
作者|新浪云存储平台 - 姚国涛
本篇文章是我们做 RBD 客户端性能、IO 模式统计功能的设计实现方案,在这里整理出来,文中内容仅代表个人理解,可能有误,欢迎大家指正和探讨。
背景
对于分布式存储系统来说,除了数据可靠性、可伸缩性、可维护性等硬指标之外,性能也是一大考量指标。存储系统的性能指标可以从 Throughput、IOPS、以及 Latency 三方面来衡量。Throughput、IOPS 可以比较直观的统计出来,但是 Latency 如果以平均值来统计的话,误差可能就比较大,尤其是对于分布式系统来说,长尾延迟比较明显,更加剧了这种误差。
为什么说平均值误差可能比较大,因为每次测试结果不总是完全一样,而是有高低之分,如果高低值的差值很大,比如测试了 10 次,9 次的 latency 是 1ms,1 次是 100ms,latency 的平均值就为 10.9ms,但这个平均值完全没有反应出测试的真实情况,100ms 的那次数据可能是一个噪点,总之我们需要通过其他方式来尽可能的反应真实的测试情况。
这样就引入了百分位数统计,也就是我们常见的 P50、P90、P99 等统计结果。以上面的 10 次测试为例,P90 的 latency 为 1ms,我们能够更准确的看到的绝大部分请求是在 1ms 内完成的,有个别请求延迟较大。
在实际工作中,对于我们的分布式存储系统,长尾延迟具体情况如何?业务统计的 Latency 和后端存储的实际 Latency 能否匹配上?
分位数定义
分位数是指用分割点将一个随机变量的概率分布范围分为几个具有相同概率的连续区间。常用的有中位数(二分位数)、百分位数。
百分位数:将一组数据从小到大排序,并计算相应的累计百分点,则某百分点所对应数据的值,即为这个百分点的百分位数,用 Pk 表示第 k 百分位数。
分位数统计算法
理论上的百分位计算应该是一个精确的值,比如 90 分位,表示数据经过排序后,90% 位置上的数值。但实际上在大量数据计算时,全部数据排序是非常耗时、低效的。所以百分位统计又分精确计算和类似计算两种方案。
分位数精确计算
一个比较简单的实现是,划定一个固定的时间窗口,比如一分钟,将这一分钟的请求响应时间记录下来,并对其进行排序,计算出每分钟的百分比数据。这个算法需要相对多的 CPU 和内存成本,在一些比较简单的场景中使用没问题,在一些高吞吐、高 IOPS 的场景中,效率就比较低了。
分位数近似计算
分位数近似算法有很多种,比如 HdrHistogram 算法、q-digest 算法、GK 算法、CKMS 算法、T-Digest 算法等,其中 HdrHistogram 算法和 T-Digest 算法在软件系统中使用的比较多,T-Digest 算法用于 ElasticSearch、Kylin 等系统中,HdrHistogram 的简化版用于 Prometheus 中。下面我们简单介绍一下这两种常用算法:
静态分桶
思想:将整个存储区域以规律性的区间划分为多个桶,整个规律性的区间可以是线性增长,也可以是指数增长。每个桶只记录落在该区间的采样数量,计算分位数时,会假设每个区间也是线性分布,从而计算出具体的百分位点的数值。这样通过牺牲小部分精度,达到减小空间占用,并且统计结果大致准确的结果。
典型的实现是:https://github.com/HdrHistogram/HdrHistogram。所以后续也称之为 Histogram 算法。
缺点:统计范围有限,需要预先确定,不能改变。
示例:
假设延迟我们的服务响应时间基本在 1ms 到 50ms 之间,我可以把桶数量设置为 5 个,每个桶区间以 10ms 线性增长,就会有如下的桶:
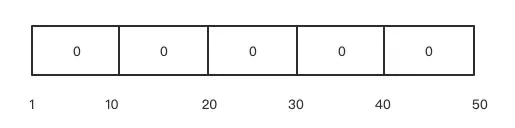
假设第一个请求响应时间为 25ms,上图中第三个桶中的数据就会累加 1;第二个请求响应时间为 15ms,上图中第二个桶中数据会累加 1。依次类推,每次请求响应后都会更新上面的桶,桶中数据只做请求数的累加。最终形成如下的桶:
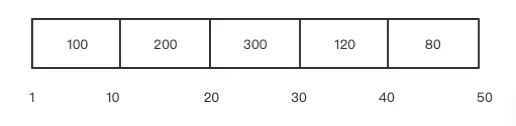
那怎么计算百分位数值呢?假设计算 P90 的延迟:
计算请求总量:总的请求数量为 800
计算第百分位数个请求数:800 * 0.9=720
计算第 720 个请求所在的桶:处于第 4 个桶中(从小到大依次计算,检查是否在该桶中)
计算处于第四个桶的具体位置:第 4 个桶的第 120 个
将第 4 个桶的区间(30-40)按照该桶的请求数量(120)等分:10/120 = 0.083
求第 4 个桶第 120 个数的具体耗时:30+0.083*120= 39.96
通过上面的计算 P90 的延迟为 39.96ms。
从上面的理论分析来看,这种算法的百分位数精准度依赖于对采样点范围有一定的了解,以及桶数量的选取,桶间距过大的话,而落在该区间的数量又过少,误差就比较大。桶间距越小,误差越小,当然带来的也是 CPU、内存成本增大,计算效率降低。
动态分桶
T-Digest 算法
