
导读:随着前端的范畴逐渐扩大,深度逐渐下沉,富前端必然带来的一个问题就是性能。特别是在大型复杂项目中,重前端业务可能因为一个小小的数据依赖,导致整个页面卡顿甚至崩溃。本文基于 Quick BI(数据可视化分析平台)历年架构变迁中性能的排查、解决和总结出的“个性”问题,尝试总结整个前端层面相对“共性”的问题,提供一些前端性能解决思路。
一 引发性能问题原因?
引发性能问题的原因通常不是单方面缘由,特别是大型系统迭代多年后,长期积劳成疾造成,所以我们要必要分析找到症结所在,并按瓶颈优先级逐个击破,拿我们项目为例,大概分几个方面:
1 资源包过大
通过 Chrome DevTools 的 Network 标签,我们可以拿到页面实际拉取的资源大小(如下图):
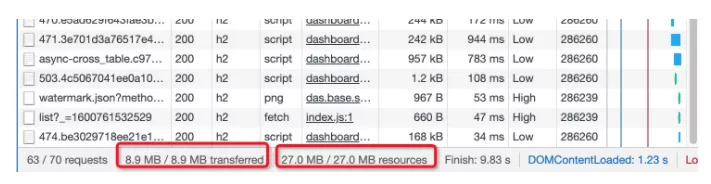
经过前端高速发展,近几年项目更新迭代,前端构建产物也在急剧增大,因为要业务先行,很多同学引入库和编码过程并没有考虑性能问题,导致构建的包增至几十 MB,这样带来两个显著的问题:
弱(普通)网络下,首屏资源下载耗时长
资源解压解析执行慢
对于第一个问题,基本上会影响所有移动端用户,并且会耗费大量不必要的用户带宽,对客户是一个经济上的隐式损失和体验损失。
对于第二个问题,会影响所有用户,用户可能因为等待时间过长而放弃使用。
下图展示了延迟与用户反应:

2 代码耗时长
在代码执行层面,项目迭代中引发的性能问题普遍是因为开发人员编码质量导致,大概以下几个缘由:
不必要的数据流监听
此场景在 hooks+redux 的场景下会更容易出现,如下代码:
const FooComponent = () => { const data = useSelector(state => state.fullData); return <Bar baz={data.bar.baz} />;};假设 fullData 是频繁变更的大对象,虽然 FooComponent 仅依赖其.bar.baz 属性,fullData 每次变更也会导致 Foo 重新渲染。
双刃剑 cloneDeep
相信很多同学在项目中都有 cloneDeep 的经历,或多或少,特别是迭代多年的项目,其中难免有 mutable 型数据处理逻辑或业务层面依赖,需要用到 cloneDeep,但此方法本身存在很大性能陷阱,如下:
// a.tsxexport const a = { name: 'a',};// b.tsximport { a } = b;saveData(_.cloneDeep(a)); // 假设需要克隆后落库到后端数据库上方代码正常迭代中是没有问题的,但假设哪天 a 需要扩展一个属性,保存一个 ReactNode 的引用,那么执行到 b.tsx 时,浏览器可能直接崩溃!
Hooks 之 Memo
hooks 的发布,给 react 开发带来了更高的自由度,同时也带来了容易忽略的质量问题,由于不再有类中明码标价的生命周期概念,组件状态需要开发人员自由控制,所以开发过程中务必懂得 react 对 hooks 组件的渲染机制,如下代码可优化的地方:
const Foo = () => { // 1. Foo可用React.memo,避免无props变更时渲染 const result = calc(); // 2. 组件内不可使用直接执行的逻辑,需要用useEffect等封装 return <Bar result={result} />; // 3.render处可用React.useMemo,仅对必要的数据依赖作渲染};Immutable Deep Set
在使用数据流的过程中,很大程度我们会依赖 lodash/fp 的函数来实现 immutable 变更,但 fp.defaultsDeep 系列函数有个弊端,其实现逻辑相当于对原对象作深度克隆后执行 fp.set,可能带来一些性能问题,并且导致原对象所有层级属性都被变更,如下:
const a = { b: { c: { d: 123 }, c2: { d2: 321 } } };const merged = fp.defaultsDeep({ b: { c3: 3 } }, a);console.log(merged.b.c === a.b.c); // 打印 false3 排查路径
对于这些问题来源,通过 Chrome DevTools 的 Performance 火焰图,我们可以很清晰地了解整个页面加载和渲染流程各个环节的耗时和卡顿点(如下图):

当我们锁定一个耗时较长的环节,就可以再通过矩阵树图往下深入(下图),找到具体耗时较长的函数。
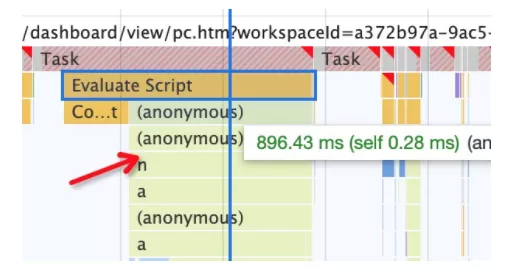
诚然,通常我们不会直接找到某个单点函数占用耗时非常长,而基本是每个 N 毫秒函数叠加执行成百上千次导致卡顿。所以这块结合 react 调试插件的 Profile 可以很好地帮助定位渲染问题所在:
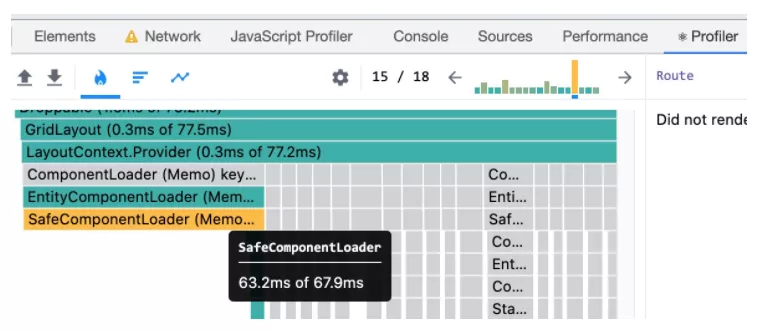
如图 react 组件被渲染的次数以及其渲染时长一目了然。
二 如何解决性能问题?
1 资源包分析
作为一名有性能 sense 的开发者,有必要对自己构建的产物内容保持敏感,这里我们使用到 webpack 提供的 stats 来作产物分析。
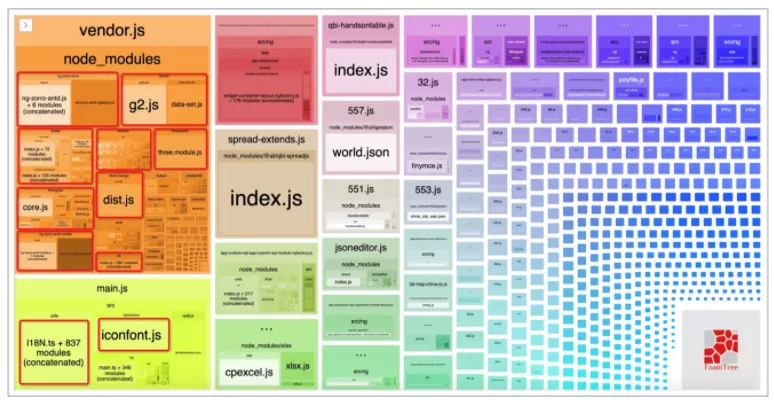
首先执行 webpack --profile --json > ./build/stats.json 得到 webpack 的包依赖分析数据,接着使用 webpack-bundle-analyzer ./build/stats.json 即可在浏览器看到一张构建大图(不同项目产物不同,下图仅作举例):
当然,还有一种直观的方式,可以采用 Chrome 的 Coverage 功能来辅助判定哪些代码被使用(如下图):
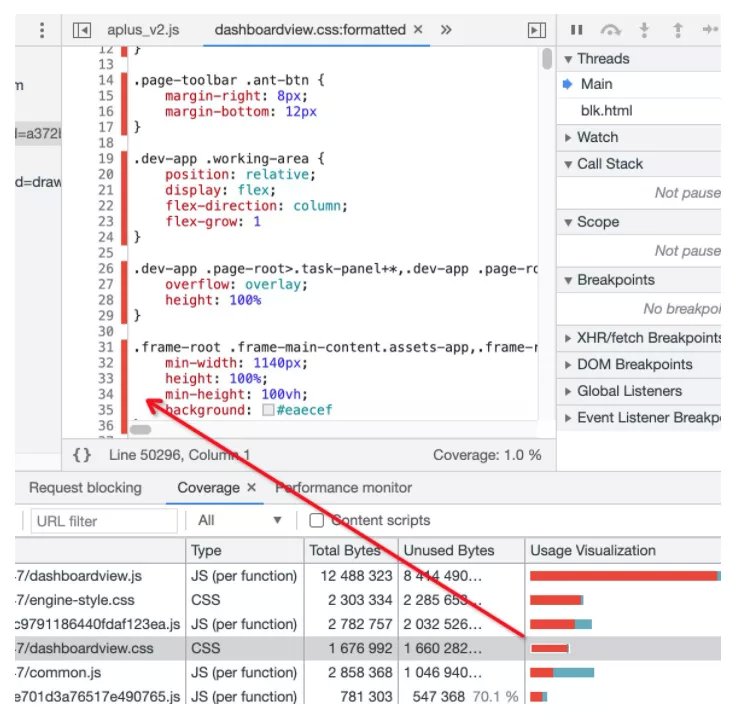
红色表示未执行过的代码
最佳构建方式
通常来讲,我们组织构建包的基本思路是:
按 entry 入口构建。
一个或多个共享包供多 entry 使用。
而基于复杂业务场景的思路是:
entry 入口轻量化。
共享代码以 chunk 方式自动生成,并建立依赖关系。
大资源包动态导入(异步 import)。
webpack 4 中提供了新的插件 splitChunks 来解决代码分离优化的问题,它的默认配置如下:
module.exports = { //... optimization: { splitChunks: { chunks: 'async', minSize: 20000, minRemainingSize: 0, maxSize: 0, minChunks: 1, maxAsyncRequests: 30, maxInitialRequests: 30, automaticNameDelimiter: '~', enforceSizeThreshold: 50000, cacheGroups: { defaultVendors: { test: /[\\/]node_modules[\\/]/, priority: -10 }, default: { minChunks: 2, priority: -20, reuseExistingChunk: true } } } }};根据上述配置,其分离 chunk 的依据有以下几点:
模块被共享或模块来自于 node_modules。
chunk 必须大于 20kb。
同一时间并行加载的 chunk 或初始包不得超过 30。
理论上 webpack 默认的代码分离配置已经是最佳方式,但如果项目复杂或耦合程度较深,仍然需要我们根据实际构建产物大图情况,调整我们的 chunk split 配置。
解决 TreeShaking 失效
“你项目中有 60%以上的代码并没有被使用到!”
treeshaking 的初衷便是解决上面一句话中的问题,将未使用的代码移除。
webpack 默认生产模式下会开启 treeshaking,通过上述的构建配置,理论上应该达到一种效果“没有被使用到的代码不应该被打入包中”,而现实是“你认为没有被使用的代码,全部被打入 Initial 包中”,这个问题通常会在复杂项目中出现,其缘由就是代码副作用(code effects)。由于 webpack 无法判定某些代码是否“需要产生副作用”,所以会将此类代码打入包中(如下图):
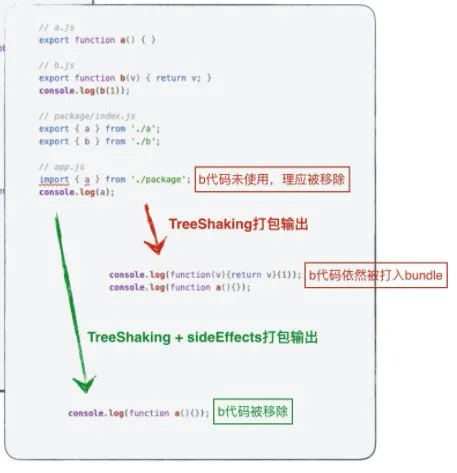
所以,你需要明确知道你的代码是否有副作用,通过这句话判定:“关于‘副作用’的定义是,在导入时会执行特殊行为的代码(修改全局对象、立即执行的代码等),而不是仅仅暴露一个 export 或多个 export。举例说明,例如 polyfill,它影响全局作用域,并且通常不提供 export。”
对此,解决方法就是告诉 webpack 我的代码没有副作用,没有被引入的情况下可以直接移除,告知的方式即:
在 package.json 中标记 sideEffects 为 false。
或 在 webpack 配置中
module.rules添加 sideEffects 过滤。
模块规范
由此,要使得构建产物达到最佳效果,我们在编码过程中约定了以下几点模块规范:
[必须] 模块务必 es6 module 化(即 export 和 import)。
[必须] 三方包或数据文件(如地图数据、demo 数据)超过 400KB 必须动态按需加载(异步 import)。
[禁止] 禁止使用 export * as 方式输出(可能导致 tree-shaking 失效并且难以追溯)。
[推荐] 尽可能引入包中具体文件,避免直接引入整个包(如:import { Toolbar } from '@alife/foo/bar')。
[必须] 依赖的三方包必须在 package.json 中标记为 sideEffects: false(或在 webpack 配置中标记)。
2 Mutable 数据
基本上通过 Performance 和 React 插件提供的调试能力,我们基本可以定位问题所在。但对于 mutable 型的数据变更,我这里也结合实践给出一些非标准调试方式:
冻结定位法
