

导读:一般的推荐系统主要包括召回、排序和后续的业务机制 ( 重排序、多样性保证、用户体验保证等等 ) 这三大模块,而其中召回模块主要负责根据用户和 item 的特征,从众多待推荐的候选 item 中初步筛选出用户可能感兴趣的 item。一般而言召回模块都是多路并发的,各路的不同召回模型之间互不影响。本文主要关注于最近几年,特别是深度学习广泛用于推荐场景之后召回模型的一个演化过程。
01 传统方法:基于协同过滤
协同过滤可分为基于用户的协同过滤、基于物品的协同过滤,基于模型的协同过滤 ( 比如 MF 矩阵分解等 )。这部分不详细讲解,网上资料很多。这里说下基于 item 的协同过滤方法吧,主要思想是:根据两个 item 被同时点击的频率来计算这两个 item 之间的相似度,然后推荐用户历史行为中各个 item 的相似相关 item。虽然基于用户的协同过滤召回方法具有简单、性能较高,因此在实际的推荐场景中用途十分广泛。不过也是有天然的缺陷:召回结果的候选集 item 限定在用户的历史行为类目中,并且难以结合候选 item 的 Side Information ( 比如 brand,品类一些 id 信息 ),导致其推荐结果存在发现性弱、对长尾商品的效果差等问题,容易导致推荐系统出现 “越推越窄” 的问题,制约了推荐系统的可持续发展。
02 单 Embedding 向量召回
这部分工作主要介绍单 embedding 向量召回 ( 每个 user 和 item 在一个时刻只用一个 embedding 向量去表示 ) 的一些经典方法,其主要思想为:将 user 和 item 通过 DNN 映射到同一个低维度向量空间中,然后通过高效的检索方法去做召回。
