

本文最初发表在 Medium 博客,经原作者 Deep Dutta 授权,InfoQ 中文站翻译并分享。
本文带你从零开始了解量子机器学习。
如今,随着量子信息科学的日益普及,量子机器学习将是信息科学与技术领域的下一个大事件。从根本上说,量子机器学习是量子计算和机器学习的结合。从零开始学习吧。
什么是量子计算机?
所以,量子计算基本上是在量子计算机上进行的计算,因为许多因素,如计算速度和计算空间,在经典计算机上是无法完成的。进行量子计算的计算机叫做量子计算机,它利用了量子的叠加、纠缠、干涉等性质。
量子计算机和经典计算机的区别是什么?
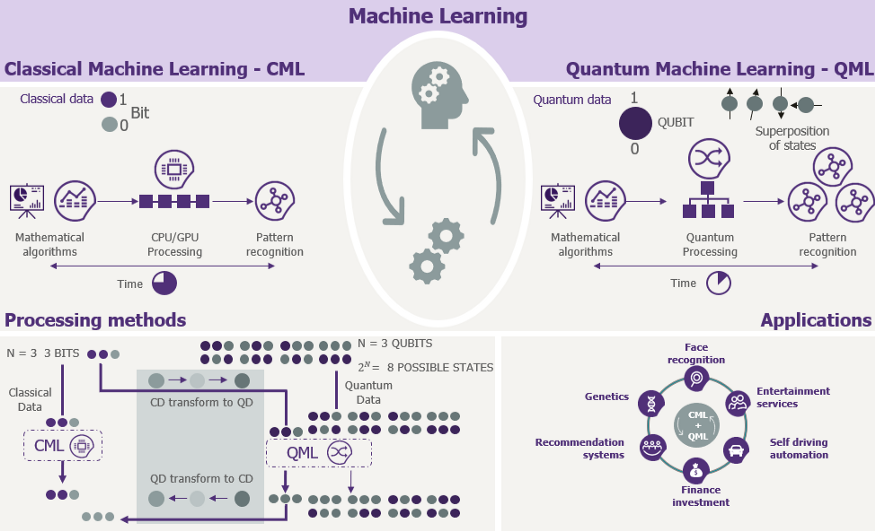
量子计算机与经典计算机的基本区别在于,经典计算机以比特为工作对象,而量子计算机以量子比特为工作对象。因此,如果我们想把数据存储在经典计算机中,它首先被转换成 0 和 1 的特定组合,然后把二进制数据存储在硬盘上。硬盘上有磁区,我们有磁极化,我们可以改变磁化强度,使之指向上或指向下。
而在量子比特中,可以用叠加的方法得到任意组合的二进制结果,我们可以把它看作是自旋。这样我们就可以把它想象成自旋向上或自旋向下,但我们也可以把它想象成是向上和向下的叠加,如果它足够孤立的话。
基本的量子特性是什么?
叠加、纠缠和干涉是量子信息科学中的三个基本属性。下面我们将简要地讨论这些特性。
叠加:我们已经讨论过叠加,它不仅仅是 0 或 1。它的状态是 0 和 1 的组合。通过一个例子,我们就能很容易地理解这一点。假设我有一个钢镚,它的正面和反面两个结果分别被分配为 0 和 1。无论什么时候,如果我们把这枚钢镚的一面朝下,问问别人这个钢镚是正面还是反面,我们都能很容易地回答这个钢镚是正面还是反面。它就像是经典计算机中的比特。现在,如果我们旋转钢镚并提问同样的问题,我们就不能回答这一问题,因为它可以是任意一面的组合。很可能就是量子比特。
纠缠:简单地说,假设我们有两个量子比特,如果我们把它们纠缠在一起,它们就会连接起来,然后它们就会永久地连接起来,然后它们的行为就像一个系统。这就是纠缠。并且,每一个成对或成组的粒子的量子状态不能独立于其他粒子的状态来描述,它们之间是以这种方式联系在一起的。举个例子就会更简单。假设我们有两个钢镚(把它们当成量子比特),它们纠缠在一起。然后,如果我们各自旋转两个钢镚,在停止之后,它们应该有相同的结果(正面或反面)。
干涉:想一想降噪耳机。它们是怎么工作的?它读取周围环境的波长,然后产生相反的波长来抵消。它们实际上制造了干涉。干涉有两种类型,相长干涉和相消干涉。在相长干涉中,两波的波峰(或波谷)同时抵达同一地点,称两波在该点同相,干涉波会产生最大的振幅;而在相消干涉中,两波之一的波峰与另一波的波谷同时抵达同一地点,称两波在该点反相,干涉波会产生最小的振幅。所以这个性质被用于控制量子态的。它放大了那些指向正确答案的信号,而消除了那些指向错误答案的信号。
什么是机器学习?
机器学习无非是在海量数据的帮助下训练机器(计算机),让计算机从我们的数据中找到一些模式,然后将这些模式应用到新的数据集上。你可以把它看作是婴儿如何学会说话。在不同的场合,他 / 她会多次听到我们周围环境中的大量词汇,并且每天学习何时说什么。
这是一个持续的过程,并且持续一生。同样,我们第一次遇到许多不同的单词,然后找出一种情况(计算机的模式),什么时候用到这个单词,以后遇到相同的情况就可能用到这个单词。因此,在这个例子中,我们正在使用这些数据来训练大脑。计算机就像一个婴儿,除了把 0 和 1 的组合作为输入外,它什么都不知道。因此,我们使用大量的数据训练计算机,然后使用另一组数据的模式完成某些任务。使用机器学习,我们可以解决许多不同类型的问题。在回归中,我们预测测试数据集的一些值;在分类中,我们可以在不同类别的数据之间进行分类。
什么是量子机器学习?
如今,通过对量子计算和机器学习的了解,我们很容易就能理解其背后的概念。量子机器学习无非是当我们在量子计算机上,或者在量子实例中代替经典计算机进行机器学习计算。下面我给大家举一个分类的基本问题,量子机器学习比经典机器学习更好。这里我将使用支持向量机算法(Support Vector Machine,SVM)。经典支持向量机与量子支持向量机的基本区别在于,经典支持向量机运行在经典实例上,而量子支持向量机运行在量子实例上。下面我们简单介绍一下支持向量机。
支持向量机:假设我们处理的是一个二元分类问题。然后,支持向量机算法的目标是在高维空间中找到一个超平面,超平面可以清晰地划分数据点。为了区分这两类数据点,需要选择多个可能的超平面。我们的目标是找到一个具有最大余量的平面,也就是两类数据点之间的最大距离。最大化边缘距离提供了一种增强方法,从而可以更有把握地对未来的数据点进行分类。
量子机器学习框架:到目前为止,量子机器学习有一些很好的框架。Tensorflow 有Tensorflow Quantum,IBM 有QisKit。除了这些之外,Pennylane还有一个很好的量子机器学习实现,并且所有的库都有很好的文档。如果你想知道更多的话,你可以通过它。在本文中,我将使用 qiskit 来实现。
量子机器学习超越经典机器学习?
接下来,我们会看到一个量子机器学习比传统机器学习实现有明显的优势。为了简单起见,我们将使用一个基本数据集,即ad-hoc数据集。在此,除了经典计算机所需要的所有依赖关系外,我们还需要通过导入 BasicAer 导入一个 Quantum Simulator,通过导入 ZZFeaturemap 导入一个特征图而不是量子特征图,通过导入 QuantumInstance 导入一个量子实例,最后是 QSVM。
我们把特征维度取 2,训练和测试大小分别取 20 和 10。这样做就可以进行基本的比较,另一个原因是我们目前还没有足够稳定的量子计算机。除此之外,我们把随机种子和散点数设为 10000。将 gap 设为 0.3,这只是一个高维空间的空隙,可以分隔我的数据。我们还会绘制数据并标记类。

