

编者按:本文节选自图灵程序设计丛书 《Kafka 权威指南》一书中的部分章节。
为什么选择 Kafka
基于发布与订阅的消息系统那么多,为什么 Kafka 会是一个更好的选择呢?
多个生产者
Kafka 可以无缝地支持多个生产者,不管客户端在使用单个主题还是多个主题。所以它很适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。例如,一个包含了多个微服务的网站,可以为页面视图创建一个单独的主题,所有服务都以相同的消息格式向该主题写入数据。消费者应用程序会获得统一的页面视图,而无需协调来自不同生产者的数据流。
多个消费者
除了支持多个生产者外,Kafka 也支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。这与其他队列系统不同,其他队列系统的消息一旦被一个客户端读取,其他客户端就无法再读取它。另外,多个消费者可以组成一个群组,它们共享一个消息流,并保证整个群组对每个给定的消息只处理一次。
基于磁盘的数据存储
Kafka 不仅支持多个消费者,还允许消费者非实时地读取消息,这要归功于 Kafka 的数据保留特性。消息被提交到磁盘,根据设置的保留规则进行保存。每个主题可以设置单独的保留规则,以便满足不同消费者的需求,各个主题可以保留不同数量的消息。消费者可能会因为处理速度慢或突发的流量高峰导致无法及时读取消息,而持久化数据可以保证数据不会丢失。消费者可以在进行应用程序维护时离线一小段时间,而无需担心消息丢失或堵塞在生产者端。消费者可以被关闭,但消息会继续保留在 Kafka 里。消费者可以从上次中断的地方继续处理消息。
伸缩性
为了能够轻松处理大量数据,Kafka 从一开始就被设计成一个具有灵活伸缩性的系统。用户在开发阶段可以先使用单个 broker,再扩展到包含 3 个 broker 的小型开发集群,然后随着数据量不断增长,部署到生产环境的集群可能包含上百个 broker。对在线集群进行扩展丝毫不影响整体系统的可用性。也就是说,一个包含多个 broker 的集群,即使个别 broker 失效,仍然可以持续地为客户提供服务。要提高集群的容错能力,需要配置较高的复制系数。第 6 章将讨论关于复制的更多细节。
高性能
上面提到的所有特性,让 Kafka 成为了一个高性能的发布与订阅消息系统。通过横向扩展生产者、消费者和 broker,Kafka 可以轻松处理巨大的消息流。在处理大量数据的同时,它还能保证亚秒级的消息延迟。
数据生态系统
已经有很多应用程序加入到了数据处理的大军中。我们定义了输入和应用程序,负责生成数据或者把数据引入系统。我们定义了输出,它们可以是度量指标、报告或者其他类型的数据。我们创建了一些循环,使用一些组件从系统读取数据,对读取的数据进行处理,然后把它们导到数据基础设施上,以备不时之需。数据类型可以多种多样,每一种数据类型可以有不同的内容、大小和用途。
Kafka 为数据生态系统带来了循环系统,如图 1 所示。它在基础设施的各个组件之间传递消息,为所有客户端提供一致的接口。当与提供消息模式的系统集成时,生产者和消费者之间不再有紧密的耦合,也不需要在它们之间建立任何类型的直连。我们可以根据业务需要添加或移除组件,因为生产者不再关心谁在使用数据,也不关心有多少个消费者。
