

本文整理自 2019 年 ArchSummit 全球架构师峰会深圳站字节跳动头条研发软件工程师江帆演讲话题《字节跳动容器化场景下的性能优化实践》。
如今在字节跳动的容器私有平台上,托管了抖音、今日头条等大量在线用户的容器。随着这些业务的快速发展,字节跳动的 Kubernetes 集群数量和规模也会越来越大,与此同时,机器的负载也会越来越高,给日常的运维工作带来了巨大的挑战。
尤其是性能问题,在系统问题排查后发现,归根结底在于内核本身的 Cgroups 隔离性和可观测性不足,不能提供所需的数据,这就给线上运维工作带来了困难,进而也阻碍了真正提升资源利用率的进程。那么在字节跳动大规模的容器化场景下,如何实现既提高机器的利用率又能兼顾成本问题呢?
传统的系统监控,治标不治本
很多人第一时间想到利用传统的系统监控去处理,但是并不能。一个很重要的原因,我们常用到的系统监控,包括像 cAdvisor,Atop 等等,这些系统监控的一个弊端是,只能看到内核暴露出来的数据,也就是说,如果内核没有提供这块数据,我们就没有办法看到。如果我们希望通过修改内核,去支持一些问题的排查和新的特性,但内核的上线过程,又是一个非常痛苦和非常长期的一个过程。
我们的思路是,通过提升系统的可见性,去了解服务器之间的相互影响,进而去提升整个系统的效率,再提升资源利用率。

基于 eBPF 的系统监控,提升系统可见性
Kubernetes 实际上是一个面向应用的技术架构,它的服务资源的部署业务关心的是资源,而不是机器,它的监控系统也应该是服务级别的,而不是机器级别的,基于这些考虑,我们就引入了 eBPF。
eBPF 是一个在内核中运行的虚拟机,它可以去运行用户。在用户态实现的这种 eBPF 的代码,在内核以本地代码的形式和速度去执行,它可以跟内核的 Trace 系统相结合,给我们提供了几乎无限的可观测性。
