
尽管今年这世界发生很多事,但我们仍然有机会看到那么多丰硕的研究成果,特别是在人工智能领域。同时,Al 偏见和 Al 伦理也开始逐渐进入大家的视野,引起大家的普遍重视。人工智能在不断发展,我们对人类大脑以及它与人工智能的联系的理解在不断深入,在不久的将来势必将出现了不起的应用。本文将为你介绍本年度那些不容错过的最有意思的研究论文,并附上了论文链接和相关代码地址。
如果本文漏掉了那些重要的论文,欢迎在评价区留言告诉我和其他的读者小伙伴!
文末列出了引用的所有论文
在 GitHub 查阅完整列表:
https://github.com/louisfb01/Best_AI_paper_2020
观看 15 分钟时长的 2020 年度完整回放:
1、YOLOv4: 目标检测的最佳速度和精度 [1]

Alexey Bochkovsky 等人于 2020 年 4 月在论文“YOLOv4: 目标检测的最佳速度和精度”中介绍它的第 4 个版本。该算法的主要目标是制作一个高精度、高质量的超高速目标检测器。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#1
代码地址:
https://github.com/AlexeyAB/darknet
2、DeepFace rawing:依据草图深度生成人脸图像 [2]

你现在可以使用这种新的图像到图像的转换技术,依据粗糙甚至不完整的草图生成高质量的人脸图像,而你本人无需绘图技巧!如果你的画技和我一样差,你甚至可以调整眼睛、嘴巴和鼻子对最终图像的影响。让我们看看它是否真的有效,以及他们是如何做到的。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#2
代码地址:
https://github.com/IGLICT/DeepFaceDrawing-Jittor
3、英伟达研究人员用人工智能重新制作了《吃豆人》[3]
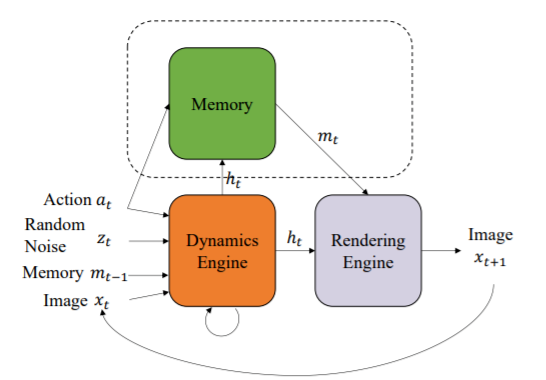
40 年前,《吃豆人》首次登陆日本的街机平台,并成为全球巨星,现在英伟达研究人员用人工智能重新制作了它。(https://blogs.nvidia.com/blog/2020/05/22/gamegan-research-pacman-anniversary/)
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#3
代码地址:
https://github.com/nv-tlabs/GameGAN_code
4、PULSE: 通过衍生模型的潜在空间探索进行自我监督的照片采样提升 [4]

这个新算法将模糊的图像转换成高分辨率的图像! 它可以把超低分辨率的 16x16 图像转换成 1080p 高清晰的人脸,人工智能让模糊的脸看起来清晰 60 倍!如若不信,就可以像我一样亲自试一试,只需不到一分钟!但首先,让我们看看他们是怎么做到的。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#4
代码地址:
https://github.com/adamian98/pulse
5、编程语言的无监督翻译 [5]

这种新模型无需任何监督即可将代码从一种编程语言转换成另一种编程语言!它可以将一个 Python 函数转换成 c++ 函数,反之亦然,而不需要任何先前的例子!它理解每种语言的语法,因此可以推广到任何编程语言!我们来看看他们是怎么做到的。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#5
代码地址:
https://github.com/facebookresearch/TransCoder?utm_source=catalyzex.com
6、用于高分辨率三维人体重建的多层次像素对齐隐式函数 [6]

