本文作者为广发证券首席架构师梁启鸿,他讲结合自己的经历,分享他在在传统券商环境引入与推动容器化技术的思考历程,尝试陈述为什么云计算对证券业甚至整个金融业重要,而容器化技术的出现又带来何种契机。整个文章比较长,聊聊架构将拆分为多篇分时发送,如果你对这个话题感兴趣,请根据文末指引扫码入群交流。
广发证券是一家本土的券商公司,于 2014 年 Docker 等容器技术尚未盛行之时开始投入容器化技术的研究,并于 2015 年开始大规模投入应用 - 成交量六百亿(2015 年)规模的金融电商平台、消息推送日均数千万条级别的社会化投顾问答平台以及日均流经交易量峰值近五十亿的交易总线均被容器化;投入生产的容器化云服务包括行情、资讯、消息推送、自选股、统一认证、实时事件处理等等。
2016 年并开始基于 Docker、Kubernetes、Rancher 等技术研发运维机器人投顾(已投产)、极速交易系统、社会化 CRM,构建容器化的混合云解决方案。可能是为数不多把容器化技术大规模用到“真金白银”的金融业务中的案例。容器化技术帮助一家传统券商在云计算领域“弯道超车”。
在此分享本人在这两年里的在传统券商环境引入与推动容器化技术的思考历程,尝试陈述为什么云计算对证券业甚至整个金融业重要、而容器化技术的出现又带来何种契机。
历史学家黄仁宇在其被认为是“大历史观”典范之作的《万历十五年》序言中提到两个观点,一是对一件历史事件的评价,要把时间坐标推到三四百年的范围,才能看清楚该事件的来龙去脉;另一是“可以数目字上管理”是区分社会现代化与非现代化的分水岭。
借这个角度看,我们现在的技术发展,是物理世界不可逆转的日益数字化虚拟化的过程 – 一切都为了更高效更“数目字可管理”,数字化进程也许可以追溯到电子计算机出现前并因技术革命而以指数级别加速推进,而云计算的出现,是这一进程里的关键事件之一,对于未来的 IT 系统技术与架构有着深远的影响。
在此之前,我们以物理世界的硬件(服务器与网络设备)承载着一个虚拟世界,这个物理载体很大程度上依然靠人肉运维(最多加上一些半自动化的工具,然而称不上“智能”);在此之后,物理载体本身被数字化 – 虚拟机(Virtual Machine)、容器(Container)、软件定义网络(SDN),物理设施固然还在,但是它上面的软件栈(stack)却越来越关键。
数字世界像一个黑洞,它把一切线下的、非数字化的东西都席卷进来。连基础设施(infrastructure)都数字化的 IT 系统 – 所谓 Infrastructure As Code(基础设施即代码、可编程基础设施),一旦结合大数据、机器学习,智能化、自动化的运维逐渐成为可能;一个因应突发事件而弹性自伸缩、自愈、自适应的软件系统,“自己运维自己”的“无人值守”运维,相信到今天对于一部分 IT 人而言,并不是科幻电影。
开场白引用黄仁宇先生,乃因为个人深受其“大历史观”(macro history)之影响,倾向于认同事物在“历史上长期的合理性”,这对于金融业这个受高度监管的行业有特别寓意。 目前金融业大部分机构,未能积极拥抱与利用云技术,原因之一恐怕是因为监管方面就“信息安全”尚有顾虑,原因之二是金融业相对传统之 IT,对云计算本身缺乏深刻认识。云计算是数字化进程里一个必然环节,被本身即已高度数字化的金融业以合理合规的方式采用是早晚的事情,“历史潮流”是无法阻挡的。