eBPF 的基本原理——它所有的接口都是通过 BPF 系统调用来跟内核进行交互,eBPF 程序通过 LVM 和 Cline 进行编译,产生 eBPF 的字节码,通过 BPF 系统调用,加载了内核,由 5:18 去验证代码的安全性,从而通过 GIT 实时的转化成 Native 的 X86 的指令。
准确识别用户程序在各资源维度的具体行为
如果这个程序是跟内核的 Kprobe 相结合的,当它执行到我们需要 hook 那个内核函数时,就回调我们自定义的 eBPF 程序,同时它也提供了一些 Map,用来存 KV,再通过 BPF 这个系统调用,去读取数据,这一套机制,就给我们提供了几乎无限的一个可观测性。那么我们就基于 eBPF 这个内核的机制,实现了一个叫做 SysProbe 的系统监控,在 CPU 和内存层面,我们同样延续使用了 Cgroups 的一些数据,同时增加了 throttle 组线程数和状态,以及实例 Load 等更能反映实例负载真实情况的一些指标。
在 BlockIO 这层,通过识别 Hook 的 VFS 层关键的函数以及系统的调用,实现准确识别实例的读写行为。在网络 IO 这一层也是类似的情况,我们可以去探测服务的 Socket 级别的连接的状态的监控,以及它实时的 SLA,比如说 SRTT 的抖动,基于这种线程级别的数据,我们可以把它聚合到容器级别,再聚合到实例级别,这样我们就得到了一个更准确的实例级别的监控,它的核心的思想就是准确的去识别用户程序在各个资源纬度的系统行为。

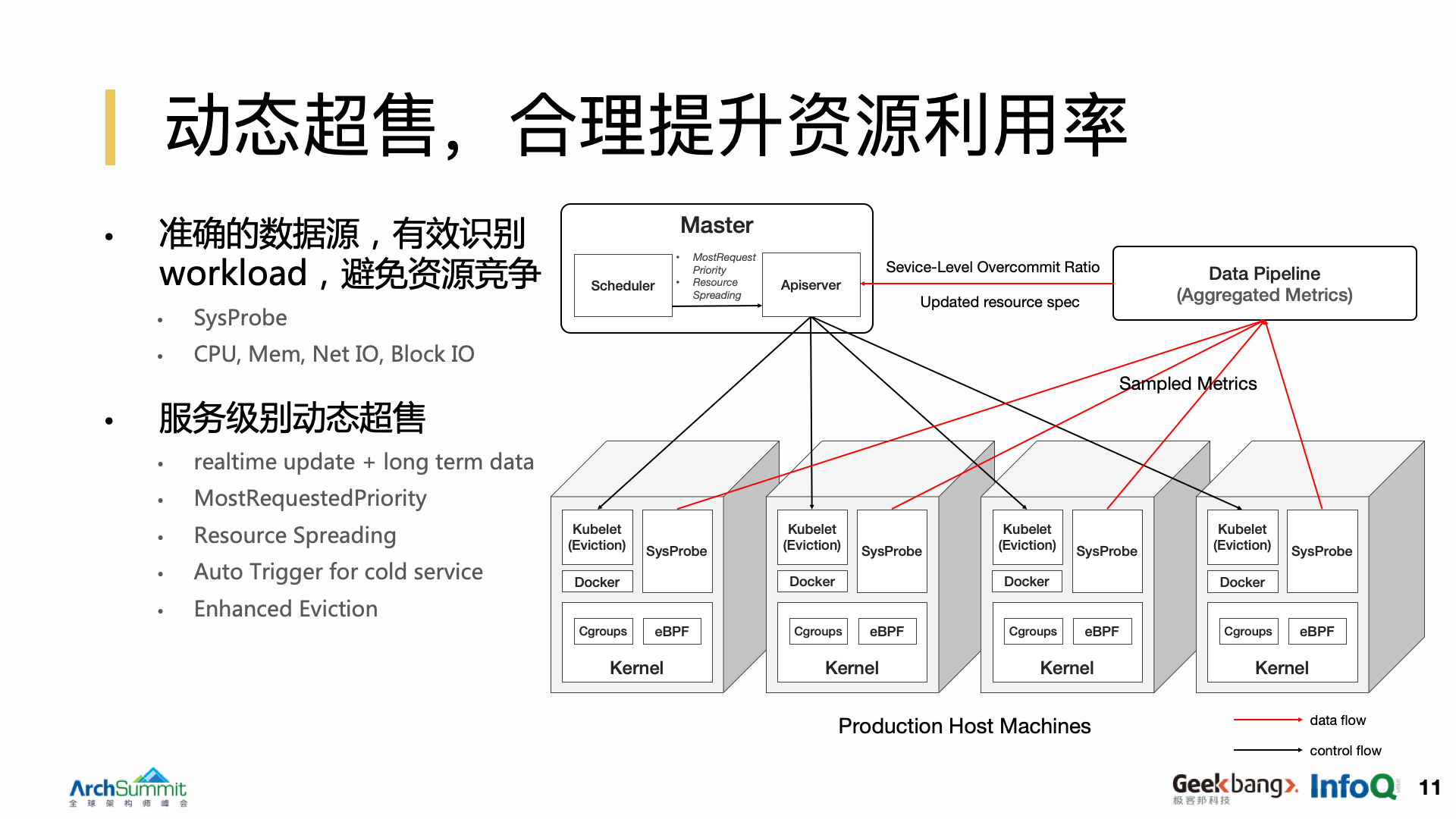
合理提升资源利用率