加载和绘制数据集
因此数据集看起来是这样的,有两个类 A 和 B,分别标记为 0 和 1。所以我们可以清楚地看到,我们需要一个高维空间中的超平面来区分这两个类。
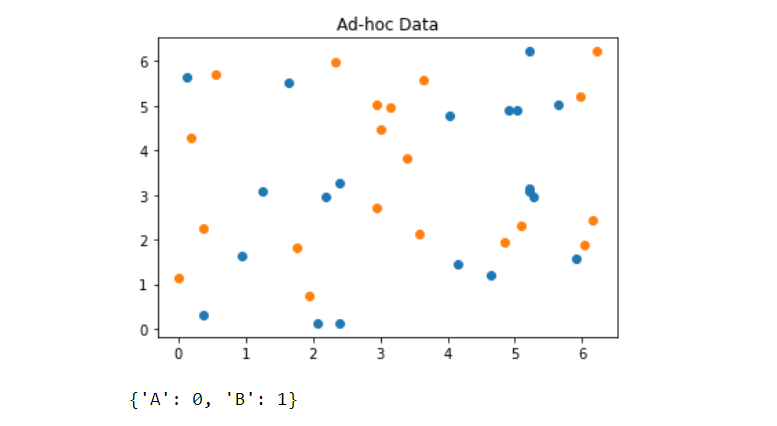
看一看数据集
为了在经典计算机上运行量子支持向量机,我们需要有一个量子模拟器作为后端,还有一个量子实例来在我的后端上运行。所以我们在 BasicAer 的后端有一个 Qasm-simulator,以及一个具有 reps2 的特征图,即重复电路(量子电路)的数目为 2。然后我们将在量子实例上运行量子支持向量机。

