
本文翻译自“ Dimensional Modeling and Kimball Data Marts in the Age of Big Data and Hadoop ”,翻译已获得原作者 Uli Bethke 授权。Uli Bethke 是 Sonra 公司的 CEO,爱尔兰 Hadoop 用户组主席,也是 Oracle 的 ACE。
维度建模已死?
在回答这个问题之前,让我们回头来看看什么是所谓的维度数据建模。
为什么需要为数据建模?
有一个常见的误区,数据建模的目的是用 ER 图来设计物理数据库,实际上远不仅如此。数据建模代表了企业业务流程的复杂度,记录了重要的业务规则和概念,并有助于规范企业的关键术语。它清晰地阐述、协助企业揭示商业过程中模糊的想法和歧义。此外,可以使用数据模型与其他利益相关者进行有效沟通。没有蓝图,不可能建造一个房子或桥梁。所以,没有数据模型这样一个蓝图,为什么要建立一个数据应用,比如数据仓库呢?
为什么需要维度建模?
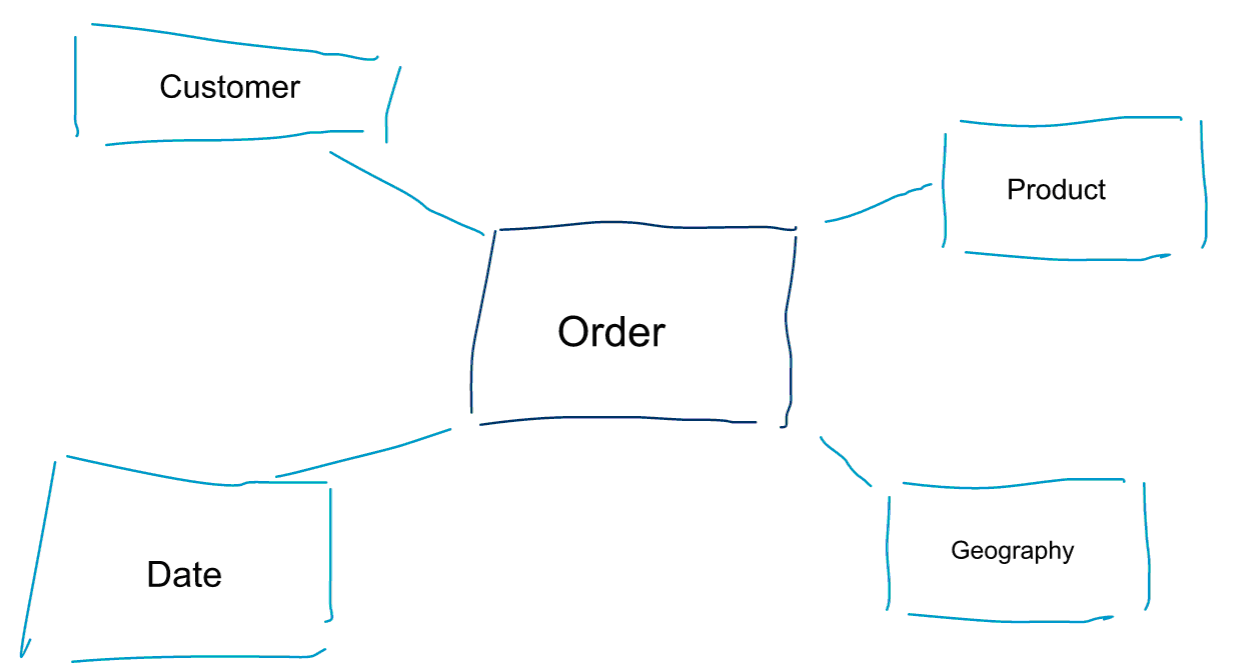
维度建模是数据建模的一种特殊方法。维度建模有两个同义词,数据集市和星型结构。星型结构是为了更好地进行数据分析,参考下面图示的维度模型,可以有一个很直观的理解。通过它可以立即知道如何通过客户、产品、时间对订单进行分割,如何通过度量的聚集和比较对订单业务过程进行绩效评估。
维度建模最关键的一点,是要定义事务性业务过程中的最低粒度是什么。如果切割或钻入数据,到叶级就不能再往下钻取。从另一个角度看,星型结构中的最低粒度,即事实和维度之间没有进行任何聚集的关联。
数据建模和维度建模
标准数据建模的任务,是消除重复和冗余的数据。当数据发生变化时,我们只需在一个地方修改它,这有助于保证数据的质量,避免了不同地方的数据不同步。参考下面图示的模型,它包含了代表地理概念的几张表。在规范化模型中,每个实体有一个独立的表,数据建模只有一张表:geography。在这张表中,city 会重复出现很多次。而对于每个 city,如果 country 改变了名字,就不得不在很多地方进行更新。
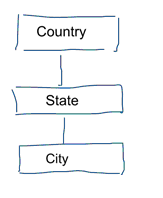
注:标准数据模型总是遵守 3NF 模式。
标准的数据建模,本身并不是为了商业智能的工作负载而设计的。太多的表会导致过多的关联,而表关联会导致性能下降,在数据分析中我们要尽力去避免这种情形发生。数据建模过程中,通过反规范化把多个相关表合并成一个表,例如前面例子里的多个表被预合并成一个 geography 表。
那么为何部分人认为维度建模已死?
一般人都认可数据建模的方式,而把维度建模当成特殊处理方式,它们都是有价值的。那为什么在大数据和 Hadoop 的时代,部分人会认为维度建模没用了?
“数据仓库之死”
首先,一些人混淆了维度建模和数据仓库。他们认为数据仓库已死,于是得出结论:维度建模也可以被丢进历史的垃圾箱。这种论点在逻辑上是连贯的,但是,数据仓库的概念远没有过时。我们总是需要集成的、可靠的数据来产生商业智能仪表盘(BI Dashboards)。
允许读时模式(Schema on Read)的误解
第二个常听见的争论,比如“我们遵循允许读时模式(Schema on Read),所以不需要对数据再进行建模了”。依我看来,这是数据分析过程中最大的误解之一。我同意起初仅转储原始数据,这时不过多考虑模式是有意义的。但是,这不应该成为不对数据进行建模的借口。允许读时模式只是降低了下游系统的能力和责任,仍有一些人不得不咬牙定义数据类型。访问无模式数据转储的每一个进程都需要自己弄清楚发生了什么,而这完全是多余的。通过定义数据类型和正确的模式,很容易就可以避免这些工作。
再谈反规范化和物理模型
是否那些宣传维度建模的观点实际上已过时了? 的确有些观点比上面列出的两条更好,要理解它们需要对物理建模和 Hadoop 的工作方式有一些了解。
前面简单提到采用维度建模的原因之一,和数据的物理存储方式有关。标准数据建模中每个真实世界里的实体,有一个自己的表。我们这样做,是为了避免数据冗余和质量问题在数据中蔓延。越多的表,就需要越多的关联,这是标准建模的缺点。表关联的代价是昂贵的,特别是关联数据集中关联大量记录的时候尤其突出。当我们考虑维度建模时,会把多个表合并起来,这就是所谓的预关联或者说数据反规范化。最后的结果是,得到更少的表、更少的关联、更低的延迟和更好的查询性能。
可参与领英上相关的讨论。
彻底反规范化
为什么不把反规范化做到彻底?去掉所有的表关联只保留一张表?的确,这样做可以不需要对任何表进行关联,但是可以想象到,它会带来一些负面影响。首先,它需要更多的存储,因为要存储大量的冗余数据。随着数据分析的列式存储格式的出现,这一点现在不那么令人担忧了。反规范化最大的问题是,每次属性值发生变化,就不得不在很多地方进行更新,可能是几千甚至几百万次更新。一个解决办法是在晚上对模型进行全量重载,通常这比增量更新要更快、更容易。列式数据库通常采用这种方法,首先将要做的更新存储在内存中,然后异步地写入磁盘。
分布式关系型数据库(MPP) 上的数据分布
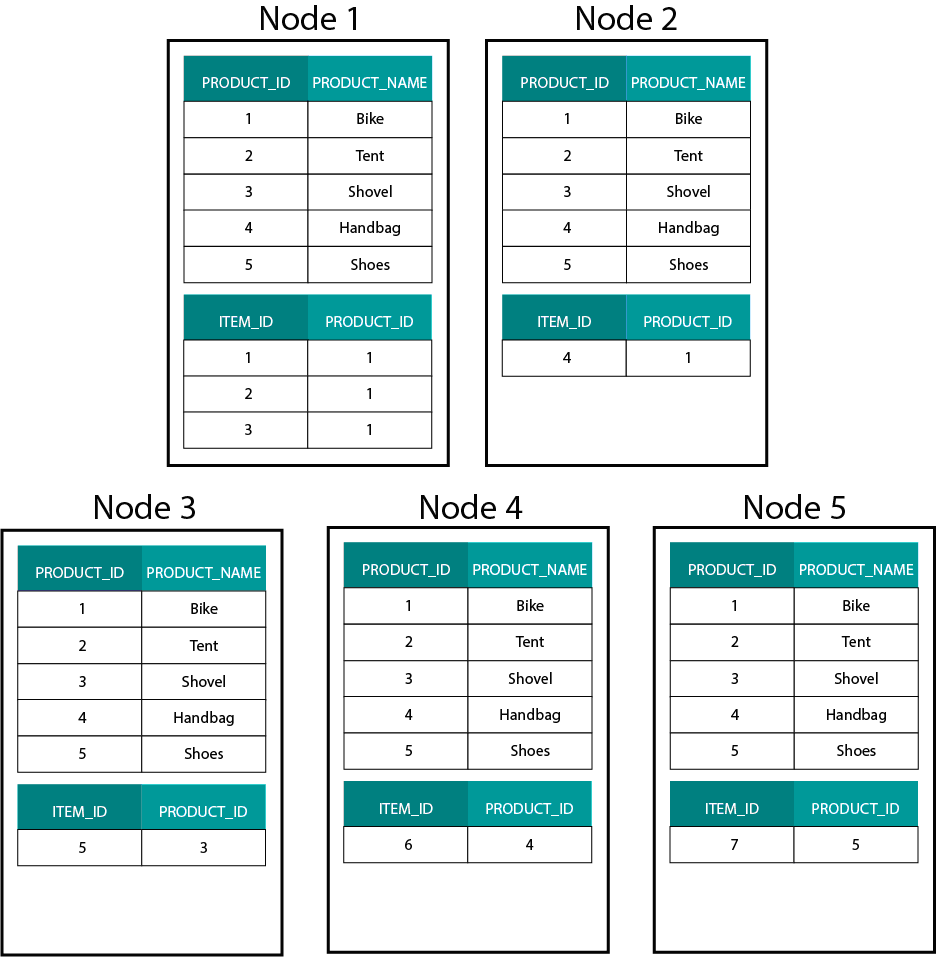
在 Hadoop,例如 Hive、SparkSQL 上建立维度模型,要很好地理解一个技术上的核心特征,就是它和分布式关系型数据库(MPP)上的建立方式是不一样的。在 MPP 中的节点上分布数据,可以控制每条数据记录的位置。基于分区策略,例如 Hash、List、Range 等,可以在同一个节点上跨表同定位(co-located)各个记录的键值。由于数据的局部性得到保证,关联速度会非常快,因为不需要在网络上发送任何数据。参考下面图示的例子,在 ORDER 和 ORDER_ITEM 表中有相同 ORDER_ID 的记录存储在同一节点上:
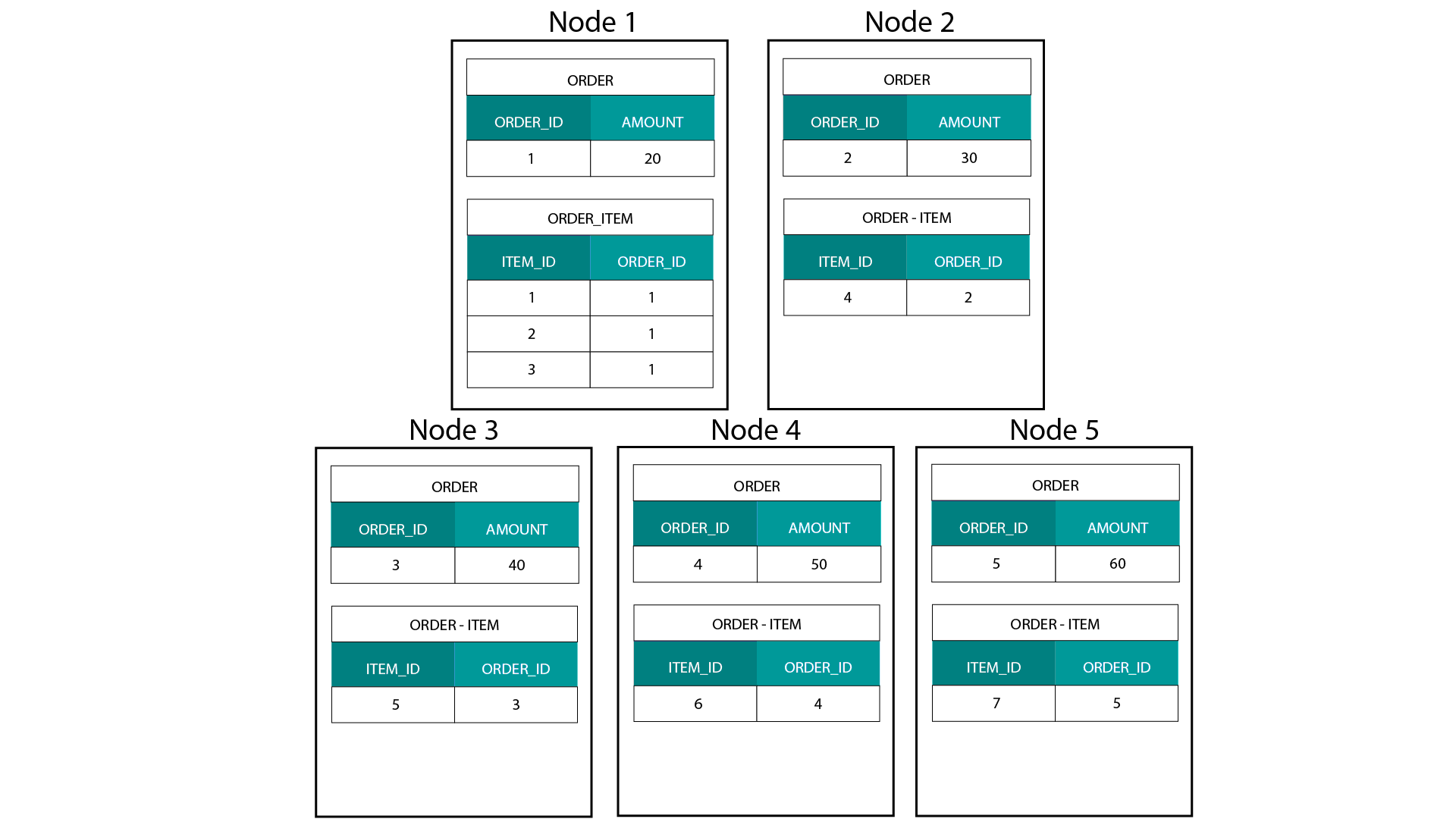
ORDER 和 ORDER_ITEM 表中 ORDER_ID 对应的键值,在相同的节点做到同定位。
Hadoop 上的数据分布
数据分布在基于 Hadoop 的系统中是非常不同的,我们将数据分割成大型的块(chunks),并在 Hadoop 分布式文件系统(HDFS)的各个节点进行分发和复制。这种数据分发策略不能保证数据的一致性。参考下面图示的例子,记录 ORDER_ID 的键被存储在不同的节点:
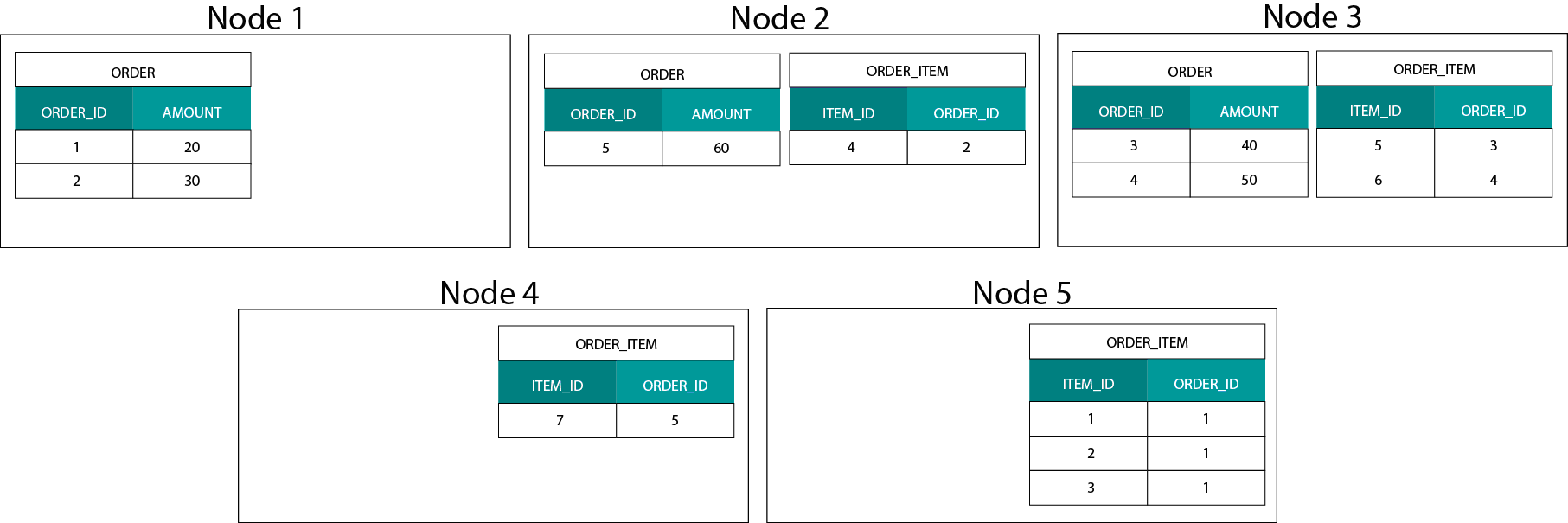
为了关联它们,需要在网络上发送数据,这样做会影响性能。
处理这个问题的一个策略,是在集群的所有节点上复制要关联的表,该策略被称为广播式关联(broadcast join)。如果对 MPP 使用相同的策略,可以想象,只能用在较小的 lookup 或维度表中。
那么当关联一个大的事实表和一个大的维度表,比如客户或产品,甚至关联两个大型事实表时,我们该怎么办?
Hadoop 上的维度建模
为了解决性能问题,可以利用反规范化将大的维度表放进事实表,以保证数据是同定位的(co-located),而对较小的维度表可以在所有节点上广播(broadcast)。
关联两个大型事实表时,可以把低粒度的表嵌套到更高粒度的表中,例如把 ORDER_ITEM 表嵌套到 ORDER 表中。高级的查询引擎,比如 Impala 或 Drill 可以让数据扁平化(flatten out):

嵌套数据的策略很有用,类似于 Kimball 概念中用桥接表来表示维度模型中的 M:N 关系。
Hadoop 和缓慢变化维
Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据。如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪。但是从内部机制看,数据库是以类似的机制工作,在一个进程异步地更新数据文件中的数据之前,将所有变更保存在一个不可变的预写式日志(WAL- write-ahead log,Oracle 中称为 redo log)中。
不可变性(immutability)对维度模型有什么影响?你也许还记得维度建模课程中渐变维的概念(Slowly Changing Dimensions - SCDS)。SCDS 有选择地保存属性值变更的历史,于是可以在某个时间点上对属性值进行度量。但这不是默认的处理方式,默认情况下会用最新的值来更新维度表。那么在 Hadoop 上如何选择呢?记住! 我们不能更新数据。