众所周知,数据流思想的产生缘由之一就是避免 mutable 数据无法追溯的问题(因为你无法知道是哪段代码改了数据),而很多项目中避免不了 mutable 数据更改,此方法就是为了解决一个棘手的 mutable 数据变更问题而想出的方法,这里我暂时命名为“冻结定位法”,因为原理就是使用冻结方式定位 mutable 变更问题,使用相当 tricky:
constob j= { prop: 42};Object.freeze(obj);obj.prop=33; // Throws an error in strict modeMutable 追溯
此方法也是为了解决 mutable 变更引发数据不确定性变更问题,用于实现排查的几个目的:
属性在什么地方被读取。
属性在什么地方被变更。
属性对应的访问链路是什么。
如下示例,对于一个对象的深度变更或访问,使用 watchObject 之后,不管在哪里设置其属性的任何层级,都可以输出变更相关的信息(stack 内容、变更内容等):
const a = { b: { c: { d: 123 } } };watchObject(a);const c =a.b.c;c.d =0; // Print: Modify: "a.b.c.d"watchObject 的原理即对一个对象进行深度 Proxy 封装,从而拦截 get/set 权限,详细可参考:
https://gist.github.com/wilsoncook/68d0b540a0fea24495d83fc284da9f4b
避免 Mutable
通常像 react 这种技术栈,都会配套使用相应的数据流方案,其与 mutable 是天然对立的,所以在编码过程中应该尽可能避免 mutable 数据,或者将两者从设计上分离(不同 store),否则出现不可预料问题且难以调试
3 计算 &渲染
最小化数据依赖
在项目组件爆炸式增长的情况下,数据流 store 内容层级也逐渐变深,很多组件依赖某个属性触发渲染,这个依赖项需要尽可能在设计时遵循最小化原则,避免像上方所述,依赖一个大的属性导致频繁渲染。
合理利用缓存
(1)计算结果
在一些必要的 cpu 密集型计算逻辑中,务必采用 WeakMap 等缓存机制,存储当前计算终态结果或中间状态。
(2)组件状态
对于像 hooks 型组件,有必要遵循以下两个原则:
尽可能 memo 耗时逻辑。
无多余 memo 依赖项。
避免 cpu 密集型函数
某些工具类函数,其复杂度跟随入参的量级上升,而另外一些本身就会耗费大量 cpu 时间。针对这类型的工具,要尽量避免使用,若无法避免,也可通过 “控制入参内容(白名单)” 及 “异步线程(webworker 等)”方式做到严控。
比如针对 _.cloneDeep ,若无法避免,则要控制其入参属性中不得有引用之类的大型数据。
另外像最上面描述的 immutable 数据深度 merge 的问题,也应该尽可能控制入参,或者也可参考使用自研的 immutable 实现:
https://gist.github.com/wilsoncook/fcc830e5fa87afbf876696bf7a7f6bb1
const a = { b: { c: { d: 123 }, c2: { d2: 321 } } };const merged = immutableDefaultsDeep(a, { b: { c3: 3 } });console.log(merged === a); // 打印 falseconsole.log(merged.b.c === a.b.c); // 打印 true三 写在最后
以上,总结了 Quick BI 性能优化过程中的部分心得和经验,性能是每个开发者不可绕过的话题,我们的每段代码,都对标着产品的健康度。
本文转载自公众号高德技术(ID:amap_tech)。
原文链接:




