
前言
持续集成是极限编程十二实践之一(1999 年Kent Beck 编写的《解析极限编程》),最初被使用极限编程方法的开发人员所推捧,并在过去的几年中得到广泛应用,成为业界广为人知的软件开发实践。该实践用于解决软件开发过程中一个具体且重要的问题,即“确保当某个开发人员完成新的功能或修改代码后,整个软件仍旧能正常工作。”
然而,持续集成并非像大多数人想像的那样,首次部署好持续集成环境后就大功告成,一劳永逸了。恰恰相反,它与你项目中的其它产品代码一样,需要改进与重构,否则,就会使你进入一种“持续闹心”的状态,甚至可能让你觉得这件事根本不应该做,如何解决这一问题呢?对“持续集成”应用“Retrospective”和“重构”。本文将结合 Cruise 团队一年多的实际历程,讲述持续集成实践在软件开发过程中的演进。
友情提示:请读者在阅读本文时,注重文中所述的思考过程与“持续集成”的重构方式,而非产品本身。
基本持续集成——万里长征第一步
实际问题:我们需要一个持续集成环境
为什么要做持续集成不在本文讨论之内。
理论基础
持续集成基于这样一个假设:如果两次代码集成的间隔时间越长,最终集成时痛苦的经历就会越多。而其目标有两个:一是“频繁集成”,二是“反映代码质量”。为了做到“ 频繁集成”,就要求任何开发人员在每次向中央代码库提交代码时,就将所有代码进行编译,打包,部署,以确保能够产生交付物。然而,“频繁集成”仅仅证明了 每次提交是否可以得到交付物,而我们真正需要知道的是“这个交付物的质量如何”。如果交付物有问题,引起问题的代码则要么被回滚,要么被修正。当然,这样 的任务也可以通过手工来完成,但手工工作的特点就是易出错且耗时,所以需要将其自动化。为了做好“持续集成实践”,写一个自动化构建脚本来自动构建并运行 一些自动化测试套件还是必要的。这种传统的持续集成方式常被固化于开发环节,即:开发人员安装一个专门的持续集成服务器来自动化运行这些单元测试,然后通 过各种各样自动生成的测试结果分析代码的质量,这也是 CruiseControl 诞生的原因。
解决方案
最初,我们的代码并不多,自动化脚本比较简单,在一台机器上运行所有的测试也仅需要几分钟,该构建套件的运行顺序是:CheckStyle -> Compile -> UnitTest -> FunctionTest -> Report。示意如下:
<project name="Cruise" default="all" basedir="."> <target name="all" depends="checkStyle, Compile, UnitTest,FunctionTest, Report"/> <target name="checkStyle"> .... </target> <target name="Compile" > ... </target> <target name="UnitTest" depends="Compile"> ... </target> <target name="FunctionTest" depends="Compile"> ... </target> <target name="Report" depends="FunctionTest"> ... </target> </project>
这也是大部分软件团队进行持续集成的起点。
目前,有很多种持续集成工具,其中不乏开源产品,如 CruiseControl 家族。项目伊始,我们使用 CruiseControl 建立了自己的持续集成服务器,整个项目的持续集成基础结构如图所示:
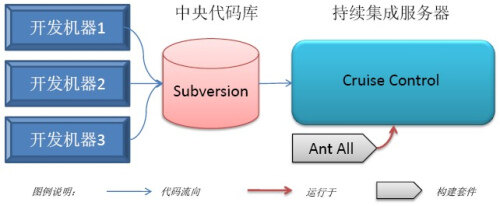
图 1 基础持续集成模式
注:得到快速反馈是开发好产品的关键。因此,我们自己就做了 Cruise 的第一个用户,首先解决自己的持续集成需求。项目开始后仅几周,我们的产品 Cruise 已经基本满足自身团队持续集成的需求,因此,我们就将 CruiseControl 替换成 Cruise,但持续集成基本结构并没有变化。
阶段化持续集成 —— 平衡的艺术
