

编者按:本文节选自华章科技智能系统与技术丛书 《深入理解 AutoML 和 AutoDL:构建自动化机器学习与深度学习平台》一书中的部分章节。
“机器学习”名字的由来
人工智能在 1956 年由约翰·麦卡锡(John McCarthy)首次定义,其含义是可以执行人类智能特征任务的机器。包括语言理解、物体识别、声音识别、学习和智能地解决人类问题等方面。人工智能可以从广义和狭义两个方面理解:广义是指人工智能是可以实现同等人类能力的计算机;狭义是指其可以做人类要求的特定任务,并且能够做得非常好,比如一台用来识别图像的机器就仅限于能够很好地识别图像,而不能做其他事情。
机器学习是人工智能的核心任务,阿瑟·塞缪尔(Arthur Samuel)将机器学习定义为“没有明确编程就能学习的能力”。虽然在不使用机器学习的情况下,就可以实现人工智能,但是这需要通过定义复杂的规则和决策树等方式来构建数百万行代码。因此,就出现了现在的机器学习算法,不需要通过手动编码和定义特定的指令来完成特定的任务,只需要以一种“训练”算法的方式让机器自己学习,并根据输入的数据进行自我调整和改进。
那么“机器学习”的名字是怎么来的呢?
1952 年,阿瑟·塞缪尔在 IBM 公司研制了一个西洋跳棋程序,塞缪尔自己并不是下西洋棋的高手,因此这个计算机程序的下棋能力很差,但是它具有自学习能力,可以通过自己对大量棋局的分析,逐渐学会如何分辨当前局面出的是“好棋”还是“坏棋”,从中不断积累经验和吸取教训,进而不断提高棋艺,最后竟然超过了塞缪尔本人。塞缪尔认为,在不使用具体的代码,只使用一定数量的训练数据和泛型编程的前提下,机器就可以从训练数据中学到赢棋的经验,这就是机器学习最初的定义。1961 年,“知识工程之父”爱德华·费根鲍姆(Edward Feigenbaum,1994 年图灵奖得主)为了编写其巨著《Computers and Thought》,邀请塞缪尔提供该程序最好的一个对弈实例。借此机会,塞缪尔向当时的康涅狄格州的跳棋冠军,也是全美排名第四的棋手发起挑战,最终塞缪尔的程序获得了胜利,轰动一时。
塞缪尔的这个跳棋程序不仅在人工智能领域成为经典,它还推动了整个计算机科学的发展进程。计算机刚出现的时候,只是被用来做大型计算的机器,不可能完成没有事先编好程序的任务,而塞缪尔的跳棋程序,打破了这种思想的禁锢,创造了不可能,从那以后,引领了新的计算机潮流,成为后人发展计算机的新方向。
“机器学习”的前世今生
20 世纪 50 年代到 70 年代初期,人工智能在此期间的研究被称为“推理期”,简单来说,人们认为只要赋予机器逻辑推理能力,机器就能具有智能。这一阶段的代表性工作有 A. Newell 和 H. Simonde 的“逻辑理论家”(Logic Theorist)程序,以及后来的“通用问题求解”(General Problem Solving)程序等,这些工作在当时获得了令人振奋的结果。“逻辑理论家”程序分别在 1952 年和 1963 年证明了著名数学家罗素和怀特海的名著《数学原理》中的 38 条定理和全部的 52 条定理。因此,A. Newell 和 H. Simonde 成为 1975 年图灵奖的获得者。随着研究的深入发展,机器仅仅具有逻辑推理能力是远远不够的,为了实现人工智能,机器必须要具有智能,也就是说,必须要想办法让机器拥有知识。
从 20 世纪 70 年代中期开始,人工智能的研究就进入了“知识期”。1965 年,Edward Feigenbaum 主持研制了世界上第一个专家系统“DENDRAL”,自此开始,一大批专家系统成为主流,它们也在很多应用领域取得了成功。因此,在 1994 年 Edward Feigenbaum 获得了图灵奖。但是,专家系统随着科学技术的进步,面临了“知识工程瓶颈”,最大的困境就是,由人把知识总结出来再教给计算机是相当困难的。那么,让机器自己学习知识,会不会成为可能呢?
答案是肯定的,有太多的事实已经证明机器是可以自己学习知识的,其中最早的是上文提到的塞缪尔的跳棋程序。到 20 世纪 50 年代中后期,出现了基于神经网络的“联结主义”(Connectionism)学习,代表作是 F. Rosenblatt 的感知机(Perceptron)、B. Widrow 的 Adaline 等。在 20 世纪六七十年代,多种学习技术得到了初步发展,基于逻辑表示的“符号主义”(Symbolism)学习逐渐发展,例如以决策理论为基础的统计学习技术以及强化学习技术等。二十多年后,“统计机器学习”(Statistical Learning)迅速崛起,代表性的技术有支持向量机(Support Vector Machine,SVM)等。
在过去的二十多年中,人类在收集数据、存储、传输、处理数据上的需求和能力得到了很大的提升。随着大数据时代的到来,人类社会无时无刻不在产生着数据,那么如何有效地对数据进行分析和利用,成为迫切需要解决的问题,而机器学习恰巧成为有效的解决方案。目前,在人类生活的各个领域,都可以看到机器学习的身影。无论是在复杂的人工智能领域,如自然语言处理、专家系统、模式识别、计算机视觉、智能机器人,还是在多媒体、网络通信、图形学、软件工程、医学领域,甚至是更常见的购物系统等,机器学习已然成为我们不可获取的一部分。
有关机器学习的介绍已经非常多了,在这里就不再赘述,我们接下来的讲述重点将放在机器学习的实现方法,还有为了解决现有机器学习的问题,而产生的自动化机器学习到底是什么吧。
“机器学习”的理论基础
在机器学习发展的过程中,逐渐分划成两条路线,这同时也影响了后来的自动化机器学习。一条路线是以 Barlow 为主导的单细胞学说,这个理论是说,一开始是从零基础开始的,一个单细胞逐渐发展生长出多个细胞,这也意味着神经细胞的结构可能会很复杂。而另一条路线是 Hebb 主张的,由多个相互关联的神经细胞集合体作为开始,称其为 ensemble,并不断通过改变细胞个数和细胞间的连接来发展神经细胞的结构。虽然这两种假设都有生物学证据的支持,但是至今没有生物学的定论,这也为计算机科学家们提供了想象的空间,也造就了后来机器学习发展过程的不同研究路线,并且这两种假设都对机器学习研究有相当重要的引导作用。
基于这两种假设,机器学习的发展历程被分为了两类,一类是以感知机、BP 和 SVM 等为主导的,另一类是以样条理论、K-近邻、符号机器学习、集群机器学习和流形机器学习等代表的。
本书中的重点—统计机器学习是近几年被广泛应用的机器学习方法。从广义上说,这是一类方法学。当我们从问题世界观测到一些数据,如果没有能力或者没有必要建立严格的物理模型时,可以使用数学方法从这些数据中推理出数学模型。注意,这里的数学模型一般是没有详细的物理解释的,不过会在输入输出的关系中反映实际问题,这就是我们开始提到的“黑箱”原理。一般来说,“黑箱”原理是基于统计方法的,统计机器学习的本质就是“黑箱”原理的延续。因此,统计机器学习主要关注的是数学方法的研究,而神经科学则被列为深度学习领域。
统计机器学习的基本要求是,假设同类数据具有一定的统计规律性。目标则是,从假设的空间中,也就是常说的模型空间,从输入空间到输出空间的映射空间中寻找一个最优的模型。综上,可以总结统计机器学习方法的主要研究问题,可分为如下 3 个:
1)模型假设:模型假设要解决的问题是如何将数据从输入空间转化到输出空间,通常用后验概率或是映射函数来解决。
2)模型选择:在模型的假设空间中,存在无穷多个满足假设的可选择模型,模型选择要解决的问题就是如何从模型假设空间中选择一个最优模型。通常采用损失函数来指定模型选择策略,将模型选择转化为一个最优化问题来求解。为了降低模型的复杂性,提高模型的泛化能力,避免过拟合的发生,通常会加上正则化项。
3)学习算法:既然已经将模型选择转化为一个最优化问题了,那么最优化问题该如何实现,这就是学习算法要解决的了。比如在给定损失函数后,并且在损失函数的约定条件下,怎样快速地找到最优解,常用的学习算法包括梯度下降等。
统计机器学习的这 3 个问题都是机器学习发展过程中的研究热点。对于模型假设来说,如果模型选择错误,那么无论如何都难以描述出数据集的正确分布特性。从而,在模型空间假设上,衍生出了很多方法,包括交叉验证等。模型选择的关键问题在于损失函数的设计,损失函数通常包括损失项和正则化项,不同的选择策略会造成不同的模型选择,而模型选择的不同,则会导致预测效果的巨大差异。对于学习算法来说,不同的学习算法,其学习的效率会有很大的差异,而且学习出来的效果也不一样。
统计机器学习是基于对数据的初步认识以及学习目的的分析(特征工程),选择合适的数学模型,拟定超参数,并输入样本数据,依据一定的策略,运用合适的学习算法对模型进行训练,最后运用训练好的模型对数据进行分析预测。具体流程如图 1 所示。
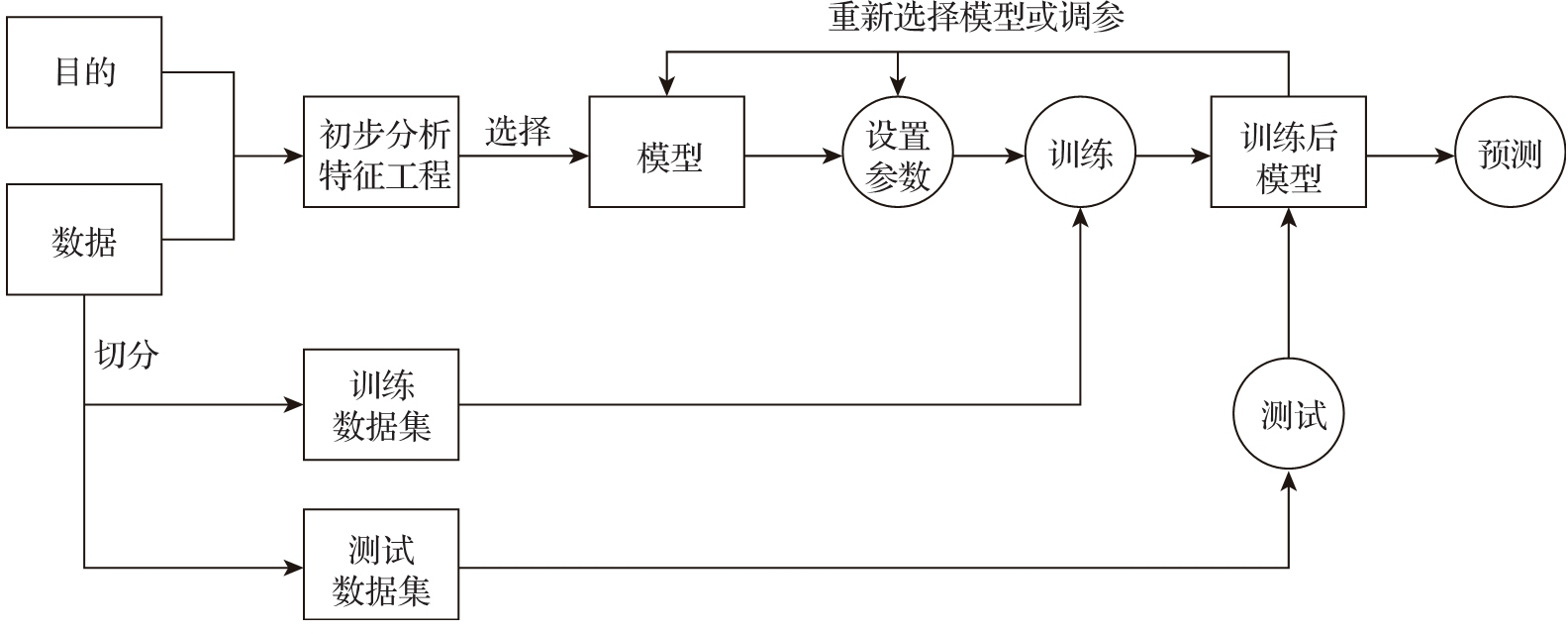
图 1 统计机器学习的流程图
根据图 1 中的流程和统计机器学习研究的 3 个主要问题,可以将统计机器学习总结为如下 3 个要素:
1)模型(model):比如支持向量机、人工神经网络模型等。模型在未进行训练前,其可能的参数是多个甚至无穷的,故可能的模型也是多个甚至无穷的,这些模型构成的集合就是假设空间(hypothesis space)。
2)策略(strategy):即从假设空间中挑选出参数最优的模型的准则。模型的分类或预测结果与实际情况的误差(损失函数)越小,模型就越好。
3)算法(algorithm):即从假设空间中挑选模型的方法(等同于求解最佳的模型参数)。机器学习的参数求解通常都会转化为最优化问题,例如支持向量机实质上就是求解凸二次规划问题。
图书简介:https://item.jd.com/12685946.html

相关阅读
深入理解AutoML和AutoDL(一):AutoML的研究意义
深入理解AutoML和AutoDL(二):现有AutoML平台产品盘点

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论