假如有这样一个场景:系统每秒钟都会收到大量的事件,每个事件又包含很多参数,用户不仅需要准实时地还需要定期地判断每一种事件、事件的每一种参数值的组合是否超过了系统设定的阈值。面对这一场景,用户应该采用什么样的方案呢?最近,来自于 Premium Minds 的软件架构师 André Camilo 在博客上发表了一篇文章,介绍了他们是如何使用 Akka 解决这一棘手问题的。
在该文章中 André Camilo 首先介绍了他们的应用场景:
我们的系统每秒钟最多会收到几百个事件,有些事件有 8 个参数,有些事件有超过 240,000 个参数值的组合(* 假如有一个 PhoneCall(phoneNumber, countryCode, geoZone) 事件,该事件有三个参数,其中 phoneNumber 有 4,000 个值, countryCode 有 5 个值,geoZone 有 10 个值,那么可能的参数值组合约为 (4000+1)(5+1)(10+1)=240k 个 *),我们不仅需要实时地判断这些事件以及参数值的组合是否超过了系统设定的阀值,还要保留最近 30 分钟的数据,以便于判断在这段时间内它们出现的频率是否也超过了阀值。
处理该问题最简单的方式或许就是将这些数据都存起来,然后每隔一秒钟就去计算每一种组合出现的频率,但是事实上这是无法实现的,因为这样每秒钟会有超过 240,000 个查询,系统是无法承受的。 André Camilo 给出的第一种方案是使用 Spark 和 ElasticSearch:
我们创建了一个 Spark Streaming 的数据流管道,该管道首先从 JMS 队列中读取消息并将其转换成 PhoneCall 事件,然后根据事件的参数值将一个事件分离成多个事件,之后再使用 countByWindow 函数计算每一种事件组合的频率,最后检查每种组合的平均频率是否超过了阈值。在使用 countByWindow 计算时,每秒钟都会设置一个 30 分钟的窗口,同时函数输出值会除以 1800 秒以得到每个窗口的平均频率,最终结果使用 ElasticSearch 集群存储。
该方案的流程如下:
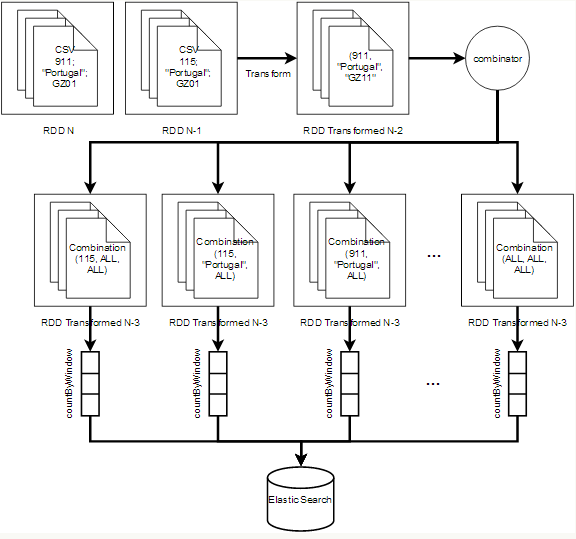
这一方案虽然可行,但是并没有解决 André Camilo 的问题,不是因为 Spark 不行,而是因为虽然 Spark Streaming 能够处理大量的实时数据,但是却无法处理大量的窗口。在 André Camilo 的实验中,如果组合数低于 1000,那么这种方案能够工作的很好,但是如果超出了这一数量,那么就会导致内存溢出问题。
André Camilo 给出的第二种方案是使用 Akka :
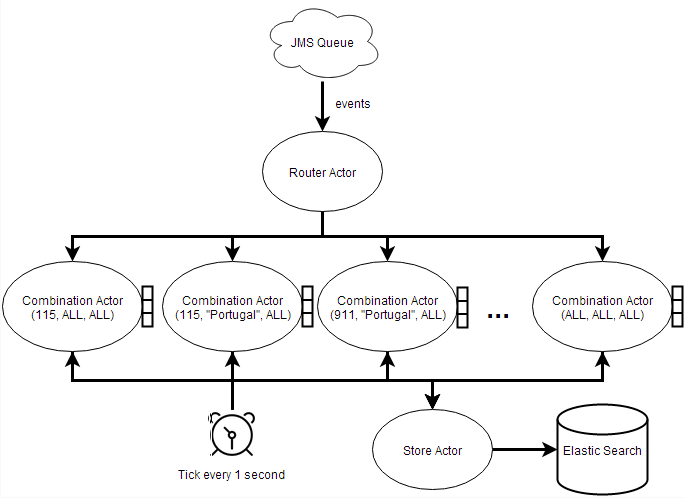
- 对每一种参数值的组合创建一个组合 Actor
- 创建一个负责接收所有事件的 Actor,该 Actor 根据事件的参数值将一个事件分离成多个事件,并根据参数组合的对应关系将分离后的事件发送到步骤 1 创建的组合 Actor
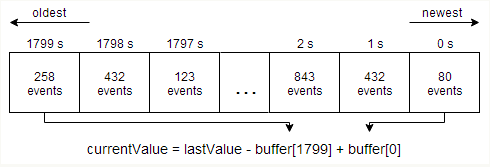
- 每一个组合 Actor 通过环形缓冲区存储最近 30 分钟的事件数(单位为秒),每过一秒,该缓冲区就滚动一个位置,同时该 Actor 会计算事件的频率,检查该频率是否超过了系统设定的阈值,并将结果发送到 ElasticSearch Actor
- ElasticSearch Actor 仅仅是一个 ActorPublisher,负责将数据发送到 ElasticSearch 流驱动
第二种方案的流程如下:
环形缓冲区的结构如下:
你可能会问,为每一种组合创建一个 Actor 会不会导致 Actor 太多?André Camilo 告诉我们,对 Akka 这个超轻量级的事件驱动框架来说这都不是问题。使用该方案 André Camilo 在一个 i7 4GB 的笔记本上轻松解决了 800 个事件的分离处理。更为重要的是,Akka 支持水平扩展,如果系统有更多的参数值组合,或者需要更大的吞吐量,那么只需要增加更多的机器即可。
最后,André Camilo 的结论是:Spark 有非常好的特性,它的解决方案更简单、更直观,但不太适合这个场景。Akka 非常适合处理 CPU 敏感的问题,Actor 模型更适合处理高并发的问题。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