实际问题:测试越来越慢,开发人员等得不耐烦。
随着时间的推移,Cruise 每次做持续集成的运行时间很快就超过了 15 分钟(开发人员能够忍受的最大限度)。然而,为了保证 Cruise 支持大多数浏览器,我们还打算增加 Cruise 运行于不同操作系统及不同浏览器的功能测试。
理论基础
一般来说,测试代码越多,越能够正确反映代码的质量[前提:你写的测试是有意义的:)]。所以在整个生命周期中,大家都试图增加更多的测试代码。然而,越 多的测试代码也意味着更长的运行时间,更慢的反馈速度。因此,我们不得不在“反馈时间”与“判断质量准确性”两者之间找到一种平衡,而“阶段化持续集成” 就有了用武之地。
所谓的“阶段化持续集成”是指为不同的构建测试套件(以下称构建计划)建立不同的持续集成循环周期,由于单元测试运行时间短,反馈较快,所以可以频繁进 行,而功能测试、性能测试的时间比较长,占用资源比较多,比较昂贵,所以适当减少集成次数,但一定要保证其周期性运行。因此,我们的持续集成方案很自然地 分成了多个构建计划:快速构建计划让开发人员尽可能快地得到反馈,此时我们牺牲了准确性来换取时间。但当你得到了快速反馈以后,再花多一点儿时间从其它构 建计划中得到更详细的反馈。这样一来,对于同一个项目,你有多个构建计划,每个对应一种构建类型(单元测试,功能测试、功能测试等),越靠后的构建计划在 运行时需要的时间就越长。如下图,
单元测试构建计划运行了多次, U1,U2…U7,其中 U4 失败了。功能测试构建计划时间较长,在该时间段内仅运行两次,F1 和 F2(失败),而性能测试构建计划 P1 时间最长。整个 持续集成系统由多个机器组成,包括一个中心服务器(Server)和多台工作站(Agent),每个构建计划都在一台工作站(agent)独立执行,以便 无相互影响。
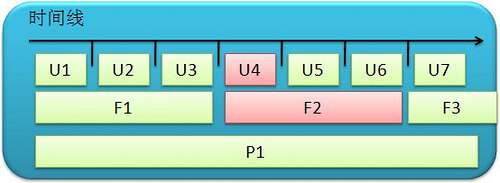
图 2 阶段式并行构建图解
解决方案
由于 Cruise 本身已经支持这种持续集成模式,所以我们的持续集成基本框架也演变成下图:
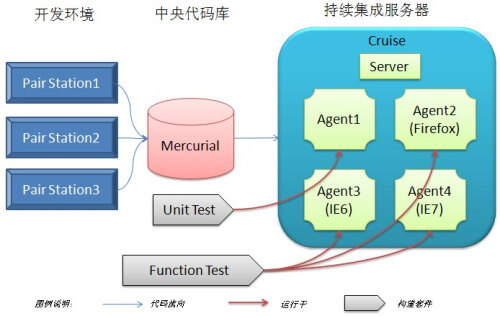
图 3 阶段式持续集成模式图解
中心服务器 (Server) 的责任是(1)检查中央代码库的代码是否发生变化,(2)如果代码发生了变化,将相应的构建类型分配到各自的工作站 (Agent)上运行;(3)中心仓库,保存所有信息。上图中,单元测试 (Unit Test) 构建类型运行于工作站 Agent1 上,每次执行需要 15 分钟左右,而功能测试 (Function Test) 构建类型分别运行于三个工作站(Agent2,Agent3 和 Agent4)上,每次执行约 30 分钟(其中 Agent1 为 Debian 操作系 统,Agent2 是 Ubuntu8.04 操作系统,安装有 Firefox2.0,Agent3 是 WindowXP+IE6,而 Agent4 是 Windows 2003 + IE7)。
细心的读者会发现,中央代码库从 Subversion 变成了 Mercurial,我的同事胡凯在《为什么我们要放弃Subversion 》一文中讲述了缘由,其根本收益就是提高了Cruise 生产效率。构建计划:是根据功能划分的自动构建循环周期,由一系列的步骤组成。下图为三种不同的构建计划:
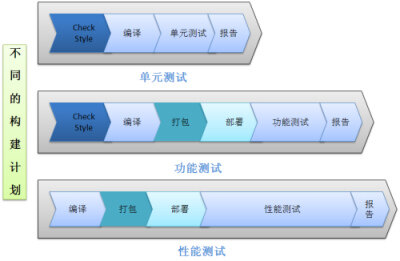
图4 不同类型的构建计划
利弊分析
益处:暂时解决反馈时间长的问题。
缺点:仍存在浪费,提交频繁时,问题定位有时较困难。
在执行每个构建计划前,都需要从中央服务器上检出代码。不同的构建计划中,有很多步骤都是重复的,例如图4 所示的编译与打包工作。当代码库比较小时,这并 不是一个大问题。然而,对于此时的Cruise 来说,就已经是“浪费”了。在图2 中,单元测试U4 已经以失败而告终,可功能测试还是在另外三台工作站 (Agent)上运行着,一直占用着机器,直至结束。想像一下,如果构建计划的数量多于工作站(Agent)的个数时,这种资源的浪费又是多么严重呢?
