

V8 引入全新的非优化 JS 编译器:Sparkplug
想要编写高性能的 JavaScript 引擎,光是有高度优化的编译器(如 TurboFan)是不够的。特别是对于短生命周期的会话(例如加载网站或命令行工具),在高优化编译器开始优化之前就已经有很多工作要做,更没有时间去生成什么优化代码了。
正因如此,自 2016 年起,我们不再跟踪综合基准测试(如 Octane)的成绩,而是转而去衡量实际场景中的性能表现。并且从那时起,我们就一直在努力研究如何提升高优化编译器作用范围之外的 JavaScript 性能。这意味着我们需要在解析器、流式处理、对象模型、垃圾收集中的并发性、缓存编译后的代码等事项上逐个攻关……每一个领域都有新鲜的感觉。
当我们转向提升现实场景中初始 JavaScript 的执行性能,我们在优化解析器时开始遇到诸多局限。V8 的解析器经过高度优化,速度极快,但解析器总有一些固有开销是我们无法摆脱的;字节码解码开销或调度开销是解析器功能的内在组成部分。
基于我们目前的双编译器模式,我们很难更快地升级(tier-up)到优化代码;我们可以(并且正在)提升优化的效果,但在某些时候,想要提升速度就只能去掉一些优化项,但这会降低峰值性能。更糟糕的是,我们还无法提前优化进程,因为我们还没有稳定的对象形态反馈。
今天我们向大家介绍 Sparkplug:这是我们将随 V8 v9.1 发布的,全新的非优化 JavaScript 编译器,位于 Ignition 解析器和 TurboFan 优化编译器之间。

新的编译器管道
这是一款速度很快的编译器