而我们作为高性能交易系统、互联网金融平台之研发者,对于云计算、尤其是容器化技术,有着特别的触觉。自从 2013 年 Docker 这种容器技术出现后,我们仿佛嗅到了些什么。在经过两年的研究与投产应用后,我们反省采用云技术的动机,总结得益好处、落实手段、技术关键,以飨同好。
从《黑天鹅》说起
我们研究和应用云技术的动机,来源于对“黑天鹅”事件的应对。“黑天鹅”这一概念,是在美国学者、风险分析师、前量化交易员、前对冲基金经理塔勒布(Nassim Nicholas Taleb)的《黑天鹅》(The Black Swan – The impact of the highly improbable)一书发表后在全球被得以高度认知。在发现澳大利亚之前,17 世纪之前的欧洲人认为天鹅都是白色的。但随着第一只黑天鹅的出现,这个不可动摇的信念崩溃了。黑天鹅的存在寓意着不可预测的重大稀有事件,它在意料之外并且后果非常严重。
一个黑天鹅事件,具有这三个特点:(1)稀缺、通常史无前例(rarity),(2)影响很极端(extreme impact),(3)虽然它具有意外性,但人的本性促使我们在事后为它的发生找到理由 – “事后诸葛亮”,并且或多或少认为它是可解释和可预测的(introspective)。IT 系统、尤其是资本市场里的交易系统,所发生的各种重大问题,其实是很符合黑天鹅事件的特点的。
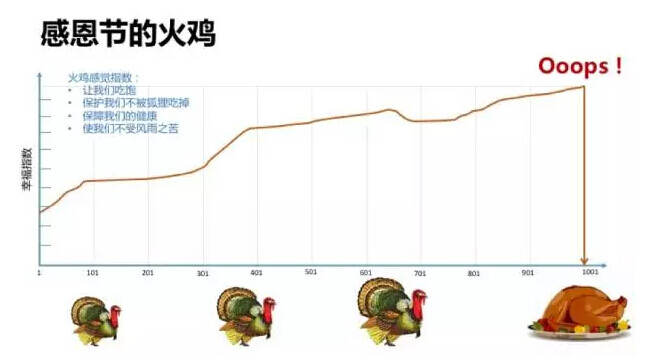
塔勒布用“感恩节的火鸡”很形象的解释了黑天鹅的概念 – 直到被宰掉成为感恩节火鸡晚餐前的每一天,火鸡都应该是活的很不错的,它的一生里没有任何过去的经验供它预测到自己未来的结果,而后果是致命的。
一套复杂的 IT 系统,很有可能就是那只火鸡,例如就个人近年所遭遇的类似事件最典型的两次,一是与某机构对接的技术接口,据称已经存在并稳定使用近 10 年 – 虽然技术古老但是从未出现问题,然而在过去两年持续创新高的交易量压力之下,问题终究以最无法想象到的方式出现并形成系统性风险(因为对接者不仅一两家);另一,则是老旧的系统因对市场可交易股票数目作了假设(而从未被发现),某天新股上市数量超过一定值而导致部分交易功能无法正常进行。
这两个例子都符合黑天鹅特征,一是“史无前例” (如果以前发生过,问题早就被处理了),二是可以“事后诸葛亮”(所有 IT 系统问题,最后不都可以归结为“一个愚蠢的 bug” ?因为开发时需求不清楚、因为开发者粗心、因为技术系统所处的生态环境已经发生变化导致原假设无效…),三是“后果严重”(如果技术系统本身是一个广被采购的第三方的商业软件,则整个行业都有受灾可能;如果是自研发的技术,则最起码对交易投资者造成灾难性损失)。
事实上,资本市场乃至金融业整体,可能都是黑天鹅最爱光顾的地方。甚至连普罗大众都听过的例子诸如:2010 年 5 月 6 日的 Flash Crash – 在三十分钟内道琼斯指数狂泻近千点、1987 年 10 月 19 日的 Black Monday、国内著名的“乌龙指”事件导致的市场剧动… 不一而足。
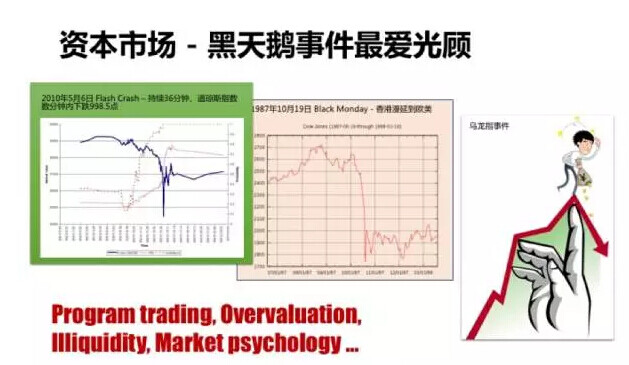
导致黑天鹅降临的原因,事后分析五花八门,可能是量化交易导致的、可能是市场流动性不足引起的、也可能是市场心理(例如恐慌抛售)触发的… 无论何者,IT 系统几乎都是最后被压垮的那只骆驼。正如塔勒布文章中提到,高盛在 2007 年 8 月的某天突然经历的为平常 24 倍的交易量,如果到了 29 倍,系统是否就已经坍塌了?

事实上,在这个日益数字化的世界,本身就高度数字化的证券市场,面临的黑天鹅事件会越来越多,出于但不仅限于以下一些因素:
- 增长的交易规模。
- 更高频、更复杂的交易算法(《高频交易员》一书里指出,股票市场已经变成机器人之间的战争)。
- 更全球化更加波动 – 海内外政治经济情况引起的突发变化。
- 更快速更先进的技术 – 已经出现数百纳秒内完成交易处理的专门性硬件芯片,快到人类根本无法响应。
据一篇科技论文(Financial black swans driven by ultrafast machine ecology) 的数据,人类国际象棋大师对棋盘上局势危机的判断大概需要 650 毫秒,而日常人类活动中通常的反应起码是秒级的;但是在一个高频交易的世界里,一笔交易可能在极速硬件的支持下只需要万分之几毫秒完成。人类,已经无法轻易掌控自己的交易算法在极速之下带来的问题、更无法了解自己的算法和他人的算法在交易市场上相互作用的集合带来的后果、甚至无法预测突发性政治经济事件对自身算法、技术、系统会触发何种反应。
数字世界,尤其是金融业的数字世界,正好是塔勒布笔下所谓的”极端斯坦“(Extremistan),它完全不受物理世界的规律影响 – 一切极端皆有可能。例如在物理世界常识告诉我们,一个数百斤的超级胖子的体重加到 1000 人里面比重依然是可以忽略不计的;但在金融世界,一个比尔盖茨级别的富豪的财产数字,富可敌国。
金融 IT,正好生存在这么一个”极端斯坦“ – 这里复杂系统内部充满难以察觉的相互依赖关系和非线性关系,这里概率分布、统计学的”预测“往往不再生效。塔勒布称之为”第四象限“,我们,作为证券交易的 IT,刚好在这个象限里谋生。

(塔勒布《黑天鹅》第四象限图)
上述这一切,和云计算有什么关系呢? 我们觉得非常紧密,逻辑如下:
- 世界越来越数字化、更加“数目字可管理”- 一切效率更高。
- 本来就数字化的金融世界,日益是个“极端斯坦”,只能更快、更复杂,面临更多黑天鹅事件。
- 应对数字世界的黑天鹅,只能用数字世界的手段(而不是“人肉”手工方法),就像《黑客帝国》,你必须进入 Matrix,用其中的武器和手段,去解决里面的问题(并影响外面)。
- 云计算,不过是世界数字化进程里的一步 – 把承载数字世界的物理载体也进一步数字化,但是它刚好是我们应对数字黑天鹅的基本工具 – 运算资源本身也是“数目字可管理”,并且正因为如此而可以是自动的和智能的。
即便到了今天,相信很多企业、机构的机房里的运算资源,依然不是“数目字可管理” – 这本身真是一个讽刺。但直到云技术出现,才解决这个问题。结合云计算的技术,交易系统不再是“your grandmother‘s trading system”。
“反脆弱”的技术系统
黑天鹅事件是不可预测的,但是并非不可应对。《黑天鹅》的作者塔勒布,在其另一本有巨大影响力的著作《反脆弱》(Anti-Fragile)里,提到了如何在不确定中获益。这本闪烁着智慧之光的著作,早已超越了金融而进入到政治、经济、宗教、社会学的思考范畴,对 IT 系统技术架构的设计,同样具有启发意义。想想,一个经常被黑天鹅事件光顾的交易系统,如果不仅没有坍塌、还随着每一次的考验而技术上变的越来越周全和强壮,这对于任何开发工程师、运维工程师来说,是不是一个梦想成真?
实际上,这个过程对于任何 IT 工程师而言都是非常熟悉的,因为我们中很多人每天的工作,可能就是在不断的以各种应急手段紧急救援不堪重负的生产系统、或者在线弥补技术缺陷,在这过程中我们发现一个又一个在开发和测试时没有发现的问题、一次又一次推翻自己在开发时的各种假设、不断解决所遭遇到的此前完全没有想象过的场景。如果项目、系统活下来了,显然它变得更加健壮强韧。
只不过,这一切是被动的、低效的、“人肉”的,而且视系统架构和技术而定,变强韧有时是相对容易的、有时则是不可能的 – 正如一艘结构设计有严重缺陷的船,打更多的补丁也总会遇到更大的浪把它打沉。
如果基于《反脆弱》的三元论,也许大部分 IT 系统大致上可以这么看:
- 脆弱类:绝大部分企业 IT 系统,依赖于大量技术假设与条件,不喜欢无序和不稳定环境,暴露于负面“黑天鹅”中。
- 强韧类:小部分大规模分布式系统(也许通常是互联网应用),适应互联网相对不可控的环境(如网络延迟与稳定性、客户端设备水平和浏览器版本、用户量及并发请求变化),经受过海量用户与服务请求的磨练,相对健壮。
- 反脆弱类:能捕捉到正面“黑天鹅”- 系统不仅在冲击中存活,并且变的更加强韧,甚至在这过程中获益。
这里所谓的“脆弱”,并不是指系统不可靠、单薄、技术不堪一击,而是指这类系统厌恶变化、厌恶不稳定不可控环境、本身架设在基于各种稳定性假设前提的精巧设计上,无法对抗突如其来的、此前无法循证的事件(黑天鹅),更无法从中自适应和壮大。就这个角度看,证券行业甚至整个金融业里,大部分的系统可能都是脆弱系统。传统 IT 系统有以下一些常见的技术特点,例如:
- 一切以关系型数据库为中心(RDBMS-centric)。
- 很多历史遗留系统(legacy system)有数以百计的表、数以千计的存储过程。
- 业务逻辑高度依赖数据库。
- 中间层与数据层高度紧耦合。
- 多层架构(multi-tiered architecture),层与层之间依赖于高度的约定假设(协议 -protocol、接口 - API、数据格式 – data format 等等),并且这些约定经常来不及同步(例如某个团队改变了维护的接口而没有通知其他团队、或者数据库的表结构改变了但是中间层的对象库因为疏忽而没有及时步调一致的重构),有些约定甚至只存在于协作的开发者脑海中而没有形成文档(即便形成文档也经常因需求变化频繁而无法及时更新)。
- 应用程序依赖于某些第三方的代码库,而这些代码库很有可能依赖于某个版本的操作系统及补丁包,并且这种依赖关系是传递的 – 例如某个第三方代码库依赖于另一个第三方代码库而该库依赖于某个版本的操作系统…
- 系统设计,往往没有考虑足够的失败场景(因此可能完全没有容错机制),没有考虑例如不稳定网络延迟对业务逻辑的影响(例如大部分企业系统都假设了一个稳定的 LAN)。
- 组件、模块、代码库、操作系统、应用程序、运维工具各版本之间具有各种线性、非线性依赖关系,形成一个巨大的复杂系统。
然而,以下这些变化是任何 IT 系统所不喜欢却无法回避的,例如:
- 多层架构里,任何一个环节的约定独立发生细微改变,必定导致系统出错(只是严重性大小的差别),这几乎无法很好的避免 – 研发团队的素质不够高、软件工程的水平低、瞬息万变的市场导致的频繁更改等等,总是客观存在。
- 因为安全原因,需要对操作系统进行打补丁或者升级,导致应用程序所依赖的代码库发生兼容性问题 – 在打补丁或升级后通过测试及时发现兼容问题已经算是幸运的,最怕是在生产环境运行过程中才触发非线性关系的模块中的隐患。
- 跨系统(尤其是不同团队、部门、组织负责的系统)的调用协议与接口发生变化,是一个常态性的客观事实。
- 互联网环境、甚至企业内部的网络环境,并不是一成不变的,网络拓扑出于安全、合规隔离、性能优化而变化,可能导致延迟、吞吐等性能指标的变化,应用系统本来没有出现的一些问题,有可能因为运行环境的变化而浮现,而系统内部容错机制往往没有考虑到这些问题。
- 业务需求永远在变,以数据库为中心的系统,不可避免产生表结构(schema)调整,系统升级需要做数据迁移,而这总是有风险的(例如 data integrity 需要保证万无一失)。
于是,传统 IT 对于这些系统的运维,最佳实践往往不得不这样:
- 在使用压力增大的情况下,最安全的升级手段是停机、换机器、加 CPU、加内存,直到硬件升级、垂直扩容(vertical scale、or scale-up)手段用光。
- 维护一个庞大的运维团队,随时救火。
- 试图通过软件工程的管理,例如制定规章制度,让协作人员、团队之间在接口升级前走流程、互相通知,来避免随意的系统变化导致的风险。
- 加大测试力度 – 通常很有可能是投入更多的人肉测试资源,以保证较高的测试覆盖率和回归测试(regression test)能力。
- 强调“纪律”,以牺牲效率为代价,通过“流程”、“审核”设置重重关卡以达到“维稳”效果。
- 重度隔离运维与研发,禁止研发人员触碰生产环境,减少误操作 – 例如随意升级操作系统、对应用逻辑抱着侥幸心理打补丁等等。
不可否定,这些“套路”在以往的时代可能是最佳实践,也体现了一个 IT 组织的管理水平。但是毫无疑问,这样研发、运维和管理的系统,是一个典型的“脆弱系统”,它依赖于很多的技术、工具、环境、流程、纪律、管理制度、组织结构,任何一个环节出现问题,都可能导致轻重不一的各种问题。最重要一点,这样的系统,厌恶变化、喜好稳定,无法在一个“只有变化才是唯一不变”(并且是变化越来越频繁)的世界里强韧存活,更无所谓拥抱变化而生长。
强韧类的技术系统,情况要好的多,起码能“响应”变化(如后文所论述)。但是注意,在塔勒布的定义里,“强韧”并非“脆弱”的反面,“强韧系统”只是能相对健壮的对抗更大的压力、更苛刻的环境,它并不能从变化、不确定中获益。“脆弱”的反面,塔勒布在现有语言里找不到一个合适的词语,所以他发明了一个新概念,“反脆弱”(Anti-Fragile)。问题是,接受“变化是一种常态”、拥抱变化并从中获益的“反脆弱”的技术系统,能被构建出来吗?