另外,如图2 所示,由于单元测试运行较快,所以功能测试F2 中包含多个单元测试(U2,U3,U4)所覆盖的代码变化。如果F2 失败,很难判断是哪次Checkin 使F2 失败的,因为前面已经成功结束的U2 和U3 也可能使F2 失败。
过程化持续集成 —— 消除浪费
实际问题
开始使用阶段式持续集成时,由于不用改太多的构建脚本,而且也初步达到了目的。可是随着时间的推移,代码越来越多,逻辑越来越复杂,问题定位令我们头痛,而且每个构建计划都要重新编译和打包等重复性工作也让团队不爽。
理论基础
过程化则是将每一个步骤单元化,并顺序执行。如第一个单元是CheckStyle,编译及单元测试,第二个单元是打包生成软件,第三个单元是“部署 并进行功能测试”,第三个单元是“性能测试”。这种过程化分解因去除了重复步骤,所以更有效率,而且每次执行时,代码可以顺序经历一系列的测试。
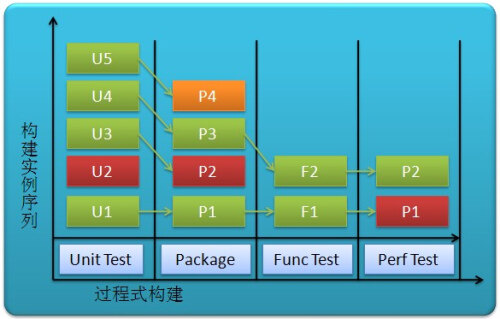
图5 过程化构建图解
该类型集成的关键在于让所有这些分离的单元可以顺序执行。首先,编译过程被调用,一旦编译单元成功结束,下一单元(快速测试)即开始。正是此刻,我们遇到 了第一个复杂性。由于第二个单元(如快速测试)并不是一个完整的过程,所以并不能用它自己产生的产物来测试。而这一点恰恰是过程化持续集成的的关键:将构 建与测试分离以节省时间,这也是其与阶段性集成的不同之处。由于后续单元并不产生测试所需要的产物,就要从外部获取,而这些产物正好产生于前面的单元。因 此,运行前面单元时,它要将这些产物放在一个已知位置,而后续的单元从这个已知位置拿到产物。图5 所示,U4 成功后,P3 从U4 处拿到代码进行打包;P3 结束后,F2 从P3 处拿到交付物进行部署和功能测试,F2 成功后,P2 再开始运行。
利弊分析
优点:消除和重复工作,提供了持续的信息反馈,反映了整个的过程。
前一个构建计划U2 失败后,后续的构建计划P2 也不会从U2 中拿取产物来运行,而是等待拿U3 的结果来运行,从而也有效的利用的资源。
缺点:团队自己管理的内容多一些,复杂一些。
由于各个构建计划之间是各自独立的,所以它们之间的依赖关系由它们之间传递的参 数表现。当您想追踪某个后续构建计划为什么失败时,你必须找到这个参数。可 这种过程化持续集成并没有提供一个内在功能来完成它,所以你必须自己再多做一点儿工作,而且前后构建单元之间的产物传递也要自己来完成。 产物传递看上去要复杂一点儿。因为最近一次构建的结果很容易将前一次的结果覆盖掉。解决这一问题的一种方法是将每次构建的结果分开存放,而后续的单元要知 道在哪里可以找到它们所需的文件。利用构建编号做为目录名来保存构建结果时,后续的单元就需要知道这个构建编号,以便找到它所需要的文件。尽管这不难做 到,但还是需要做一点儿工作才能做到的。
另外,由于这种方式需要准备产品的中央存储空间,建立命名规则,修改我们的构建代码,以便在各过程之间传参数。另外,这种模式还是不能从根本解决问题定位这个难题。
团队结论
由于采用这种方式的管理复杂性较高,在我们的环境中,潜在的时间消耗也不少,所以我们放弃了这种集成方式。
管道式持续集成——企业级持续集成的解决方案
实际问题
阶段化持续集成重复任务多,而过程化集成的管理复杂性太高了,任何过程化上的变化都要修改已经写好的脚本,而这些脚本维护比较困难。既然以上两种模式都不灵了,那就再想别的办法吧。
理论基础
管道式持续集成形式上与过程化持续集成相类似,但却在概念上有显著不同。在管道式持续集成中,所有的过程单元都运行在同一管道的上下文中,即各单元所使用 的原材料都是完成相同的,即代码基线相同。当持续集成服务器发现有新的代码时,会创建新的一个管道,所有的过程单元都在这一个管道中运行。而每个单元产生 的产物也在该管道中有效。如图所示:

图6 管道化持续集成
利弊分析
管道式持续集成综合了阶段化与过程化的优点,而带来的复杂性却不用你操心,因为Cruise 为你管理这一切。
也就是说,你很容易就掌握,哪些产品代码是在哪个管道中生成的,是由哪些原材料(源代码)生成的,而与其它管道产生的产品代码有什么不同。在管道式中,每次构建都会试图从管道的一端走到另一端。因此,你不会遗漏任何一个版本的成功产品代码。
解决方案
Cruise 持续集成类似于下面的持续集成构建管道:
<pipeline name="Cruise"> <stage name="UnitTest"> <job name = "windows"> <artifacts> <artifact src="testreport" dest="report"/> <artifact src="pkg" dest="package"/> </artifacts> <tasks> <ant /> </tasks> </job> <job name="linux"/> </stage> <stage name="FuncTest"> <job name = "windows"/> <job name="linux"/> </stage> <stage name="TwistTest"> <job name = "windows"/> <job name="linux"/> </stage> <stage name="Package"> <job name = "Solaris"/> <job name="linux"/> </stage> </pipeline>
