
这是一篇由 Ankit Sirmorya 撰写的客座文章。Ankit 在亚马逊担任机器学习主管/高级机器学习工程师,并在亚马逊生态系统中领导了几个机器学习项目。Ankit 一直致力于应用机器学习来解决模棱两可的业务问题并改善客户体验。例如,他创建了一个平台,利用强化学习技术在亚马逊产品页面上进行不同假设的实验。目前,他在 Alexa 购物组织中,开发基于机器学习的解决方案,向客户发送个性化的再订购提示,以改善他们的体验。
问题说明
设计一个类似于 Netflix 的视频流媒体平台,内容创作者可以上传自己的视频内容,让观众通过各种设备回放。我们还应该能够存储视频的用户统计数据,如观看次数、视频观看时长等等。
收集需求
范围之内
该应用程序应当能够支持以下需求:
内容创造者应当能够在规定的时间将内容上传。
观众能够通过各种平台上观看视频(电视、移动 App 等)。
用户应当能够根据视频标题来搜索视频。
该系统还应支持视频的副标题。
范围之外
将个性化视频推荐给不同用户的机制。
观看视频的计费和订阅模式。
容量规划
我们需要开发一款应用,它应该能够支持 Netflix 那样规模的流量。我们还应该能够处理流行的网剧(如《纸牌屋》、《绝命毒师》等)续集推出时经常出现的流量激增。以下是与容量规划相关的一些数字。
在应用程序上注册的活跃用户数量 = 1 亿人。
每分钟上传的视频内容的平均大小 = 2500 MB。
需要支持的分辨率和编解码格式的总组合 = 10。
用户每天平均观看的视频数量 = 3。
Netflix 由多个微服务组成,其中,负责响应用户回放查询的回放服务将获得最大的流量,因此,它需要最大数量的服务器。我们可以通过下面的公式来计算处理回放请求所需的服务器数量:
S𝑒𝑟𝑣𝑒𝑟𝑠 𝑖𝑛 回放 𝑐𝑟𝑜𝑠𝑒𝑟𝑣 = (# 每秒请求的回放次数 * 延迟时间)/ 每台服务器的 # 并发连接数
我们假设回放服务的延迟(响应用户请求所需的时间)为 20 毫秒,每台服务器最多可以支持 10K 的连接。此外,我们需要在 75% 的活跃用户提出回放请求的高峰流量情况下扩展该应用。在这种情况下,我们将需要总共 150 台服务器(= 75M * 20ms/10K)。
每秒观看的视频数量=(#活跃用户 #每日观看的平均视频)/ 86400 = 3472(100M 3/86400)
每天存储的内容大小 = #每分钟上传的视频平均大小 #分辨率和编解码器的配对组合 24 60 = 36TB / 天 (= 2500MB 10 24 60)
概要设计
该系统将主要有两类用户:上传视频内容的内容创作者,以及观看视频的观众。整个系统可以分为以下几个部分:
内容分发网络(CDN):它负责将内容存储在地理上最接近用户的地方。这大大增强了用户体验,因为它减少了我们的视频比特在回放过程中必须经过的网络和地理距离。它也在很大程度上减少了对上游网络容量的整体需求。
趣事:Open Connect 是 Netflix 的全球定制 CDN,向全世界的会员提供 Netflix 的电视节目和电影。这本质上是一个由成千上万的 Open Connect Appliances(OCA)组成的网络,用于存储编码的视频/图像文件,并负责将可回放的比特传送到客户端设备。OCA 由优化过的硬件和软件组成,部署在 ISP 网站上,并进行定制,以提供最佳客户体验。
控制平面:这个组件将负责上传新的内容,这些内容最终将通过 CDNS 分发。它还将负责诸如文件存储、分片、数据存储和解释关于回放体验的相关遥测数据。这个组件中的主要微服务列举如下:
CDN 健康检查器服务:这个微服务将负责定期检查 CDN 服务的健康状况,了解整体回放体验,并努力优化它。
内容上传器服务:这个微服务将消费由内容生成器提供的内容,并在 CDN 上分发,以确保健壮性和最佳回放体验。它还将负责在数据存储器中存储视频内容的元数据。