Sparkplug 的设计目标是快速编译。非常快,如此之快,让我们可以随时随地进行编译,于是我们就可以比 TurboFan 代码更积极地升级到 Sparkplug 代码。
Sparkplug 编译器的速度来自于一些技巧。首先,它会作弊;它所编译的函数已经被编译为字节码,并且字节码编译器已经完成了大多数艰苦的工作,例如变量解析、弄清楚括号是否实际上是箭头函数、消除结构化语句等等。Sparkplug 从字节码而不是 JavaScript 源代码进行编译,因此不必操心这些麻烦的事情。
第二招是,Sparkplug 不会像大多数编译器那样生成任何中间表示(IR)。相反,Sparkplug 通过字节码的一次线性 pass 直接编译为机器码,并发出与该字节码的执行相匹配的代码。实际上,整个编译器是一个 for 循环内的一个 switch 语句,分派给固定的,按字节码的机器码生成函数。
缺少 IR 意味着编译器的优化机会有限,只能做一些非常本地的小幅度优化。这也意味着我们必须将整个实现分别移植到我们支持的每种架构上,因为这里没有架构无关的中间阶段。但事实证明这些都不是问题:快速编译器是简单编译器,因此代码很容易移植;并且 Sparkplug 不需要大量优化,因为我们稍后会在管道中提供优化效果很出色的编译器。
从技术上讲,我们目前对字节码进行了两次 pass——一次用来发现循环,第二次生成实际代码。不过,我们最终的计划是摆脱第一个。
解析器兼容框架
向现有的成熟 JavaScript VM 添加新的编译器是一项艰巨的任务。除了标准执行之外,你还需要支持各种各样的事情;V8 有一个调试器、一个 stack-walking CPU profiler、针对异常的堆栈跟踪、集成到升级、堆栈替换以优化代码实现热循环……实在很多。