基于 eBPF 的系统监控,给我们提供更准确的应用行为的描述,运维根据这些数据构建一个实时的一个 Papeline,继而在调度层面去做更多的事情,比如说我们可以基于这些数据去实现一个动态的销售的提升,从管控层面去提升资源利用率。
关于调度层面影响最大的 Kubernetes 调度系统,它会把机器上的 CPU 内存尽量部署的更满,去减少 CPU 和内存的碎片。在网络 IO 和磁盘 IO 等没有被抽象成为一个可分配资源的场景下,我们会去把这两个纬度的资源去做个打散,才真正的尽量去避免实例之间的相互影响,对于一些冷服务(升级不太频繁的服务),我们会主动去促发它的一些滚动,让它去更新套餐。既然我们把机器部署的更满,那么意味着,它们可能出现更多资源被饿死和排队的情况,当出现服务过载时,我们有必要去做一些驱逐,去保证机器上的资源处于一个合理的水位。
关于驱逐的优化,主要保证在关键的资源维度上,包括 CPU 内存和磁盘空间等纬度,第一不出现浪费,第二不出现排队。对于在线服务来说,实例 Load 是一个非常重要的指标,因为它更能反映服务在内核调度器上的排队的情况,这对于我们在线服务来说非常的有用,同时我们也对它 Kubernetes 本身驱逐的机制做了一些优化,让它实受到约束,而不至于把一个服务所有实例全部驱逐。
PCT99 是影响终端用户体验的关键指标
基于 Kubernetes 管控层面调度上的优化,是否就能够把利用率提上去,同时业务也不受影响呢?这显然是不够的,对于在线服务来说,有一个很关键的指标——PCT99,在这种大型的后台的分布式这种系统里面,很有可能成为整个后台系统的一个瓶颈,最终影响到终端用户的体验。
这些问题是从 Kubernetes、Docker 这些层面是无法解释清楚的,我们必须要从更深层次去挖掘这个问题的原因。在此不得不提到 RPC 请求,探索一个完整的链路是怎样的一种形态,继而分析出来性能瓶颈究竟出在哪里。
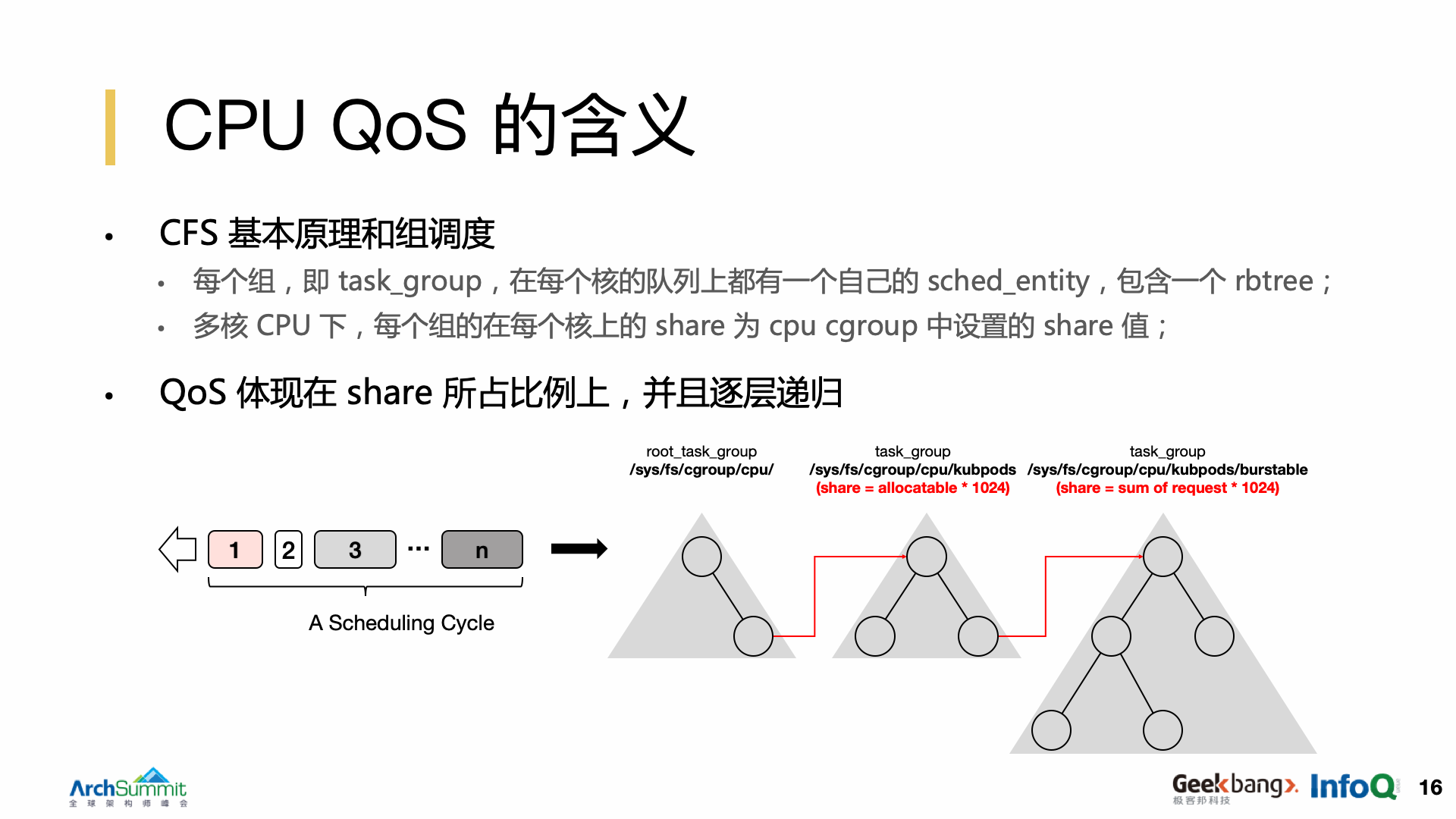
Kubernetes QoS 的深层含义
上文提到,eBPF 是一个很好的内核性能分析利器,因此基于 eBPF 我们可以对一个 RPC 请求的完成链路的延迟进行拆解分析,并确定实际产延迟主要发生在业务进程处理处理请求这个阶段,而 Kubernetes 的 CPU QoS 配置是其最重要的一个影响因素。
Kubernetes 的资源模型主要包含两个维度,即 Request 和 Limit。Request 表现出来的是 Cgroups 中的进程在 CFS 调度器上的 share,而 Limit 则是 CFS 上的带宽限制。带宽限制意味着,用户申请了两核,那么就只能使用两核的 CPU 时间。基于 Request 和 Limit 相互大小的差异,在 Kubernetes 管控层面,将 Pod 换分为三个 QoS 层级, 优先级由高到低依次是 Guaranteed、Burstable 和 Besteffort。如果我们对服务进行了超售,那么 Request 就会小于 Limit, 在我们的场景下,大部分业务 Pod 都被放置在 Burstable 层级。因此,超售在管控层面的表现是,机器上所有 Pod 的 Request 总和小于机器的可分配资源,进而小于机器上所有 Pod 的 Limit 的总和。
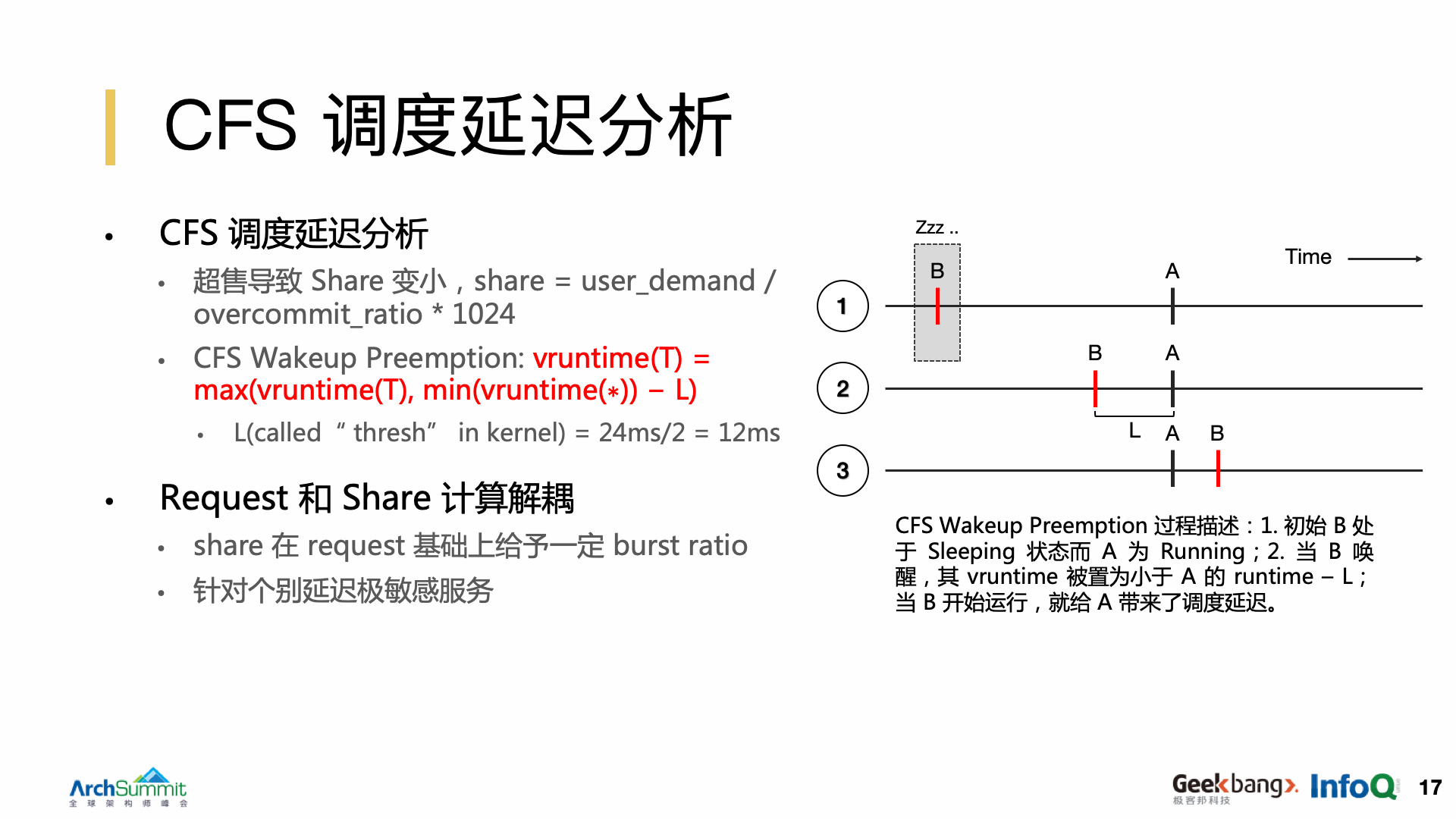
