

本文整理自百度李俊卿在 QCon 上的演讲:《流式数据处理在百度数据工厂的应用与实践》。
百度数据工厂最原先用 Hive 引擎,进行离线批量数据分析和 PB 级别的查询,处理一些核心报表数据。但是在我们推广过程中发现,用户其实还是有复杂分析、实时处理、数据挖掘的请求,我们在 Spark1.0 推出的时候,就开始跟进 Spark。在 Spark1.6 时候彻底在团队中推广起来,当时是 Spark Streaming。当时 Spark1.6 的 API 基于 RDD,它和 Spark 批式处理的 API 并不同步。后来在 Spark2.2、2.3 发布的时候,Spark 推出了 Struct Streaming,它的 API 和批处理 API 已经完全一致,这时候我们迎来一次完整的架构升级,基于 Spark 做了一次更强大的封装;以 Spark 为基础,加上其他的 CRM,PFS 等各种模块来做统一元数据处理;统一的资源调度;以 Spark 为基础做了统一的一个计算引擎,以前 Hive 的一套也有完全融入到 Spark 里来;包括多种提交方式;安全管理等等。最后形成一套完整的成品。
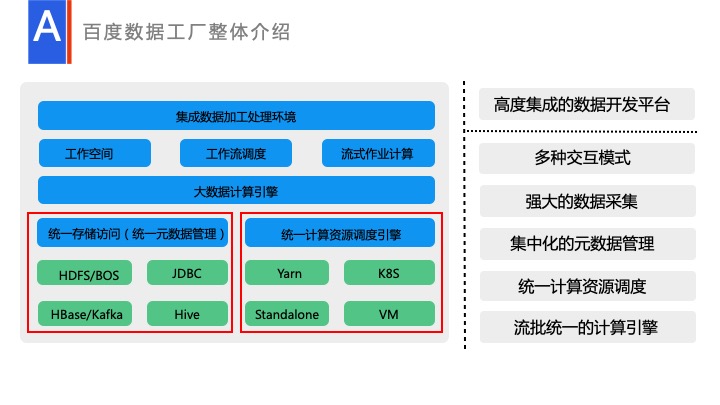
这就是我们目前的一个整体的技术架构。左下角是统一元数据处理,包括文件类的元数据处理和结构类数据,比如说 Hive,或者 MySQL 的元数据处理,这都是作为统一的处理层的。还有就是统一调度引擎处理,我们会有统一的调度引擎,由用户注册队列,执行的时候只需要显示队列,去执行具体的资源。目前也支持 K8S 等。再往上一层是统一的 Spark 引擎。Spark 引擎里面我们现在目前支持了 SQL、Dataset API,可在上面跑各种复杂的处理。
再往上一层就是由 Jupyter 提供的工作空间,还有由我们自研提供的调度,自研的一套流式计算作业处理,整个一套就构成了现在完整的数据工厂。
流式数据处理在百度数据工厂的应用
接下来是比较最核心的部分,百度在 Spark 流批处理上做的哪些内容,主要是 Spark 流式 SQL 问题、实时转离线问题、实时转大屏展示问题。
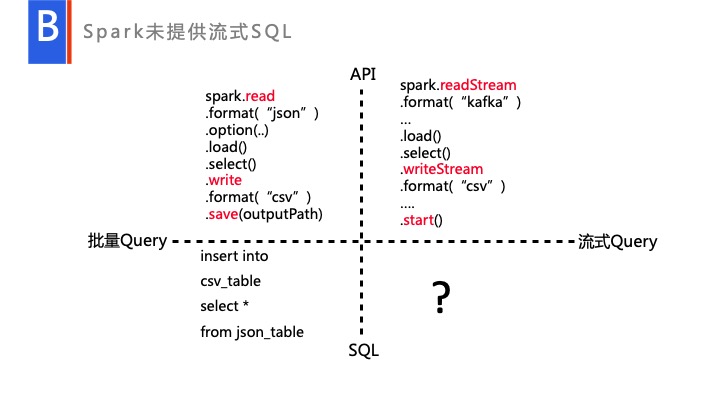
首先 Spark 本身有一套完整的 API 的,有专门的引擎用来分析,所有的流、Batch 分析,信息都会经过这套 API 进行一系列的处理,包括语义分析、语法分析、一些优化等。大家可以注意到,右下角是空缺的,Spark 目前是没有提供这部分内容的。而用户转型过程中很多用户都是由 Hive 过来的,是熟悉应用 SQL 的用户,他们要处理流式数据,就会迫切的需要有一个 SQL 的引擎,来帮他将 Hive 的 SQL 转型成一个流式的 SQL。
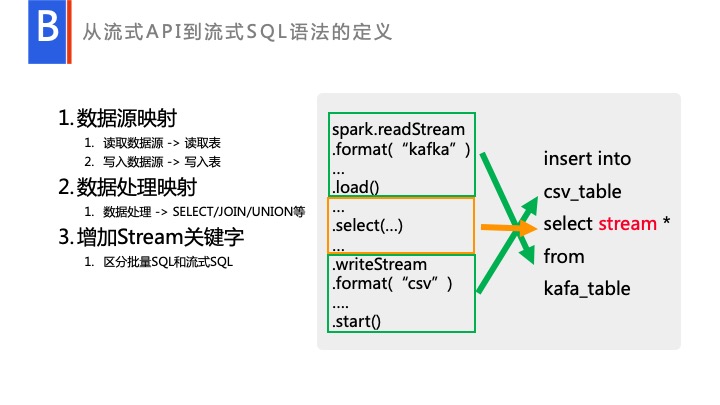
我们针对这个问题进行了一些开发。首先大家看一下,上面是 Spark API 层,Spark 在流批处理上的 API 已经做得很完善了,是通过 read 和 readStream 来进行区分的。批到 SQL 处理,其实就是,可以完全看到它是首先是 Spark read 一个 Source,而它会映射成一个 From Table,具体的处理会映射成 select、join、union 等各种操作。然后 Write Table 这种,在最后映射成了 kafka_Table。我们流式 SQL 也可以映射这种类型的。
比如说这个例子,它从 Kafka 读取,输出到 HDFS,映射的流式 SQL 的就是 Kafka_Table。我们可以专门定义一个 Kafka Table。用户的处理,我们会变成 select *。大家注意,我中间加了一个 stream 关键字。Spark 在处理的时候,做了统一引擎的处理。只有 API 层用户写 readStream 的时候,它才是一个流式的处理,如果它用户写一个 Read,它就是一个批处理。相对来说,SQL 层我们也做了相应的处理,跑的同样的 SQL,用户如果没加 Stream 关键字,它就是批处理的一个 SQL,如果加 Stream 关键字,它就变成一个流式处理。但里面处理的引擎是完全一致的,只不过最后转换 Plan 的时候,将最后原 Plan 的部分转换成了流的 plan。
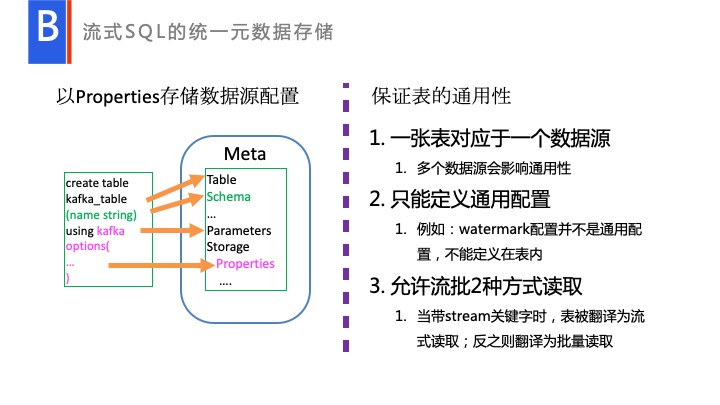
这里也涉及了 Table 是怎么存储的。Table 存储,如图所示,一个批量的 Table 存储的时候,无非就是 Table name、Schema、Properties,还有一些定义,比如说 location 等一些配置的信息。同样可以把我们创建的 Kafka Table 也可以映射进去,比如说我创建的 Table 名称可以映射 Table Name 等,和 Meta 这边进行一一对应,这样我们在 Hive 那一侧,已经有了完善的一套 Table 的存储信息。它会生成一个虚拟的路径,其实并不会真正去创建,并不会真正去对它执行的。在数据工厂中,我们是这样定义一个 Table 的。一个 Table 定义出来以后为要能被多个人使用,但临时 Table 除外,你能够授权给其他人去读,也能够去进行列裁减,能够对它进行一些如数脱敏的数据分析,这时候就需要考虑 Table 的通用性。
首先第一点,我们创建的 Table 不能存放多个数据源。比如说存放三个数据源,这时完全可以定义三个 Table,不同的数据源做 Join,做 Unit 分析等,这在 Spark 里面都是 OK 的。
第二点只能定义通用配置。给别人使用,授权,计算的时候,肯定会需要考虑他自己的应用场景,这里面不能去搀杂何与应用场景相关信息,比如说 watermark 配置,这就是属于与应用场景相关的信息,这部分信息都是不能存放于 Table 里面的。
另外就是 Spark 原生是支持 Kafka,流式的 Table。它要既能够去流式的去读,也能够批量的去读,既然定义了 Table 我们怎么去读呢?这就是我们在 Spark 里面的改进,主要改动的部分就是改动了语义分析层的一个逻辑。大家可以看一下右侧整个逻辑框架。
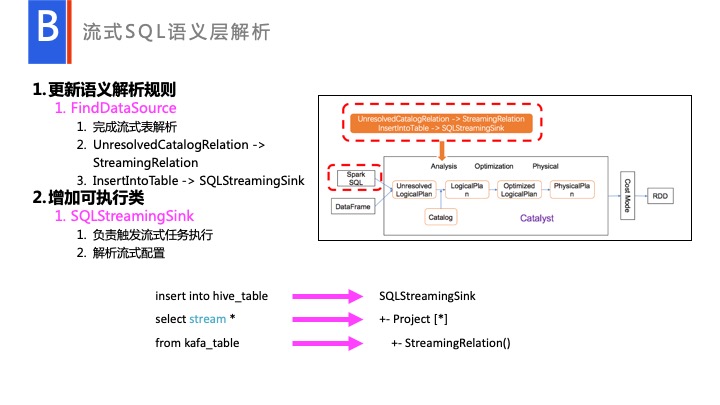
我们主要改动就改动在语义层分析上。在这个规则上增加一个语义分析 FindDataSouce,完成流式表解析,和增加了一个专门的可执行类 SQLStreamingSink,用来专门读取。比如说读取 Watermark 或各种的配置,最终产生一个流式的 Plan 去执行。最后经过语义层分析之后,就变成了一个 SQLStreamingSink。到这一步,一旦执行起来,它和正常 API 调度是一样的,这样 API 和 SQL 在语义层之后已经达到完整一致了。整体只在语义层这个地方做了一些区别而已。

总结来说,首先我们提供了一个统一的 Hive 元数据存储,我们所有的 Table 都是基于 Hive 的,当然 Hive 只是一种方案,主要是用数据仓库的形式来对数据进行统一管理。我们升级了 FindDataSource,用来处理 Table 到 Source 一个定义。比如说用户的 groupby,filter,sum 等操作都会通过语义解析的时候,会对它进行分析。现在这套方案,我们已经提供给社区。如果大家有兴趣的可以一块看看有什么更好的方案解决 Streaming Join Bach 的处理,在 Spark 的 Patch 中搜 SQLStreaming 可以看到目前正在讨论的链接,欢迎一起讨论相关方案。
实时转离线问题
很多人会说实时转离线用的场景多吗?其实在百度内的场景用的不少的,因为比如说用户的点击日志数据,大部分都是实时存放在日志中的,他会进行流式处理时候会全部打到 Kafka 消息队列里面,它还是有些需求,对数据进行一些比如说天级别,月级别,甚至年级别的数据分析。这时候应该怎么办呢?于是我们就提供了实时转离线的功能,其实 Spark 本身已经提供了一个实时转离线的,就是右侧的这个代码。

比如说定义了一个 CSV,定义一下它的分区路径,定义 partition、location 等,去执行写的操作时是有问题的。首先它输出信息完全是由人为去记在如一个卡片里,记在一个统一的文档里,下游去用的时候,问上游询要。一旦上游改变了,里面信息肯定就完全不对称了。
另外一个就是迁移升级问题。在百度内部存在集群迁移的问题,一个机房一般用几年之后,都会下线,这时候就会存在机型迁移。在输出路径上,或者在输出格式上,需要做出改变。而现在,一般来说,就是很多数据开发的人员,更期望的是开发的代码,能长时间运行。如果我用当前的实时转离线方案的话,肯定需要拿到原生的代码进行修改,再搭架构,再执行,这也是现实场景中用户吐槽最多的。
另外就是一个拓展文件格式,比如说甲方要求输出 sequenceFile,并指定了格式。但下游需要的 sequenceFile 格式是不同,怎么去拓展?这样开发代价很大,很多用户是比较抵制的,我们提供的方案是什么呢?就是实时转数仓的方案。

大家知道 Hive 保存了很多信息,里面这些元数据信息,比如说有统一的管理员进行管理之后,这些信息都可以很明晰,很明了的被其他人看到。但输出升级或迁移了,这时候修改 location 就可以了,代码比较好改。具体代码是什么样呢?就是右下角的这行代码。
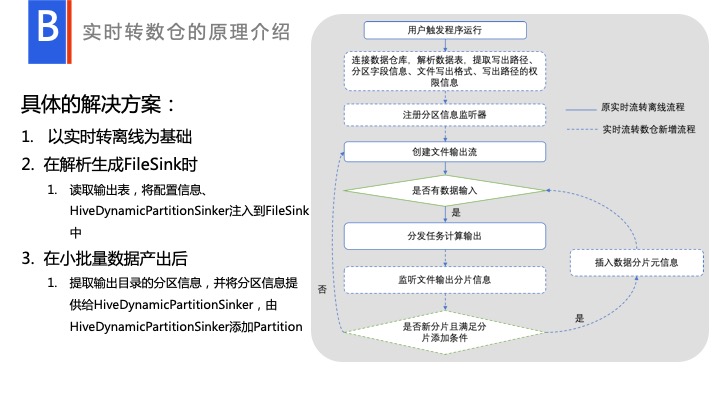
这个方案具体实现是这样的,原生有一个 FileSink,读取 CSV 的数据,然后对数据进行处理之后,进行流式输出。只不过我们改动变成了 Hive 的 File Format,以批量的形式进行写入,然后输出出去。我们在创建 FileSink 的时候,我们会读一下用户填入的 Table,拿到它的信息,注入进去,进行一个写操作。大家可以注意到有一个分析监听器 HiveDynamicPartitionSinker,在运行完每一个批量,都有一个信息反馈,如到底输出了哪些 partition,能拿到相应的分区信息。拿到这个分区信息之后,可以对它进行一些处理,最后注入到 Hive 中,这样的话到底生产了哪些 partition,完全可以在 Hive 里面可以去查到的。
基本上这就是这完整的一套实时转数仓方案。我们基于这一套方案,在百度内部已经推广到了很多业务上。在百度内部还有很多细粒度的权限处理使用实时转数仓方案。一旦写入数仓,下游在订阅的时候会有一些数据脱敏,或者是读写权限控制,或者列权限控制,都能用这套方案进行控制,所以实时转数仓方案在百度内部还是比较受欢迎的。
实时转大屏展示
我们在推广过程中,用户是也些大屏展示的使用场景的。
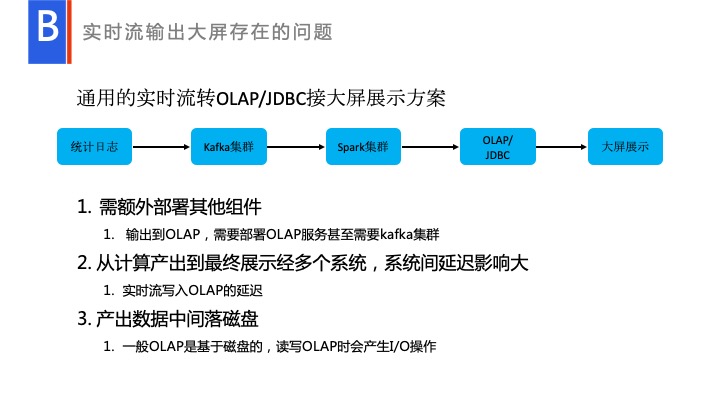
这页显示的这是一个通用的用户使用场景,比如说将 Streaming 实时的数据输出到一个 OLAP 里面,最终展示给大屏。但是这个场景有什么问题呢?这里需要额外使用其他的系统,比如 Kafka 系统、OLAP 系统,最后再接入到大屏展示里面。每个系统,都需要找不同的负责人去处理,中间一旦出问题,需要反复去找负责人,与他们相互协调。中间会很复杂,一旦有一个网络出现故障,数据就会延时,负责人都需要处理自己的业务瓶颈。处理瓶颈是在用户使用场景中比较难办的问题。
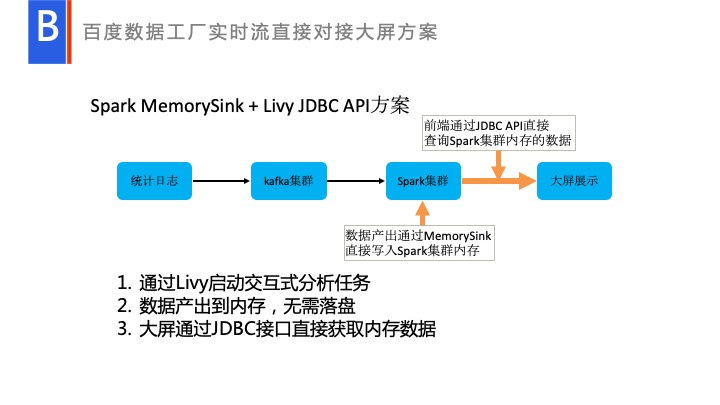
我们是如何处理呢?现有的一套解决方案提供了一套原生的基于 Spark SQL,Spark shell 的系统。我们自研了一套就是交互式的分析,可以在本地,通过 Livy JBDC API,当用户 select *或者什么的时候,它完全可以交互式的提交到集群上处理,然后反馈给用户。这时候结合 Spark MemorySink 去处理,将数据进行一些复杂的分析,具体的业务逻辑处理之后,它会将数据写入到集群内存里面。前端通过 Livy JDBC API 去交互式的去查询 Spark 集群内存的数据。这样数据是直接落到集群内存的,没有任何产出,是保存在内存里面的。Livy 去查的时候直接从里面去拿出来,相当于直接走内存,不会走经过落盘,网络等。这套方案就在实时处理和部署上,比较受欢迎。
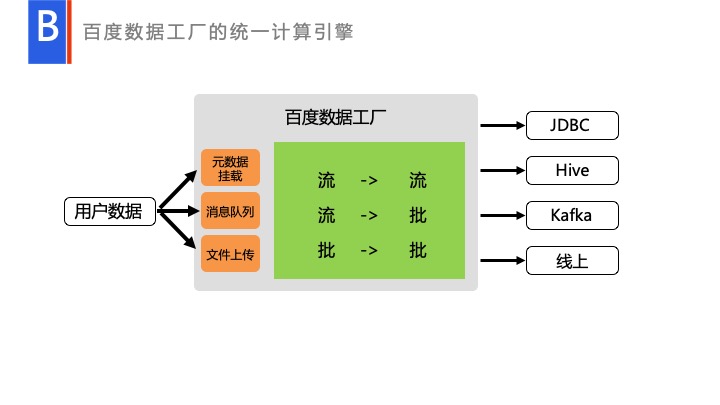
然后这就是,我们整个的流批的处理,用户通过各种方式传输数据,我们经过流到流,或者是流到批,或者是批到批的处理,当然中间我们可以完全映射成 Table,就是流式的 Table 到批的 Table,再到具体的业务输出方。或者流式的 Table 到流式的 Table,或者是批的 Table 的到批的 Table,这完全是 OK 的。
流式数据处理在百度数据工厂的实践
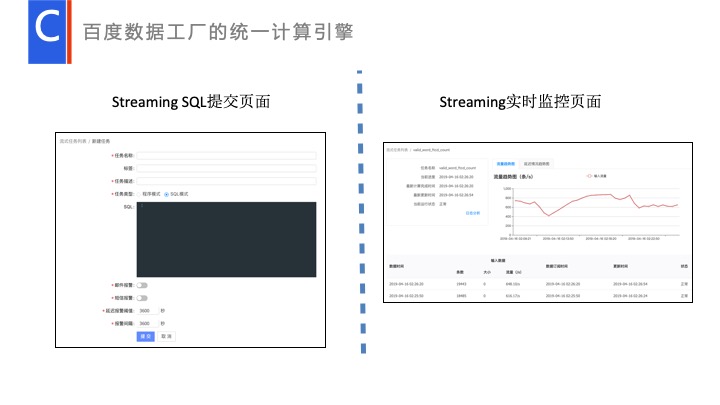
基于这套数据处理,我给大家简单介绍一下百度内部的一些实践。下图是流式的第一版本的产品化界面。我们已经在设计第三版了。左边是一个流式 SQL 的一个提交界面,用户可以在里面添加 SQL,右边是流式监控。和现在 Spark 比较,和 Spark 监控页面比较类似的,监控当天有什么数据,显示实际处理量、数据时延等。
广告物料分析实践案例是我们一个比较典型的流批处理的使用场景。在实际的产品运维过程中,存在广告主投放广告的场景。广告主投放广告付钱是要看真实的点击率、曝光率和转化率的,而且很多广告主是根据曝光量、点击量、转化量来付钱的。
这种情况下,我们就需要专门针对广告物料进行分析,根据点击、曝光日志和转化数据生成广告的 pv、uv、点击率和转化率,并根据计费数据生成广告收益。
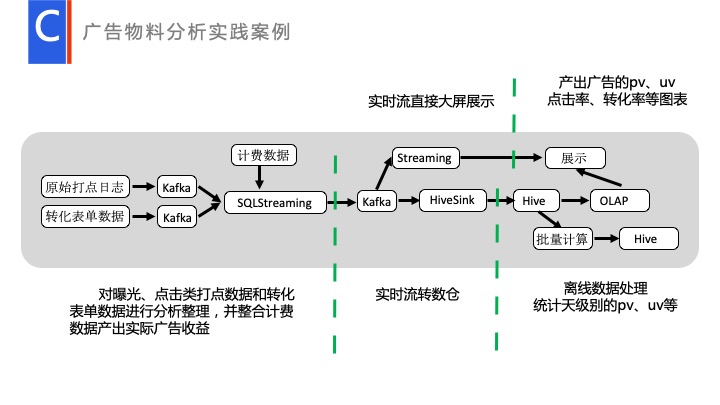
可以看到我们会通过 Streaming 直接输出到大屏展示。广告主会直接看到实时的用户量、当前的产出、收益。另外一部分数据产出到离线里面,通过实时转离线输出出来,进行一个日级别,天级别的分析,生成一些天级别,还有月级别的一些 PV 量,供后台做策略人员分析,以调整广告的投放策略。
未来计划
百度云数据工厂的链接https://cloud.baidu.com/product/pingo.html里面有详细的介绍,如果大家有什么疑问可以在上面看。百度数据工厂整合了各种解决方案,目的就是提供一个一站式的数据处理平台。下一步是我们产品化第三版本的正在研发中,基于 Spark3.0 DataSource v2 设计。后面会提供更细力度的一些监控和运维,对用户会更友好一些。另外就是流计算方面,我们会在 SQL API 中完全融入纯流式的数据计算。谢谢大家。
讲师介绍:李俊卿,百度高级研发工程师,数据工厂流式数据处理负责人。经历百度大数据离线批处理从 Hive 到 Spark1.x 到 Spark2.x 技术方案的架构升级;设计并研发百度数据工厂流式数据处理核心部分;研发基于 Spark 的流批统一 SQL 引擎。
QCon 全球软件开发大会(北京站)2019 已经圆满结束,QCon 上海 2019 即将起航,点击 「 阅读原文 」了解详情。大会 7 折早鸟票限时开售,现在报名立减 2640 元,团购可享更多优惠!有任何问题欢迎联系票务小姐姐 Ring ,电话:13269076283 微信:qcon-0410

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论