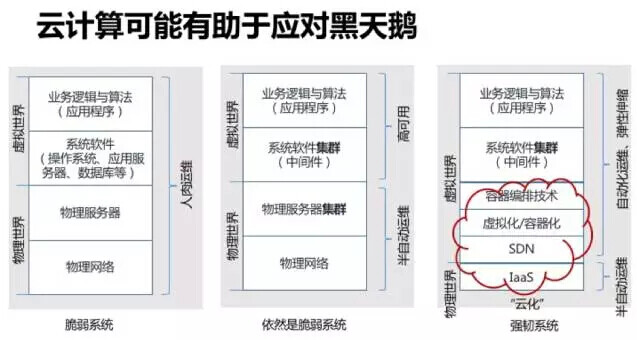
云计算的出现,有利于帮助 IT 构建强韧系统,并且让“反脆弱”系统成为可能。其最根本原因在于,云计算本身是机房物理设施数字化的过程,如上文所述,数字世界的黑天鹅 – 微秒、纳秒内发生的极端事件,只能通过数字化手段才能高效解决。伴随云计算出现的是 DCOS(Data Center Operating System)、APM(Application Performance Monitoring)、Infrastructure As Code(基础设施即代码、可编程运维、可编程基础设施…)、DevOps 等等技术方案、技术产品、技术理念和方法论。这些都是构建强韧系统的有力武器,而在云计算时代之前,它们严格意义上不曾存在过。
到此为止,本文想立论的,是云计算相关技术的出现,对于金融类尤其是交易系统意义重大,技术架构必须调整以利用之,对于构建强韧的、甚至潜在有“反脆弱”能力的系统,有极大帮助。云技术、尤其是容器化技术出现后,金融软件系统的研发与运维面貌将被极大的改变。
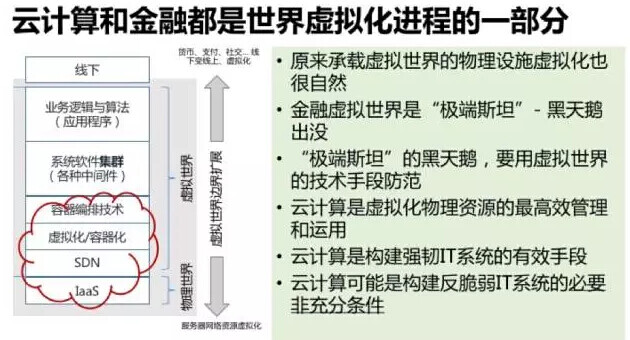
云计算也许是目前为止对于证券交易系统、甚至对于更广义的金融技术系统而言最适合应对黑天鹅的技术手段。监管机构不应该见到“云”字就敏感的与“公有云”、信息安全、交易可监管性等问题联系起来;金融机构则需要与时俱进的学习掌握“云化”的技术手段、架构思维 – 至于系统是运行在公有云、私有云还是混合云,都已经是另一个故事。
未完待续。
作者介绍
梁启鸿,哥伦比亚大学计算机科学系毕业,出道于纽约 IBM T.J. Watson 研究院,后投身华尔街,分别在纽约 Morgan Stanley、Merrill Lynch 和 JP Morgan 等投行参与交易系统研发。本世纪初加入 IT 界,在 Sun Microsystems 大中华区专业服务部负责金融行业技术解决方案。此后创建游戏公司并担任 CTO 职位 5 年。后作为雅虎 Senior Principal Architect 加入雅虎担任北京研究院首席架构师角色。
三年前开始厌倦了框架、纯技术的研发,开始寻找互联网前沿技术与线下世界、传统行业的结合;目前回归金融业负责前端技术、大数据、云计算在互联网金融、股票交易系统的应用。
个人兴趣是把前沿的互联网技术应用到垂直行业中,做一点能改变传统面貌的、最重要是有趣好玩又有用的事情;紧跟 Go、Docker、Node.js、AngularJS 这些技术但更关注如何把技术用到应用场景里,从中获得乐趣。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