如图 7 所示,最后一次构建版本(1.2.128)从管道的一头成功走到了另一头,正在进行最后一步(部署到生产环境,黄色方块代表正在运行),版本 1.2.127 失败于打包交付物,虽然我们让版本 1.2.126 走到了管道的尽头,但您可能注意到这是一个有暇疵的版本(Package 有点问题),而且 被很快在 1.2.128 中修复了。而其它版本都有问题而未能走到管道的尽头。

图 7 构建管道图解
并发执行——时间就是金钱,资源也是金钱
实际问题
尽管我们将整个持续集成过程中所需完成的工作根据具体任务分成了很多独立的步骤,并管道化运行,但是并未能解决真正的“时间运行超长”问题。因为, 我们的测试代码已经达到相当数量,运行一次所有的单元测试要在 40 分钟以上,而在一台机器上运行所有功能测试大约需要 2 小时以上。而且可以预见到,这一时 间量会快速增加。那么,要如何解决这个问题呢?当然不可能因为时间长而不增加测试。
理论基础
将同一类型的测试分成几组,同时运行在配置相同的 Agent 上。这样,虽然不能减少总时间,但是完成所有同类型测试所需要的时间周期会缩短。
解决方案
Cruise 团队成员利用业余时间创建了一个开源项目,名为 Test-Load-Balance , 利用 Cruise 的特性,根据 Cruise 中 Job 的配置,自动将测试分成多组,运行于不同的 Agent 中。当测试运行时间到了无法接受的时候,只需要在 Cruise 的配置文件中增加一个 Job,它就会自动感知这一变化,将测试再多分一份出来。只要有足够的 Agent,那么你的测试时间一定会缩短到 15 分 钟以内。目前,Cruise 的单元测试被 Test-load-Balance 自动等分成四组运行于 Windows,以及五组运行于 Linux,而功能测试也一样被自动分成四组,分别运行于 Windows 和 Linux。目前用于 Cruise 持续集成环境中的工作站共计 11 台虚拟机,使 Cruise 的所有单元测试可以在 15 分钟内完成,所有的功能测试可以在 35 分钟内完成。
我们的持续集成基本结构变为:
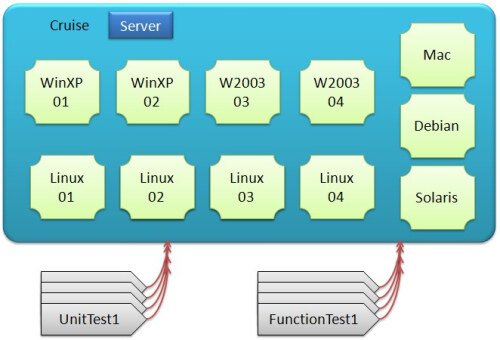
图 8 Build Cloud
Cruise 团队的持续集成类似下面的配置文件:
<pipeline name="Cruise"> <stage name="UnitTest"> <job name = "windows-01"/> <job name = "windows-02"/> <job name = "windows-03"/> <job name = "windows-04"/> <job name="linux-01"/> <job name="linux-02"/> <job name="linux-03"/> <job name="linux-04"/> </stage> <stage name="FuncTest"> <job name = "windows"/> <job name="linux"/> </stage> <stage name="TwistTest"> <job name = "windows-01"/> <job name = "windows-02"/> <job name = "windows-03"/> <job name = "windows-04"/> <job name="linux-01"/> <job name="linux-02"/> <job name="linux-03"/> <job name="linux-04"/> </stage> <stage name="Package"> <job name = "Solaris"/> <job name="linux"/> </stage> <stage name="UAT"> <job name = "deployUAT"/> </stage> <stage name="Production"> <job name = "deployProd"/> </stage> </pipeline>
利弊分析
我们已无需投入过多的精力在持续集成环境上了,除非我们的硬件不足(可现在的硬件成本要比人工成本低多了)。因为 Cruise Server 自动会将构建计划平均分成多组,并分配到相应的工作站 (Agent) 上运行。如果测试代码进一步膨胀,我们只需要在相应的测试阶段加增加 Job 的个数,再克隆出几台虚拟机扔到我们的 Agent grid 中。而这仅需很少的人工操作,根本不必修改我们的自动构建代码。
个人持续集成——最大化利用资源
实际问题
测试越来越多,运行时间越来越长。开发人员在本地执行单元测试的时候,开发人员就要看着屏幕等待吗?