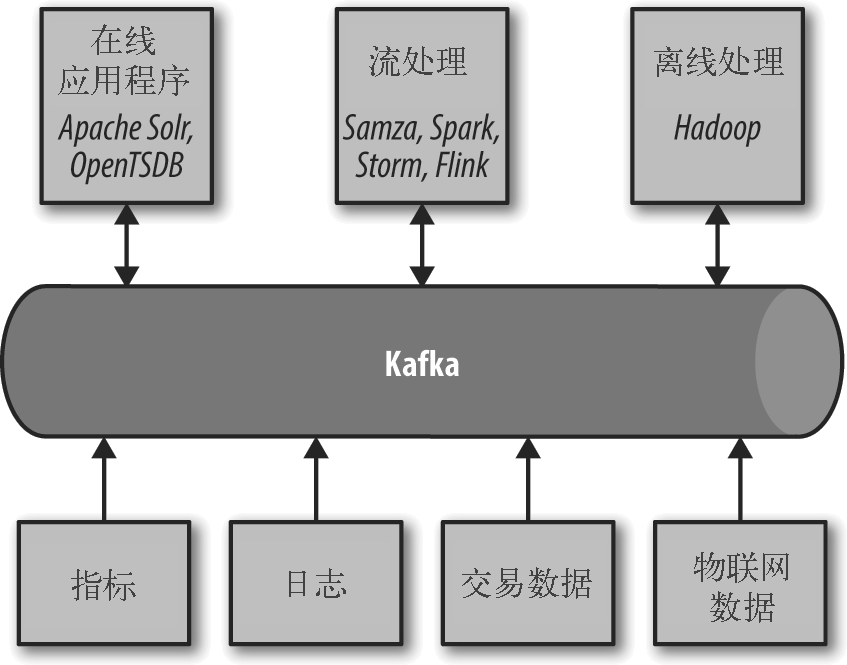
图 1:大数据生态系统
使用场景
活动跟踪
Kafka 最初的使用场景是跟踪用户的活动。网站用户与前端应用程序发生交互,前端应用程序生成用户活动相关的消息。这些消息可以是一些静态的信息,比如页面访问次数和点击量,也可以是一些复杂的操作,比如添加用户资料。这些消息被发布到一个或多个主题上,由后端应用程序负责读取。这样,我们就可以生成报告,为机器学习系统提供数据,更新搜索结果,或者实现其他更多的功能。
传递消息
Kafka 的另一个基本用途是传递消息。应用程序向用户发送通知(比如邮件)就是通过传递消息来实现的。这些应用程序组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何被发送的。一个公共应用程序会读取这些消息,对它们进行处理:
格式化消息(也就是所谓的装饰);
将多个消息放在同一个通知里发送;
根据用户配置的首选项来发送数据。
使用公共组件的好处在于,不需要在多个应用程序上开发重复的功能,而且可以在公共组件上做一些有趣的转换,比如把多个消息聚合成一个单独的通知,而这些工作是无法在其他地方完成的。
度量指标和日志记录
Kafka 也可以用于收集应用程序和系统度量指标以及日志。Kafka 支持多个生产者的特性在这个时候就可以派上用场。应用程序定期把度量指标发布到 Kafka 主题上,监控系统或告警系统读取这些消息。Kafka 也可以用在像 Hadoop 这样的离线系统上,进行较长时间片段的数据分析,比如年度增长走势预测。日志消息也可以被发布到 Kafka 主题上,然后被路由到专门的日志搜索系统(比如 Elasticsearch)或安全分析应用程序。更改目标系统(比如日志存储系统)不会影响到前端应用或聚合方法,这是 Kafka 的另一个优点。
提交日志
Kafka 的基本概念来源于提交日志,所以使用 Kafka 作为提交日志是件顺理成章的事。我们可以把数据库的更新发布到 Kafka 上,应用程序通过监控事件流来接收数据库的实时更新。这种变更日志流也可以用于把数据库的更新复制到远程系统上,或者合并多个应用程序的更新到一个单独的数据库视图上。数据持久化为变更日志提供了缓冲区,也就是说,如果消费者应用程序发生故障,可以通过重放这些日志来恢复系统状态。另外,紧凑型日志主题只为每个键保留一个变更数据,所以可以长时间使用,不需要担心消息过期问题。
流处理
流处理是又一个能提供多种类型应用程序的领域。可以说,它们提供的功能与 Hadoop 里的 map 和 reduce 有点类似,只不过它们操作的是实时数据流,而 Hadoop 则处理更长时间片段的数据,可能是几个小时或者几天,Hadoop 会对这些数据进行批处理。通过使用流式处理框架,用户可以编写小型应用程序来操作 Kafka 消息,比如计算度量指标,为其他应用程序有效地处理消息分区,或者对来自多个数据源的消息进行转换。第 11 章将通过其他案例介绍流处理。
图书简介:https://www.ituring.com.cn/book/2067

相关阅读

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论