这个人工智能通过 2 维图像重新生成 3 维高分辨率的人体!你只需要一张图片,哪怕是背面的,它就能生成一个三维的你,看起来一模一样!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#6
代码地址:
https://github.com/facebookresearch/pifuhd
7、高分辨率换脸技术 [7]
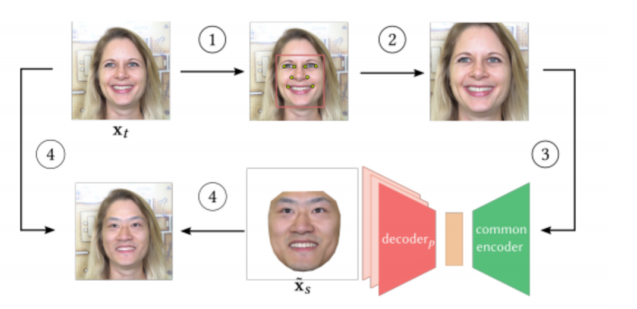
迪士尼的研究人员在同名论文中开发了一种新的高分辨率换脸算法。它能够以百万像素的分辨率渲染照片,得到逼真的视觉效果。迪士尼无疑是最适合这项工作的团队。它们的目标是在不影响演员表演的同时,将该演员替换为另一名演员的外貌。这非常具有挑战性,但在很多情况下都很需要,比如改变角色的年龄,比如该演员不在的时候,比如对于演员来说太过危险的特技场景。目前的做法需要专业人员后期处理大量的逐帧动画。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#7
8、更换自动编码器的深度图像处理 [8]
这种新技术可以改变任何图片的纹理,同时使用完全无监督的训练保持逼真效果!结果看起来甚至比 GANs 能实现的还要好,而且速度更快!它甚至可以用来制作真假难辨的赝品!

论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#8
代码地址:
https://github.com/rosinality/swapping-autoencoder-pytorch?utm_source=catalyzex.com
9、GPT-3: 实现小样本学习的语言模型 [9]

目前最先进的自然语言处理系统难以泛化推广以处理不同的任务。它们需要对数千个示例的数据集进行微调,而人类只需要看到几个示例就可以执行新的语言任务。这就是 GPT-3 想要实现的目标,改进语言模型的任务无关特性。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#9
代码地址:
https://github.com/openai/gpt-3
10、用于视频修复的联合时空变换 [10]
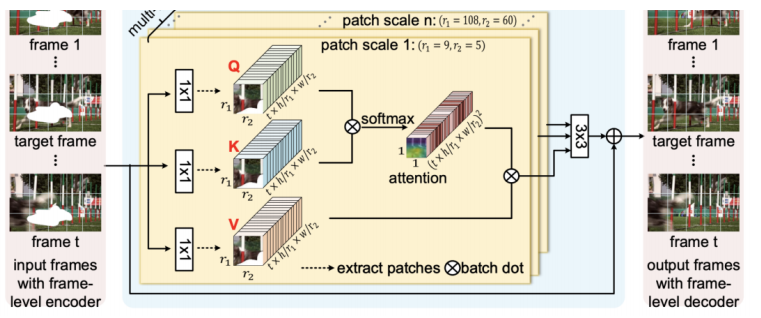
这种人工智能技术,可以填补删除了移动物体之后缺失的像素,并且可以重建整个视频。这种方法,比之前的方法都要更准确,更清晰。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#10
代码地址:
https://github.com/researchmm/STTN?utm_source=catalyzex.com
11、图像 GPT——像素级别的生成预训练 [11]
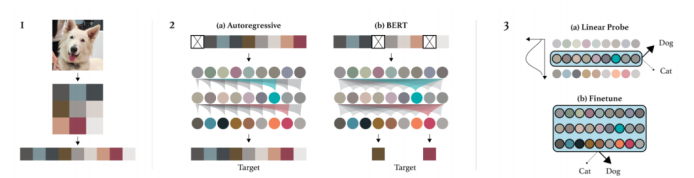
一个好的人工智能,比如 Gmail 中使用的那个,可以生成连贯的文本并补全你的短语。这张图片使用了同样的原则来完成一张图片!所有这些都是在无人监督的训练中完成的,根本不需要任何标签!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#11
代码地址:
https://github.com/openai/image-gpt
12、使用白盒卡通表示来学习卡通化 [12]
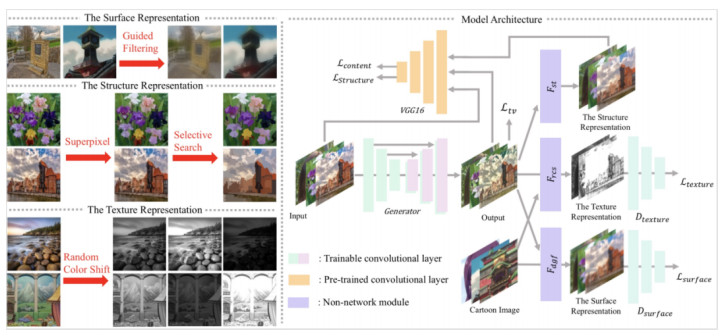
输入你想要的任意卡通风格,这个人工智能可以卡通化任何图片或视频!论文中列举了很多示例,我们可以看看它是怎么做到的。你甚至也可以像我一样自己动手尝试一下!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#12
代码地址:
https://github.com/SystemErrorWang/White-box-Cartoonization
13、FreezeG 冻结甄别器:用于微调 GAN 的一个简单基准 [13]