数据存储:视频元数据(标题、描述等)被持久地保存在数据存储器中。我们还将把字幕信息持久化在最佳数据库中。
数据平面:这是终端用户在回放视频内容时与之互动的组件。这个组件从不同的媒体流媒体平台(电视、手机、平板电脑等)获取请求,并返回可以提供所请求文件的 CDN 的网址。它将由两个主要的微服务组成。
回放服务:这个微服务负责确定为回放请求服务所需的具体文件。
指导服务:这个服务确定最佳的 CDN 网址,从那里可以获取所请求的回放
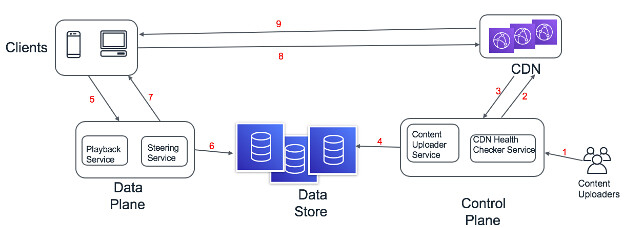
Netflix HLD
在上图中,我们展示了整个系统的鸟瞰图,它应该能够满足所有范围内的要求。下面列出了每个组件互动的细节:
内容创建者将视频内容上传到控制平面。
视频内容被上传到 CDN 上,CDN 在地理上更接近终端用户。
CDN 向控制平面报告状态,如健康指标、他们存储了哪些文件、最佳 BGP 路由等。
视频元数据和相关的 CDN 信息被持久地保存在数据存储器中。
客户端设备上的用户提出了回放特定标题(电视节目或电影)的请求。
回放服务确定回放一个特定标题所需的文件。
指导服务选择最佳的 CDN,从那里可以获取所需的文件。它生成这些 CDN 的 URL,并将其提供给客户端设备。
客户端设备请求 CDN 提供所要求的文件。
CDN 将所要求的文件提供给客户端设备,并呈现给用户。
API 设计
视频上传
路径:
POST /video-contents/v1/videos主体:
{ videoTitle : Title of the video videoDescription : Description of the video tags : Tags associated with the video category : Category of the video, e.g. Movie, TV Show, videoContent: Stream of video content to be uploaded}搜索视频
路径:
GET /video-contents/v1/search-query/查询参数:
{ user-location: location of the user performing search}流视频
路径:
GET /video-contents/v1/videos/查询参数:
{ offset: Time in seconds from the beginning of the video}数据模型
在这个问题的范围内,我们需要将视频元数据及其字幕持久化在数据库中。视频元数据可以存储在一个面向聚合的数据库中,考虑到聚合内的值可能会经常更新,我们可以使用 MongoDB 这样的基于文档的存储来存储这些信息。用于存储元数据的数据模型如下表所示。

我们可以使用一个时间序列数据库,如 OpenTSDB,它建立在 Cassandra 之上,来存储子标题。我们在下面展示了一个数据模型的片段,它可以用来存储视频副标题。在这个模型中(我们称之为媒体文档),我们提供了一个基于事件的表示,每个事件在时间线上占据一个时间间隔。

趣事:在这次演讲中,来自 Netflix 的 Rohit Puri 谈到了 Netflix 媒体数据库(Netflix Media Database,NMDB),它是基于具有空间属性的媒体时间轴的概念而建立的。NMDB 期望成为一个高度可扩展的、多租户的媒体元数据系统,它能够提供近乎实时的查询,并能够提供高读写吞吐量。媒体时间线数据模型的结构被称为“Media Document”。
组件设计
控制平面
这个组件主要由三个模块组成:内容上传器,CDN 健康检查器,以及标题索引器。这些模块中的每一个都将是执行特定任务的微服务。我们在下面的章节中已经介绍了这些模块的细节。
内容上传器
当内容创建者上传内容时,该模块被执行。它负责在 CDN 上分发内容,以提供最佳的客户体验。
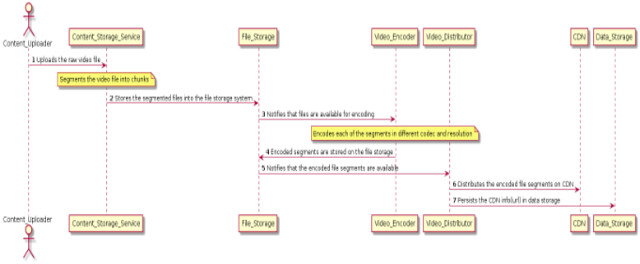
内容上传操作的序列图
上图描述了内容创作者上传视频内容(电视节目或电影)时执行的操作序列。
内容创建者上传原始视频内容,可以是电视节目或电影。
Content_Storage_Service 将原始视频文件分割成几块,并将这些片段保存在文件存储系统中。
Video_Encoder 以不同的编解码器和分辨率对每个片段进行编码。
编码后的文件段被存储在文件存储中。
Video_Distributor 从分布式文件存储系统中读取已编码的文件段。
Video_Distributor 在 CDN 中分发编码的文件段。
Video_Distributor 将视频的 CDN 网址链接持久化在 data_storage 中。
视频编码器
编码器的工作原理是将视频文件分割成更小的视频片段。这些视频片段以所有可能的编解码器和分辨率的组合进行编码。在我们的例子中,我们可以计划支持四种编解码器(Cinepak、MPEG-2、H.264、VP8)和三种不同的分辨率(240p、480p、720p)。这意味着,每个视频段共被编码为 12 种格式(4 种编解码器 * 3 种分辨率)。这些编码后的视频段分布在 CDN 上,CDN 的网址被保存在数据存储中。回放 API 负责根据用户请求的输入参数(客户的设备、带宽等)找到最理想的 CDN 网址。
趣事:Netflix 的媒体处理平台用于视频编码(FFmpeg)、标题图像生成、媒体处理(Archer)等等。他们开发了一个名为 MezzFS 的工具,在 Netflix 的内存时间序列数据库 Atlas 中收集数据吞吐量、下载效率、资源使用等方面的指标。他们利用这些数据来开发优化,如重播和自适应缓冲。
CDN 健康检查器
该模块摄取 CDN 的健康指标,并将其持久化在数据存储中。当用户请求回放时,这些数据被数据平面用来获得最佳的 CDN 网址。
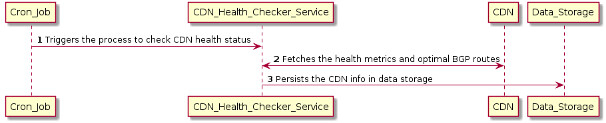
用于检查 CDN 健康指标的序列图
在上图中,我们展示了为获得 CDN 健康指标和 BGP 路由的统计数据而执行的操作顺序。下面列出了序列图中每个步骤的详细信息。
cron 作业触发了负责检查 CDN 健康状况的微服务(CDN_Health_Checker_Service)。
CDN_Health_Checker_Service 负责检查 CDN 的健康状况并收集健康指标和其他信息。
CDN_Health_Checker_Service 将 CDN 信息保存在数据存储中,然后在数据平面中使用,根据文件的可用性、健康状况和与客户端的网络接近程度,找到可以提供文件的最佳 CDN。
标题索引器
这个模块负责创建视频标题的索引,并在弹性搜索中更新它们,使终端用户能够更快地发现内容。
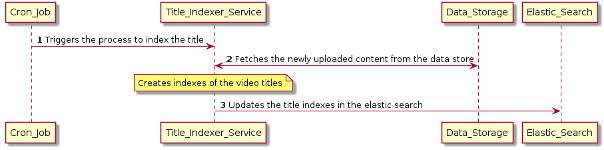
在 ElasticSearch 上存储索引标题的顺序图
下面列出了为搜索视频内容而编制视频标题索引所需的操作序列的细节。
cron-job 触发 Title_Indexer_Service 来索引视频标题。
Title_Indexer_Service 从数据存储中获取新上传的内容并应用业务规则为视频标题创建索引。
Title_Indexer_Service 用视频标题的索引更新 Elastic_Search,使标题容易被搜索到。
数据平面
这个组件将实时处理用户的请求,并由两个主要的工作流组成:回放工作流和内容发现工作流。
回放工作流
这个工作流负责在用户提出回放请求时协调操作。它在不同的微服务之间进行协调,如授权服务(用于检查用户授权和许可)、指导服务(用于决定最佳回放体验)和回放体验服务(用于跟踪事件以衡量回放体验)。指导服务通过根据用户的要求,如用户的设备、带宽等,找到最优化的 CDN 网址,确保最佳的客户体验。协调过程将由 Playback_Service 处理,如下图所示。
