

本篇文章选自数据库内核杂谈系列文章。
数据库是用来存储海量数据的。存储如此大量的数据,自然而然想到的就是以文件的形式存储在硬盘(HDD 或 SSD)中。当然,一些商用数据库为了追求性能,是将数据优先存储在内存中(比如 SAP 的 HANA 和 MemSQL)来获得更高速的读写。本文主要涉及的是关系型数据库针对硬盘的存储。对于内存数据库来说,依然需要硬盘作为备份或者 2 级存储,所以相关知识也是适用的。
相较于列举常见的存储形式然后对比优缺点的分类法,我们今天另辟蹊径,从"演化论"的角度来看,不同的存储形式和优化方法是怎么一步一步进化出来的。
一个数据库存的是什么呢?这里简单介绍一下关系模型(relational model)。关系模型由 Ted Codd1970 年提出,关系模型定义了所有的数据都是以元组(tuple)的形式存在,每个元组定义了多个属性(attribute)的键值对,多个含有相同属性的元组排列在一起就形成了一个关系(relation)。元组,属性和关系对应到数据库中的概念就是行(row),列(column), 和表(table)。一个表定义了多个 column,每个 column 有一个 type,每个 row 对应于每一个 column 都有一个取值(取值满足 type 的定义),每个表又由多个 row 构成。不同的数据库虽然有库(database),schema 或者命名空间(namespace)等不同级别的逻辑抽象,但是表却是每个关系型数据库最基本的存储对象。
好了,确认了数据库需要存储的基本单元是表。那么给定一张表,应该怎么存在文件中呢?如果还能回想起上一讲的内容,你会说,可以用 comma-separated-value(CSV)格式的文件来存储。确实,CSV 文件中的每一行对应于一条 row,每个 row 的不同 column 用逗号隔开,一个文件对应了一张表。下图截取了一段 Titanic 幸存者的 CSV 文件。

titanic_survivor.csv

titanic_survivor_with_header.csv
方法二,把 column 的定义(我们通常称之为表的元数据)和数据分开存储。比如存在一个叫 titanic_survivor.header 的文件中,下图给了文件的示意。
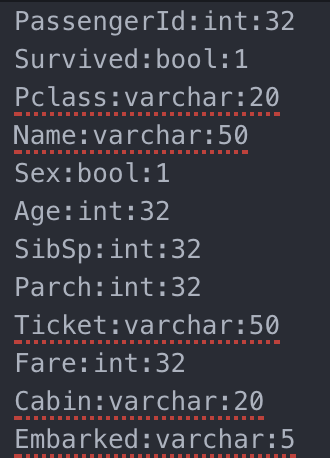
titanic_survivor.header
比较这两种方法,哪一种更好呢?我们可以从支持数据库操作的角度出发来看。对于表,数据库系统会支持新增一个新属性,修改或删除已有属性。如果把属性放在 csv 文件的第一行,对于任何一种属性操作,需要对文件进行大量的改动:对于删除一个已有属性,需要删除所有行的对应数据来保证 CSV 文件的有效性,对于新增一个新属性,同样需要修改每一行。如果数据文件非常大(1 billion rows), 会消耗大量时间来更新数据。对于第二种方法,修改的代价就小很多,只需要对 header 文件进行修改即可。你可能会有疑问,如果单单修改 header 文件,岂不是和数据文件就对应不上了。一个可行的解决方案就是在对 header 文件修改时,加上标注。比如对于删除一个现有属性,只需要标注这个属性被删除,并不直接在 header 文件里删除这个属性的定义。当数据库对表的数据进行读取时,我们只需要同时读取 header 文件,然后根据最新的定义,对于读取的每一行数据,忽略已经被删除的属性值即可。同理,当新增一个新属性时,标注这是一个新属性,并给定默认值(不给定数据库会定义为 NULL),那在读取每一行数据时,如果没有新属性,就赋予默认值即可。
这种分离元数据和数据的另一个好处在于,方便数据库统一管理所有表的元数据。几乎所有的数据库都会提供类似于 information schema 的功能,用来显示数据库的各种元数据。比如有几个 namespace,对于每个 namespace 分别有几个表,每个表都有哪些属性。单独存储表的属性就更方便读取和管理。
为了更好得支对表的元数据的管理和变更操作,我们从原有的 csv 文件进化出了第一个特性,分离元数据和数据的存储。
讨论完了元数据的管理,我们再来看 CSV 文件对于其他常见的数据库操作还有什么做得不够好的。除了最频繁的查询语句,另一类常见的操作就是添加,修改或者删除表里的数据。对于添加,我们只需要将新数据添加到文件的末尾。对于修改,如改变某一行的某一个属性或删除某一行,就需要在数据文件中进行修改。相较于在文件末尾添加,文件中的修改会低效很多,尤其是当数据文件特别大的时候。
有什么思路来改进呢?那些数据库先贤就想了一招,分开管理的思路也可以用在数据本身呢。设想一下,除了 CSV 存放每一行数据外,我们再单独维护一个 slot_table 的文件,这个文件存啥呢,就存对应 CSV 数据文件每一行的标注信息,比如对应原始的 CSV 文件,我们先生成对应的 slot_table 如下:

tianic_survivor.slot_table
对应每一行,我们标注 V 表示(valid)。对应于新增数据操作,我们只要同时 append 数据行和 slot_table 行即可。如果我们现在执行了一个更新语句,删除姓名起始为"Cumings"的数据,那第二行的数据就要被删除。对应的,我们可以不用修改 CSV 文件,只是把 slot_table 中的 2:V 改为 2:D(deleted)。如果要执行更新语句呢,比如把姓名为"Braund, Mr. Owen Harris"年龄纪录更新成 37 岁,这又应该怎么操作呢?我们可以在数据文件中添加一行新数据(第 9 行),这行数据复制了第一行但是把年龄改成 37。在 slot_table 文件中把 1 改为 D,然后添加 9:V。修改后的 slot_table 和数据文件如下:
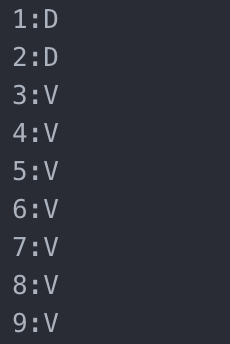
updated titanic_survivor.slot_table
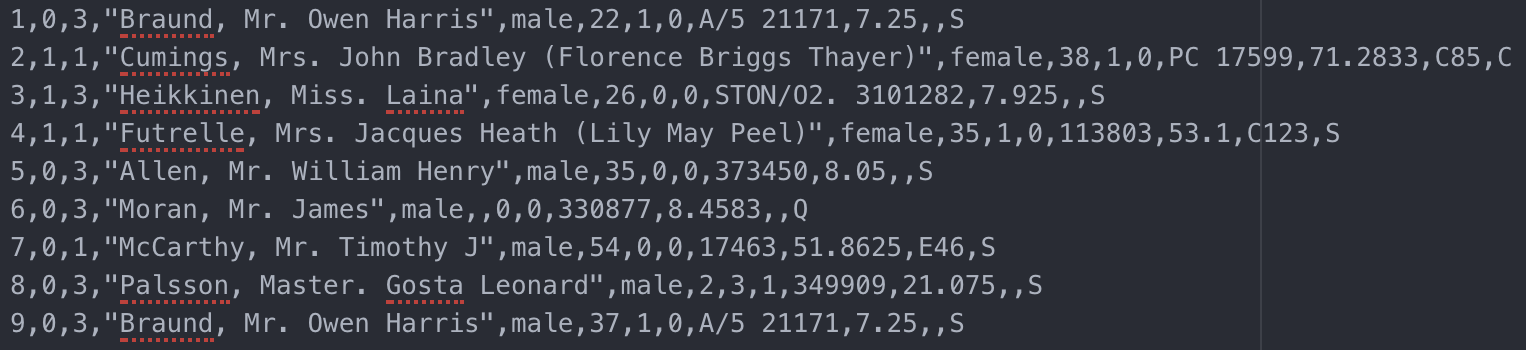
updated titanic_survivor.csv (line 9)
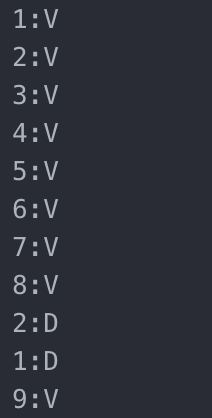
append only titanic_survivor.slot_table
然后在读取数据的时候,先读取 slot_table,然后逆序读取所有行的标注信息(读取到 2D 后就忽略第二行),就能知道哪些行是有效的,哪些行可以略过不用读取了。
对于数据的增删改,我们已经可以对数据文件和 slot_table 都实现 append_only。还有什么问题吗?对于一个数据表,每次操作都会添加新信息,久而久之,数据文件越来越大,而且无效的行越来越多,岂不是很浪费空间。有什么办法可以优化呢?有。数据库都会支持 vacuum 操作(或者叫 compact),这个操作所做的就是读取数据文件和 slot_table,然后根据标注把有效的数据行写回新的文件。比如,对我们的示例进行 vacuum 操作,新的数据文件和 slot_table 如下所示:
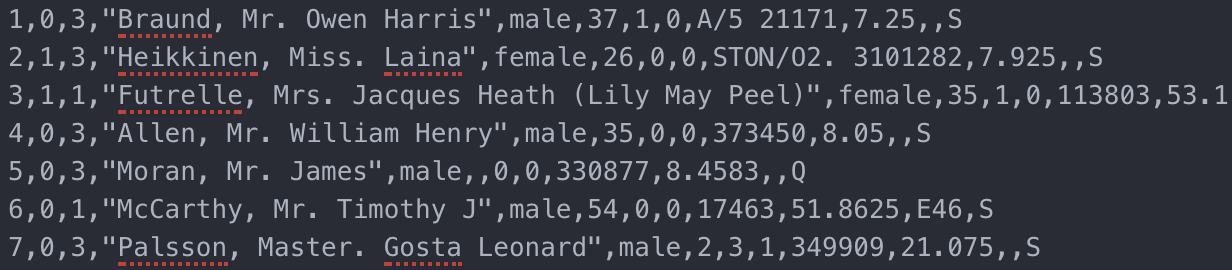