思想:使用近似算法 Sketch,也就是素描,用一部分数据来描绘整体数据集的特征。T-Digest 将数据集进行分组,相邻的数据为一组,用平均数(mean)和个数(weight)来代替这一组数,我们将这两个数合称为质心数(centroid)。T-Digest 算法会形成如下的质心数:
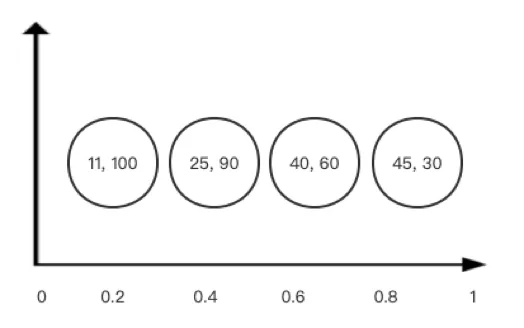
计算百分位数方法如下:
根据百分位比 q 和所有数据的总个数计算出第 N 个数为要计算的数
找出和第 N 个数相邻的两个质心数
根据两个质心数的平均数(mean)和个数(weight)使用线性插值的方式来计算出百分位数。
从上图中可以看出,最终百分位数结果的精准性依赖于质心数的个数值,质心数中的个数越多,包含的数据范围越大,越不精准,但太小的质心数又会引起质心数数量增多,增加 CPU、内存成本。T-Digest 通过百分位数来控制质心数代表的数据多少,在首尾两侧,质心数较小,精准度更高,而在中间的质心数则较大,以此达到 1%、99% 这些日常业务中更关注的数据的精确度高的效果。
开源实现为 t-digest:https://github.com/tdunning/t-digest
t-digest 使用了两种算法来实现:buffer-and-merge 算法和 AVL 树的聚类算法。
buffer-and-merge 算法:将采样数据插入到 tmp buffer 中,当 tmp buffer 满了或者需要计算百分位数的时候,将 tmp buffer 中的数据和已经 merge 的质心数进行排序合并,生成最新的质心数。合并时如果 weight 超过了上限,就会创建新的质心数,否则只修改当前质心数的平均值和个数。
AVL 树聚类算法:和 buffer-and-merge 算法相比,多了一步通过 AVL 平衡二叉树搜索数据最靠近质心数的步骤,也就是采样数据插入时,就会通过 AVL 算法搜索所属的质心数,并进行 merge。
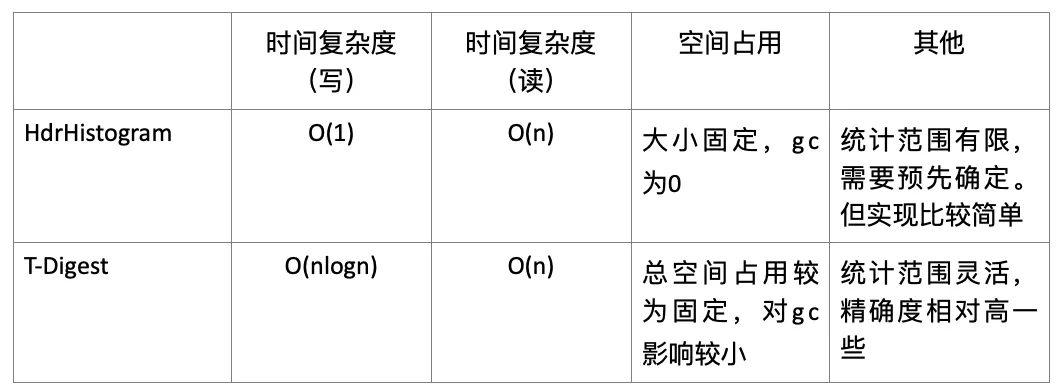
两种算法对比
Histogram 算法在 Ceph 中的应用
再看 ceph 代码,发现 ceph 的 perf counters 也实现了 perf histogram。我们简单看看 ceph 的 perf histogram 实现:
Ceph 的 PerfHistogram 类实现了 Histogram 算法,但是标准的 Histogram 算法的扩展,标准的 Histogram 算法只追踪一个维度的数据,ceph 的 PerfHistogram 实现了二维的数据追踪记录,比如一个维度记录请求大小,另一个维度记录处理时间,我们就能清晰的看到某个请求大小的处理时间是多少,这样就把两个维度关联起来。如果我们只关注其中的一个维度,也很简单,直接把不关注的那个维度所有数据求和即可。
下面我们就以 OSD 相关代码为例,看一下 ceph 的 PerfHistogram 的使用方法。
在 src/osd/osd_perf_counters.cc 文件中,初始化了通过 perf counter 和 perf histogram 追踪的性能指标。
PerfCounters *build_osd_logger(CephContext *cct) {PerfCountersBuilder osd_plb(cct, "osd", l_osd_first, l_osd_last);// Latency axis configuration for op histograms, values are in nanosecondsPerfHistogramCommon::axis_config_d op_hist_x_axis_config{"Latency (usec)",PerfHistogramCommon::SCALE_LOG2, ///< Latency in logarithmic scale0, ///< Start at 0100000,///< Quantization unit is 100usec32, ///< Enough to cover much longer than slow requests};// Op size axis configuration for op histograms, values are in bytesPerfHistogramCommon::axis_config_d op_hist_y_axis_config{"Request size (bytes)",PerfHistogramCommon::SCALE_LOG2, ///< Request size in logarithmic scale0, ///< Start at 0512, ///< Quantization unit is 512 bytes32, ///< Enough to cover requests larger than