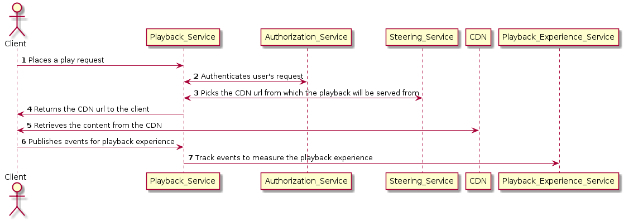
回放服务的序列图
序列图中每个步骤的细节列举如下:
客户端放置一个回放视频的请求,该请求被引导到 Playback_Service。
回放服务调用授权服务来验证用户的请求。
回放服务调用指导服务(Steering_Service)来选择可以提供回放的 CDN 网址。
CDN 网址被返回给客户端(手机/电视)。
客户端从 CDN 检索内容。
客户端将回放体验的事件发布给回放服务。
Playback_Service 通过调用 Playback_Experience_Service 来跟踪事件以衡量回放体验。
趣事:正如 Netflix 工程师 Suudhan Rangarajan 在这次演讲中提到的,gRPC 被用作 Netflix 不同微服务之间的通信框架。与 REST 相比,它的优势包括:双向流、最小的操作耦合和跨语言和平台的支持。
内容查找工作流
这个工作流程是在用户搜索视频标题时触发的,由两个微服务组成。内容发现服务和内容相似度服务。当用户要求搜索视频标题时,内容发现服务被调用。另一方面,如果确切的视频标题不存在于我们的数据存储中,内容相似性服务会返回类似的视频标题列表。
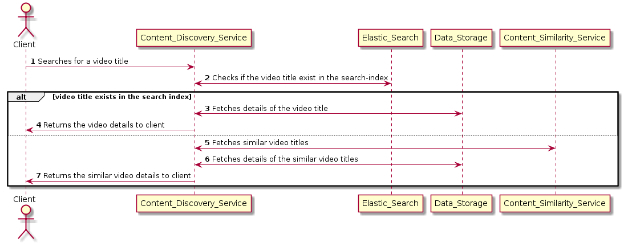
内容查询工作流程的顺序图
我们在下面列出了内容查询工作流程中涉及的每个步骤的细节:
客户端搜索一个视频标题。
内容发现服务(Content Discovery Service,CDS)查询 Elastic Search,检查视频标题是否存在于我们的数据库中。
如果视频标题可以在弹性搜索中找到,那么 CDS 从数据存储中获取视频的细节。
视频的详细信息会返回给客户端。
如果标题不存在于我们的数据库中,CDS 查询内容相似性服务(Content Similarity Service,CSS)。
CSS 将类似视频标题的列表返回给 CDS。
CDS 从数据存储中获取这些类似视频标题的视频细节。CDS 将类似的视频细节返回给客户。
优化
我们可以通过缓存 CDN 信息来优化回放工作流程的延迟。这个缓存将被引导服务用来挑选 CDN,视频内容将从那里被提供。我们可以通过使架构异步化来进一步提高回放操作的性能。让我们通过回放 api(getPlayData()) 的例子来进一步理解它,它需要客户 (getCustomerInfo()) 和设备信息 (getDeviceInfo()) 来处理 (decisionPlayData()) 一个视频回放请求。假设这三个操作(getCustomerInfo()、getDeviceInfo()、和 decidePlayData())分别依赖于不同的微服务。
getPlayData() 操作的同步实现将类似于下面的代码片段。这样的架构将包括两种类型的线程池:请求处理程序线程池和客户端线程池(针对每个微服务)。对于每个回放请求,来自请求-响应线程池的一个执行线程被阻塞,直到 getPlayData() 调用完成。每当 getPlayData() 被调用时,一个执行线程(来自请求-处理器线程池)与依赖的微服务的客户端线程池交互。它被阻断,直到执行完全结束。它适用于简单的请求/响应模型,延迟不是问题,而且客户端的数量有限。
PlayData getPlayData(String customerId, String titleId, String deviceId) { CustomerInfo custInfo = getCustomerInfo(customerId); DeviceInfo deviceInfo = getDeviceInfo(deviceId); PlayData playData = decidePlayData(custInfo, deviceInfo, titleId); return playData;}扩展回放操作的一种方法是将操作分成独立的进程,这些进程可以平行执行并重新组合在一起。这可以通过使用一个异步架构来实现,该架构由处理请求-响应和客户-互动的事件循环以及工作线程组成。我们在下面的图片中展示了回放请求的异步处理。
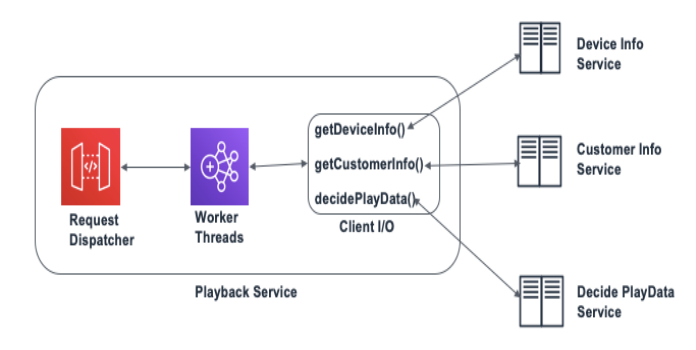
回放 API 的异步架构
我们在下面展示了调整后的代码片段,以有效地利用异步架构。对于每一个回放请求,请求处理程序事件池会触发一个工作线程来设置整个执行流程。之后,其中一个工人线程从相关的微服务中获取客户信息,另一个线程获取设备信息。一旦两个工作线程都返回了响应,一个单独的执行单元就会将这两个响应捆绑在一起,并将其用于 decisionPlayData() 调用。在这样一个过程中,所有的上下文都是以独立线程之间的消息形式传递的。异步架构不仅有助于有效利用可用的计算资源,还能减少延迟。
PlayData getPlayData(String customerId, String titleId, String deviceId) { Zip(getCustomerInfo(customerId), getDeviceInfo(deviceId), (custInfo, deviceInfo) -> decidePlayData(custInfo, deviceInfo, titleId) );}解决瓶颈问题
微服务的使用伴随着在调用其他服务时有效处理回退、重试和超时的注意事项。我们可以通过使用混沌工程(Chaos Engineering)的概念来解决使用分布式系统的瓶颈问题,有趣的是,Chaos Engineering 是在 Netflix 设计的。我们可以使用诸如 Chaos Monkey 这样的工具,在生产中随机终止实例,以确保服务对实例故障有弹性。
我们可以通过使用故障注入测试(Failure Injection Testing,FIT)的概念在系统中引入混沌。这可以通过在 I/O 调用中引入延迟或在调用其他服务时注入故障来实现。之后,我们可以通过从故障服务中返回最新的缓存数据或使用回退的微服务来实现回退策略。我们还可以使用诸如 Hystrix 这样的库来隔离故障服务之间的访问点。如果错误阈值被突破,Hystrix 会充当断路器。我们还应该确保重试超时、服务调用超时和 Hystrix 超时是同步的。
趣事:在 Nora Jones(Netflix 的混沌工程师)的演讲中,详细讨论了 Netflix 的弹性测试的重要性和不同策略。她提供了工程师在设计微服务时应牢记的关键要点,以实现弹性,并确保在持续的基础上作出最佳设计决策。
扩展需求
在流媒体视频中观察到的一个常见问题是,字幕出现在视频中的文本之上(称为文本叠加问题)。这个问题在下面的图片中得到了说明。我们怎样才能扩展当前的解决方案和数据模型来检测这个问题?

文本叠加问题的例子
我们可以扩展现有的媒体文档解决方案(用于视频字幕)来存储视频媒体信息。然后,我们可以在媒体文档数据存储上运行视频中文本检测和字幕定位算法,并将结果作为单独的索引持久化。之后,这些索引将被文本中的文字检测应用程序查询,以识别任何重叠,这将检测到文本中的文字问题。
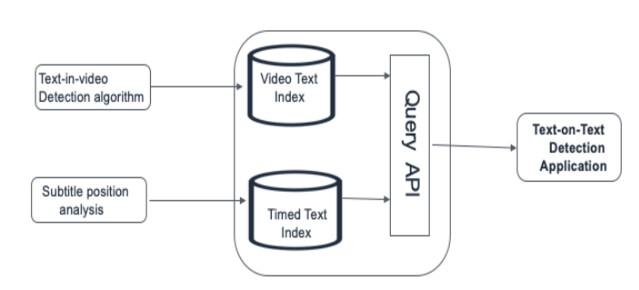
text-on-text 的检测应用流程
作者介绍:
Ankit Sirmorya,亚马逊机器学习工程经理,曾入选 40 Under 40 Data Scientists(意为 40 名 40 岁以下的数据科学家)
原文链接:
http://highscalability.com/blog/2021/12/13/designing-netflix.html