这个面部生成模型能够将正常的面部照片转换成独特的风格,如 Lee malnyeon 的卡通风格,辛普森一家的风格,艺术风格,甚至是狗的风格!这项新技术最好的地方是它超级简单,并且显著优于以前在 GAN 中使用的技术。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#13
代码地址:
https://github.com/sangwoomo/freezeD?utm_source=catalyzex.com
14、基于单个图像中对人物重新进行神经式渲染 [14]
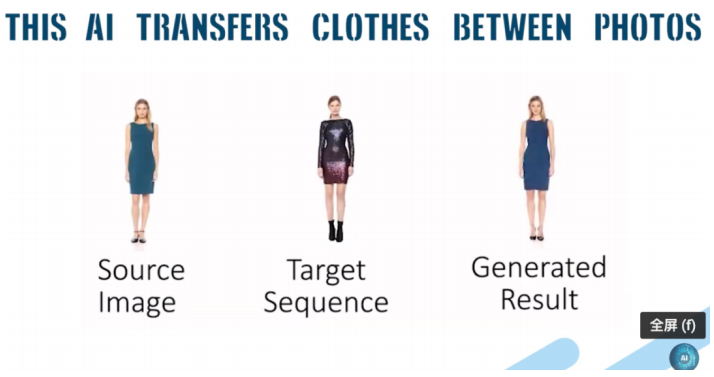
该算法将人体姿态和形状表示为一个参数网格,可以从单一图像中重构,且易于恢复。给定一个人的图像,他们能够根据另一个输入图像创建出这个人的不同姿势或不同服装的合成图像。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#14
15、I2L-MeshNet:lixel 级预测网络,用于从单一 RGB 图像精确的 3D 人体姿态和网格预测 [15]

他们的目标是提出一种新的技术,用于从单一的 RGB 图像 3D 人体姿态和网格预测。他们称之为 I2L-MeshNet。其中 I2L 表示图像到 lixe 级。正如体素(体积 + 像素)是三维空间中的量化单元一样,他们将 lixel(线和像素)定义为一维空间中的量化单元。他们的方法比以前的方法性能更好,且代码是公开的!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#15
代码地址:
https://github.com/mks0601/I2L-MeshNet_RELEASE
16、超级导航图:连续环境中的视觉语言导航 [16]

语言导航是一个被广泛研究且非常复杂的领域。的确,对一个人来说,穿过一个房间拿你放在床左边床头柜上的咖啡似乎很简单。但对于智能体来说,情况就完全不同了。智能体是一种自主的人工智能驱动系统,该系统使用深度学习来执行任务。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#16
代码地址:
https://github.com/jacobkrantz/VLN-CE
17、RAFT: 用于光流的递归全对场变换 [17]
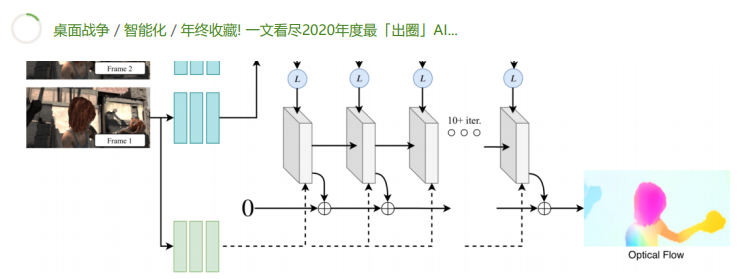
此篇论文来自于普林斯顿大学的团队,并获得 ECCV 2020 最佳论文奖。研究者开发了一种新的端到端可训练的光流模型。他们的方法超越了最先进的架构在多个数据集上的准确性,而且效率更高。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#17
代码地址:
https://github.com/princeton-vl/RAFT
18、众包抽样的全光功能 [18]