Kubernetes 对于 Cgroups 进程的优先级配置,最终会反映到 CFS 调度器上,而调度延迟是引起响应延迟抖动的主要原因。这里需要简单介绍下 CFS 调度器的基本原理。CFS 设计初衷是保证运行中进程的公平性,它会给每一个进程赋予一个权重,同时还有一个 vruntime 的概念,用于表示每个进程的累计运行时间。CFS 保证当前运行的是拥有最小 vruntime 的进程,如果进程的优先级高,则 vruntime 累计速度慢,优先级低,则 vruntime 累计速度快。组调度就是在 CFS 的基础上添加了 task_group 的概念,表示一组进程。因此在引入组调度后,一个 sched_entity 可能是一个进程,也可能是一个进程组。task_group 在每个核的队列上有一个自己 sched_entity 和一个 rbtree。基于这样一种设计,Cgroups 支持递归创建子 Cgroup。因此 QoS 的本质是 Pod 所在 Cgroup 在 CFS 上的 share 占总体的比例,并且逐层递归。
调度延迟的含义,不是进程的运行速度变慢了,而是因为调度算法导致进程本该去执行的时候没有办法分配到 CPU 时间。产生调度延迟主要包含两个方面。第一个方面是上文提到的 Kubernetes 管控层面的超售,它本质上使 Cgroup 内进程在 CFS 队列上的 share 变小了,所以在一个调度周期内运行时间相对变小。另一方面,实际上也是影响最大的一个方面,即 CFS 的唤醒抢占。其含义是,进程等待的资源就绪时,进程状态被置为 running,并被加入到调度队列等待执行,内核认为刚唤醒的进程有要事要做,会给它一些 vruntime 的补偿,将它的 vruntime 置为当前队列中所有处于运行状态的进程的 vruntime 的最小值减去 L,L 默认 12 毫秒。例如,现在有两个进程 A 和 B,A 为 running 状态而 B 为 sleeping 状态。当 B 唤醒时,其 vruntime 被置为 A 的 runtime 减去 L,并很快抢占 A 的 CPU 时间。因此在 B 的运行过程中,就给 A 带来了调度延迟。
