各位热爱 AI 以及关心 AI 的朋友们,各位从事 AI 的同仁们,大家上午好,非常感谢杨静女士给我这个机会,和大家交流人工智能相关的话题。我的主题聚焦在 AI 具体领域—即知识图谱。
我们认为,知识是 AI 非常重要的基石,所以,今天我专门和大家交流一下我们在知识图谱方面的工作。
“科学技术是第一生产力”, 这句话相信所有朋友都知道。从 18 世纪第一次工业革命开始,科学技术就把巨大的自然力和自然科学注入到生产过程中,从而大大提升了生产力,生产力又影响生产关系的变化,进而为整个社会方方面面都带来改变。19 世纪的第二次工业革命使我们进入电气时代,20 世纪第三次工业革命使我们进入了信息时代。随着这些工业革命的发生,科技对我们越来越重要。而今天,我们非常幸运地处在第四次工业革命之中,这其中最核心的科技就是人工智能。我们看到,人工智能已经在影响我们生活的方方面面,渗透到各行各业。无论是我们想搜索信息还是浏览信息,还是根据地图导航出行,或者翻译……各行各业都在大量地应用人工智能。
我们可以清晰地看到,不管世界范围内还是在中国,人工智能的投资、产业规模等都在迅速增长,而且可以预计未来还会高速增长。人工智能在各个领域、各个方向上都非常活跃。
总结以上所说的,我们认为,人工智能是新的生产力,是未来很长一段时间里,人类生产力提升最重要的基础。
众所周知,百度是从做搜索引擎开始的。差不多 18 年前,我们开始做搜索引擎。从做的那天开始,一些人工智能技术就在其中得到应用,比如自然语言处理技术。七八年前,我们更全面地布局人工智能,从自然语言处理开始,到语音、图像、深度学习、机器学习、数据挖掘等等,今天,我们形成了相对完整的人工智能布局。
基础层,是人工智能很重要的组成部分,要有大数据,强大的计算能力,还要有非常强大的算法。
而真正可以模拟人的能力,我们把它们分成两层:感知层和认知层。我们知道,每个人通过眼睛、耳朵等来感知这个世界,所以,我们要做计算机视觉相关的图像、视频技术,也要做 AR、VR 技术,还要做和人的听觉相关的语音技术,如语音识别等等。应该说,感知能力不仅人有,很多动物也有,甚至有的动物听觉比人强,有的动物视觉比人强。而认知是人特有的,语言是人区别于其他动物的能力。同时,知识也是人不断进步的重要基础。我们除了要有认识客观世界的知识,人和人之间还要交互,以及对人的理解,这就是认知层的技术要解决的。
在此基础上,我们提供 AI 开放平台。在百度内部,我们用平台化的方式支持了公司大量的应用,同时也把我们的平台对外开放,打造 AI 生态,最终通过产品应用为每个用户、企业等提供服务。
假如我们要搜索一张图片,用图像处理技术很容易在网上找到一张相似的图,这个图像处理技术就能完成了。如果我们想问的问题是,白葡萄酒的营养价值,仅仅图像处理技术就不够了,这需要知识。百度在回答这样一个问题时就会用到背后的知识图谱。下面这个例子也是一样:语音技术可以把曲子识别出来是什么,相应地在曲库里找到歌曲,甚至专辑的封皮也能调出来,但是如果想知道这个曲子谁演奏过,仅仅语音技术就不够了,这就需要知识以及知识图谱的支撑。
因此,大家看到,感知层、认知层技术看似是相对独立的,而且每个技术也有非常多的问题要继续研究解决,但是,把它们组合在一起,尤其是赋予知识以后,我们就可以做更多的事情。所以我想说,知识是 AI 进步的阶梯。我们每个人都知道高尔基这句话——“书籍是人类进步的阶梯”,这里面包含两方面的意思,一方面人通过读书可以不断地学习更多的知识,不断地进步;同时,有了更多知识,更多能力的人也可以不断地产生新的知识,有更多的知识可以沉淀下来、传承下去,这个阶梯也会随之越大越高,人也可以越走越高。对人工智能来讲,知识也是一样的,有了知识的人工智能会变得更强大,可以做更多的事情,反过来,因为强大的人工智能,也可以帮我们更好地从客观世界中去挖掘、获取和沉淀知识,而这些知识和人工智能系统形成正循环,两者共同进步。
我们有很多方法可以把现实的知识富集起来,通过各种算法,让它变成一个网状的知识图谱,这里面的知识非常多,比个人脑子里存储的知识都要多,同时可以有强大的网络,成为人工智能应用的基石。
先举个例子,这是从数据到信息、到知识、到智能的“金字塔”。比如我们看到 95 这个数字,我们都知道这是数字,但它意味着什么呢?如果我不给你更多的信息,你只知道它是一个数字,如果我告诉你,这是今天的 PM2.5 指数,那 95 这个数字就变成了一条有用的信息。但是如果我没有背景知识,不知道 PM2.5 是 95 意味着什么,这个信息对我的价值也不大,95 是好还是不好呢,不知道。如果这时候有知识,我知道 95 意味着空气质量大概是良,这就已经是有知识了。进一步,我可以知道这个指数可以正常户外活动,但敏感人群应该减少外出,这就是从信息到知识到智能的过程。

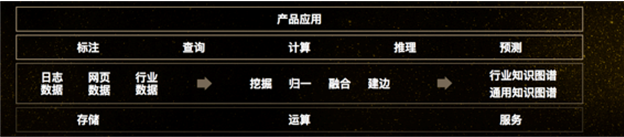
这是百度知识图谱。最下面一层,我们要有基础的存储、运算和服务能力。百度的知识图谱从非常多的海量数据里挖掘出来,包括互联网上的数据、行业数据,也包括日志数据等等,再进行挖掘、归一、融合。同时,图中一个个节点要建边,最终形成通用知识图谱、行业知识图谱。在这些基础之上的巨大图谱,会有基本的算子去查询、标注、计算、推理、预测等,每一个产品会调用这些算子访问图谱,从而完成特定的能力。
这样讲还比较抽象,给大家看一个图。这是百度庞大的知识图谱里一个很小的局部。我们随便从中间看一个节点,比如《中国有嘻哈》,会发现很多事实可以连接到这个节点上,比如它相关的演员、音乐的类型,办这个节目的爱奇艺等等。经过几次大家发现会关联到很远,右边是关联到中国诺贝尔奖得主屠呦呦,左边也关联到其他很多人。知识图谱包含大量的知识,在不同的应用中会起作用。当然,这里面每个节点,远远大于我此刻所展现出来的,,如果这个屏更大,能给大家展现更多。
回到抽象的部分,看看我们这个知识图谱到底有多大。这里面的每个节点可以理解为一个实体,不管是人、物还是实体,大概有几亿个,实体和实体之间会有很多边,一个实体可能会有几十个、几百个、几千个边,这是组合关系,非常多。每个边构成一个事实,比如《中国有嘻哈》谁参加了这个演出就是一个事实,谁举办了它又是一个事实。现在百度知识图谱里这个事实的量已经有千亿个。同时,我们支持基于图谱的动态计算,包括几十个应用场景,每天有几百个数据流同时在工作,都支持秒级更新,可以多层次地查询。
下面举一个通用知识图谱的例子。这里有一段百度百科里的文字,通过自然语言分析理解,可以把这段文字抽取成一个图谱。比如银河系会和太阳、地球等连接,会有很多边,这是抽取出来的一个通用图谱。而右边相当于从另一篇文章里抽取的又一个图谱。这两个图谱有些相似但又不同,他们有不同的数据来源,尤其一些常见的实体,网上有成千上万的网页和它有关,能抽取非常多的知识,这时候要做知识的融合,甚至有一些数据可能带来错误,不管是原始数据的错误还是分析过程中的错误,都要校验,最后保证知识图谱的质量。
再举一个行业知识图谱的例子,这是电信行业某一个运营商的手机流量套餐。和流量套餐相关的会有很多联接,比如日流量、月流量、流量包等等,可以建这样的图谱。同时,对于一个行业来讲,除了它静态的实体、属性、关系以外,还有业务逻辑。比如你打一个运营商的客服电话,想办流量包,他会问你是什么包,全国包还是本地包等等。你选择了其中一个以后,要查流量或者其他服务,又是一个完整的流程。这个流程实际上组成行业知识图谱的一部分。结合左边的图和右边的流程,我们就完成了一个运营商自动的客服。现在大家打到运营商某个客服电话,有一定比例其实是在和百度的智能客服机器人对话。
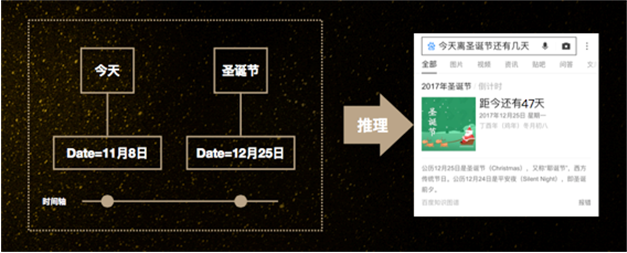
刚才讲的是一些基本的图谱应用,再讲一个带有一定推理色彩的。比如我们问今天离圣诞节还有几天。这样的问题对人来讲不是很难,对知识图谱而言,这就不是一个静态的知识,我们无法把这个问题的答案直接存在图谱里,而是需要先把今天是几号搞清楚,圣诞节是哪一天搞清楚,然后做个简单的计算得到一个正确的答案。
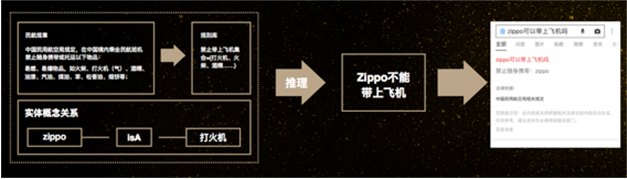
