
简介
随着移动互联网迅速发展,大数据技术为企业带来了前所未有的发展机遇,然而中小企业和传统行业由于其数据量缺乏且单一,技术投入不足的劣势,面对大数据技术发展带来的红利只能望洋兴叹。

本文介绍我们即将推出的微信斑马系统,该系统旨在为中小企业和传统行业提供基于微信大数据分析技术的受众分析,精准推广,激活留存和商业智能决策的全套解决方案。
功能与模块
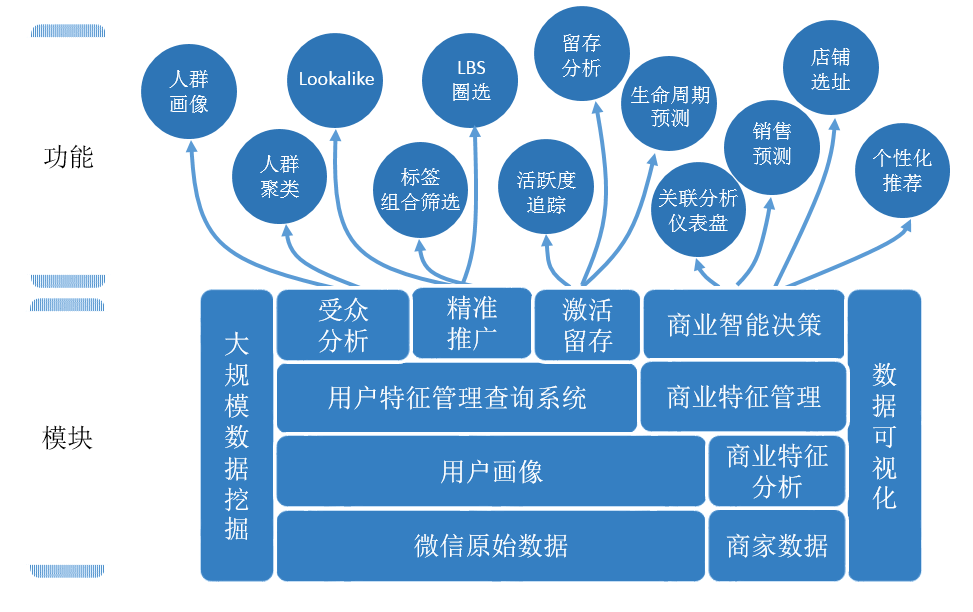
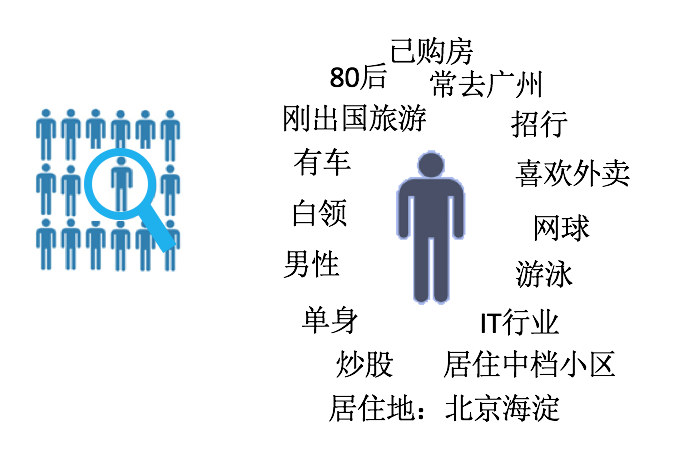
上图是斑马系统的功能与模块,最底层是数据层,我们先看左边的微信原始数据,这里主要是零散的网络日志包括个人填写的信息,网络行为,社交关系等,我们对其进行提取和分析得到用户的属性和各种特征,比如,居住地,年龄,是否结婚,正在旅游等。这样一个个的用户在我们系统里就有了各自丰富的特征,这个过程叫用户画像(Persona)。
这些特征的来源,覆盖人数,更新周期各不相同,随着业务的发展和系统的不断更新,用户特征将不断完善,我们开发了一套用户特征管理查询系统,用于将用户的所有特征整合在一个存储体系下实现新特征快速加入,周期更新和快速查找。
用户特征管理查询系统的外层是面向商家和运营人员的三个模块:受众分析、精准推广和激活留存。下面我来逐一介绍。
受众分析
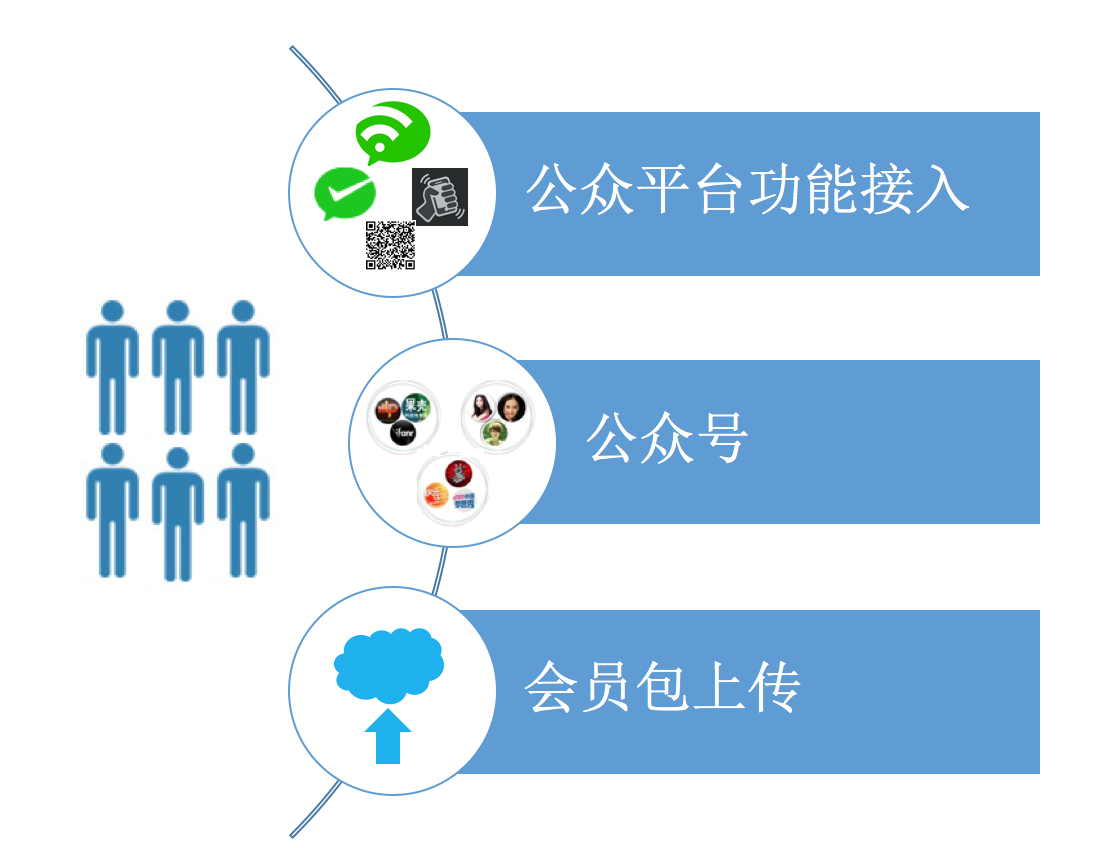
受众分析模块可以根据商家提供的自有用户数据分析人群特征。商家有多种方式告知系统自有用户。
- 商家接入了微信支付,微信 Wifi,微信授权登陆等功能,当用户使用这些功能时微信斑马系统就可以自动追踪到这批用户。
- 已有公众号的商家其粉丝即是对应的用户群。
- 商家可以上传自己的会员包,支持手机号,微信号,QQ 号的匹配。(无需全部的会员记录,只需要商家提供一定量的随机采样即可,考虑隐私保护问题目前系统只支持对 1 万人以上的人群做分析)
推荐使用第一种方式,因为不仅可以获得目标用户还可以分析人群的活跃度,到店频次和周期。
重要通知:接下来 InfoQ 将会选择性地将部分优秀内容首发在微信公众号中,欢迎关注 InfoQ 微信公众号第一时间阅读精品内容。

该模块提供人群画像和人群聚类两个功能:
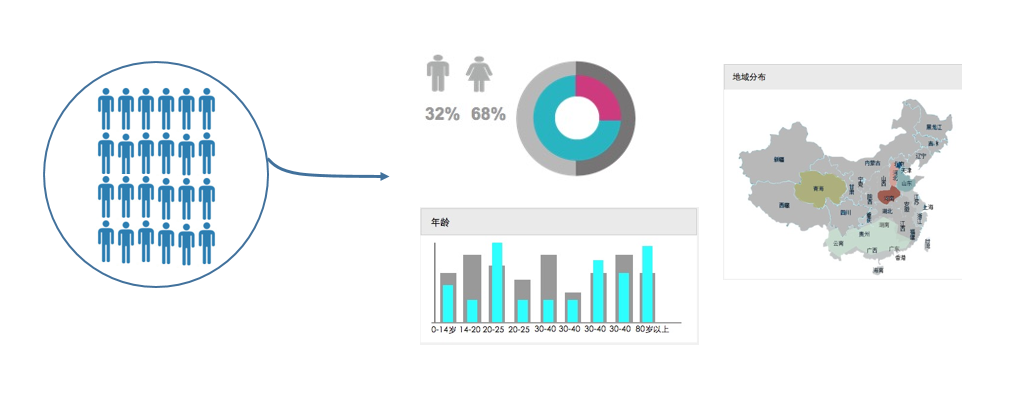
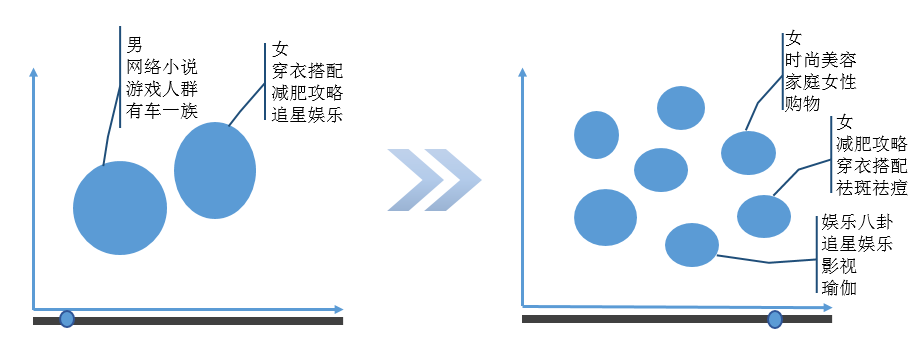
人群画像 (Audience Insights) 是对人群做画像的工具,它不仅对商家选定的人群做简单的统计分析,还会将用户包的人群特征和平台上全体用户的平均水平做对比,找出最能刻画该人群的特征。同时可以在各个维度上观察人群特征,比如只看男性用户特征,或只看北京用户特征。微信斑马系统的人群画像可以结合本文后面介绍的精准推广模块的各个筛选功能对海量人群秒级画像,比如通过上传公众号列表快速生成关注人群的画像。
人群聚类
虽然人群画像可以通过属性选择在各个维度上观察人群特征,但需要操作人员对行业有一定了解,人群聚类可以根据用户之间的相似性自动将其分为不同的人群,便于商家分析人群的内部结构和分布特点。
精准推广