我们可以简单地为 SCD 选择默认方式并对每一个变化进行审核(audit)。如果想运行基于当前值的报表,可以在 SCD 之上创建一个视图,让它仅仅检索到最新值,利用 Windows 函数可以很容易做到这一点。或者,可以运行一个所谓合并(Compaction)的服务,用最新的值物理地创建维度表的一个单独版本。
Hadoop 的存储演化
Hadoop 平台的供应商并没有忽视这些 Hadoop 的限制,例如 Hive 就提供了满足 ACID 的事务和可更新的表。根据大量的主要公开问题以及个人经验,这个特性还没有完善到可以部署生产环境。Cloudera 采取了另外一个手段,利用 Kudu 建立了一个新的可变更存储格式,它并没有基于 HDFS,而是基于本地 OS 操作系统。它完全摆脱了 Hadoop 的限制,类似于列式 MPP 的传统存储层。通常来说,在 Impala + Kudu 这样一个 MPP 上运行 BI 和 Dashboard 的任何使用场景,会比 Hadoop 更好。不得不说,当它涉及到弹性、并发性和扩展性时,有自己的局限。当遇到这些限制时,Hadoop 和它的近亲 Spark 是解决 BI 工作负载的好选择。
判决:维度模型和星型模式过时了吗?
我们都知道,Ralph Kimball 已经退休了,但他设计原则的思想和观念仍然是有效的,也将会继续存在。即使我们不得不让它们适应新的技术和存储类型,它们仍然能够带来巨大的价值。
补充阅读
Tom Breur: The Past and Future of Dimensional Modeling
Edosa Odaro: 5 Radical Tips for Speedy Big Data Integration - The Anti Data Warehouse Pattern
感谢蔡芳芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论