运行量子支持向量机
在运行量子支持向量机之后,我们就能在训练过程中检查我们的内核矩阵了。内核矩阵如下:
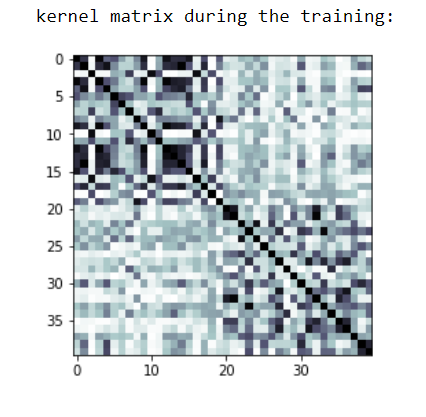
量子支持向量机内核矩阵
在量子支持向量机训练完成之后,就可以对测试数据集进行分类预测了。而你可以清楚地看到,量子支持向量机在这两个类别中的分类非常完美。
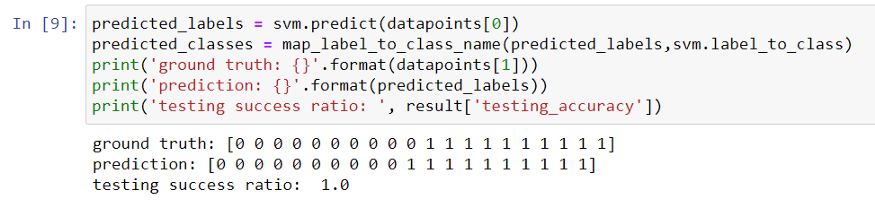
量子支持向量机预测
在掌握了量子支持向量机的正确率之后,我们就可以实现经典支持向量机,并比较量子支持向量机和支持向量机的正确率。在 qiskit 中也有同样的 scikit-learn SVM 的实现,我们将在本文使用该实现。内核矩阵如下:
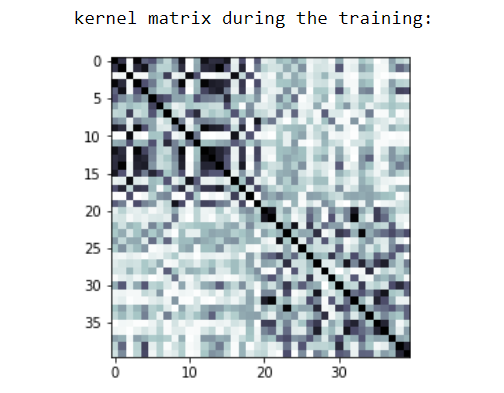
支持向量机内核矩阵
而我们可以看到支持向量机对两个类的分类准确率都达到了 65%。所以,这里量子支持向量机的表现明显超过了机器学习。但是为什么呢?

为什么量子机器学习会超越经典机器学习?
既然我们在讨论支持向量机,我们就会用支持向量机的术语来解释它。对于分类来说,找到一个分割超平面往往只有在更高维度才有可能。这涉及到计算高维空间中数据点之间的距离。因此,如果维数很大,则计算发现距离的开销就非常大。所以,更简单的做法被称为“内核技巧”。内核是一个易于计算的函数,它获取我们的数据点并返回一个距离,而内核可以通过优化来最大化类间的距离。遗憾的是,有些内核指标很难用类计算。这就是量子计算机的用武之地。如果内核不能进行类优化,量子机器学习就显示出了很大的前景,因为它能够利用量子计算机的多维计算空间来寻找超平面。当数据从其输入维度映射到量子计算机的希尔伯特空间时,自然会把数据放到更高维空间。因此,量子支持向量机的性能优于支持向量机。
你可以在这里找到完整的代码实现:
https://github.com/itzzdeep/Quantum-Machine-Learning
作者介绍:
Deep Dutta,熟悉机器学习。
原文链接:
https://medium.com/swlh/quantum-machine-learning-the-next-big-thing-95bfc3b4f08f

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论