vacuumed titanic_survivor.csv
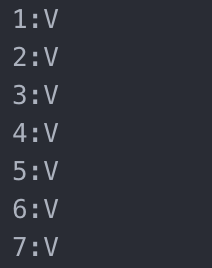
vacuumed titanic_survivor.slot_table
为了更高效地实现增删改数据,我们引入了第二个特性,slot_table 以及标注信息来纪录对数据的增删改,并且引入 vacuum 操作定期清理无用的行数据。
对于 CSV,还有什么能改进的吗?你可能已经发现了,CSV 是用明文来存储数据,太低效了。比如对应一个 boolean 的类型,明文存成 true 或者 false,如果用 ascii 编码就是 32 或者 40 个 bit(按照 8bit 的 extended ascii 编码)。但如果用 byte 存储,只要 1 个 bit 即可(即便是用 0,1 明文来存储 boolean 也还是没有 byte 高效)。CSV 为了方便用户直接能够理解,所以牺牲了效率。但是数据文件完全由数据库系统管理和读取,可以存储 raw byte 配上高效的编码和解码算法来进一步优化。那如何才能更高效得存储呢?这里我就不给出具体的实现了,可以参考现在流行的 RPC 框架比如Thrift和Protocol Buffers,这些网络端传输数据的协议,为了追求效率对数据的编码和解码有很多优化。相对应的,slot_table 里存储的不再只是行号,而应该是该条数据对应在文件中的 byte offset。
为了更高效得存储数据,我们引入了第三个特性,用 raw byte 来存储数据配合高效的编码和解码算法来加速读取和写入。
还有什么能再进一步优化吗?说下一步优化前,我们先来了解这样一类数据库。这类数据库并不进行修改和添加操作,但是存储了大量的数据,并且要运行大量非常复杂的分析语句。没错,这类数据库是数据仓库(Data warehouse)。区别于普通的 Online transactional processing(OLTP)的数据库,通过抓取,清洗和变化 OLTP 数据库的数据然后导入到数据仓库负责分析报表等需要查询大量历史数据的复杂语句。这类数据库的表结构称之为雪花模型(snowflake schema),由一张或者多张的实体数据表(entity table),配合一些辅助表(英文里称 dimension table)。实体数据表通常是交易记录等存有大量数据(亿甚至千亿级别),辅助表则只有少量的相关信息比如国家,商户等的具体信息。下图引用了 TPC-H(非常有名的数据库基准测试)的雪花模型,其中表 lineitem_orders 就是一个包含所有交易纪录的实体表。
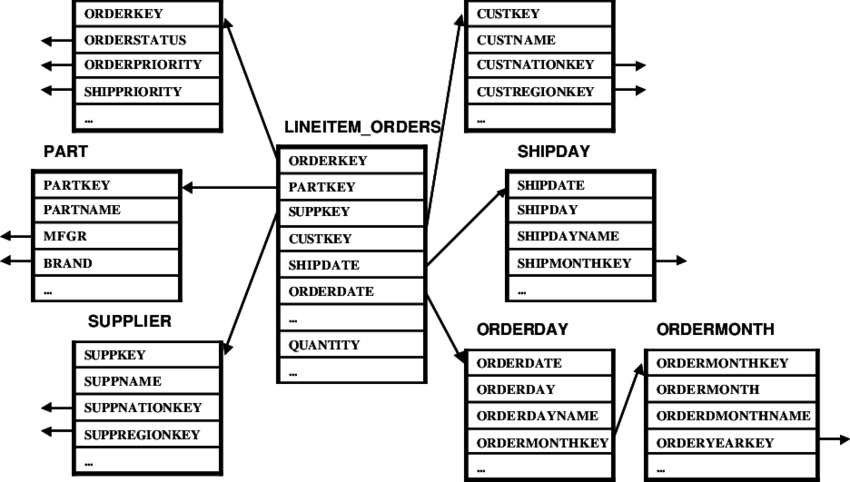
TPC-H snowflake schema
实体表不仅有大量数据行,属性也很多(100 到 200 都很常见)。可是,大部分的分析报表语句仅需要读取相关的几个属性(列)。为了运行该语句,就需要把整个实体表的数据读到内存中来抽取需要的属性列。设想一个实体表有 100 个属性,10 亿条数据,但某个语句只需要用到 3 个属性。按照 CSV 方式读取数据,97%的数据是没有用处的。贪得无厌的数据库的大牛想,有什么办法可以优化需要读取的数据吗?于是列存(column-oriented store)就这样出现了。
类似于 CSV 这样把每一个 tuple 的数据存放在一起的存储方式叫行存(row-oriented store)。相对应的列存,就是指把一个表的每个属性, 单独存在一个数据文件中。还是沿用上面 titanic 的例子,我们会有单独的数据文件(还有 slot_table 文件)来存储姓名,船票价格,登船码头,等等。在读取的时候,根据查询语句需求,需要用到哪个属性就读取哪个属性的数据文件。按照前面的例子,我们只需要读取原来的 3 个属性的数据文件,读取速度自然就提高了。
除了可以避免读取不必要的数据,列存还能带来什么优势?因为每一列的类型是相同的,比如都是整形或者是字符串。在存储同类型的数据时,压缩算法能够更有效地进行压缩,使得数据量更近一步减少,来加快读取速度。举个简单的例子,上述 titanic 的例子中有一列 Cabin 纪录了仓位信息(假设值分为 A1,A2,A3,B1,…等),相较于对于每一行都直接用字符串来存储,我们可以采用下面 enum 的压缩方式。因为仓位类型不多,所以对于每一行,只需要用 tiny 就能存下是哪个仓位了。只需要数据库系统在读取数据的时候根据 meta 把对应数据换出即可。
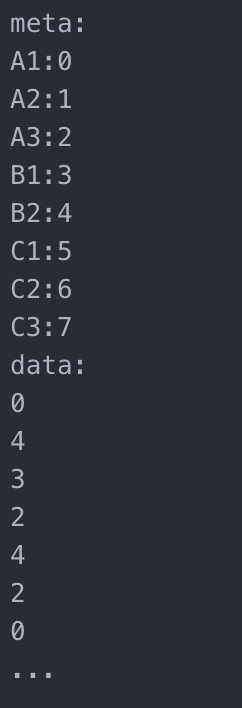
cabin.titanic_survivor.column_store
小结
至此,我们从最原始的使用 CSV 文件格式来存储数据,一步一步根据数据库的操作需要,"进化"出了下面这些优化方法:
为了更好得支持对表的元数据的管理和变更操作, 分离元数据和数据的存储
为了更高效地实现增删改数据,引入 slot_table 以及标注信息来纪录对数据的增删改,并且引入 vacuum 操作定期清理无用的行数据
为了更高效得存储数据,用 byte 来存储数据配合高效的编码和解码算法来加速读取和写入
为了应对数据仓库中复杂报表的查询语句和超大量的数据读取,引入列存概念,并且用压缩算法来进一步优化数据量
具体到真正数据库的实现,还有无数各个方面的工程优化。比如,为了提高从文件系统读取数据到内存的速度,把文件块的大小设置得和内存页一致,用内置的缓存机制来提前换进和换出数据页(相对于操作系统的默认缓存机制,数据库系统更清楚哪些数据会一起被使用从而可以提前做好准备)。但是各种优化,也并不是数据库大牛拍脑袋想出来的。而是针对问题,提出思路和解决方案,一步一步实践出来的。所以面对工作中的工程问题,我们也应该本着这种心态去处理和解决。
最后留个坑,虽然列存的实现,使得我们不用读取无用列的数据,但针对某些点查询的语句(point query),比如"select col2 from table1 where col1 = 10", 我们依然需要读取 col1 和 col2 两列的全部数据。有什么办法可以优化这类查询吗?
下一篇,我们接着聊这类优化-索引(indexing)。
作者介绍:
顾仲贤,现任 Facebook Tech Lead,专注于数据库,分布式系统,数据密集型应用后端架构与开发。拥有多年分布式数据库内核开发经验,发表数十篇数据库顶级期刊并申请获得多项专利,对搜索,即时通讯系统有深刻理解,爱设计爱架构,持续跟进互联网前沿技术。
2008 年毕业于上海交大软件学院,2012 年,获得美国加州大学戴维斯计算机硕士,博士学位;2013-2014 年任 Pivotal 数据库核心研发团队资深工程师,开发开源数据库优化器 Orca;2016 年作为初创员工加入 Datometry,任首席工程师,负责全球首家数据库虚拟化平台开发;2017 年至今就职于 Facebook 任 Tech Lead,领导重构搜索相关后端服务及数据管道, 管理即时通讯软件 WhatsApp 数据平台负责数据收集,整理,并提供后续应用。
相关阅读:
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论 10 条评论