
前言
本文是 Hadoop 最佳实践系列第二篇,上一篇为《 Hadoop 管理员的十个最佳实践》。
MapRuduce 开发对于大多数程序员都会觉得略显复杂,运行一个 WordCount(Hadoop 中 hello word 程序)不仅要熟悉 MapRuduce 模型,还要了解 Linux 命令(尽管有 Cygwin,但在 Windows 下运行 MapRuduce 仍然很麻烦),此外还要学习程序的打包、部署、提交 job、调试等技能,这足以让很多学习者望而退步。
所以如何提高 MapReduce 开发效率便成了大家很关注的问题。但 Hadoop 的 Committer 早已经考虑到这些问题,从而开发了 ToolRunner、MRunit(MapReduce 最佳实践第二篇中会介绍)、MiniMRCluster、MiniDFSCluster 等辅助工具,帮助解决开发、部署等问题。举一个自己亲身的例子:
某周一和搭档 (结对编程) 决定重构一个完成近 10 项统计工作的 MapRuduce 程序,这个 MapReduce(从 Spring 项目移植过来的), 因为依赖 Spring 框架 (原生 Spring,非 Spring Hadoop 框架), 导致性能难以忍受,我们决定将 Spring 从程序中剔除。重构之前程序运行是正确的,所以我们要保障重构后运行结果与重构前一致。搭档说,为什么我们不用 TDD 来完成这个事情呢?于是我们研究并应用了 MRunit,令人意想不到的是,重构工作只用了一天就完成,剩下一天我们进行用 findbug 扫描了代码,进行了集成测试。这次重构工作我们没有给程序带来任何错误,不但如此我们还拥有了可靠的测试和更加稳固的代码。这件事情让我们很爽的同时,也在思考关于 MapReduce 开发效率的问题,要知道这次重构我们之前评估的时间是一周,我把这个事情分享到 EasyHadoop 群里,大家很有兴趣,一个朋友问到,你们的评估太不准确了,为什么开始不评估 2 天完成呢?我说如果我们没有使用 MRUnit,真的是需要一周才能完成。因为有它单元测试,我可以在 5 秒内得到我本次修改的反馈,否则至少需要 10 分钟(编译、打包、部署、提交 MapReduce、人工验证结果正确性),而且重构是个反复修改,反复运行,得到反馈,再修改、再运行、再反馈的过程,MRunit 在这里帮了大忙。
相同智商、相同工作经验的开发人员,借助有效的工具和方法,竟然可以带来如此大的开发效率差距,不得不让人惊诧!
PS. 本文基于 Hadoop 1.0(Cloudera CDH3uX)。本文适合读者:Hadoop 初级、中级开发者。
1. 使用 ToolRunner 让参数传递更简单
关于 MapReduce 运行和参数配置,你是否有下面的烦恼:
- 将 MapReduce Job 配置参数写到 java 代码里,一旦变更意味着修改 java 文件源码、编译、打包、部署一连串事情。
- 当 MapReduce 依赖配置文件的时候,你需要手工编写 java 代码使用 DistributedCache 将其上传到 HDFS 中,以便 map 和 reduce 函数可以读取。
- 当你的 map 或 reduce 函数依赖第三方 jar 文件时,你在命令行中使用”-libjars”参数指定依赖 jar 包时,但根本没生效。
其实,Hadoop 有个 ToolRunner 类,它是个好东西,简单好用。无论在《Hadoop 权威指南》还是 Hadoop 项目源码自带的 example,都推荐使用 ToolRunner。
下面我们看下 src/example 目录下 WordCount.java 文件,它的代码结构是这样的:
public class WordCount { // 略... public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // 略... Job job = new Job(conf, "word count"); // 略... System.exit(job.waitForCompletion(true) ? 0 : 1); } }
WordCount.java 中使用到了 GenericOptionsParser 这个类,它的作用是将命令行中参数自动设置到变量 conf 中。举个例子,比如我希望通过命令行设置 reduce task 数量,就这么写:
bin/hadoop jar MyJob.jar com.xxx.MyJobDriver -Dmapred.reduce.tasks=5
上面这样就可以了,不需要将其硬编码到 java 代码中,很轻松就可以将参数与代码分离开。
其它常用的参数还有”-libjars”和 -“files”,使用方法一起送上:
bin/hadoop jar MyJob.jar com.xxx.MyJobDriver -Dmapred.reduce.tasks=5 \ -files ./dict.conf \ -libjars lib/commons-beanutils-1.8.3.jar,lib/commons-digester-2.1.jar
参数”-libjars”的作用是上传本地 jar 包到 HDFS 中 MapReduce 临时目录并将其设置到 map 和 reduce task 的 classpath 中;参数”-files”的作用是上传指定文件到 HDFS 中 mapreduce 临时目录,并允许 map 和 reduce task 读取到它。这两个配置参数其实都是通过 DistributeCache 来实现的。
至此,我们还没有说到 ToolRunner,上面的代码我们使用了 GenericOptionsParser 帮我们解析命令行参数,编写 ToolRunner 的程序员更懒,它将 GenericOptionsParser 调用隐藏到自身 run 方法,被自动执行了,修改后的代码变成了这样:
public class WordCount extends Configured implements Tool { @Override public int run(String[] arg0) throws Exception { Job job = new Job(getConf(), "word count"); // 略... System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCount(), args); System.exit(res); } }
看看代码上有什么不同:
- 让 WordCount 继承 Configured 并实现 Tool 接口。
- 重写 Tool 接口的 run 方法,run 方法不是 static 类型,这很好。
- 在 WordCount 中我们将通过 getConf() 获取 Configuration 对象。
关于 GenericOptionsParser 更多用法,请点击这里: GenericOptionsParser.html
推荐指数:★★★★
推荐理由:通过简单的几步,就可以实现代码与配置隔离、上传文件到 DistributeCache 等功能。修改 MapReduce 参数不需要修改 java 代码、打包、部署,提高工作效率。
2. 有效使用 Hadoop 源码
作为 MapReduce 程序员不可避免的要使用 Hadoop 源码,Why?记得 2010 刚接触 hadoop 的时候,总是搞不清旧 api 和新 api 的使用方法。写了一段程序,在一个新 api 里面调用某个方法每次都是返回 Null,非常恼火,后来附上源码发现,这个方法真的就是只做了“return null”并没有给予实现,最后只得想其它方法曲线救国。总之要想真正了解 MapReduce 开发,源码是不可缺少的工具。
下面是我的源码使用实践,步骤有点麻烦不过配置一次就好:
1. Eclipse 中创建 Hadoop 源码项目
1.1 下载并解压缩 Hadoop 分发包(通常是 tar.gz 包)
1.2 Eclipse 中新建 Java 项目
1.3 将解压后 hadoop 源码包 /src 目录中 core, hdfs, mapred, tool 几个目录(其它几个源码根据需要进行选择)copy 到 eclipse 新建项目的 src 目录。
1.4 右键点击 eclipse 项目,选择“Properties”,在弹出对话框中左边菜单选择“Java Build Path”:
a) 点击“Source”标签。先删除 src 这个目录,然后依次添加刚才 copy 过来的目录
b) 点击当前对话框“Libaries”,点击“Add External JARs”,在弹出窗口中添加 $HADOOP_HOME 下几个 hadoop 程序 jar 包,然后再次添加 $HADOOP_HOME /lib、$HADOOP_HOME /lib/jsp-2.1 两个目录下所有 jar 包,最后还要添加 ANT 项目 lib 目录下 ant.jar 文件。 1.5 此时源码项目应该只有关于找不到 sun.security 包的错误了。这时我们还是在“Libraries”这个标签中,展开 jar 包列表最低下的“JRE System Library”,双击”Access rules”,在弹出窗口中点击“add 按钮”,然后在新对话框中"Resolution"下拉框选择"Accessible","Rule Pattern"填写 _*/_,保存后就 OK 了。如下图:
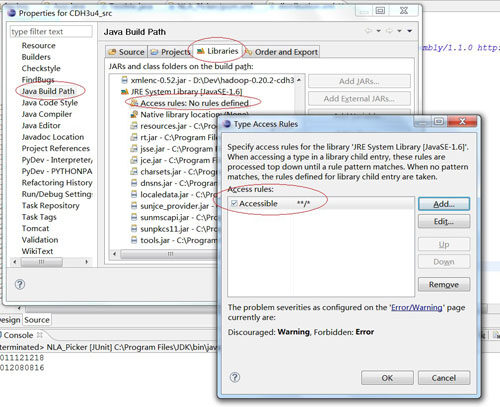
2. 如何使用这个源码项目呢?
比如我知道 Hadoop 某个源码文件的名称,在 eclipse 中可以通过快捷键“Ctrl + Shift + R”调出查找窗口,输入文件名,如“MapTask”,那可以打开这个类的源码了。
还有个使用场景,当我们编写 MapReduce 程序的时候,我想直接打开某个类的源码,通过上面的操作还是有点麻烦,比如我想看看 Job 类是如何实现的,当我点击它的时候会出现下面的情景:
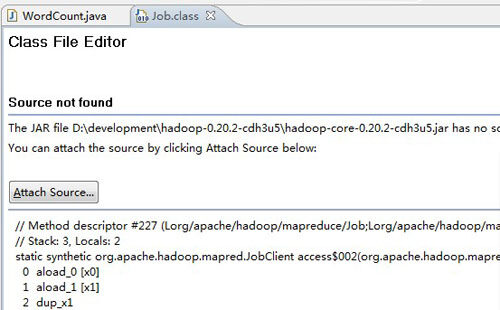
解决办法很简单:
点击图中“Attach Source”按钮 -> 点击“Workspace”按钮 -> 选择刚才新建的 Hadoop 源码项目。完成后源码应该就蹦出来了。
总结一下,本实践中我们获得了什么功能:
- 知道 hadoop 源码文件名,快速找到该文件
- 写程序的时候直接查看 Hadoop 相关类源码
- Debug 程序的时候,可以直接进入源码查看并跟踪运行
推荐指数:★★★★
推荐理由:通过源码可以帮助我们更深入了解 Hadoop,可以帮助我们解决复杂问题
3. 正确使用压缩算法
下表资料引用 cloudera 官方网站的一篇博客,原文点这里。
Compression File Size(GB) Compression Time (s) Decompression Time (s) None some_logs 8.0 - - Gzip some_logs.gz 1.3 241 72 LZO some_logs.lzo 2.0 55 35 上面表格与笔者集群实际环境测试结果一致,所以我们可以得出如下结论:
- LZO 文件的压缩和解压缩性能要远远好于 Gzip 文件。
- 相同文本文件,使用 Gzip 压缩可以比 LZO 压缩大幅减少磁盘空间。
上面的结论对我们有什么帮助呢?在合适的环节使用合适压缩算法。
在中国的带宽成本是非常贵的,费用上要远远高于美国、韩国等国家。所以在数据传输环节,我们希望使用了 Gzip 算法压缩文件,目的是减少文件传输量,降低带宽成本。使用 LZO 文件作为 MapReduce 文件的输入(创建 lzo index 后是支持自动分片输入的)。对于大文件,一个 map task 的输入将变为一个 block,而不是像 Gzip 文件一样读取整个文件,这将大幅提升 MapReduce 运行效率。
主流传输工具 FlumeNG 和 scribe 默认都是非压缩传输的(都是通过一行日志一个 event 进行控制的),这点大家在使用时要注意。FlumeNG 可以自定义组件方式实现一次传输多条压缩数据,然后接收端解压缩的方式来实现数据压缩传输,scribe 没有使用过不评论。
另外值得一提的就是 snappy,它是由 Google 开发并开源的压缩算法的,是 Cloudera 官方大力提倡在 MapReduce 中使用的压缩算法。它的特点是:与 LZO 文件相近的压缩率的情况下,还可以大幅提升压缩和解压缩性能,但是它作为 MapReduce 输入是不可以分割的。
延伸内容:
Cloudera 官方 Blog 对 Snappy 介绍:
http://blog.cloudera.com/blog/2011/09/snappy-and-hadoop/
老外上传的压缩算法性能测试数据:
推荐指数:★★★★★
推荐理由:压缩率和压缩性能一定程度是矛盾体,如何均衡取决于应用场景。使用合适压缩算法直接关系到老板的钱,如果能够节省成本,体现程序员的价值。
4. 在合适的时候使用 Combiner
map 和 reduce 函数的输入输出都是 key-value,Combiner 和它们是一样的。作为 map 和 reduce 的中间环节,它的作用是聚合 map task 的磁盘,减少 map 端磁盘写入,减少 reduce 端处理的数据量,对于有大量 shuffle 的 job 来说,性能往往取决于 reduce 端。因为 reduce 端要经过从 map 端 copy 数据、reduce 端归并排序,最后才是执行 reduce 方法,此时如果可以减少 map task 输出将对整个 job 带来非常大的影响。
什么时候可以使用 Combiner?
比如你的 Job 是 WordCount,那么完全可以通过 Combiner 对 map 函数输出数据先进行聚合,然后再将 Combiner 输出的结果发送到 reduce 端。
什么时候不能使用 Combiner?
WordCount 在 reduce 端做的是加法,如果我们 reduce 需求是计算一大堆数字的平均数,则要求 reduce 获取到全部的数字进行计算,才可以得到正确值。此时,是不能使用 Combiner 的,因为会其会影响最终结果。 注意事项:即使设置 Combiner,它也不一定被执行(受参数 min.num.spills.for.combine 影响),所以使用 Combiner 的场景应保证即使没有 Combiner,我们的 MapReduce 也能正常运行。
推荐指数:★★★★★
推荐理由:在合适的场景使用 Combiner,可以大幅提升 MapReduce 性能。
5. 通过回调通知知道 MapReduce 什么时候完成
你知道什么时候 MapReduce 完成吗?知道它执行成功或是失败吗?
Hadoop 包含 job 通知这个功能,要使用它非常容易,借助我们实践一的 ToolRunner,在命令行里面就可以进行设置,下面是一个例子:
hadoop jar MyJob.jar com.xxx.MyJobDriver \ -Djob.end.notification.url=http://moniter/mapred_notify/\$jobId/\$jobStatus
通过上面的参数设置后,当 MapReduce 完成后将会回调我参数中的接口。其中 $jobId 和 $jobStatus 会自动被实际值代替。
上面在 $jobId 和 $jobStatus 两个变量前,我添加了 shell 中的转义符”\”,如果使用 java 代码设置该参数是不需要转义符的。
总结下:看看我们通过该实践可以获得什么?
- 获取 MapReduce 运行时间和回调完成时间,可以分析最耗时 Job,最快完成 Job。
- 通过 MapReduce 运行状态(包括成功、失败、Kill),可以第一时间发现错误,并通知运维。
- 通过获取 MapReduce 完成时间,可以第一时间通过用户,数据已经计算完成,提升用户体验
Hadoop 这块功能的源码文件是 JobEndNotifier.java,可以马上通过本文实践二看看究竟。其中下面两个参数就是我通过翻源码的时候发现的,如果希望使用该实践赶紧通过 ToolRunner 设置上吧(别忘了加 -D,格式是 -Dkey=value)。
- job.end.retry.attempts // 设置回调通知 retry 次数
- job.end.retry.interval // 设置回调时间间隔,单位毫秒
当然如果 hadoop 没有提供 Job 状态通知的功能,我们也可以通过采用阻塞模式提交 MapReduce Job,然后 Job 完成后也可以获知其状态和运行时间。
推荐指数:★★★
推荐理由:对 mapreduce job 监控最省事有效的办法,没有之一。
作者介绍:
张月,EasyHadoop 技术社区志愿者,Java 程序员,7 年工作经验。2007 年加入蓝汛 ChinaCache 至今,目前从事 Hadoop 相关工作。关注敏捷和海量数据领域,关注效率。博客: heipark.iteye.com , 微博: @张月 _ 痛苦的信仰。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论