GB};...osd_plb.add_u64_counter_histogram(l_osd_op_r_lat_outb_hist,"op_r_latency_out_bytes_histogram",op_hist_x_axis_config, op_hist_y_axis_config,"Histogram of operation latency (including queue time) + data read");osd_plb.add_u64_counter_histogram(l_osd_op_w_lat_inb_hist,"op_w_latency_in_bytes_histogram",op_hist_x_axis_config, op_hist_y_axis_config,"Histogram of operation latency (including queue time) + data written");...}首先,分别定义了 X 轴、Y 轴,按照 axis_config_d 结构体中成员变量的初始化顺序,坐标轴的相关信息包含:坐标轴、坐标值增长算法、起始坐标值、坐标值单元、坐标值数量。
上面代码中的 op_hist_x_axis_config,定义了 X 轴,记录的是延迟数据,坐标值增长算法以指数增长,最小延迟为 0,坐标增长单元为 100us,一共有 32 个坐标值。
op_his_y_axis_config 定义了 Y 轴,记录的是请求大小,也是成对数级增长,最小请求为 0,坐标增长单位为 512 字节,一共有 32 个坐标值。
Ceph perf histogram 提供两种数据增长算法:Linear 和 Log2,Linear 是线性增长,适合对百分位数精度要求比较高,而且数据范围比较小的场景。Log2 是指数增长,适合对百分位数精度要求相对低,而且总的数据范围跨度较大的场景。当然精度大小还依赖于坐标增长单元。
然后通过 add_u64_counter_histogram 函数将统计项(l_osd_op_r_lat_outb_hist、l_osd_op_w_lat_inb_hist 此类统计指标)加入到 PerfCounters 实例中,后续就可以更新该指标的具体数值了。
在 PrimaryLogPG 类的 log_op_stats 函数中,更新了这些指标的数值:
void PrimaryLogPG::log_op_stats(const OpRequest& op,const uint64_t inb,const uint64_t outb){auto m = op.get_req<MOSDOp>();const utime_t now = ceph_clock_now();const utime_t latency = now - m->get_recv_stamp();const utime_t process_latency = now - op.get_dequeued_time();...else if (op.may_read()) {osd->logger->inc(l_osd_op_r);osd->logger->inc(l_osd_op_r_outb, outb);osd->logger->tinc(l_osd_op_r_lat, latency);osd->logger->hinc(l_osd_op_r_lat_outb_hist, latency.to_nsec(), outb);osd->logger->tinc(l_osd_op_r_process_lat, process_latency);} else if (op.may_write() || op.may_cache()) {osd->logger->inc(l_osd_op_w);osd->logger->inc(l_osd_op_w_inb, inb);osd->logger->tinc(l_osd_op_w_lat, latency);osd->logger->hinc(l_osd_op_w_lat_inb_hist, latency.to_nsec(), inb);osd->logger->tinc(l_osd_op_w_process_lat, process_latency);}...}在上面的代码中,PrimaryLogPG::log_op_stats 函数是 osd 中请求处理完成后回调到的,如果是读请求,使用 PerfCounters::hinc 函数更新 l_osd_op_r_lat_outb_hist 指标的延迟,同时还传了读请求大小的参数。
上面就是 ceph perf histogram 的使用方法。
我们继续跟一下 PerfCounters::hinc 的实现,具体看看 Histogram 算法实现。hinc 函数具体实现是在 PerfHistogram::inc 函数实现:
/// Increase counter for given axis values by onetemplate <typename... T>void inc(T... axis) {auto index = get_raw_index_for_value(axis...);m_rawData[index]++;}/// Calculate m_rawData index from axis valuestemplate <typename... T>int64_t get_raw_index_for_value(T... axes) const {static_assert(sizeof...(T) == DIM, "Incorrect number of arguments");return get_raw_index_internal<0>(get_bucket_for_axis, 0, axes...);}template <int level = 0, typename F, typename... T>int64_t get_raw_index_internal(F bucket_evaluator, int64_t startIndex,int64_t value, T... tail) const {static_assert(level + 1 + sizeof...(T) == DIM,"Internal consistency check");auto &ac = m_axes_config[level];auto bucket = bucket_evaluator(value, ac);return get_raw_index_internal<level + 1>(bucket_evaluator, ac.m_buckets * startIndex + bucket, tail...);}template <int level, typename F>int64_t get_raw_index_internal(F, int64_t startIndex) const {static_assert(level == DIM, "Internal consistency check");return startIndex;}上面的代码看着是不是有些晦涩?其实 inc 函数目的就是根据当前数据找到对应的直方图 bucket,并对这个 bucket 的 count 数累加。只不过这里使用了 C++11 的特性 -- 可变模版参数,它对参数进行了高度泛化,能表示 0 到任意个数、任意类型的参数。
这里不针对可变模版参数的详细的展开描述,感兴趣的同学自行搜索学习。我们只结合上面的代码看看可变模版参数怎么使用。使用可变模版参数的关键是如何展开参数包,代码中使用了可变模版参数的函数,采用递归的方式展开参数包,需要一个参数包展开的函数(第一个 get_raw_index_internal 函数就是展开函数)和一个递归终止函数用来终止递归(第二个 get_raw_index_internal 函数就是递归终止函数)。
第一个 get_raw_index_internal 函数会按 tail 参数包的顺序逐个递归调用自己,每调用一次,参数包 tail 中的参数就会少一个,直到所有 tail 参数包没有参数,此时就调用到了第二个 get_raw_index_internal 函数返回,并终止递归过程。
在当前的代码场景中,参数包中包含两个参数:x、y 两个数值,分别代表 latency、request size。第一个 get_raw_index_internal 函数的形参 value 就是可变参数展开后的具体参数值,调用过程如下:
get_raw_index_internal(get_bucket_for_axis(latency, x_config), 0, latency, request_size)
get_raw_index_internal(get_bucket_for_axis(latency, x_config), startIndex, request_size)
get_raw_index_internal(get_bucket_for_axis(latency, x_config), startIndex)
通过上面的调用,最终计算出此刻的(latency,request_size)对应的 buckets 索引。
在这里还有一个 static_assert 函数,是静态断言,在编译期间进行断言,能够在编译期间发现错误,终止编译。另外,sizeof...(T) 计算的是可变参数的个数。
RBD 性能数据统计追踪现状
经过上面的分析,我们搞清楚了 ceph perf histogram 的使用方法。但是 librbd 代码中,librbd 目前只使用了 perf counter 追踪了性能数据,比如 latency 只有平均值。
另外,现在的 ceph-mgr prometheus 模块收集到了 rbd 的性能数据,而且通过 rbd perf image iostat 也可以看到 image 的性能数据,包括读写 IOPS、读写吞吐、读写延迟。但是我们发现这个读写延迟和应用程序看到的 latency 相差挺多。
我们大致看看这套 rbd client 性能数据怎么拿到的?
在 rbd image 性能收集、计算方面,主要涉及 OSD、MGR 两大模块,OSD 类在构造函数中实例化了 MgrClient,然后在 init 函数中注册了两个函数:set_perf_queries 函数和 get_perf_reports 函数,set_perf_queries 函数是设置 perf 指标,get_perf_reports 是获取 perf 数据,这两个函数后续都会在 Mgr cleint 中调用的。
Mgr client 有定时器调用 send_report 函数发给 mgr server,send_report 就会调用前面的注册函数 get_perf_reports 来收集 osd 性能数据。Osd 的性能数据最终会从 PrimaryLogPG::log_op_stats 函数获取数据,这个函数前面提过,就不赘述了。
Mgr server 收到 mgr client 报告的性能后,按 perf 指标进行分类,保存在内存结构 Counters 中。
当使用命令行 rbd perf image iostat 查看 rbd 的性能数据时,rbd 进程会通过 mgr client 将命令请求到 mgr server,mgr server 的 rbd_support 模块来处理该命令,它会从 mgr server 上获取当前的 Counters 结构,解析出数据后返回给 client。
Mgr prometheus 模块是一个 prometheus exporter,也是定时收集数据,处理 rbd perf 数据时,和 rbd_support 基本一致,也是从 mgr server 解析当前的 Counters 结构。
看到这里,我们还是有疑问,osd 收集到的数据是具体 op 的性能数据,怎么和具体的 rbd image 关联起来。是因为 osd 收集到 op 的数据时,包含了 object id,而 object id 就是按 rbd image 进行区分的,这样一来,只需要在 rbd_support 或 prometheus 来对 osd 的数据按照 rbd image 进行分类解析,从而形成具体 rbd image 的性能数据。
到这里也就知道上层业务监控的 latency 和我们的 latency 有不小的差距的问题所在了,是因为当前在 ceph prometheus 中看到的只是 osd 处理过程的 latency。
RBD 性能及 IO 模型统计功能改造