在受众分析后商家和运营人员已经对自己的目标人群有了足够的理解,精准推广模块使用精准人群定义和相似性扩展技术为商家降低获取新用户的成本。
目前系统支持:
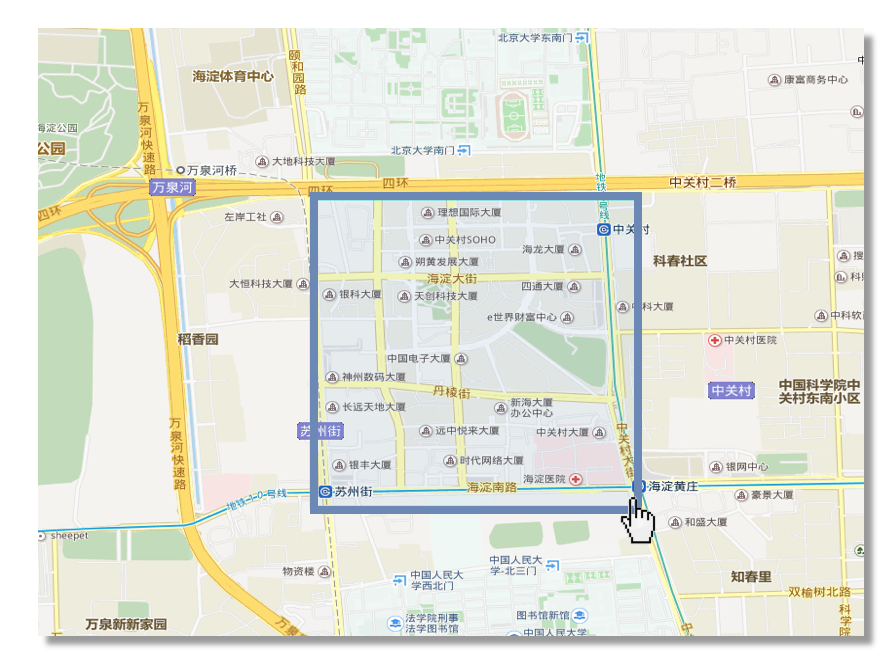
1, 基于 LBS 的圈选用户,适合线下 O2O 商家。
2,根据对产品的认识编写用户标签的组合规则筛选受众。
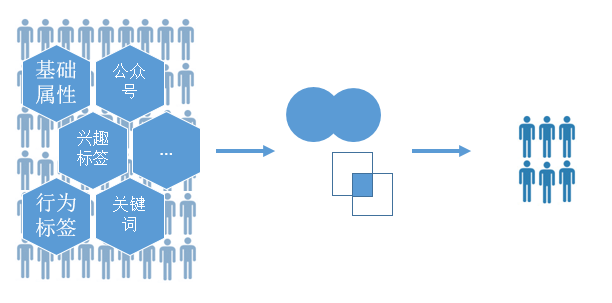
优点:
- 适合无自有会员的商家使用
- 只要规则设置的合理可以保证一定的精度
缺点:
- 召回不足(达不到需要的用户数,比如一个海外旅游的公司这次的广告计划是投放 1000 万受众,但我们特征系统里海外旅游标签下只有不到 100 万人)
- 召回过度(选出的用户过多不知道如何做进一步的筛选,比如一个卖运动鞋的品牌这次投放预算最大为 1000 万受众,但我们系统里运动相关的标签下有 5000 万人)
- 筛选的质量依赖于编写规则的人对行业的了解和标签体系的熟悉程度
- 人群复杂时用有限的标签和规则很难将受众描述清楚
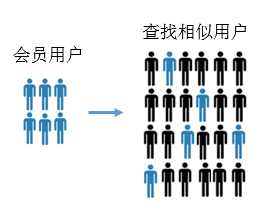
3.Lookalike
Lookalike Audiences 人群定向策略,简单的说就是用数据描述人群,以人找人,因为大部分商家都有一定量的自有用户(可能来自以往的消费记录或自身会员)那么这些用户的相似用户就是最好的受众。Lookalike 技术的产生有效弥补了标签筛选的不足,是当前社交广告中的主流方法。微信斑马系统的 Lookalike 算法不光可以对召回不足做相似性扩展,还可以对召回过度的情况做按比例精选,同时我们针对微信朋友圈社交广告人群定向的应用做了定制,使其在扩展时可以通过调节互动性参数设置扩展人群倾向于更精准还是更易于互动。如朋友圈广告人群定向时,宝马和奔驰这样的品牌广告商倾向易于产生互动的人群,而母婴,教育这类广告则更倾向于投放的精准性。
激活留存
在获取新用户后,如何提高用户的活跃度,并留住用户防止流失是运营的重点。斑马系统将用户画像与用户生命周期理论结合,利用数据挖掘技术指导商家实现个性化运营。所谓的用户生命周期是营销学里的一个理论,它将用户从获取到离开分为五个阶段

- 活跃度追踪 我们系统提供用户活跃度追踪模块,并给出各个活跃度上的人群特征。如果商家接入到开放平台的微信支付等功能,那么无需要做更多事,系统会自动追踪使用该功能用户的活跃度,分析他们随时间变化的规律,否则需要周期性的手动提交数据或是将自己的数据库接入斑马系统。
- 用户生命周期预测 系统通过挖掘历史数据中用户活跃度的变化,为每个商家生成其独有的用户生命周期模型,自动对其用户进行预测,判断其所处的阶段,告知商家有可能流失的用户群及其流失的速度,商家可以在运营中及时做出激励和促销,防止用户流失。
- 留存分析 留存分析功能根据历史数据分析用户在各个维度上的留存率,对异常的部分给出预警,以便商家及时发现问题,比如发现某个地区的用户流失近期显著增加可能为该地区的分店存在问题。
商业智能决策
商业智能决策(BI,Business Intelligence)面向有一定规模的中型或大型企业,需要对接其数据库后做商业特征分析针对不同行业引入销售,物流,生产等维度上的信息,并将其与微信中的用户特征做可视化联合展示,微信斑马系统的 BI 不仅提供传统 BI 中的仪表盘,关联分析和下钻等功能,同时还会针对不同行业提供丰富多样的实用工具,如销售预测,店铺选址,个性化推荐等
微信朋友圈广告人群定向投放系统
以上功能可以根据需要灵活组合使用,我们将受众分析,精准推广和朋友圈广告投放系统进行串联和组合,完成了微信朋友圈广告人群定向投放系统。
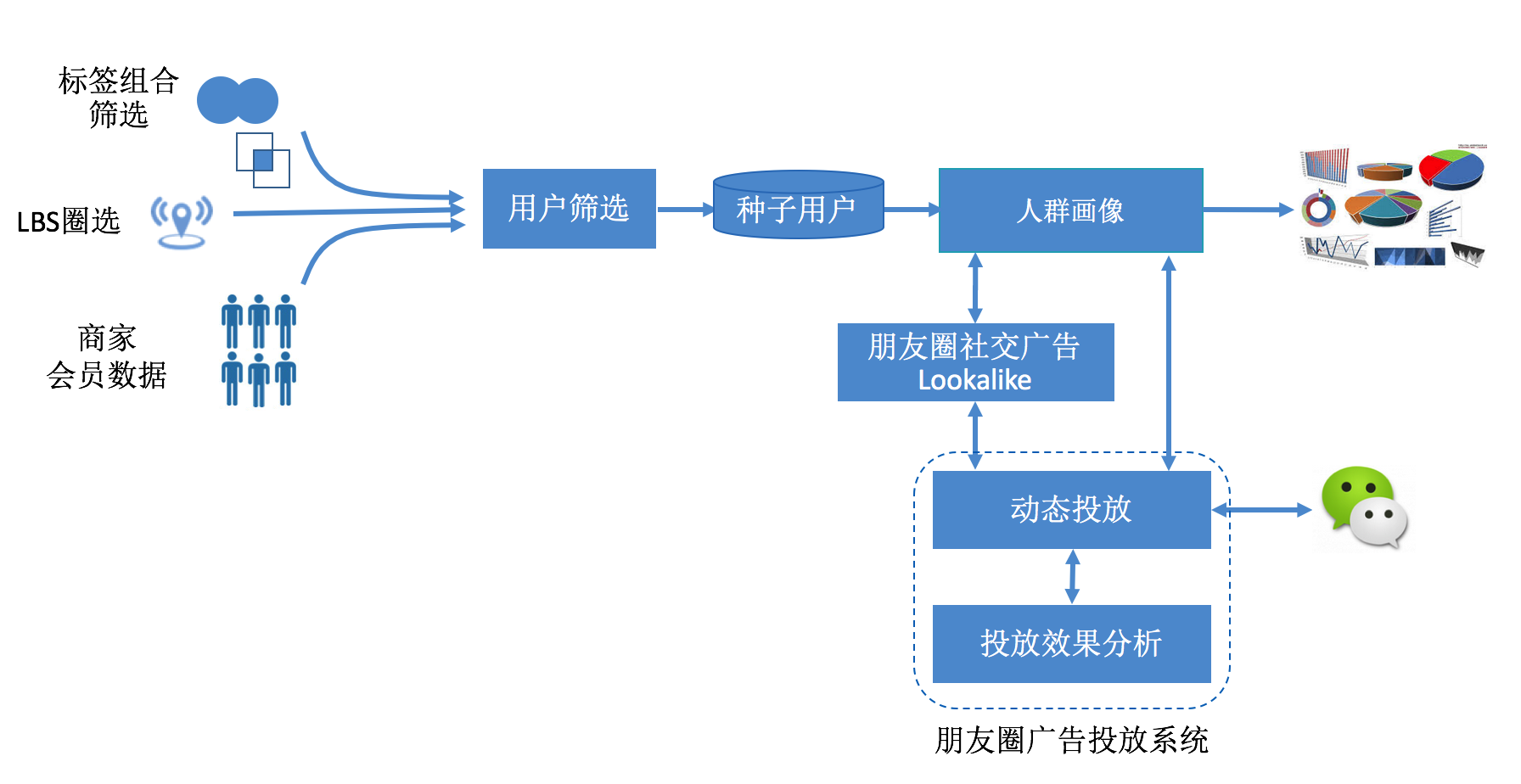
商家可以通过上传自己的会员包或是通过标签组合筛选和 LBS 圈选获取初期投放的种子用户,系统获取到种子用户后人群画像系统快速的展示出这批人群的特征和各项统计结果,整个过程只需要等待数秒。商家可以选择特征从不同维度上观察和筛选人群,确认后可以直接投放,当召回不足时可以使用 Lookalike 系统对其进行扩展,目前的扩展最大规模为种子用户的 100 倍,另外我们的 Lookalike 系统还可以对召回过量的问题设置一个 0-1 之间的倍数做精选,完成受众选择后进入广告投放配置页面设置投放计划,广告投放后可在效果分析页面查看广告投放的各项指标。
朋友圈社交广告 Lookalike 打分算法
看了上面的内容可能有读者会问朋友圈社交广告的 Lookalike 打分与相似度 Lookalike 打分有何不同?因为社交广告展示的效果很大一部分是通过用户在广告上的各项互动反馈指标来衡量的,相似度 Lookalike 的分数只能反映出该用户和当前商品用户群的相似度,不能保证其在广告投放后有效的正反馈,商家当然希望用户在广告上进行点赞,评论,转发,最好是关注,下单等操作,因此相似度 Lookalike 分数还需要使用用户在微信朋友圈广告上的各项互动因子进行缩放, 互动因子表示当前用户倾向于广告互动的程度,越大越可能产生互动。