利用游客在网上公开的照片,他们能够重建一个场景的多个视点,并保留真实的阴影和光线。对于全光场景渲染来说,这是一个巨大的进步,是当前最先进的技术。他们取得了令人惊叹的成绩。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#18
代码地址:
https://github.com/zhengqili/Crowdsampling-the-Plenoptic-Function
19、通过深度潜在空间翻译来恢复老照片 [19]

想象一下,你祖母 18 岁时的老照片,充满折皱,甚至可能被撕破过,如何能够不露任何人工干预痕迹的高清照片呢?这就是所谓的旧照片修复,而这篇论文刚刚开辟了一个全新的途径来解决这个问题,那就是使用深度学习的方法。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#19
代码地址:
https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life?utm_source=catalyzex.com
20、支持可审计自治的神经回路策略 [20]
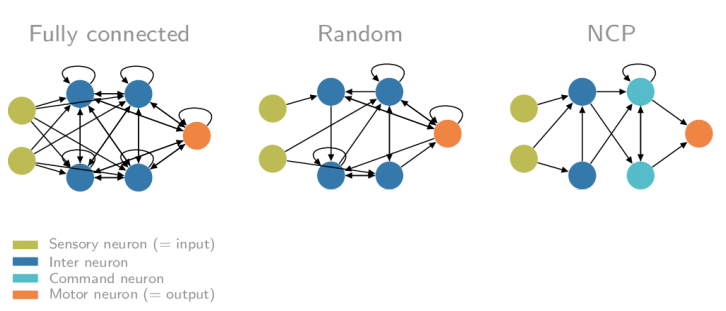
来自奥地利 IST 和麻省理工学院的研究人员已经成功地使用一种新的人工智能系统训练了一辆自动驾驶汽车,该系统基于小动物的大脑,比如蛲虫。他们只用几个神经元就能控制自动驾驶汽车,而流行的深度神经网络如“启蒙”(inveptions)、“重新网”(Resnets) 或 VGG 则需要数百万个神经元。他们的网络完全能够控制一辆汽车,只需要使用由 19 个控制神经元组成的 75000 个参数,而不是数百万个!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#20
代码地址:
https://github.com/mlech26l/keras-ncp
21、返老?还童?[21]

Adobe 研究院的一组研究人员开发了一种新的变换年龄的合成技术,该技术只基于一个人的一张照片,就它可以生成他任意年龄段的照片。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#21
代码地址:
https://github.com/royorel/Lifespan_Age_Transformation_Synthesis
22、DeOldify,黑白图像着色技术 [22]

DeOldify 是一种对旧的黑白图像甚至电影胶片进行着色和恢复的技术。它由 Jason Antic 开发,目前仍在更新中。这是现在给黑白图像着色的最先进的方法,目前所有内容都是开源的。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#22
代码地址:
https://github.com/jantic/DeOldify
23、COOT: 用于视频 - 文本表示学习的协作层次转换器 [23]
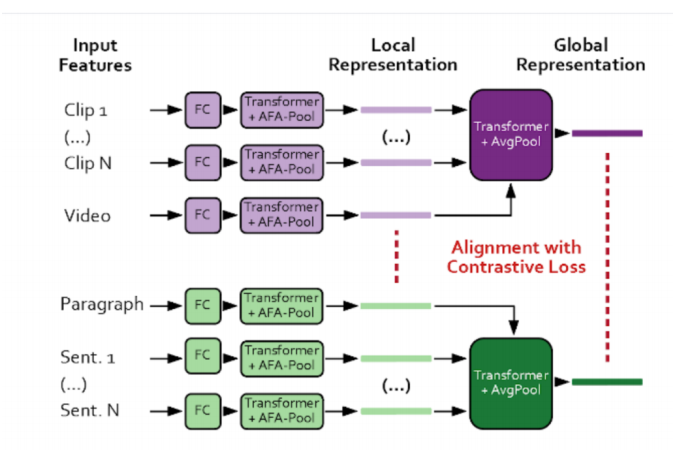
顾名思义,它将视频和对视频的一般描述作为输入,使用 transformer 为视频的每一段生成准确的文本描述。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#23
代码地址:
https://github.com/gingsi/coot-videotext
24、有风格的神经画师 [24]

这种图像到绘画的翻译方法模拟了各种风格的真实画家,它不像所有目前最先进的方法,而使用了一种不涉及任何 GAN 架构的新颖方法!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#24
代码地址:
https://github.com/jiupinjia/stylized-neural-painting
25、实时人像抠图真的需要绿幕吗?