Sparkplug 巧妙地简化了所有这些问题,具体方法就是保持一个“与解析器兼容的堆栈框架”。
稍微解释下。堆栈框架(Stack frame)是代码执行存储函数状态的方式。每当你调用一个新函数时,它都会为该函数的局部变量创建一个新的堆栈框架。一个堆栈框架由一个框架指针(标记其开始)和一个堆栈指针(标记其结束)定义:
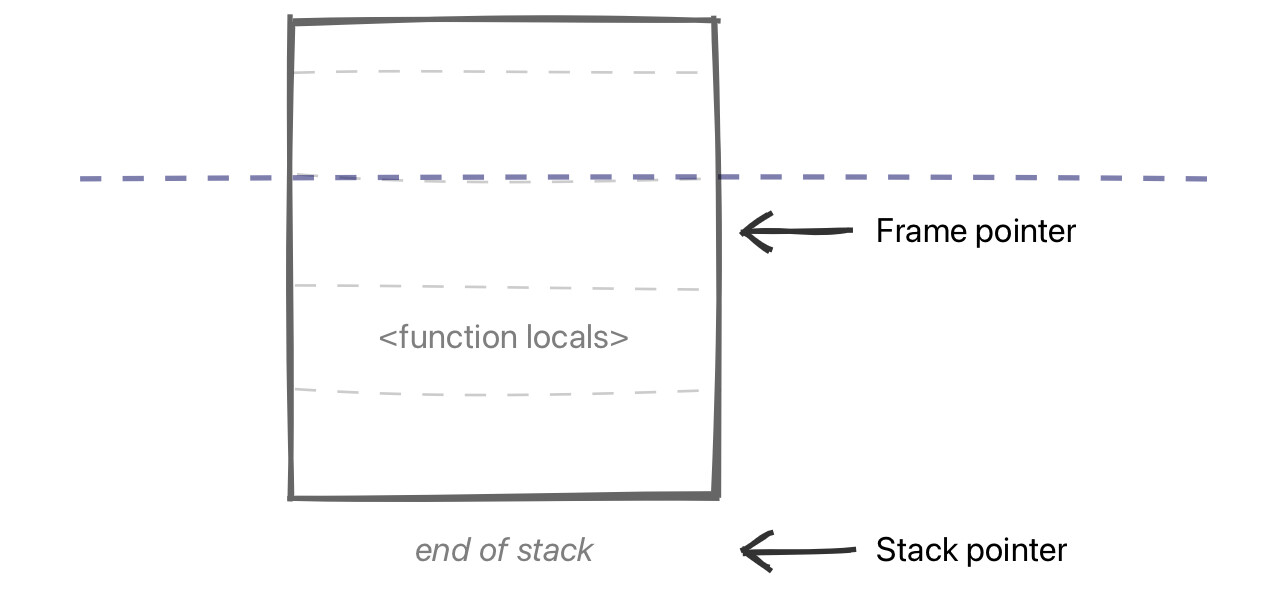
堆栈框架,带有堆栈和框架指针
看到这里,很多读者会表示抗议:“这张图不对啊,堆栈明显是朝着相反的方向的!”。别急,我为你做了一个按钮:
当一个函数被调用时,返回地址被推入这个堆栈;该函数返回时会弹出它,来知道该返回到何处。然后,当该函数创建一个新框架时,它将旧的框架指针保存在堆栈上,并将新的框架指针设置为指向它自己的堆栈框架的起始。因此,这个堆栈有了一个框架指针链,每个框架指针都指向前一个框架的起始:
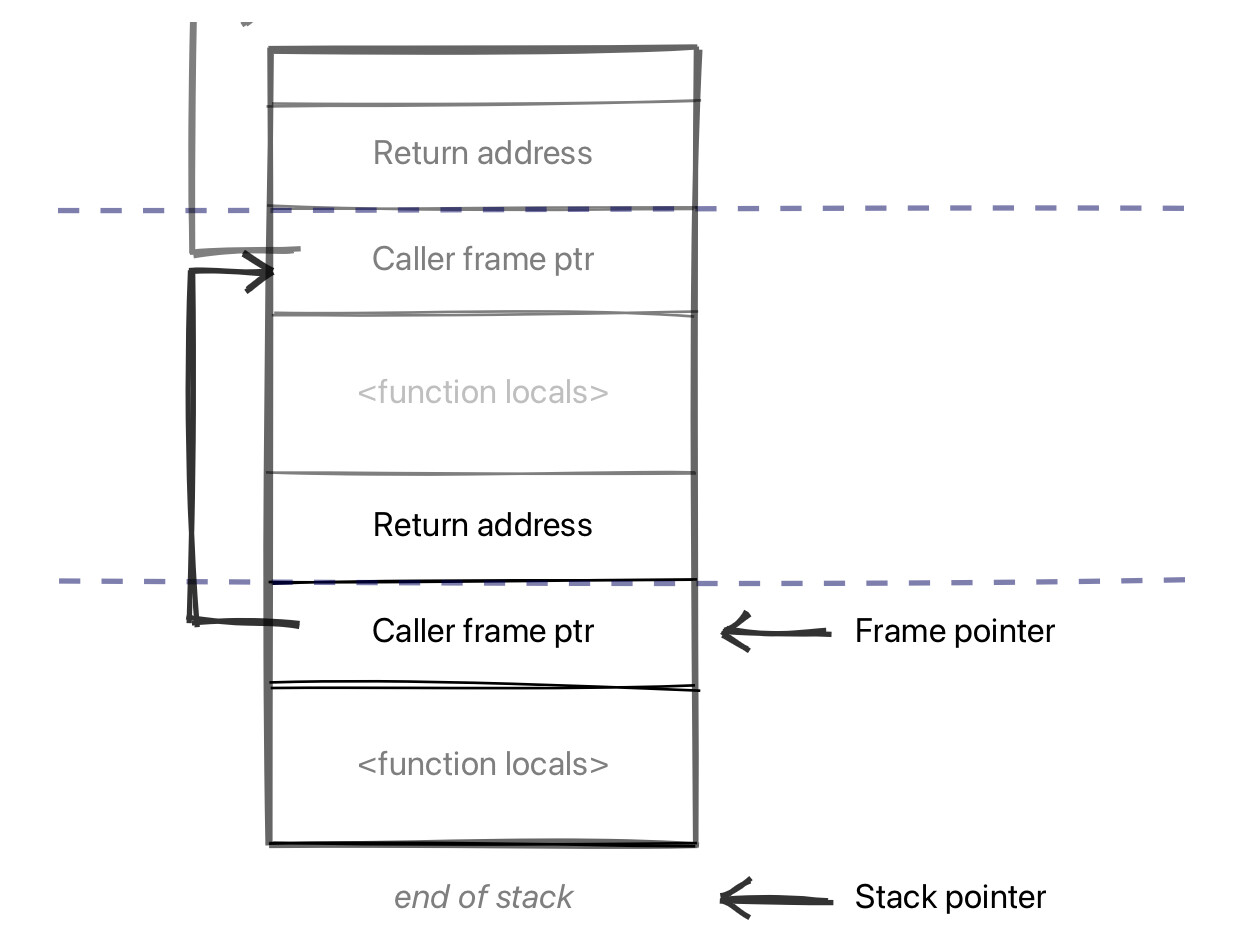
多个调用的堆栈框架
严格来说这只是一个约定,后面是生成的代码,它不是必需的。不过这是一种相当常见的方式;唯一真正中断的一次是堆栈框架完全清除的时候,或者可以改用调试边表(side-table)遍历堆栈框架的时候。
这是针对所有函数类型的常规堆栈布局;然后是关于如何传递参数,以及函数如何在其框架中存储值的约定。在 V8 中,我们有针对 JavaScript 框架的约定,即在调用函数之前将参数(包括接收器)以相反的顺序推入堆栈,并且堆栈上的前几个槽为:被调用的当前函数;被调用的上下文;以及传递的参数数量。这是我们的“标准”JS 框架布局:
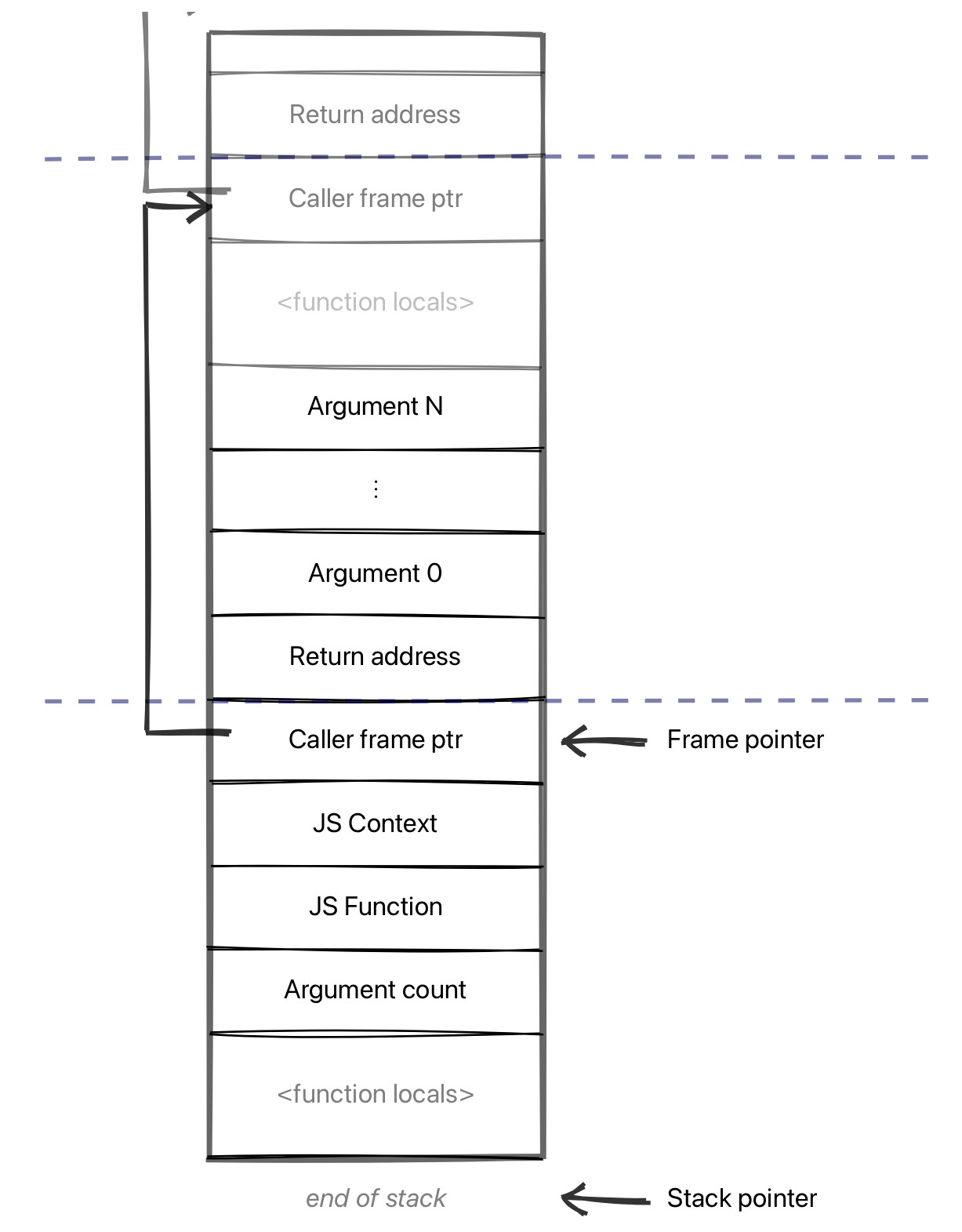
一个 V8 JavaScript 堆栈框架
这个 JS 调用约定在优化框架和解析框架之间共享,这样一来,当我们在调试器的性能面板中调优代码时,就能以最小的开销遍历堆栈,诸如此类。
对于 Ignition 解析器来说,约定变得更加显式。Ignition 是基于寄存器的解析器,这意味着存在一些虚拟寄存器(请勿与机器寄存器混淆!)来存储解析器的当前状态——其中包括 JavaScript 函数的本地变量(var/let/const 声明)和临时值。这些寄存器与要执行的字节码数组指针,以及该数组中当前字节码的偏移量一起存储在解析器的堆栈框架中:
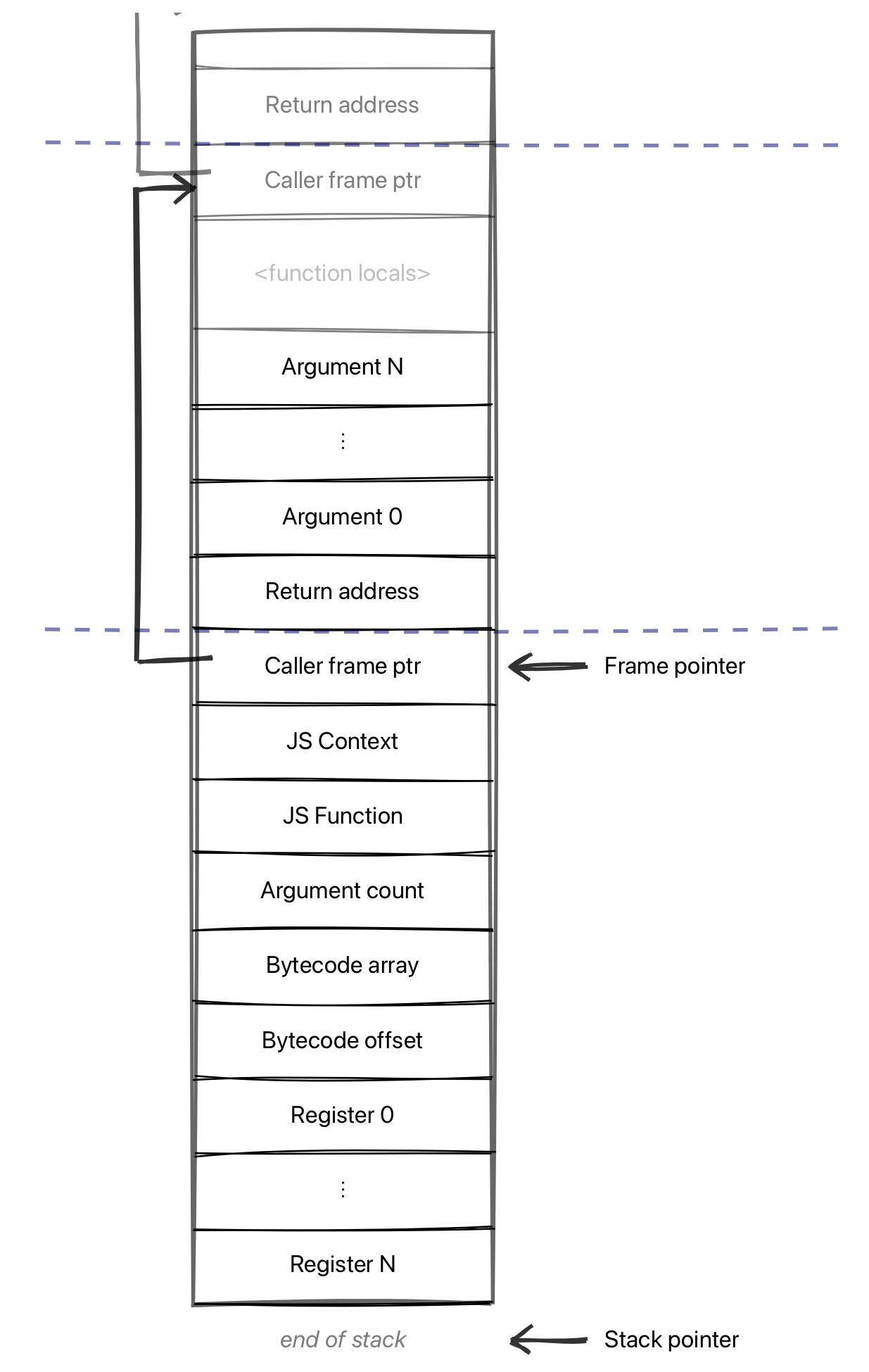
V8 解析器堆栈框架
Sparkplug 会有意创建并维护一个与解析器的框架相匹配的框架布局;只要解析器存储一个寄存器值,Sparkplug 也会存储一个值。这样做有几个原因:
它简化了 Sparkplug 的编译过程;Sparkplug 可以只镜像解析器的行为,而无需保留从解析器寄存器到 Sparkplug 状态的某种映射。
由于字节码编译器完成了分配寄存器的重活儿,因此它还加快了编译速度。
它大大简化了与系统其余部分的集成工作。调试器、profiler、异常堆栈展开、堆栈跟踪打印,所有这些操作都会执行堆栈遍历以发现当前正在执行的函数堆栈,并且所有这些操作都不需要做什么更改就能继续搭配 Sparkplug,因为就它们而言,它们有的只是一个解析器框架。