假如历史上所有用户看到的广告都是一样的,那么可以通过简单的统计对其估算,但难点就在于大部分用户历史投放的广告是不一样的,而且还有部分用户之前从未看过广告。
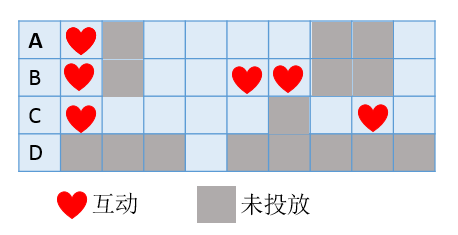
上图是用户 A,B,C,D 历史广告的行为,每列为一个历史广告,红星为有互动行为,灰色为该条广告对当前用户没有投放,这里 A 和 B 对比因为投放广告内容一致,所有可以近似认为 B 比 A 互动因子更高,但对比 A 和 C 时,因为投放广告内容是不一致,即使这里 C 比 A 的互动次数多也不能断定 C 比 A 有更高的互动因子,而对于 D 由于其在历史上看到的广告数量很少就更没办法估算了。
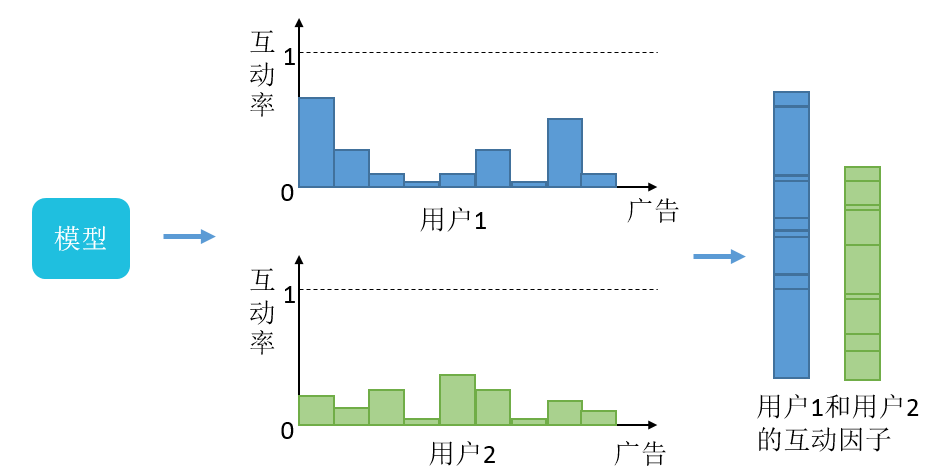
我们的解决方法是根据历史数据训练了一个用户互动行为的预估模型,再对全量用户预测,预测后每个用户在各个广告上的互动率都在 0 和 1 之间。之后就可以根据在各个广告上预测出的互动率之和作为该用户互动因子的近似,这个过程是在线下事先算好的,线上打分时会直接调用当前用户的各项互动因子,并根据设置的互动性参数微调以获得更相似的用户或是更易互动的用户。
线上效果
该系统已在微信朋友圈广告上使用,下表是对 A,B 两个广告的投放效果(这里列出正反馈 1,正反馈 2,和 负反馈 三项指标,我们系统的实际指标比这复杂的多)
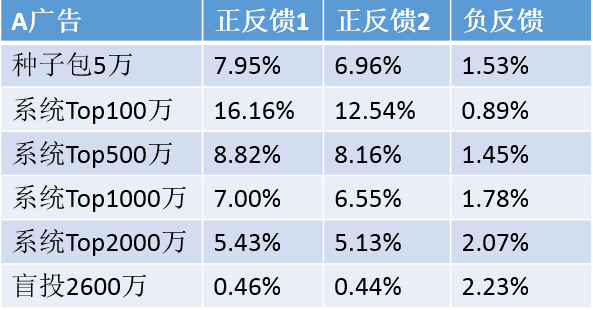
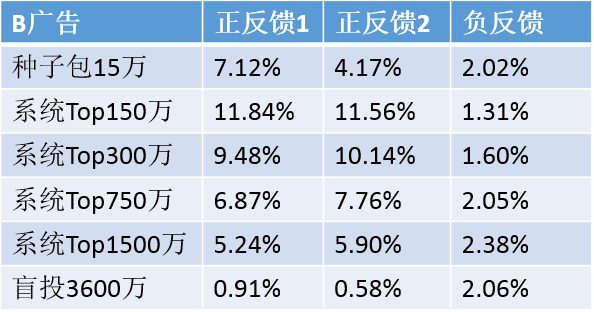
其中系统 Top 100-2000 万表示的是种子用户使用我们系统扩展后根据打分结果选出的前 100-2000 万用户,显然越靠前的用户效果越好。我们系统将种子包扩展到 90 倍到 100 倍时仍能保证负反馈没有增加的同时有同等效果的正反馈,这里的盲投是根据广告计划在年龄,地域,时间等条件下随机投放的结果,可以看到其效果明显低于种子包和系统扩展的效果。
安全与隐私保护
数据开放和共享是大数据时代公认的趋势,但隐私问题是最大的挑战。微信斑马系统从设计之初就将数据安全和个人隐私问题放在首位,系统遵循以下几个原则:
- 分析一群人而不分析一个人(我们的系统目前只支持 1 万以上的人群画像分析)。
- 不使用个人可辨识信息(Personal Identifiable Information),如:姓名,身份证号,手机号 等。(我们数据处理时使用无任何物理含义的 User ID 作为各个数据中的统一标识)
- 通讯和聊天内容神圣不可侵犯,不保存和使用任何通讯和聊天内容。
- 控制精度,这里的精度并不是指准确度,比如我们在分析用户住址时,只定位到小区,而不再做楼栋和楼层的定位。
- 只保留和使用一年以内的数据。
- 所有的标签都由算法自动化生成而不使用人工标注,工程师只负责设计算法。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论