2017 年 8 月 27 日 -9 月 1 日, 数据库领域的国际顶级学术会议 VLDB(Very Large DataBase) 在德国慕尼黑召开。 腾讯 TEG 数据平台部和北京大学联合撰写的大规模主题模型系统的论文《
LDA*:A Robust and Large-scale Topic Modeling System》, 入选了今年 VLDB 的 Research Track,并获邀在大会上进行 Oral Presentation。

VLDB 会议由 VLDB 基金会赞助,和另外两大会议 SIGMOD、ICDE 构成了数据库领域的三个顶级会议,而它是这 3 个会议中,含金量最高的一个。VLDB 的论文接受率总体很低,只有创新性很高、贡献很大的论文才有机会被录用。近年来随着大数据的发展,VLDB 的领域也从数据库扩展到大数据相关领域,与时俱进的同时,依然保持着对文章质量的严格把控。
本次论文的主要内容,是研究如何在工业界的环境中建立一个大规模的主题模型训练系统。在这之前,已经有很多的相关的系统工作,包括 YahooLDA,微软的 LightLDA 以及 Petuum 等,而LDA* 则解决了 鲁棒的采样性能 以及 词分布倾斜 这两个难题,取得了更好的性能。LDA* 构建于腾讯开源的系统 Angel 之上,得益于 Angel 开放的参数服务器架构,良好的扩展性以及优秀的编程接口设计,它可以轻松处理 TB 级别的数据和十亿维度的主题模型。
主题模型:用数学框架捕捉文档潜在语义概率分布
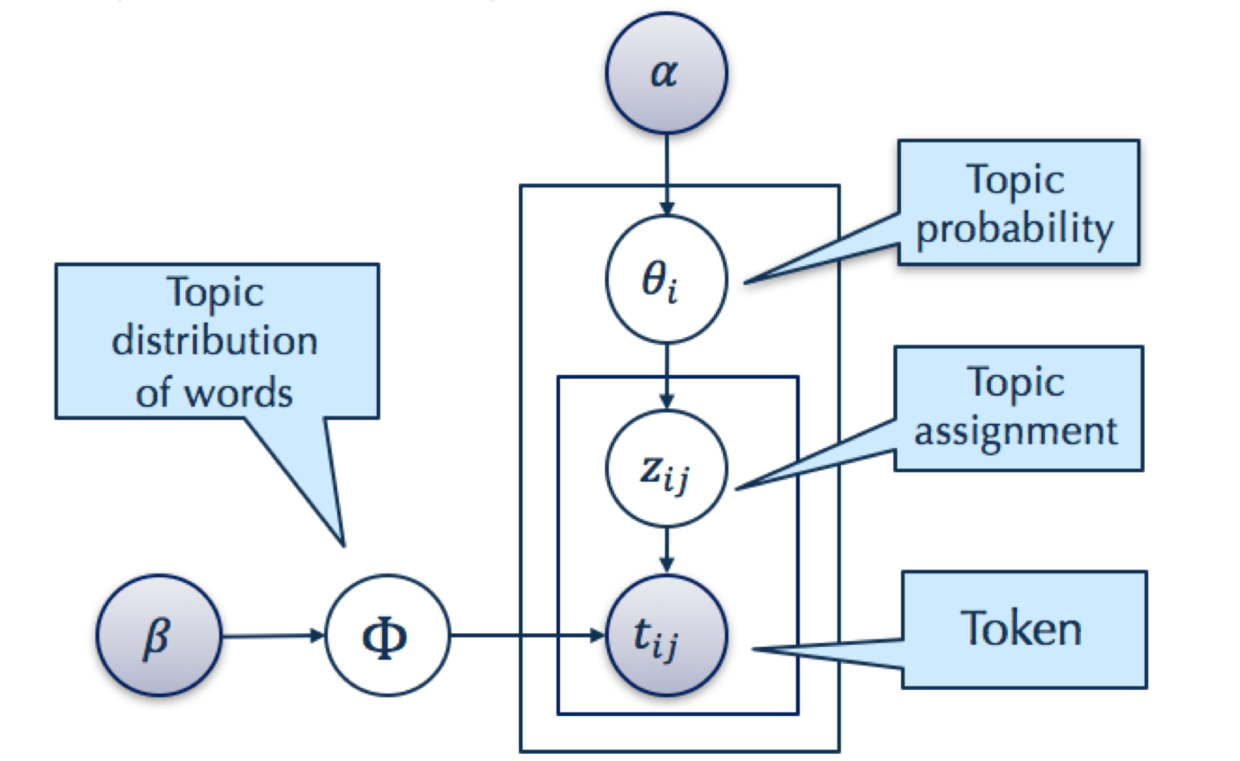
主题模型(Topic Model)在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。一篇文章通常包含多种主题(比如“猫”、“狗”),而且每个主题所占比例各不相同。主题模型试图用数学框架来体现文档的这种特点,本质上,它是一个对文本建模的概率图模型。
在主题模型中,每个文档被看成一个话题(Topic) 的分布,而将每个话题被看成一个在词语上的分布 **(Topic Distribution of Words)。通过主题模型对文本进行建模,将文档表示成话题的分布概率(Topic Probability)**,从而可以对文档进行聚类等分析。主题模型最初是运用于自然语言处理相关方向,现在已经用于多个领域,比如推荐系统、广告 CTR 预估,用户兴趣分类……
在工业界的场景下训练主题模型,经常会遇到 3 个问题:
- 训练的数据规模非常大,2T 大小的样本,3000 亿个 Token,要求在几个小时内跑出结果
- 面对的数据和参数复杂,在各种各样的数据和参数配置下,都必须要有较好的性能
- 所有的任务都是在一个集中的集群上运行,系统需要具有较高的可扩展性和鲁棒性
为此,LDA*从模型和工程上,对传统的 LDA 进行了 2 个针对性优化,使得它有广泛的适用性和良好的性能,成为一个大规模的高性能主题模型系统。
优化 1:吉布斯采样(Hybrid Sampler)
吉布斯采样是一种基于马尔科夫蒙特卡罗的采样方法,用于从一个复杂的概率分布中进行采样,常常用于求解大规模主题模型。但最原始的吉布斯采样算法,Collapsed Gibbs Sampling(CGS)拥有 O(K) 的算法复杂度(K->Topic Number),使得在大规模数据以及话题个数较多的情况下,求解效率非常低下。因此有很多研究工作考虑如何降低采样算法的复杂度。
目前业界已有的 LDA 方法包括AliasLDA,F+LDA,LightLDA 和 WarpLDA。其中 AliasLDA 和 F+LDA 利用主题模型参数的稀疏性质使得模型的采样复杂度降低到了 O(Kd),而的上限是文档的长度和话题个数 K 中的较小值;LightLDA 和 WarpLDA 则利用 Metropolis-Hastings 方法,逐一地从两个较为简单的 proposal 分布中进行采样 (qdoc 和 qword),再根据 Metropolis-Hastings 方法计算采样结果的接受率,因为利用了 Alias Table 来进行采样,LightLDA 和 WarpLDA 每次采样只需要 O(1) 的计算复杂度。
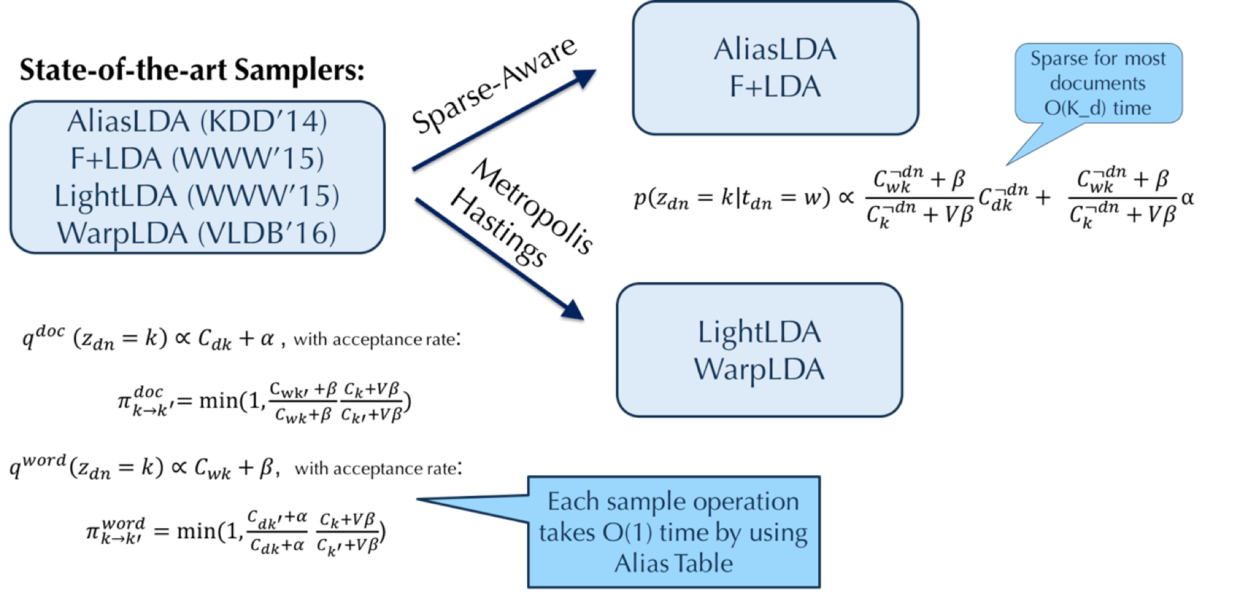
但是,O(1) 的采样复杂度并不意味着更快的收敛速度。由于 Metropolis-Hastings 方法中存在接受率,因此从概率的角度上来看,LightLDA 和 WarpLDA 平均需要 O(Kd) 次采样操作才能产生一个可接受的采样样本,从而发生一次状态转移;而 AliasLDA 和 F+LDA 虽然每次采样操作需要 O(1/ π) 的复杂度,但是每次采样都能够产生一个样本。因此,Sparse-Aware Samplers 和 Metropolis-Hastings Samplers 之间存在一个 tradeoff,单一的一种 sampler 并不能够适用于所有的数据集或者参数设置,只有发现这个 tradeoff 并且有效地将这两种 samplers 结合起来,才能达到最佳的性能。
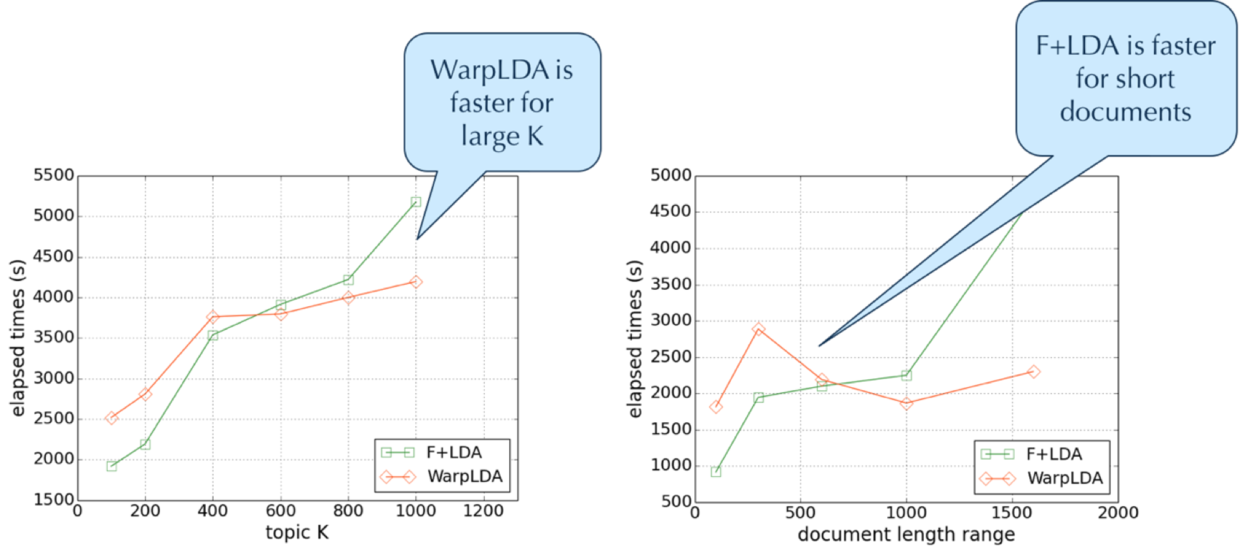
为了发现这个 tradeoff,Angel 团队做了详尽的实验,并找到两种 samplers 的交叉点。基于这个交叉点,LDA*有效地将 F+LDA 和 WarpLDA 结合起来,设计了一个新的 Hybrid Sampler。它采用了两个启发式的规则来构建这个 Hybrid Sampler。在第一个规则中,将数据集分成两个部分,文档较长的数据集和文档较短的数据集,然后使用 F+LDA 来采样较短的文档集合,使用 WarpLDA 采样较长的文档集合。在第二个规则中,将两个具有不同收敛速度的 sampler 结合起来,在一次迭代中,每个 token 话题的采样都能产生一个样本,因此对于 WarpLDA 来说,需要动态地设定其 MH 步长,而对于 F+LDA 来说,则不需要进行任何改变。
根据实验,Hybrid Sampler 在 PubMED 数据集上获得与 F+LDA 相当的甚至更好的性能,而在 Tencent 数据集上也可以获得比 WarpLDA 更好的性能。总的来说 Hybrid Sampler 在所有实验数据集上和参数配置下,都能获得最好的性能。
优化 2:非对称架构,实现模型并行
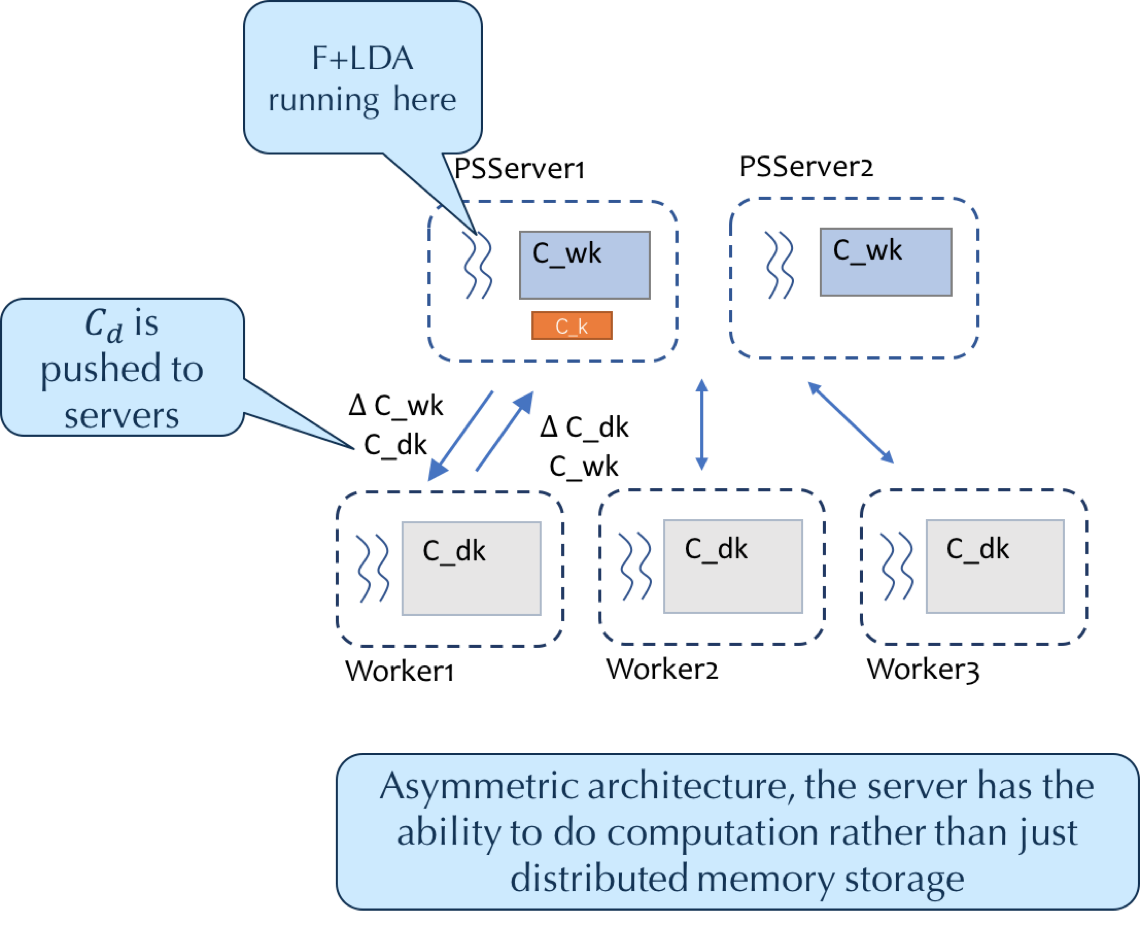
主题模型的训练常常需要大规模的数据集和较大的话题个数,因此分布式训练常常用于进行大规模的主题模型训练。已有的系统,包括LightLDA,YahooLDA 和 Petuum,其实都是采用参数服务器的架构来进行分布式训练,但是由于词分布的倾斜特性,标准的参数服务器架构会在 Worker 端产生较大的网络通信开销,因此每个 worker 几乎都需要把整个词 - 话题(Word-Topic)矩阵模型从 PSServer 上拉取下来,这个对性能会有很大的影响。
在实际的测试下,由于词分布的倾斜性,导致大部分的网络开销都产生于长尾的词语,这些长尾的词语产生的网络开销造成了在数据量和模型参数较大时带来的性能损失。因此,LDA* 对于这类长尾词语进行了特殊的处理,将一部分长尾词语的采样推送到 PSServer 端进行,从而避免了对词 - 话题矩阵的拉取操作。由于在这样的架构中,PSServer 不仅仅作为一个分布式存储,还参与了一定的计算任务,从而某种程度上实现了模型并行,这种架构为非对称架构。依托于 Angel 良好的接口设计和 psFunc 功能,LDA*的这种非对称架构可以非常轻松的实现,而不用对 Core 进行任何的修改。
性能数据:在腾讯真实的推荐数据集上最高是原有系统的 9 倍
为了进行全面的评测,LDA* 和之前开源的 Petuum,以及微软的 LightLDA,在 2 个数据集上进行对比。一个是开源的 PubMED,一个是腾讯真实的推荐数据集。实验结果表明,在数据量越大的情况下,LDA*的优势越明显。
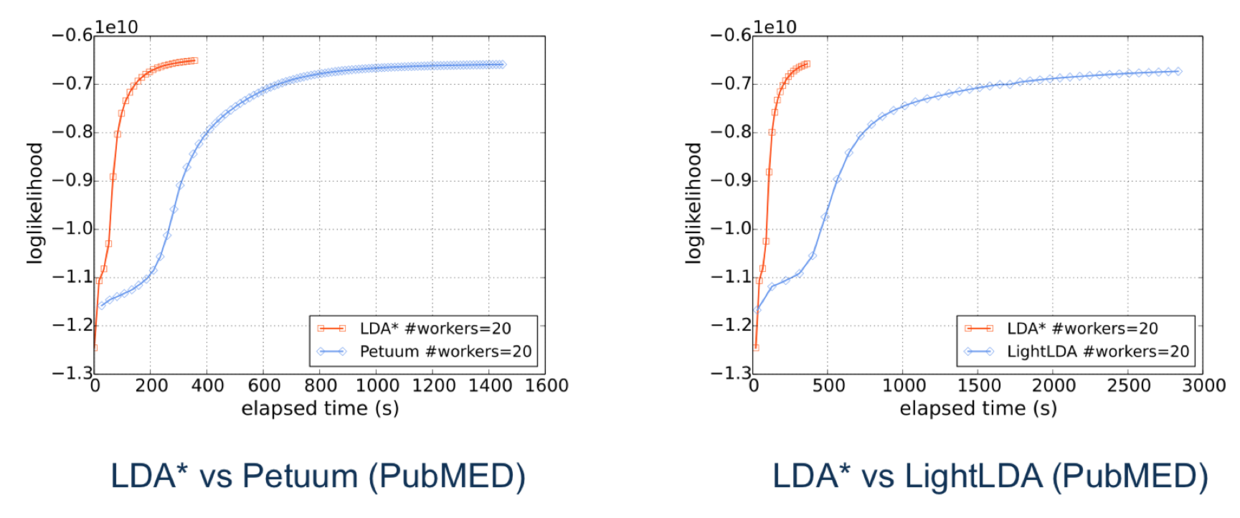
PubMED 数据集上,LDA*的速度,分别是 Petuum 和 LightLDA 的 5 倍。
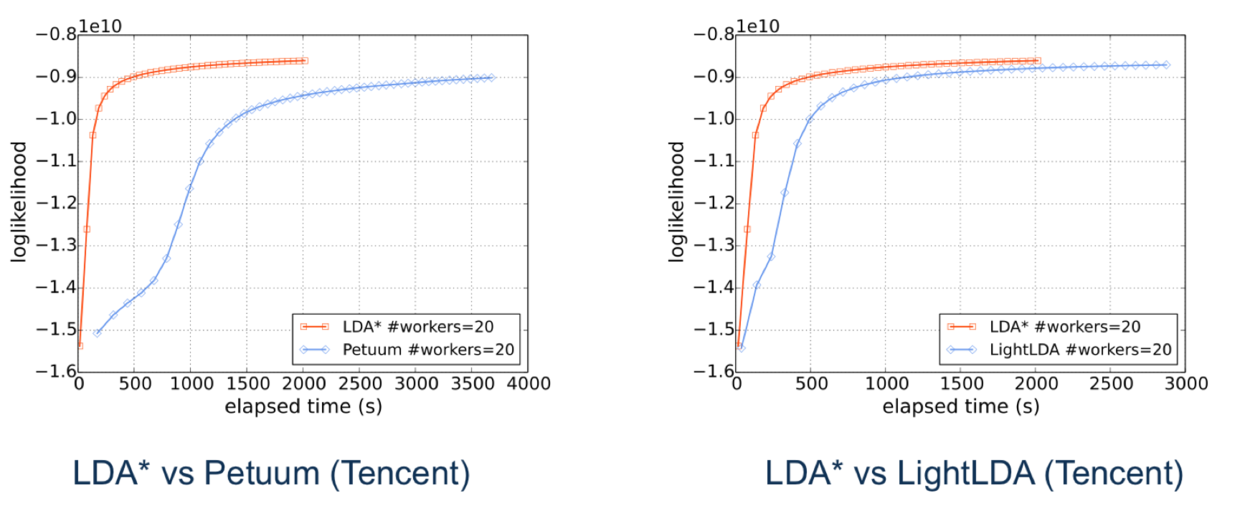
在腾讯真实的推荐数据集上,LDA*是 Petuum 的 9 倍,是 lightLDA 的 2.6 倍。
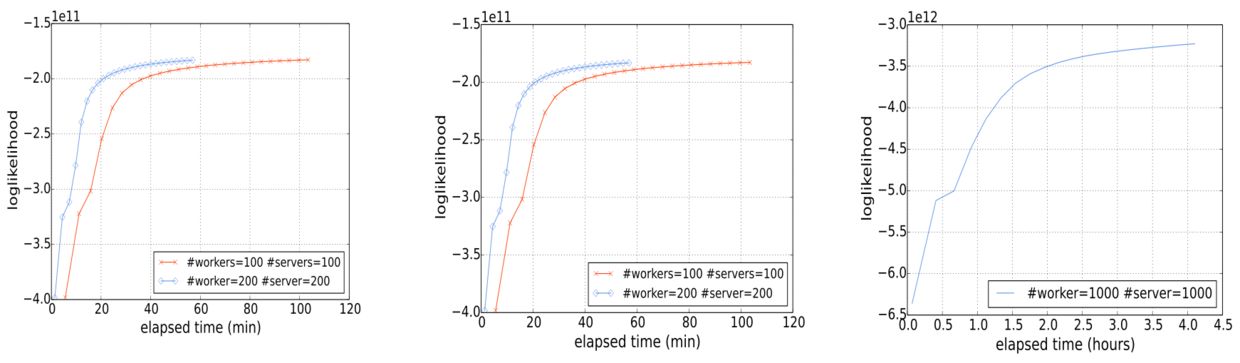
为了更好的体现LDA* 的性能,在腾讯内部生产集群上,LDA*使用更大的数据集进行训练。从下图的数据集可以看到,最大的一个数据集有 3000 亿个 token,大约 1.8TB 的数据量。在所有的任务中,话题数设置为 8000,具体数据集大小如下:
Dataset docs words tokens Average doc length Sparse text size Production1 159M 3759618 19B 122 90GB Production2 507M 5588297 60B 119 270GB Production2 2.2B 3911813 308B 138 1.8TB 测试性能如下,可以看出LDA*能够在资源充足的情况下,能得到非常好的扩展性,并且能够扩展至数千个 Worker,即便对 TB 级别的数据进行训练,时间可以控制在小时级别,很好的满足了生产系统的需要。
总结
LDA* 无论是在模型准确度还是性能上,都有不俗的表现和可扩展性,目前已经应用于腾讯的多个业务场景中,包括广点通推荐、用户画像、腾讯视频等。
未来,伴随着 Angel 的发展和推广,希望业界会有更多的公司,能够从LDA*中受益,轻松拥有大规模主题建模的能力。