而右边的更复杂一点,用户的问题是,“Zippo 能不能带上飞机”。我们需要先在知识图谱里知道 Zippo 是打火机,而民航规定打火机是不允许带的,这时候再推理一步就得到最终的答案,坐飞机是禁止带 Zippo 的。
百度很早就在做知识图谱了,真正大规模上线是 2014 年,到今年三年时间,这个曲线一直在飞速地增长,长了大概 160 倍,说明百度搜索这样的应用越来越依赖知识图谱。
传统的搜索是搜索一个内容,主流搜索引擎一页给 10 个结果。有了知识图谱的支撑,我们可以给用户更直接的答案,并以一种更友好的方式呈现。比如第一个例子是搜索“胡歌”,大家看到图文并茂的结果,需要的常用信息放在这儿。第二个问“太阳的重量”,虽然网页也能找到,但不如直接把重量给出来。最右边的例子是用户搜索“孙俪”,除了给一些孙俪的信息出来,还会有相关的人、作品等等。我们把相关的影视作品推荐出来,用户可能感兴趣,比如《那年花开月正圆》,在界面一点就可以进入《那年花开月正圆》的页面。
汉语语言本身非常博大精深,有专门针对汉语语言的知识图谱,比如问“凹凸的凹,笔顺。”这个字我相信每个人都会写,但是不是每个人都能写对笔顺呢?知识图谱可以直接把笔顺告诉大家。我们现在大多用拼音输入法和语音输入,一些字不会念,也没法拼音输入。针对中文,我们会把汉字拆解,用语言描述它。比如,如果不知道“怼”字怎么念,我们就可以这样提问,“上面是对下面是心怎么念。”家里有学生的朋友可能会比较关心这个问题,比如要查美好的“好”字的多音字词组,或者成语等等,知识图谱可以直接列出来。
屏幕上是我们根据新智元曾经发表的一篇文章,分析这篇文章里面提到的关键词语和关键实体,组成的一个图谱。文章由此被打上标签。比如主题标签是“人工智能”,话题标签是“深度学习”等等,还有加上其他标签。我们对用户也有自己的模型,知道他关心什么领域,关心什么话题,有了两者的标签,我们就可以把合适的文章推荐给合适的用户。比如这个用户的画像是“IT 精英”、“互联网”等等,新智元这篇文章可能正好是这个用户所喜欢的。
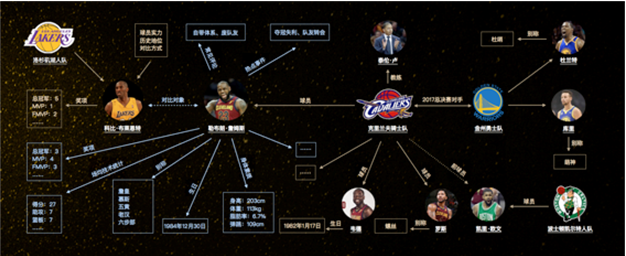
再举一个 NBA 的例子。NBA 很著名的球员,比如詹姆斯、库里等等,他们之间有各种关系,不只是和现在球队之间的关系,比如他的基本信息,身高、体重、成就等等。很多人把詹姆斯和科比做对比,这个对比在图里也能看到。用户有时会在一些产品里提问,比如问詹姆斯取得了什么成就,和科比对比等等。机器之所以能回答这些问题,是因为背后有这些知识。所以,一轮一轮,机器和人之间就交流下去了。
我上中学的时候在看 1983 版的《射雕》,现在有了最新的 2017 版《射雕》。我们现在知道这个视频是新《射雕》,它的主题曲是《铁血丹心》。当我们问类似的视频是什么,就能找到 1983 版的《射雕》。知识图谱会纵横交错把各种信息关联起来,不管现在还是历史的。1983 版的郭靖是黄日华演的,如果问黄日华其他作品,就能看到《天龙八部》;如果问这部书的作者是谁,就会找到金庸先生。一步步延伸下去,相当于在这样巨大的图里畅游,每个用户关心的方向不一样,往任何方向都可以不断地延展下去。
刚才讲了一些应用的例子,从搜索到对话,到推荐等等。虽然这次人工智能的爆发很大程度上和互联网关系很大,但人工智能影响的远远不止是互联网行业,它会影响到各行各业,深入到我们工作和生活中的方方面面。这次十九大报告也指出,将互联网、大数据、人工智能这些技术与实体经济深度融合,包括工业、农业、金融等领域。融合的过程中,人工智能要想为这些行业有更好的服务,需要对这些行业进行定制化,要有行业的知识,这时候在通用知识的图谱上也就进而要有行业的知识图谱,帮助这些行业提升生产力,帮助这些行业和产业去升级。
最后,我想总结一下。我们通过 AI 技术和大量的数据、以及与用户的互动不断地学习,汇集越来越多的知识,这些知识不仅包括通用的知识,也包括行业的知识,进而更好地理解世界,从而让我们用人工智能来提升我们的产品,提升每一个行业,让我们的生活变得更加美好。
谢谢大家!