解决方案
在 PairStation 上安装一个虚拟机,在其上建立自己的代码仓库。需要运行测试时,把 PairStation 物理机器的代码提交到这个虚拟机的代码仓库中,并让其运行测试。然后,继续在 PairStation 上写代码。如图所示:

利弊分析
益处显而易见,节省时间,提高开发效率。团队(至少个人)要使用分布式版本控制系统。另外,用于开发的物理机性能不能太差。其实,这也算不上大问题,因为在你开发软件时,思考的时间应该多于你写代码的时间。
小结
在敏捷团队中,我们所要做的只不过是:不断的回顾、找出问题与瓶颈、不断地重构。通过不断重构持续集成基础结构以及自动化构建脚本,使其达到我们对“反馈时间”和“判断质量准确性”的要求。
另外,我们已将“持续集成”扩展到整个软件开发周期,涵盖了持续部署及发布。在上面的配置文件中,细心的你会发现最后的两个 Stage 分别名为 “UAT”和“Production”,它们一个用于部署新版本到我们自己的持续集成服务器,另一个用于部署新版本到一个公用的持续集成服务器。部署 ‘UAT’的频率为两天到一周之间,‘Production’的频率为一周。这样,我们可以得到快速反馈,改进自己的产品,同时其它团队可以尽早地使用我 们开发的新功能。
持续集成并不是一蹴而就的工作,需要根据团队的实际情况来实施(但这并不能成会“偷赖”的另一个说法)。仅管 Cruise 团队的持续集成尚属“简单”之列,但并不能说明复杂项目无法做持续集成。俗语道,“没有做不到,只有想不到”。只要不断反思与重构,一样可以硕果累累。
注:这些持续集成方式早有出处,例如 2004 年的《通过“产物依赖”实现企业级持续集成》,而Cruise 团队仅是勇于实践者,并进行着不断的思考和优化。
关于Cruise
2008 年 7 月 Thoughtworks 的 Studios 部门首次发布一款持续成与发布管理的系统工具(名为 Cruise ),该产品将持续集成延伸到了应用的测试、部署与发布阶段。 Cruise 可以运行在多种操作系统上(包括 Windows , Mac OS X ,和 Linux),并为.NET , Java 和 Ruby 提供了使用上的便捷。 它使复杂软件应用的发布管理变得容易、可靠,为你的团队争取更多的时间,以便集中精力开发新的功能。
关于作者
乔梁,ThoughtWorks 公司资深咨询师及敏捷过程教练;产品Cruise 的项目经理。 他在IT 业界有十余年的工作经验,从事过开发、系统管理、培训、项目管理等工作,对于企业从CMMI 到Lean/Agile 的转换,业务分析,企业IT 管 理多有心得。目前致力于获取和传播构建、测试、部署方面的最佳实践,将Cruise 开发成为持续集成和发布管理的第一商业服务器。
相关阅读
[ ThoughtWorks 实践集锦(1)] 我和敏捷团队的五个约定。
[ ThoughtWorks 实践集锦(2)] 如何在敏捷开发中做好数据迁移。
[ ThoughtWorks 实践集锦(3)] RichClient/RIA 原则与实践(上)、(下)。
[ ThoughtWorks 实践集锦(4)] 为什么我们要放弃Subversion 。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论