谢
这里,我们要感谢 Pinterest 存储和缓存团队的各位前成员和现同事,谢谢大家在这场将最新 NewSQL 技术引入 Pinterest 存储堆栈的攻坚战中做出的卓越贡献。
我们还要感谢Pingcap团队为种种复杂问题提供的持续支持、联合调查和根本原因分析(RCA)。
最后,我们要感谢各位客户在此次大规模表迁移过程中表现出的耐心和支持。谢谢您的理解与配合!
原文链接:




