由于在语言识别、机器翻译和语言建模等领域表现出了优异的性能,为序列预测而设计的神经网络最近再次引起了人们的兴趣,但是这些模型都是计算密集型的,成本非常高。比如在语言建模领域,最新的成果依然需要在大规模 GPU 集群上训练几周的时间,虽然效果不错,但是这些计算密集型的实践对大规模计算基础设施的依赖性非常强,这限制了其在学术和生产环境中的研究速度与应用。
针对这一计算瓶颈,Facebook AI 研究院(FAIR)设计了一个新的、几乎是为 GPU 量身定制的 softmax 函数,能够非常有效地通过大规模词库训练神经网络语言模型。该函数名为自适应 softmax,它能根据不均衡的单词分布构建集群,使计算复杂度最小化,避免了对词库大小的线性依赖。同时能够在训练和测试阶段充分利用现代架构的特点和多维向量运算进一步降低计算消耗。与分层 softmax、NCE 以及重要性抽样等之前的、大部分为标准 CPU 设计的方法相比,该方法更适合 GPU。
此外,FAIR 还开发并开源了一个名为 torch-rnnlib 的类库,该类库允许研究者设计新的递归模型,并以最小的努力在 GPU 上测试这些原型。最近 Edouard Grave 、Justin Chiu 和 Armand Joulin 在 Facebook 的网站上发表了一篇文章,介绍了用户如何通过该类库设计新的递归网络。
使用torch-rnnlib 构建递归模型
1. 什么是语言建模?
语言建模就是通过给定词典中的单词序列学习其概率分布,根据单词过去的概率计算其条件分布。T 个单词序列(w 1 ,…, w[T])的概率可以表示为:
P(w 1 ,…, w[T])) = P(w[T]|w[T-1],…, w 1 )…P(w 1 )
该问题通常通过非参数化的计数统计模型来解决,但是目前基于递归神经网络的参数化模型已经被广泛应用于语言建模。
2. 如何使用 Torch-rnnlib 构建标准模型
Torch-rnnlib 为递归神经网络的构建提供了三种不同的接口:
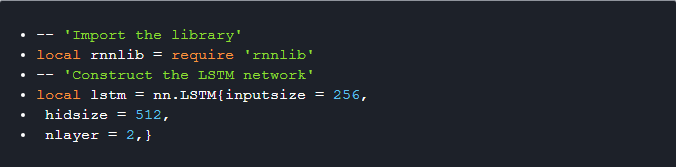
1). nn.{RNN, LSTM, GRU} 接口,用于构建所有层具有相同数量隐藏单元的递归网络。
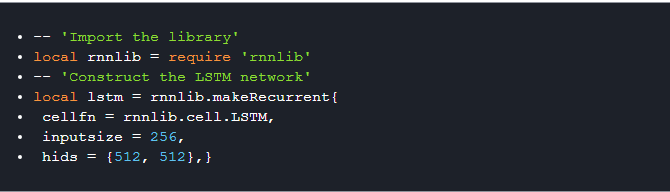
2). _rnnlib.recurrentnetwork_ 接口,用于构建任意形状的递归网络。
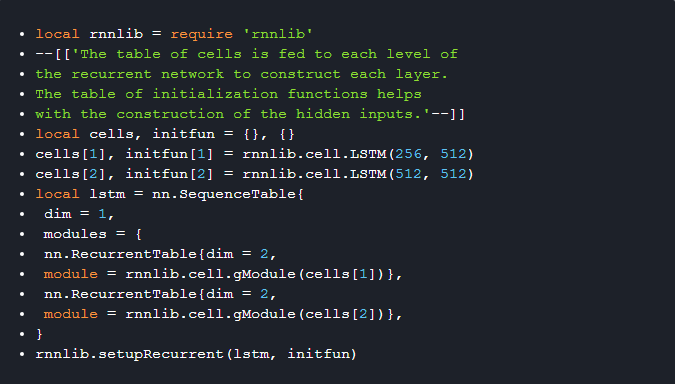
3). nn.SequenceTable 接口,用于将各种计算有效地链接到一起。nn.RecurrentTable 构造器仅是一个轻量级的包装器,它会随着时间的迁移克隆递归模块。要注意的是,这是最底层的接口,必须调用 _rnnlib.setupRecurrent(model, initializationfunctions)_ 设置递归隐藏状态行为。
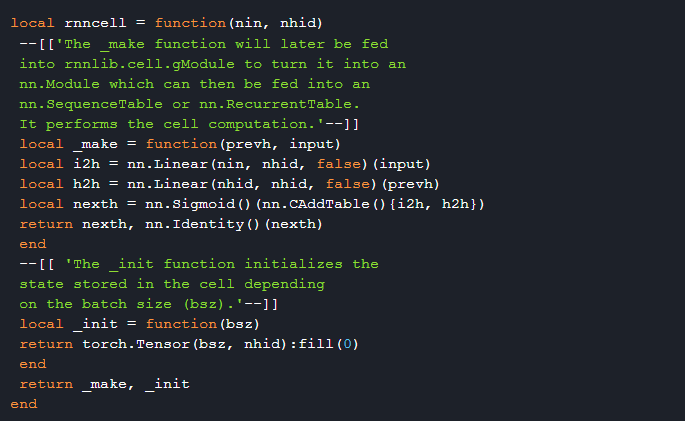
3. 构建自己的递归模型
可以通过定义 cell 函数或者 cell 状态初始化函数来创建自己的模型。下面的代码展示了如何从零开始构建一个 RNN:
4. 在 GPU 上训练 torch-rnnlib
因为 torch-rnnlib 遵循 nn 模块接口,所以调用模型的 _:cuda()_ 方法就能将其拉到 GPU 上执行。rnnlib 的目的就是让用户能够灵活地创建新的 cell 函数或者使用快基线。
此外,无论使用前面提到的第一个还是第二个接口构建递归网络,都能非常容易地使用 cudnn 来加速网络。对于第一个接口,通过 _usecudnn = true_ 来调用构造函数:

对于第二个接口,将 _rnnlib.makeRecurrent_ 替换成 _rnnlib.makeCudnnRecurrent_,然后将 cell 函数修改为 _cudnn_ 接口中的 _cellstring_。例如:

这样模型的递归部分通常会有至少两倍的速度提升。但是这并不是说整个模型会提速至少两倍,特别是当主要计算工作并不在递归部分的时候,此时提升会更小一些。
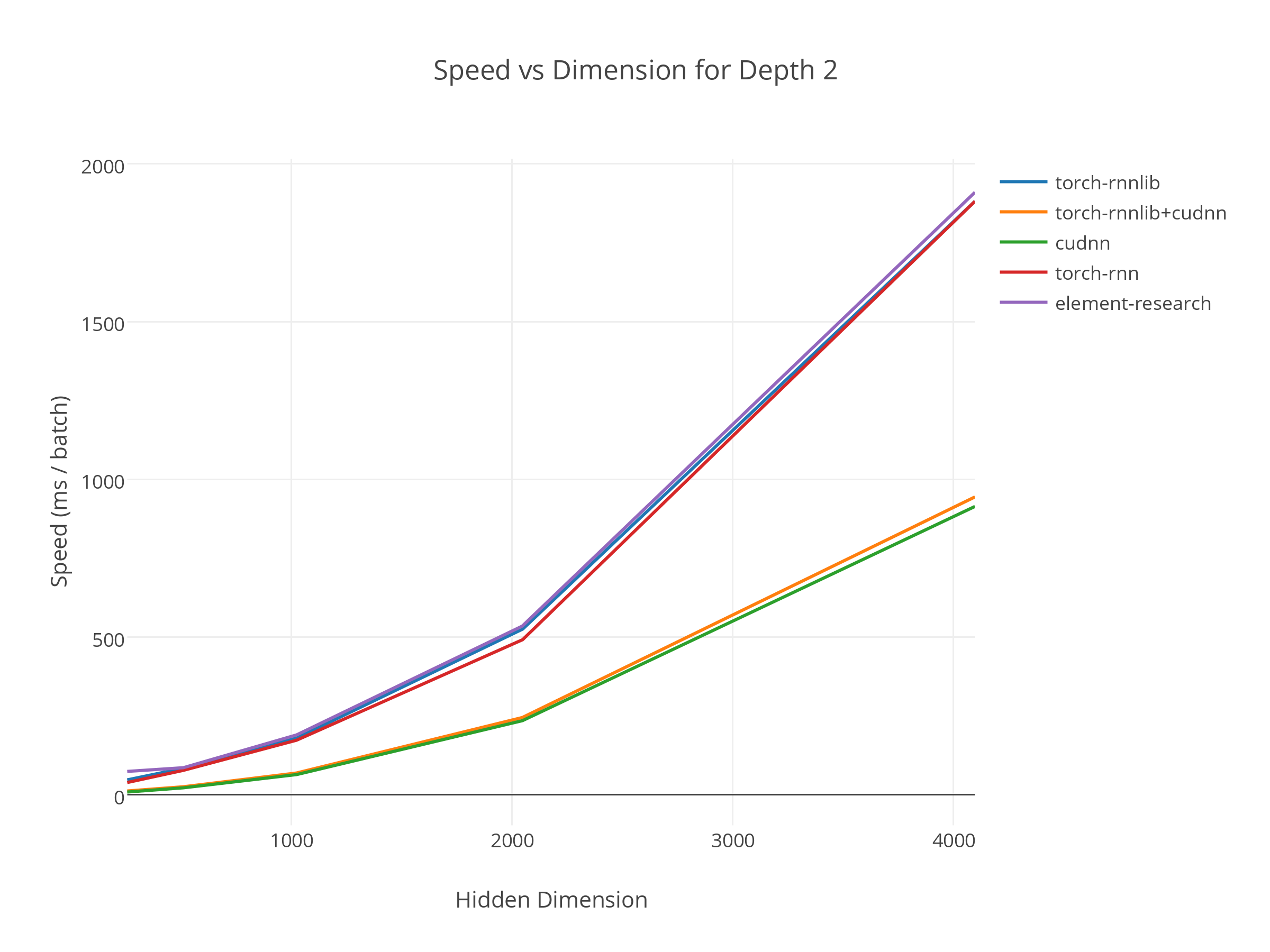
图:torch-rnnlib 及其他 torch 类库随着隐藏层数量的增加其运行时间的折线图
5. 自适应 Softmax
在处理语言模型等大规模输出空间的时候,分类器可能是模型的计算瓶颈。过去提出的很多解决方案通常都是针对标准 CPU 而设计的,很少充分利用 GPU 所特有的能力。
Facebook 开发的、新的自适应 softmax 能够根据数据的分布情况调配计算资源。它能通过加快常用类的访问速度,提供更多计算资源,来实现更好近似值和更快运行时间之间的平衡。更确切地说,它实现了一种 k-way 分层 softmax,能够根据 GPU 的架构,通过动态规划算法实现计算资源的有效分配。为了进一步降低分类器的计算负担,自适应 softmax 还使用了一些技巧:使用浅树(shallow trees)避免顺序计算;为每个集群设置类数量的最小值,避免浪费 GPU 的并行计算能力。
正如图表 1 所展示的那样,自适应 softmax 的性能与完整 softmax 的性能几乎不相上下,但是训练时间非常短。
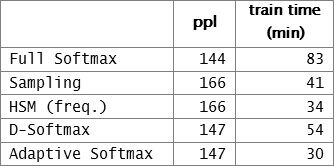
图表 1:基于 Text8 的性能。 ppl 越低越好。
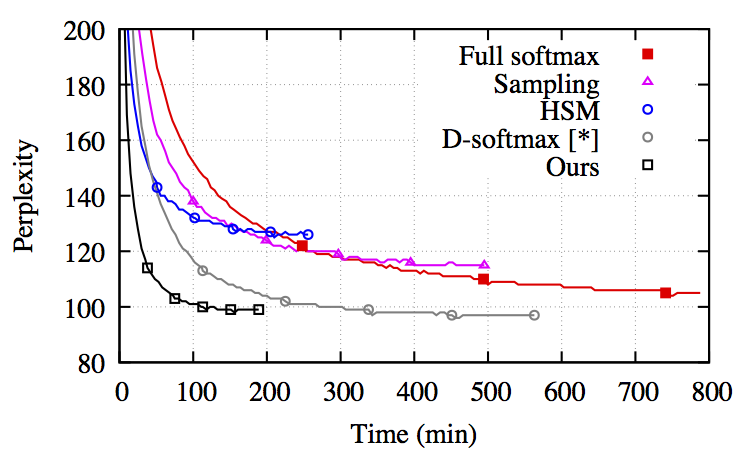
图:不同 softmax 近似函数语言模型的收敛性。该数据基于 LSTM。
测试结果
Facebook 两个模型的参数配置如下:小模型使用了有 2048 个单元的单层 LSTM,大模型使用了每层有 2048 个神经元的双层 LSTM。训练模型使用 Adagrad,权重调整使用 L2。批处理大小为 128,反向传播窗口大小为 20。

图表 2:基于 10 亿单词进行训练后的模型复杂度(越低越好)的比较。
如图表 2 所示,小模型经过几天的训练复杂度达到了 43.9,大模型经过 6 天的时间复杂度达到了 39.8。目前最佳复杂度是由 Jozefowicz et al. 在 2016 年实现的 30.0,但是 Jozefowicz et al. 达到这一数值使用了 32 颗 GPU,花了 3 周多的时间;而 Facebook 仅用 1 颗 GPU 花了几天时间。
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