人像抠图是一项非常有趣的任务,目标是在照片中找到任何一个人,然后把背景去掉。由于任务的复杂性,这真的很难实现,这不得不云找一个或多个拥有完美轮廓的人。在这篇论文中,作者回顾了多年来使用的最佳技术,以及 2020 年 11 月 29 日发表的一篇新方法。许多技术使用基础的计算机视觉算法来实现这一任务,例如 GrabCut 算法,它非常快,但不是非常精确。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#25
代码地址:
https://github.com/ZHKKKe/MODNet
26、ADA: 使用有限数据训练生成对抗网络 [26]

使用这种由 NVIDIA 开发的新的训练方法,你可以用十分之一的图像训练一个强大的生成模型!
造福于许多拿不到这么多图像的应用程序!
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#26
代码地址:
https://github.com/NVlabs/stylegan2-ada
27、在立方球体上使用深度卷积神经网络改进数据驱动的全球天气预测 [27]
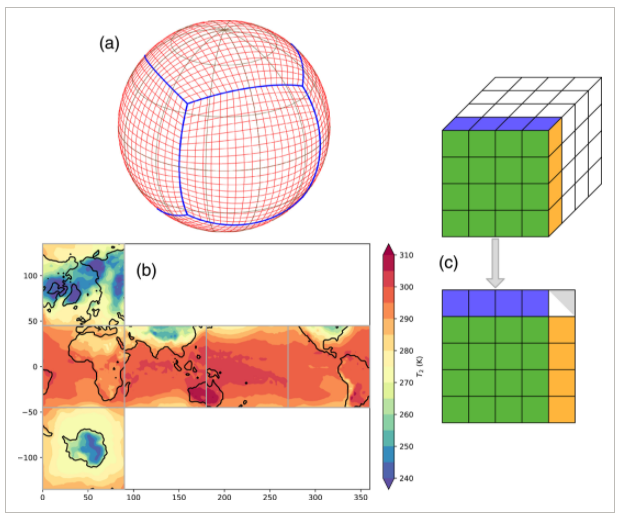
目前传统的天气预报方法使用的是我们所谓的“数值天气预报”模型。它使用大气和海洋的数学模型来根据当前的情况预测天气。它于 20 世纪 20 年代被首次引入,并在 20 世纪 50 年代通过计算机模拟产生仿真的结果。这些数学模型适用于进行短期和长期预测。但它的计算量很大,而且不能像深度神经网络那样基于那么多数据进行预测。这正是这门技术如此有前途的部分原因。目前这些数值天气预报模型已经使用机器学习作为后处理工具来改进预报。天气预报正受到机器学习研究人员越来越多的关注,已经产生了不错的结果。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#27
代码地址:
https://github.com/jweyn/DLWP-CS
28、NeRV:神经反射和可见域,用于重新照明和视图合成 [28]


这种新方法能够生成一个完整的三维场景,并能够决定场景中的照明。与以前的方法相比,所有这些都只需要非常有限的计算成本,但效果却十分惊人。
论文链接:
https://github.com/louisfb01/Best_AI_paper_2020#28
代码地址:
https://people.eecs.berkeley.edu/~pratul/nerv/
总结
如你所见,对于人工智能来说,这是极具洞察力的一年,我超级兴奋地想要看看 2021 年将会发生什么!我们将持续跟踪报道更多令人兴奋的有趣论文,如果你对人工智能研究感兴趣,欢迎保持关注!
引用论文
[1] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, 2020. arXiv:2004.10934 [cs.CV].
[2] S.-Y. Chen, W. Su, L. Gao, S. Xia, and H. Fu, “DeepFaceDrawing: Deep generation of face images from sketches,” ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH2020), vol. 39, no. 4, 72:1–72:16, 2020.
[3] S. W. Kim, Y. Zhou, J. Philion, A. Torralba, and S. Fidler, “Learning to Simulate DynamicEnvironments with GameGAN,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2020.
[4] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, Pulse: Self-supervised photo upsampling via latent space exploration of generative models, 2020. arXiv:2003.03808 [cs.CV].
[5] M.-A. Lachaux, B. Roziere, L. Chanussot, and G. Lample, Unsupervised translation of programming languages, 2020. arXiv:2006.03511 [cs.CL].
[6] S. Saito, T. Simon, J. Saragih, and H. Joo, Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization, 2020. arXiv:2004.00452 [cs.CV].
[7] J. Naruniec, L. Helminger, C. Schroers, and R. Weber, “High-resolution neural face-swapping for visual effects,” Computer Graphics Forum, vol. 39, pp. 173–184, Jul. 2020.doi:10.1111/cgf.14062.
[8] T. Park, J.-Y. Zhu, O. Wang, J. Lu, E. Shechtman, A. A. Efros, and R. Zhang,Swappingautoencoder for deep image manipulation, 2020. arXiv:2007.00653 [cs.CV].
[9] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P.Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S.Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei,“Language models are few-shot learners,” 2020. arXiv:2005.14165 [cs.CL].
[10] Y. Zeng, J. Fu, and H. Chao, Learning joint spatial-temporal transformations for video in-painting, 2020. arXiv:2007.10247 [cs.CV].
[11] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, Eds., ser. Proceedings of Machine Learning Research, vol. 119, Virtual: PMLR, 13–18 Jul 2020, pp. 1691–1703. [Online]. Available:http://proceedings.mlr.press/v119/chen20s.html.
[12] Xinrui Wang and Jinze Yu, “Learning to Cartoonize Using White-box Cartoon Representations.”,IEEE Conference on Computer Vision and Pattern Recognition, June 2020.
[13] S. Mo, M. Cho, and J. Shin, Freeze the discriminator: A simple baseline for fine-tuning gans,2020. arXiv:2002.10964 [cs.CV].
[14] K. Sarkar, D. Mehta, W. Xu, V. Golyanik, and C. Theobalt, “Neural re-rendering of humans from a single image,” in European Conference on Computer Vision (ECCV), 2020.
[15] G. Moon and K. M. Lee, “I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image,” in European Conference on ComputerVision (ECCV), 2020
[16] J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” 2020. arXiv:2004.02857 [cs.CV].
[17] Z. Teed and J. Deng, Raft: Recurrent all-pairs field transforms for optical flow, 2020. arXiv:2003.12039 [cs.CV].
[18] Z. Li, W. Xian, A. Davis, and N. Snavely, “Crowdsampling the plenoptic function,” inProc.European Conference on Computer Vision (ECCV), 2020.
[19] Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, and F. Wen, Old photo restoration via deep latent space translation, 2020. arXiv:2009.07047 [cs.CV].
[20] Lechner, M., Hasani, R., Amini, A.et al.Neural circuit policies enabling auditable autonomy.Nat Mach Intell2,642–652 (2020).https://doi.org/10.1038/s42256-020-00237-3
[21] R. Or-El, S. Sengupta, O. Fried, E. Shechtman, and I. Kemelmacher-Shlizerman, “Lifespanage transformation synthesis,” in Proceedings of the European Conference on Computer Vision(ECCV), 2020.
[22] Jason Antic, Creator of DeOldify,https://github.com/jantic/DeOldify
[23] S. Ging, M. Zolfaghari, H. Pirsiavash, and T. Brox, “Coot: Cooperative hierarchical trans-former for video-text representation learning,” in Conference on Neural Information ProcessingSystems, 2020.
[24] Z. Zou, T. Shi, S. Qiu, Y. Yuan, and Z. Shi, Stylized neural painting, 2020. arXiv:2011.08114[cs.CV].
[25] Z. Ke, K. Li, Y. Zhou, Q. Wu, X. Mao, Q. Yan, and R. W. Lau, “Is a green screen really necessary for real-time portrait matting?” ArXiv, vol. abs/2011.11961, 2020.
[26] T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, Training generative adversarial networks with limited data, 2020. arXiv:2006.06676 [cs.CV].
[27]J. A. Weyn, D. R. Durran, and R. Caruana, “Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere”, Journal of Advances in Modeling Earth Systems, vol. 12, no. 9, Sep. 2020, issn: 1942–2466.doi:10.1029/2020ms002109
[28] P. P. Srinivasan, B. Deng, X. Zhang, M. Tancik, B. Mildenhall, and J. T. Barron, “Nerv: Neural reflectance and visibility fields for relighting and view synthesis,” in arXiv, 2020.
原文链接:
译者简介:冬雨,小小技术宅一枚,从事研发过程改进及质量改进方面的工作,关注编程、软件工程、敏捷、DevOps、云计算等领域,非常乐意将国外新鲜的 IT 资讯和深度技术文章翻译分享给大家,已翻译出版《深入敏捷测试》、《持续交付实战》。