既然当前的 mgr prometheus 监控的 rbd perf 数据不是 ceph 全 IO 路径的数据,也没有我们更关注的百分位数数据,那我们就用 ceph perf histogram 来追踪统计 rbd 性能数据,而且除此之外,是不是还可以统计到一些 IO 模式相关的数据。
现在再来梳理一下,我们想从 rbd 中拿到的相关指标,我们分为两类:
性能数据类:
IOPS、Throughput(区分读写);
具体请求大小的处理时间及其百分位数据(比如:4K 大小的请求延迟情况);
整体请求的处理时间及其百分位数据。
IO 模式类:
请求大小及其百分位数据;
读写位置及其百分位数据;
读写比例如何。
通过前面所有的分析,基本的架构也比较清楚了,我们采用如下的方式来进行监控:
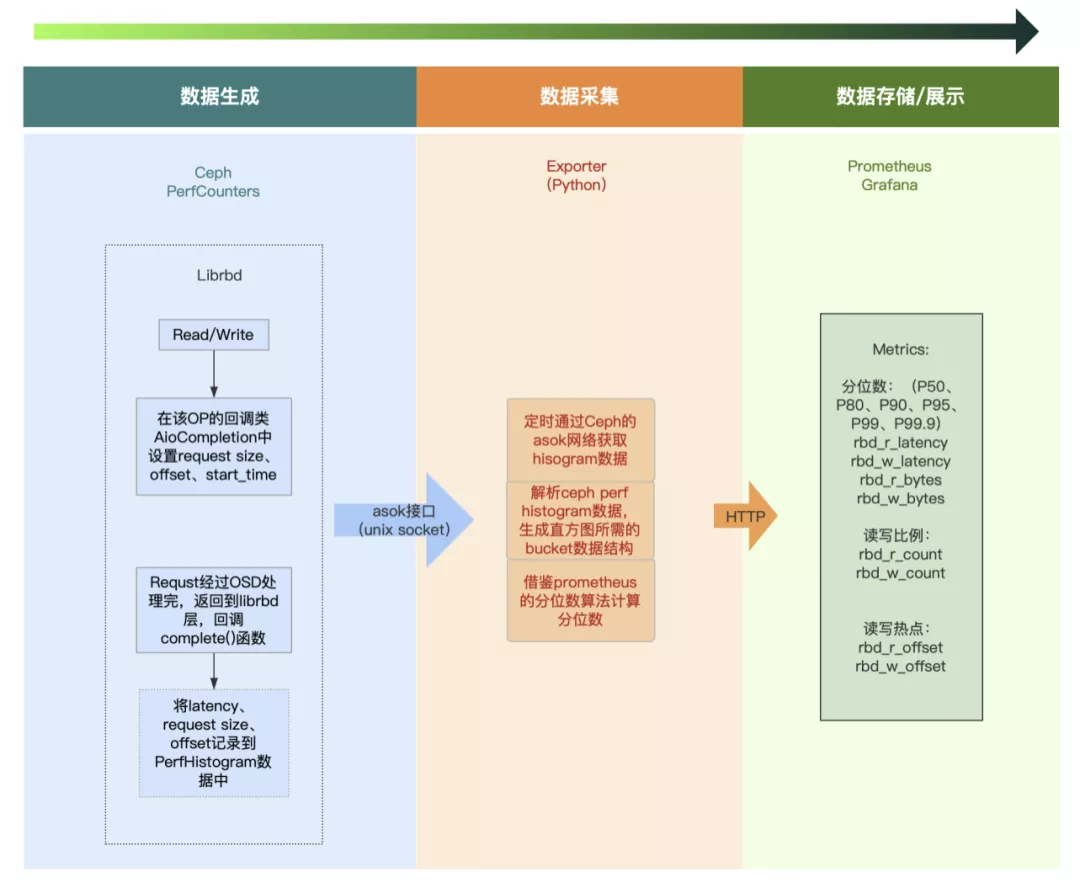
在 librbd 代码中,我们追踪两个二维的 histogram 数据,一个是 latency 和 request size,另一个是 offset 和 request size。当前的 librbd 代码中没有记录 request size 和 offset 的信息,我在 AioCompletion 类中增加了 offset 和 request size 两个变量,在 read、write 等接口创建 AioCompletion 回调类后,使用 set 方法设置这两个变量,最后在 IO 完成后,回调 AioCompletion::complete 函数的时候,根据读写类型,分别通过 PerfCounters::hinc 函数来更新统计数据。
在宿主机上部署 prometheus exporter,该 exporter 负责如下几件事:
根据宿主机上所有的 ceph client admin socket 文件,来获取其 perf histogram 数据;
实现了通过 Histogram 计算百分位数的算法,将 ceph perf histogram 吐出的数据计算成我们关注的百分位数。该算法参考的是 Prometheus 的 Histogram 函数,其是基于静态桶的实现,实现起来比较简单。
总结
我们希望通过 rbd client 端的性能数据的统计,了解我们的系统所能提供的能力,同时也为未来系统优化的方向提供数据支撑。通过 IO 模式数据的统计,来了解我们业务的 IO 模式,以此作为参考提供更优的存储方案。
参考链接:
https://blog.bcmeng.com/post/tdigest.html