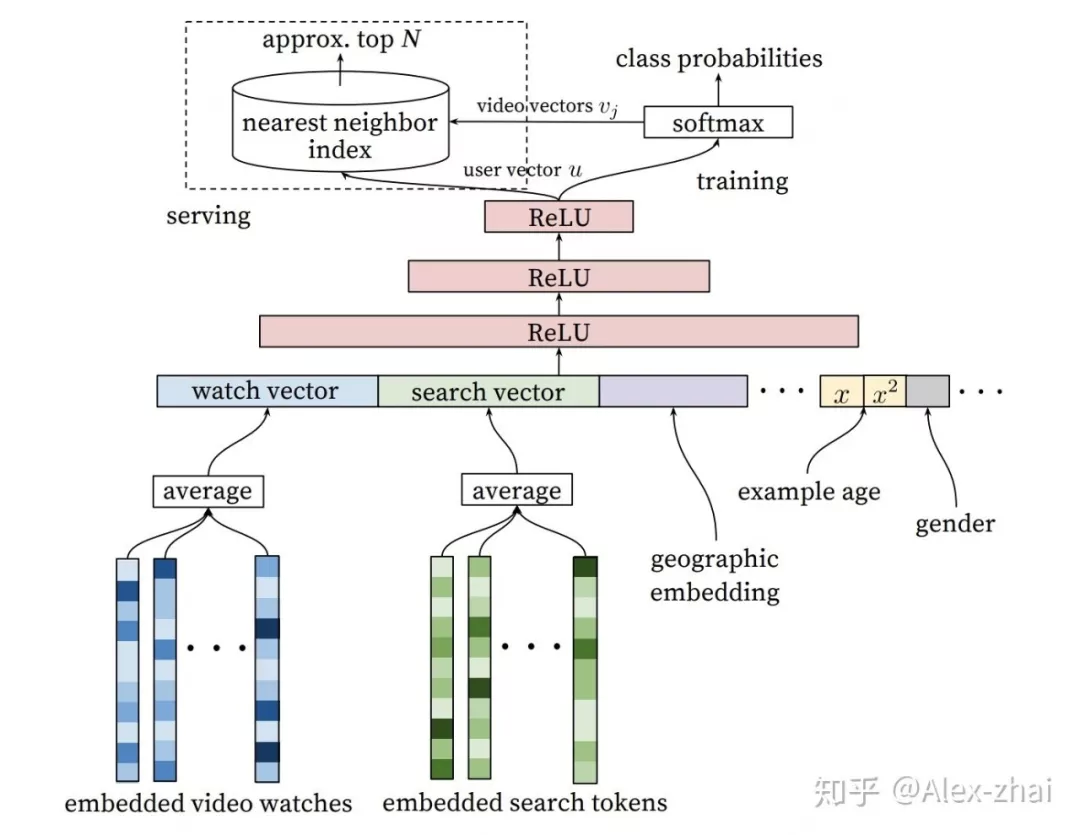
❶ Youtube DNN 召回
使用特征:用户观看过视频的 embedding 向量、用户搜索词的 embedding 向量、用户画像特征、context 上下文特征等。
训练方式:三层 ReLU 神经网络之后接 softmax 层,去预测用户下一个感兴趣的视频,输出是在所有候选视频集合上的概率分布。训练完成之后,最后一层 Relu 的输出作为 user embedding,softmax 的权重可当做当前预测 item 的 embedding 表示。
线上预测:通过 userId 找到相应的 user embedding,然后使用 KNN 方法 ( 比如 faiss ) 找到相似度最高的 top-N 条候选结果返回。
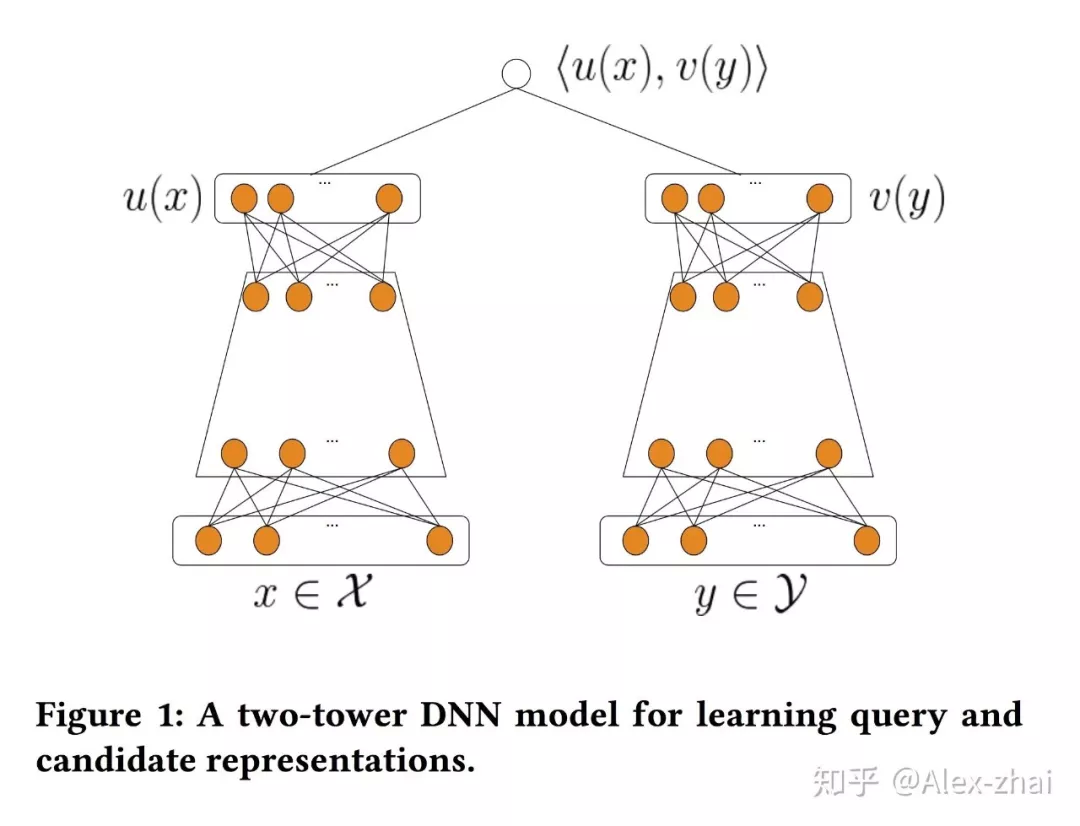
❷ 双塔模型召回
双塔模型基本是:两侧分别对 user 和 item 特征通过 DNN 输出向量,并在最后一层计算二个输出向量的内积。
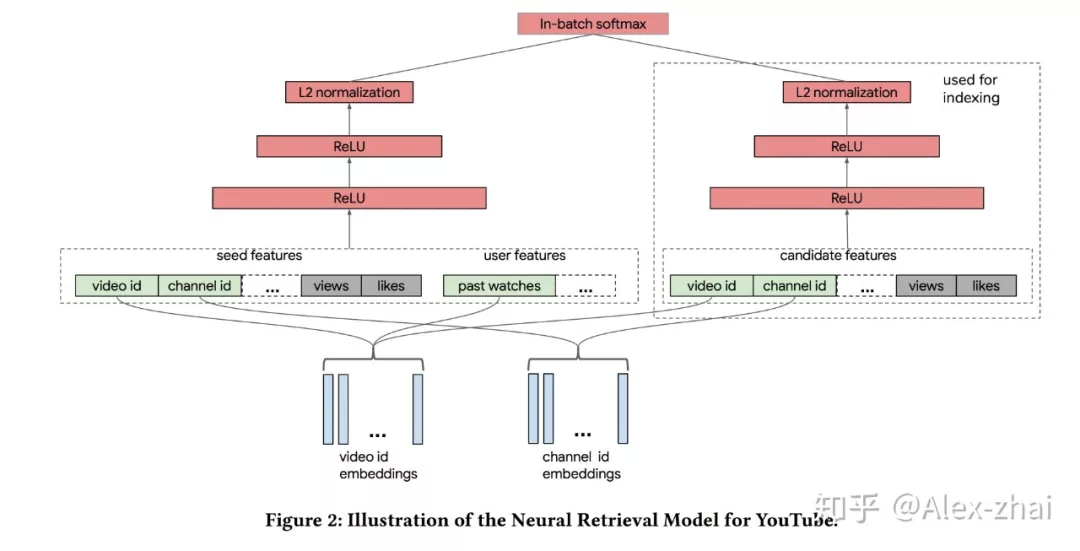
例如 YouTube 今年刚发的一篇文章就应用了经典的双塔结构:
03 多 Embedding 向量召回-用户多兴趣表达
Multi-Interest Network with Dynamic Routing 模型
背景:电商场景下用户行为序列中的兴趣分布是多样的,如下图用户 A 和 B 的点击序列商品类别分布较广,因此如果只用一个 embedding 向量来表示用户的兴趣其表征能力是远远不够的。所以需要通过一种模型来建模出用户多个 embedding 的表示。

MIND 模型通过引入 capsule network 的思想来解决输出多个向量 embedding 的问题,具体结构如下图:
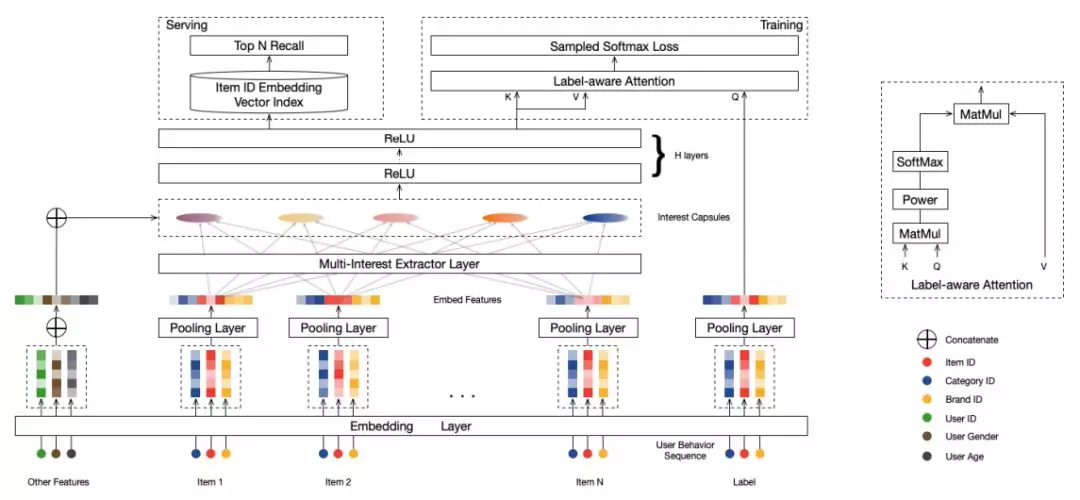
训练:Multi-Interest 抽取层负责建模用户多个兴趣向量 embedding,然后通过 Label-aware Attention 结构对多个兴趣向量加权。这是因为多个兴趣 embedding 和待推荐的 item 的相关性肯定不同 ( 这里的思想和 DIN 模型如出一辙 )。其中上图中的 K,V 都表示用户多兴趣向量,Q 表示待推荐 item 的 embedding 表示,最终用户的 embedding 表示为:
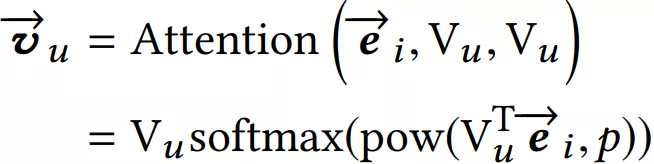
公式中的 ei 表示 item embedding,Vu 表示 Multi-Interest 抽取层输出的用户多个兴趣向量 embedding。
然后使用 Vu 和待推荐 item embedding,计算用户 u 和商品 i 交互的概率,计算方法和 YouTube DNN 一样:
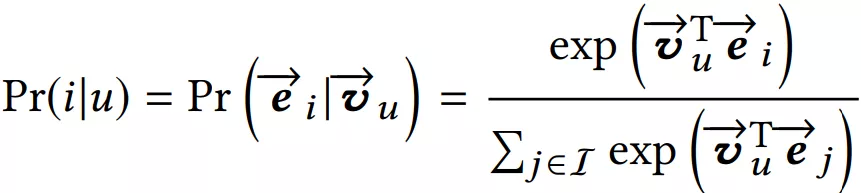
线上 serving:在线计算用户的多个兴趣向量后,每个兴趣向量 embedding 通过 KNN 检索得到最相似的 Top-N 候选商品集合。这里有个问题大家思考下?得到多个兴趣向量后通过权重将这些向量的 embedding 累加起来成为一个 ( 表示为多个向量的加权和 ),然后只去线上检索这一个 embedding 的 Top-N 相似,大家觉得这样操作可以吗?不可以的原因又是什么呢?
04 Graph Embedding
❶ 阿里 Graph Embedding with Side information
传统的 graph embedding 过程如下图:
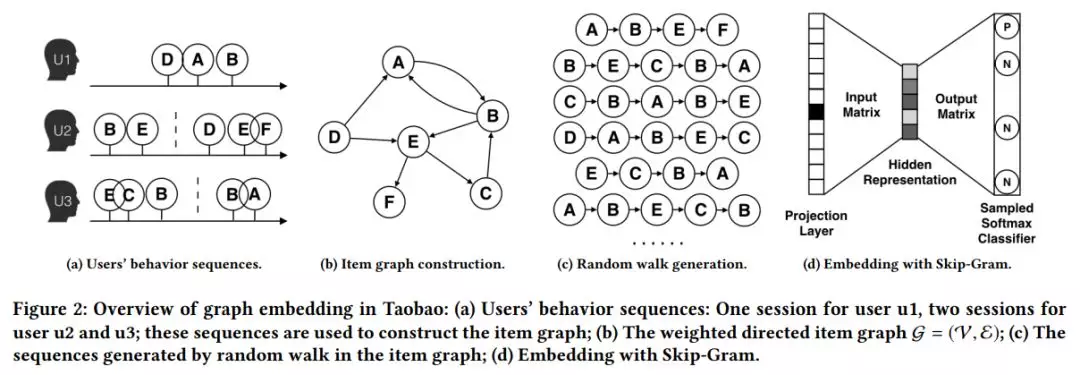
其实就是通过 “构图 -> 随机游走得到序列 -> word2vec 训练” 三部曲得到每个 item 的 embedding 表示。但是这样训练出来的模型会存在冷启动问题。就是那些出现次数很少或者从来没在序列中出现过的 item embedding 无法精确的表征。本文通过添加 side information ( 比如商品的种类、品牌、店铺 id 等 ) 等辅助类信息来缓解该问题,如下图 SI 1 - SI n 表示 n-1 个辅助 id 特征的 embedding 表示。
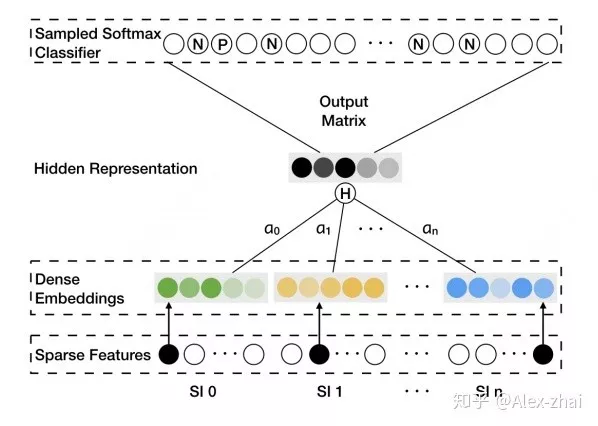
该模型的亮点是考虑了不同的 side information 在最终的 aggregated embeddings 中所占的权重是不同的,最后 aggregated embeddings 计算公式如下,其中分母用来归一化。
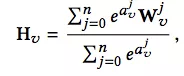
❷ GraphSAGE:Inductive representation learning on large graphs
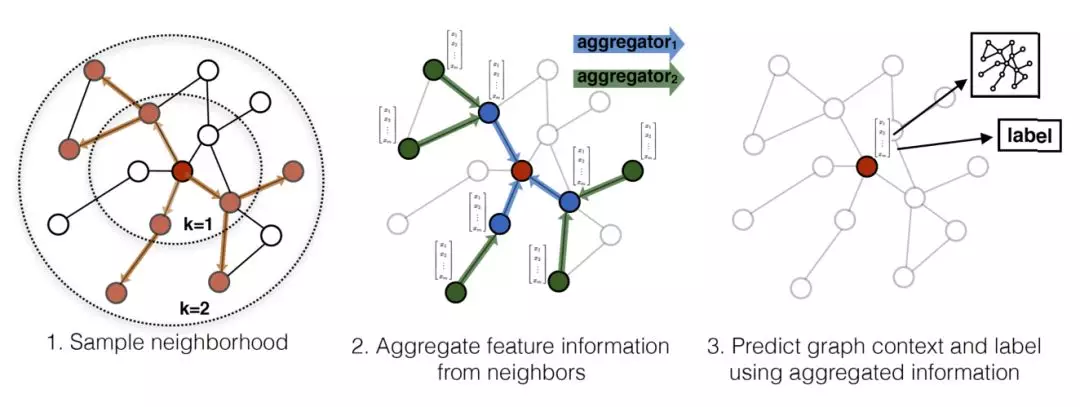
经典的图卷积神经网络 GCN 有一个缺点:需要把所有节点都参与训练才能得到 node 的 embedding,无法快速得到新 node 的 embedding。这是因为添加一个新的 node,意味着许多与之相关的节点的表示都应该调整。所以新的 graph 图会发生很大的变化,要想得到新的 node 的表示,需要对新的 graph 重新训练。
GraphSAGE 的基本思想:学习一个 node 节点的信息是怎么通过其邻居节点的特征聚合而来的。算法如下:

大致流程是:对于一个 node 需要聚合 K 次,每次都通过聚合函数 aggregator 将上一层中与当前 node 有邻接关系的多个 nodes 聚合一次,如此反复聚合 K 次,得到该 node 最后的特征。最下面一层的 node 特征就是输入的 node features。
05 结合用户长期和短期兴趣建模
❶ SDM: Sequential Deep Matching Model for Online Large-scale Recommender System
背景:在电商场景中,用户都会有短期兴趣和长期兴趣,比如在当前的浏览 session 内的一个点击序列,用户的需求往往是明确的,这属于用户短期的兴趣。另外用户还有一些长期的兴趣表达,比如品牌、店铺的偏好。因此通过模型分别建模用户的长、短期兴趣是有意义的。
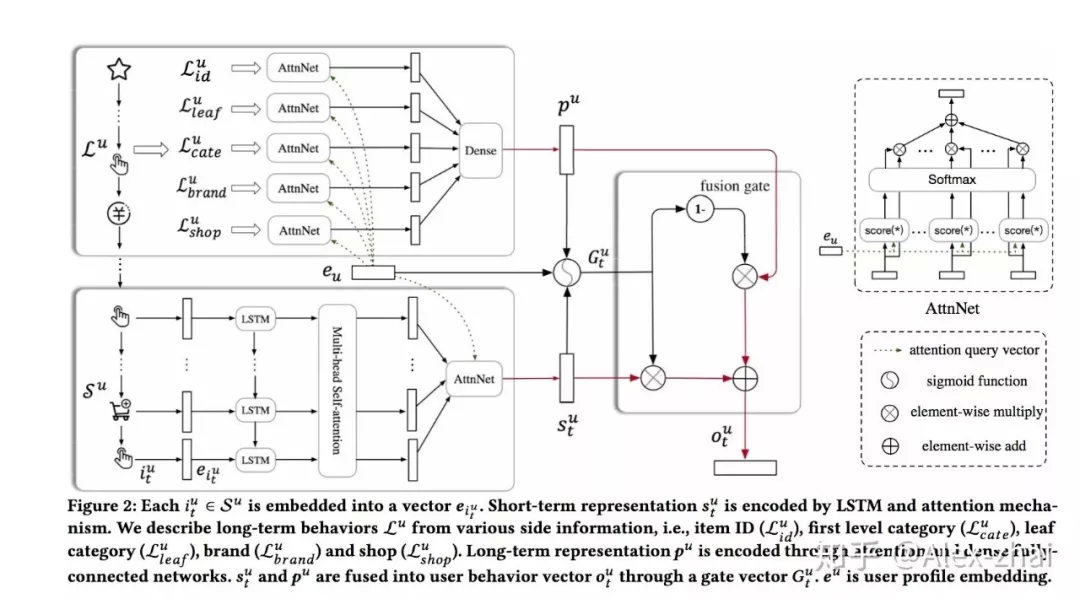
上图中 表示用户短期兴趣向量, 表示用户的长期兴趣向量,这里需要注意的是,在求长期和短期用户兴趣向量时都使用了 Attention 机制,Attention 的 Query 向量 表示 user 的 embedding,用的是基本的用户画像,如年龄区间、性别、职业等。得到长期和短期用户向量后,通过 gru 中的 gate 机制去融合两者:
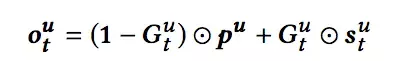
上面的公式输出表示用户的 embedding 表示,而 item 的 embedding 表示和 YouTube DNN 一样,可以拿 softmax 层的权重。其实也可用 graph embedding 先离线训练好 item 的 embedding 表示。
线上预测:通过 user id 找到相应的 user embedding,然后使用 KNN 方法 ( 比如 faiss ) 找到相似度最高的 top-N 条候选结果返回。
❷ Next Item Recommendation with Self-Attention
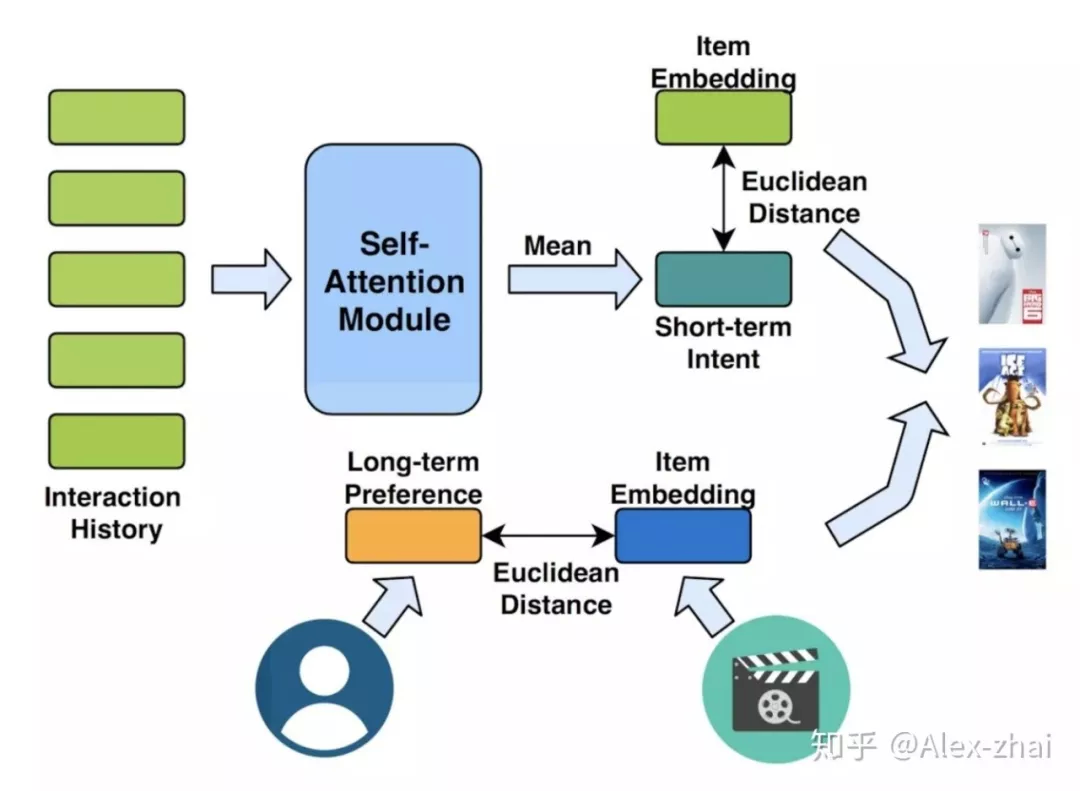
本文亮点是同时建模用户短期兴趣 ( 由 self-attention 结构提取 ) 和用户长期兴趣。其短期兴趣建模过程:使用用户最近的 L 条行为记录来计算短期兴趣。可使用 X 表示整个物品集合的 embedding,那么,用户 u 在 t 时刻的前 L 条交互记录所对应的 embedding 表示如下:
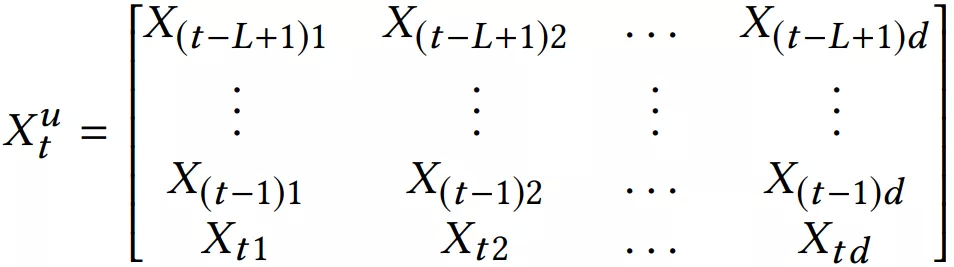
其中每个 item 的 embedding 维度为 d,将 作为 transformer 中一个 block 的输入:
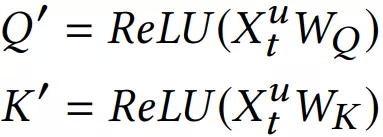
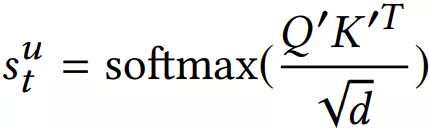
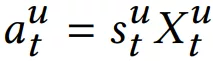
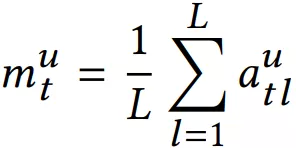
这里需要注意和传统 transformer 的不同点:
计算 softmax 前先掩掉 矩阵的对角线值,因为对角线其实是 item 与本身的一个内积值,容易给该位置分配过大的权重。
没有将输入 乘以 得到 ,而是直接将输入 乘以 softmax 算出来的 score。
直接将 embedding 在序列维度求平均,作为用户短期兴趣向量。
Self-attention 模块只使用用户最近的 L 个交互商品作为用户短期的兴趣。那么怎么建模用户的长期兴趣呢?可认为用户和物品同属于一个兴趣空间,用户的长期兴趣可表示成空间中的一个向量,而某物品也可表示为成该兴趣空间中的一个向量。那如果一个用户对一个物品的评分比较高,说明这两个兴趣是相近的,那么它们对应的向量在兴趣空间中距离就应该较近。这个距离可用平方距离表示:
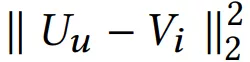
其中 U 是用户的兴趣向量,V 是物品的兴趣向量
综合短期兴趣和长期兴趣,可得到用户对于某个物品的推荐分,推荐分越低,代表用户和物品越相近,用户越可能与该物品进行交互。
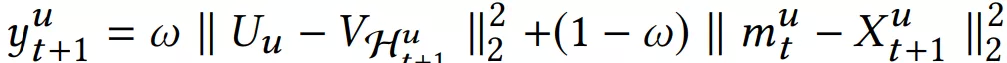
06 TDM 深度树匹配召回
TDM 是为大规模推荐系统设计的、能够承载任意先进模型 ( 也就是可以通过任何深度学习推荐模型来训练树 ) 来高效检索用户兴趣的推荐算法解决方案。TDM 基于树结构,提出了一套对用户兴趣度量进行层次化建模与检索的方法论,使得系统能直接利高级深度学习模型在全库范围内检索用户兴趣。其基本原理是使用树结构对全库 item 进行索引,然后训练深度模型以支持树上的逐层检索,从而将大规模推荐中全库检索的复杂度由 O(n) ( n 为所有 item 的量级 ) 下降至 O(log n)。
❶ 树结构
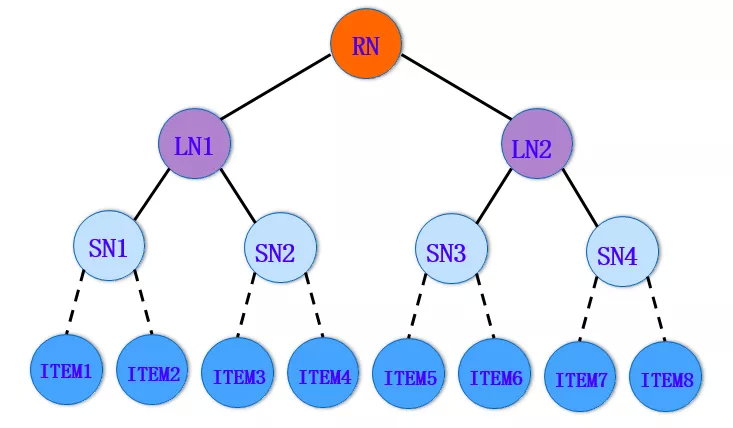
如上图所示,树中的每一个叶节点对应一个 item;非叶节点表示 item 的集合。这样的一种层次化结构,体现了粒度从粗到细的 item 架构。此时,推荐任务转换成了如何从树中检索一系列叶节点,作为用户最感兴趣的 item 返回。
❷ 怎么基于树来实现高效的检索?
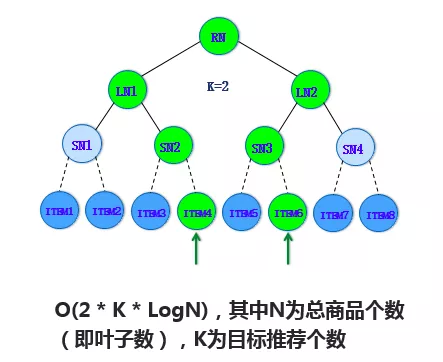
采用 beam-search 的方法,根据用户对每层节点的兴趣挑选 topK,将每层 topK 节点的子节点作为下一层挑选的候选集合逐层展开,直到最终的叶子层。比如上图中,第一层挑选的 Top2 是 LN1 和 LN2,展开的子节点是 SN1 到 SN4,在这个侯选集里挑选 SN2 和 SN3 是它的 Top2,沿着 SN2 和 SN3 它的整个子节点集合是 ITEM3 到 ITEM6,在这样一个子结合里去挑 Top2,最后把 ITEM4 和 ITEM6 挑出来。
那么为什么可以这样操作去 top 呢?因为这棵树已经被兴趣建模啦 ( 直白意思就是每个节点的值都通过 CTR 预估模型进行训练过了,比如节点的值就是被预测会点击的概率值 ),那么问题来了,怎么去做兴趣建模呢 ( 基于用户和 item 的特征进行 CTR 预估训练 )?
❸ 兴趣建模
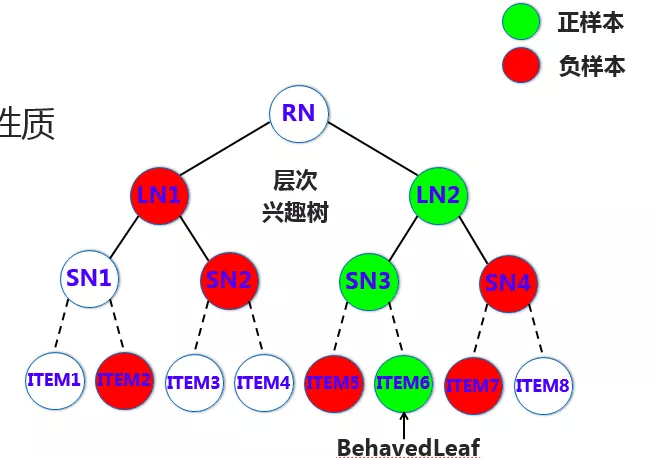
如上图,假设用户对叶子层 ITEM6 节点是感兴趣的,那么可认为它的兴趣是 1,同层其他的节点兴趣为 0,从而也就可以认为 ITEM6 的这个节点上述的路径的父节点兴趣都为 1,那么这一层就是 SN3 的兴趣为 1,其他的为 0,这层就是 LN2 的兴趣为 1,其他为 0。也就是需要从叶子层确定正样本节点,然后沿着正样本上溯确定每一层的正样本,其他的同层采样一些负样本,构建用于每一层偏序学习模型的样本。
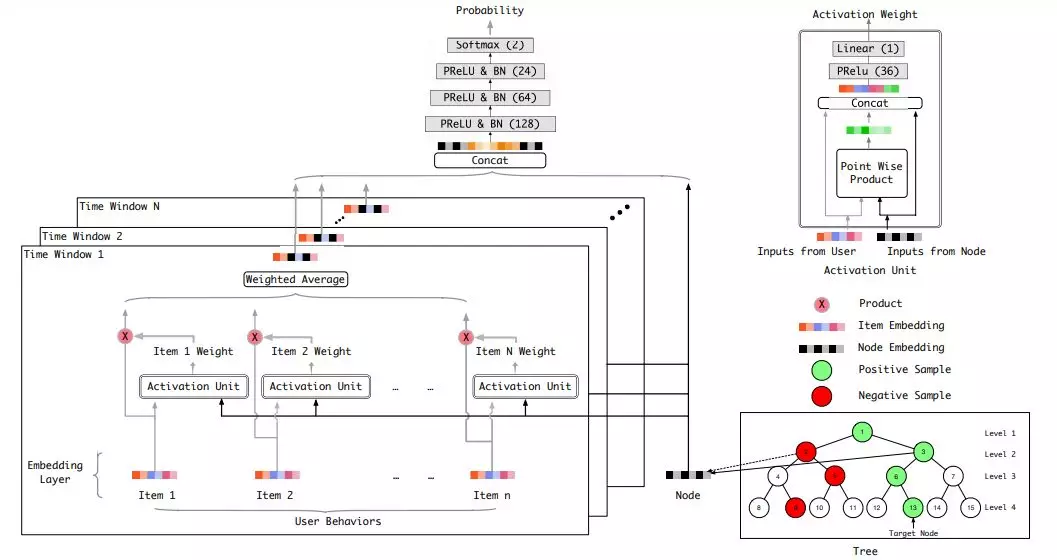
构造完训练样本后,可以利用 DIN ( 这里可以是任何先进的模型 ) 承担用户兴趣判别器的角色,输入就是每层构造的正负样本,输出的是 ( 用户,节点 ) 对的兴趣度,将被用于检索过程作为寻找每层 Top K 的评判指标。如下图:在用户特征方面仅使用用户历史行为,并对历史行为根据其发生时间,进行了时间窗口划分。在节点特征方面,使用的是节点经过 embedding 后的向量作为输入。此外,模型借助 attention 结构,将用户行为中和本次判别相关的那部分筛选出来,以实现更精准的判别。
❹ 兴趣树是怎么构建的?网络与树结构的联合训练
优化模型和优化样本标签交替进行。具体过程:最开始先生成一个初始的树,根据这个初始的树去训练模型,有了模型之后,再对数据进行判别,找出哪些样本标签打错了,进行标签的调整,相当于做树结构的调整。完成一轮新的树的结构的调整之后,我们再来做新的模型学习,实现整个交替的优化。
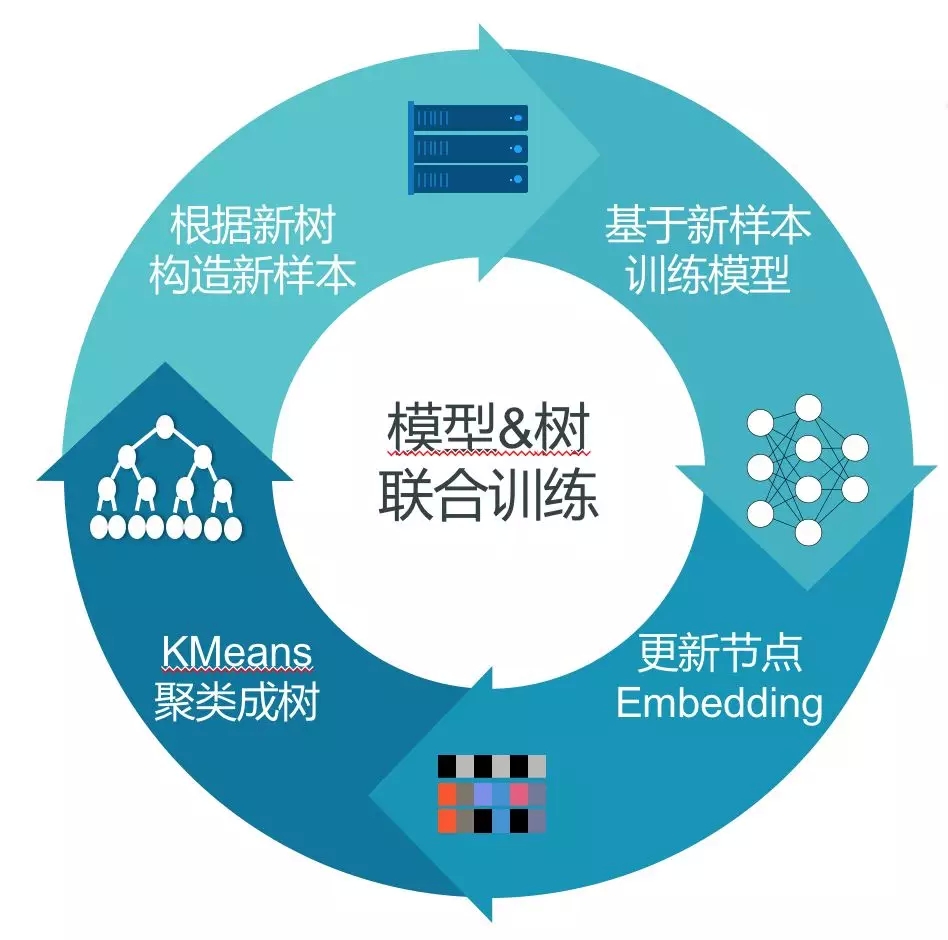
模型训练、优化样本标签过程迭代进行,最终得到稳定的结构与模型。
❺ 总结
目前 TDM 模型更多承担的还是召回的工作:
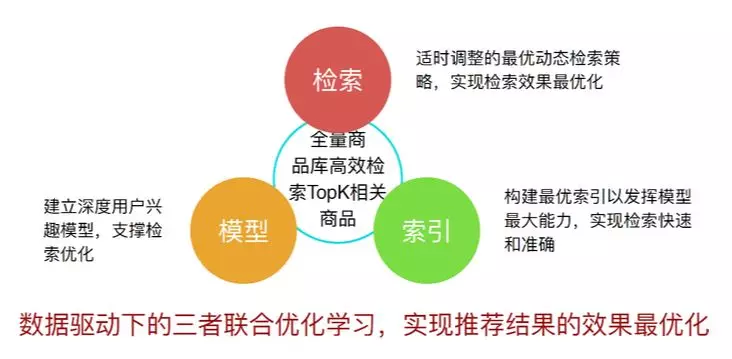
TDM 初步实现了在数据驱动下的模型、检索和索引三者的联合学习。其中索引决定了整个数据的组织结构,它承载的是模型能力和检索策略,以实现检索的快速和准确。检索实际上是面向目标,它需要和索引结构相适配。模型支撑的则是整个检索效果的优化。
参考链接:
[1]https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
[2]https://dl.acm.org/citation.cfm?id=3346996
[3]https://arxiv.org/pdf/1904.08030.pdf
[4]https://arxiv.org/pdf/1803.02349.pdf
[5]https://arxiv.org/pdf/1706.02216.pdf
[6]https://zhuanlan.zhihu.com/p/74242097
[7]https://arxiv.org/abs/1909.00385v1
[8]https://www.jianshu.com/p/9eb209343c56
[9]https://zhuanlan.zhihu.com/p/78941783
原文链接:
https://zhuanlan.zhihu.com/p/97821040
作者介绍:
Alex-zhai 京东算法工程师。从事深度强化学习、深度学习、图像处理、深度学习推荐算法、分布式训练架构等方向。
本文来自 DataFunTalk
原文链接:
https://mp.weixin.qq.com/s/Y4g2T6qMGzCcE67bINPiGA
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论