早期在我们场景下,很多业务设置的套餐过小,比如 2C4G,他们利用率不高,但是调用下游超时的情况缺非常频繁。在当时无法从系统层面解释的情况下,业务只能通过扩容去解决,所有早期我们上容器的时候,没有节省资源,反而增加了资源的浪费。其次,对于延迟极其敏感的服务,我们在 Kubernetes 加入了一些特性,支持 share 和 Request 的计算解耦,给予业务进程一些 share 的补偿。
CFS 带宽限制和调优方法
CPU share 保证的是进程可用 CPU 时间的下限,但无法阻止进程使用超过其 quota 的 CPU 时间,因此还需要 Limit,也就是带宽限制来严格控制上限。对于 Limit,通常有两种调节技术。一种是最直观的纵向调节,也就是加大套餐核数,比如有 2C 改为 6C。这样调节的不足之处是,在数据层面,其利用率也随之变低,而这通常是业务同学不愿意看到的地方,因为业务同学会认为这是你的内核隔离机制的不完善导致他们不得不承受一个低的 ROI 的后果。另一种方式,我们其实可以横向来调节带宽限制的 quota 回填周期,即 cfs_period_us,同时保证 cfs_quota_us 与 cfs_period_us 的比值不变。如下图,矩形表示 quota 大小,曲线以下面积表示进程使用的 CPU 时间。在 100ms 时,曲线以下面积大于矩形面积,但是在 300ms 的长度上来看,前者却比后者小。通过这种横向调节技术,基本可以彻底解决在线业务被 throttle 挂起导致 RPC 超时的问题。
另一方面,我们并不仅仅从系统层面去做调优,实际上业务层面可以一起来配合做这样一件事情。在我们的场景下,很多在线业务使用 Golang 编写。在 Golang 场景下,调度延迟的问题特别常见,其原因主要有两点,一是 Golang 中常用的异步超时逻辑,即一个 select 下会有一个 timer 的 channal 和一个请求处理完成的 channel,根据上文分析唤醒抢占,timer 的响应一定会比请求处理的响应时间快,因为 server 端的 reponse 数据已经达到了 client 端,但是因为调度延时而拖慢了时间,因而出现超时。另一个原因是,Golang 的 GC、work steal 协程调度算法,非常容易在短时间内产生大量并发线程而被 CFS 带宽限制给 throttle。因此我们会在微服务框架中默认限制并发度大小。对于 Python 服务,我们则通过 lxcfs 给容器一个虚拟的 /proc 和 /sys 视图,业务进程在启动时就会只启动所分配核数的 worker 进程数。

Cgroups 调优案例
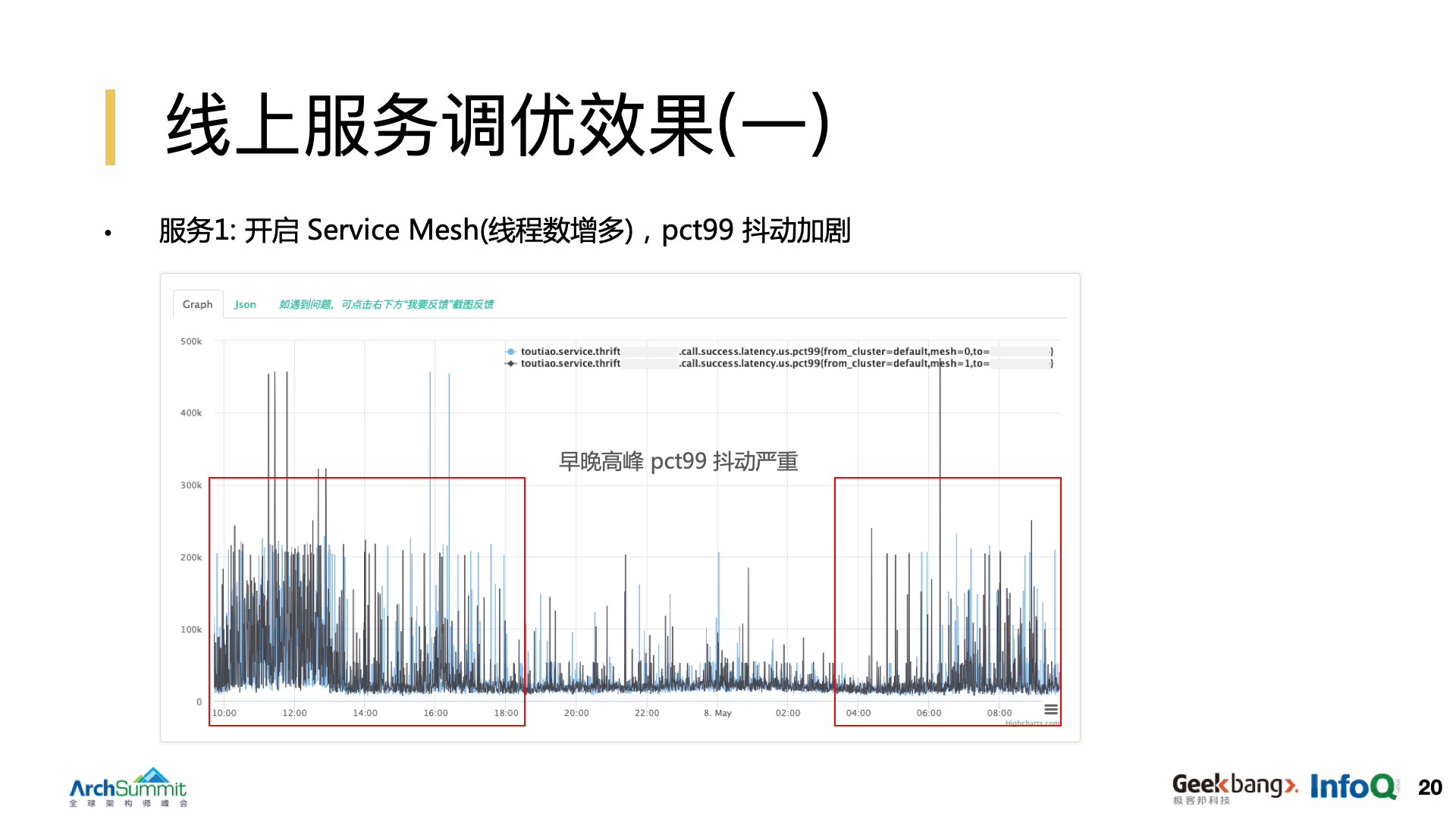
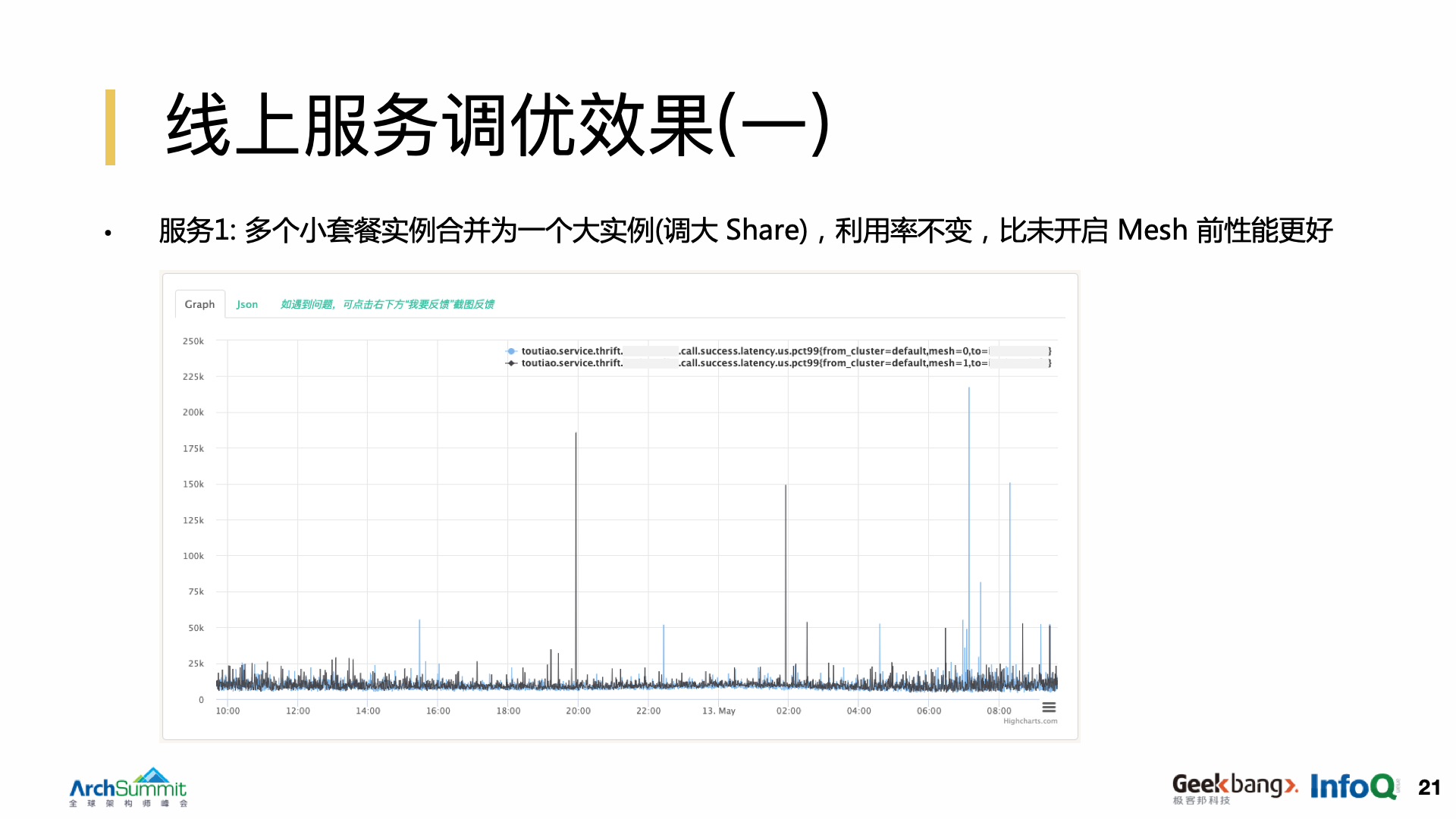
第一个服务案例。我们的场景下,Service Mesh 的 Proxy 是跟业务进程是跑在同一个容器里面的。它增加了这个容器里面的线程数,开启 mesh 以后,这个黑色的曲线是开启的,蓝色是没有开启的,我们会发现黑色比蓝色要稍微差一点,开启了 mesh 以后,他们的早晚高峰的 PCT99 抖动问题都非常的严重。我们做了一件非常简单的事情,把多个套餐合并成了一个大套餐,但实际上它整体的利用率并没有改变,整体的资源的申请量也没有改变,但是可以看到效果非常的显著,它甚至比之前没有开启 mesh 的效果还要好。
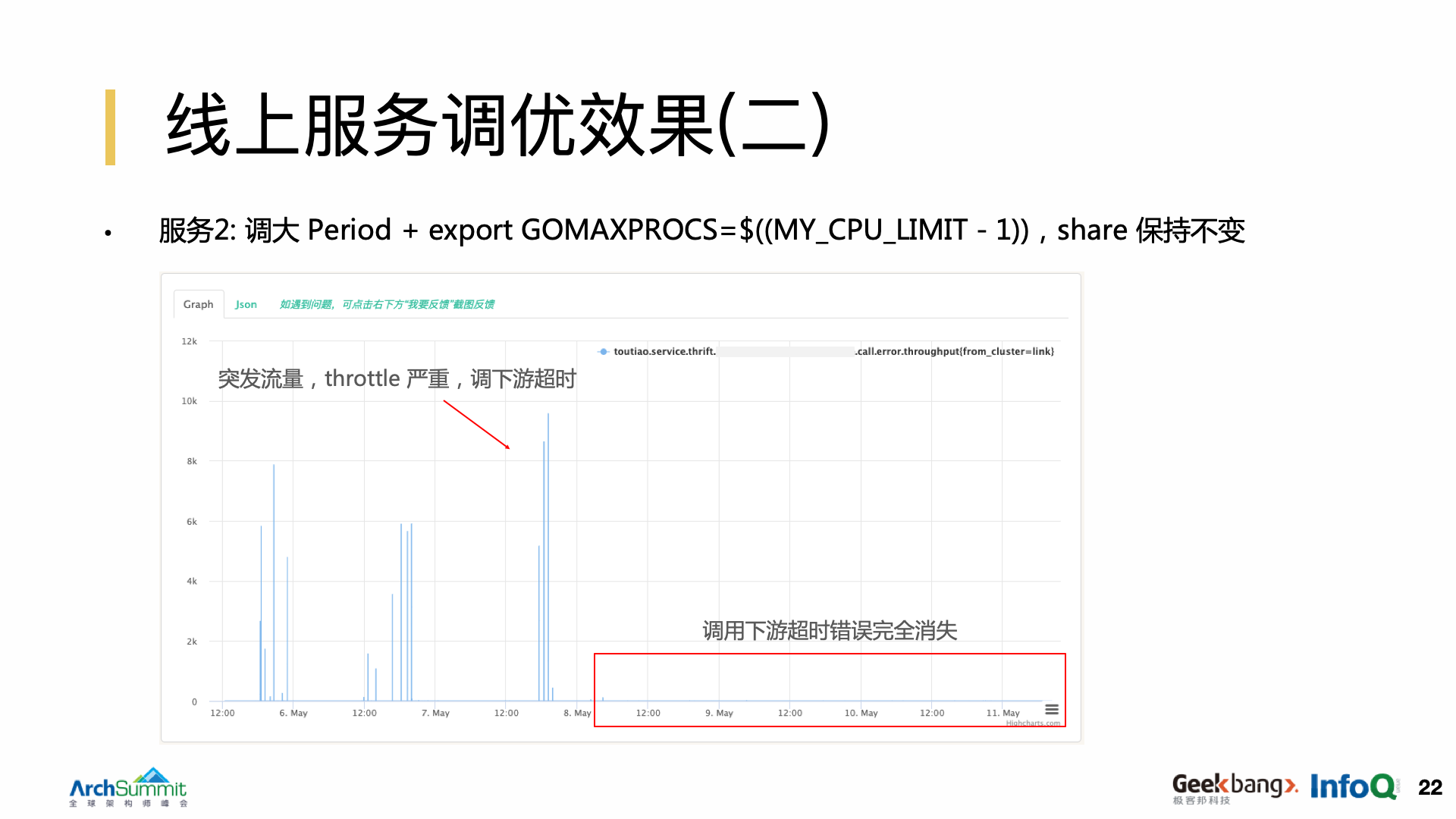
第二个服务是一个典型的在短时间内有大量的 burst 请求的服务,它会出现大量的调用下游超时,于是我们就给它就做了 period 调整,把 period 时间拉长,同时配合用户态去限制它的线程并发度,而且 share 保持不变,这时可以看到调用下游超时的情况完全消失了。
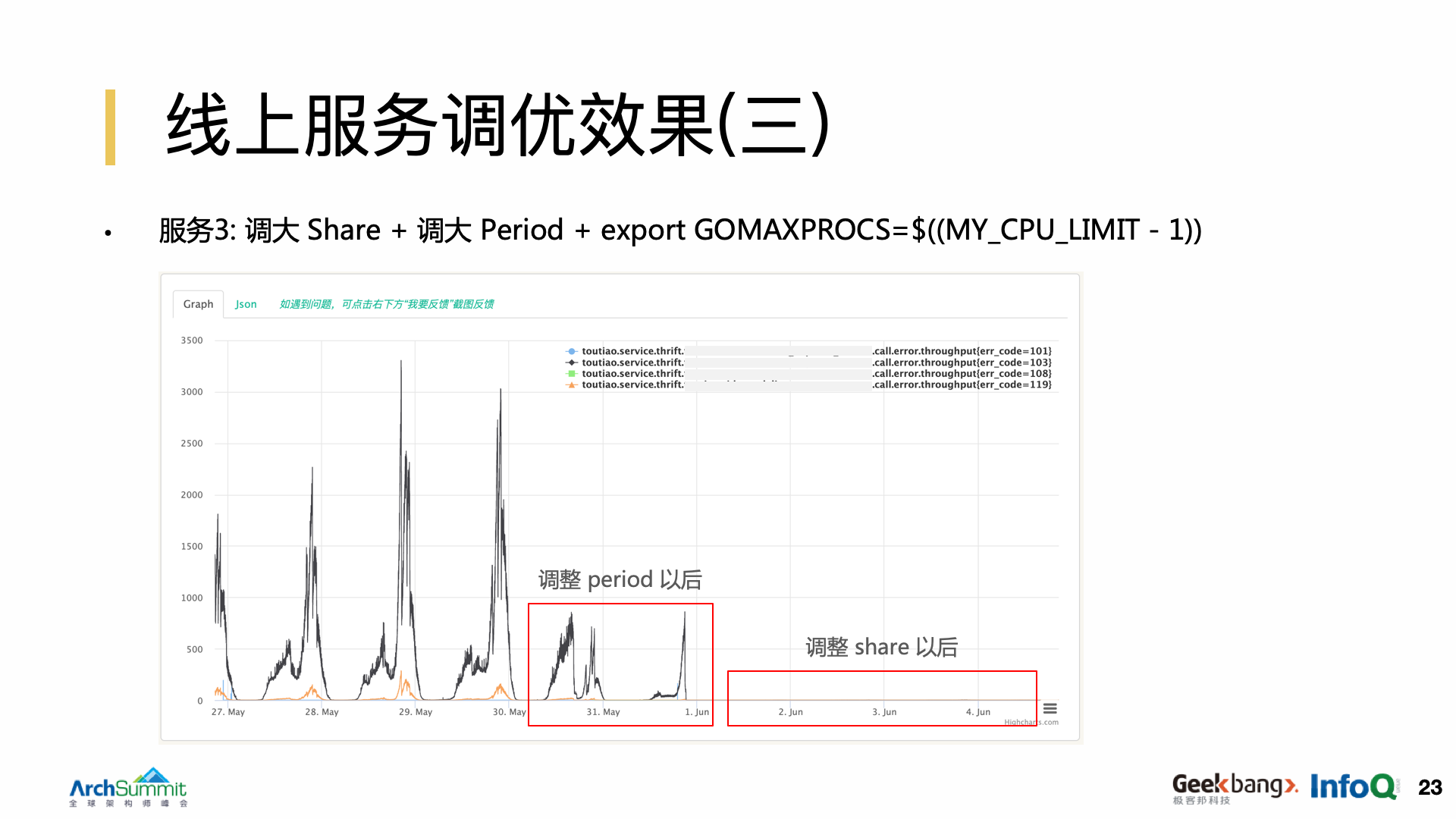
第三个服务案例,效果与上一个类似。先给它做了一个 period 调整,我们可以看到 5 月 31 号到 6 月 1 号期间,效果相对于之前来说已经好了很多,这个时候我们只调整拉长了 period,但是并没有完全解决他们的性能问题。我们又把它的套餐也调了一下,结果就看到超时情况完全消失了,效果非常的理想。
写在最后
字节跳动经过近几年来高速发展,集结和掌握了一批优质的技术资源,出品了今日头条与抖音两大国民级 App,想必其中运维与架构技术定是日趋成熟的,在容器化场景下,优化性能的优势也日益凸显。如果觉得本篇文章值得学习,欢迎继续关注Archsummit全球架构师峰会北京2019,限时 7 折大力优惠名额,有任何问题欢迎联系票务小姐姐灰灰:15600537884 (微信同号)
作者介绍:
江帆,字节跳动旗下今日头条研发软件工程师。作为早期成员,参与了 TCE 的研发工作,拥有大规模 Kubernetes 集群的开发和维护经验,熟悉由 Kubernetes 到 Docker 再到 CGroups 的整个核心链路。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论