它简化了堆栈替换(OSR)。OSR 是指在执行过程中替换当前正在执行的函数;当前,当一个已解析函数在一个热循环内(在该循环中它升级为优化代码),以及在优化代码取消优化(在其降级并继续在解析器中执行该函数)时,就会发生这种情况。使用 Sparkplug 框架镜像解析器框架时,任何适用于解析器的 OSR 逻辑都将适用于 Sparkplug;更棒的是,我们可以在解析器和 Sparkplug 代码之间切换,而框架转换开销几乎为零。
我们对解析器堆栈框架做了一个小更改,即在 Sparkplug 代码执行期间,我们不让字节码偏移保持最新。相反,我们存储一个从 Sparkplug 代码地址范围到对应的字节码偏移量的双向映射。这是一种相对简单的编码映射,因为 Sparkplug 代码是直接从字节码上的一个线性遍历发出的。每当一个堆栈框架访问想要知道一个 Sparkplug 框架的“字节码偏移量”时,我们都会在此映射中查找当前执行的指令,并返回相应的字节码偏移量。类似地,每当我们想将 OSR 从解析器转换为 Sparkplug 时,我们都可以在映射中查找当前字节码偏移量,然后跳转到相应的 Sparkplug 指令。
你可能会注意到,我们现在在堆栈框架上有一个未使用的插槽,字节码偏移量就会在这个插槽上。由于我们希望保持堆栈的其余部分不变,因此我们不能放弃它。我们重新调整了这个堆栈插槽的功能,让它为当前正在执行的函数缓存“反馈向量”。这是用于存储对象形态数据的向量,大多数操作都需要加载它。我们要做的只是谨慎一点对待 OSR,确保我们为这个插槽要么换入正确的字节码偏移量,要么换入正确的反馈向量。
于是 Sparkplug 堆栈框架为:
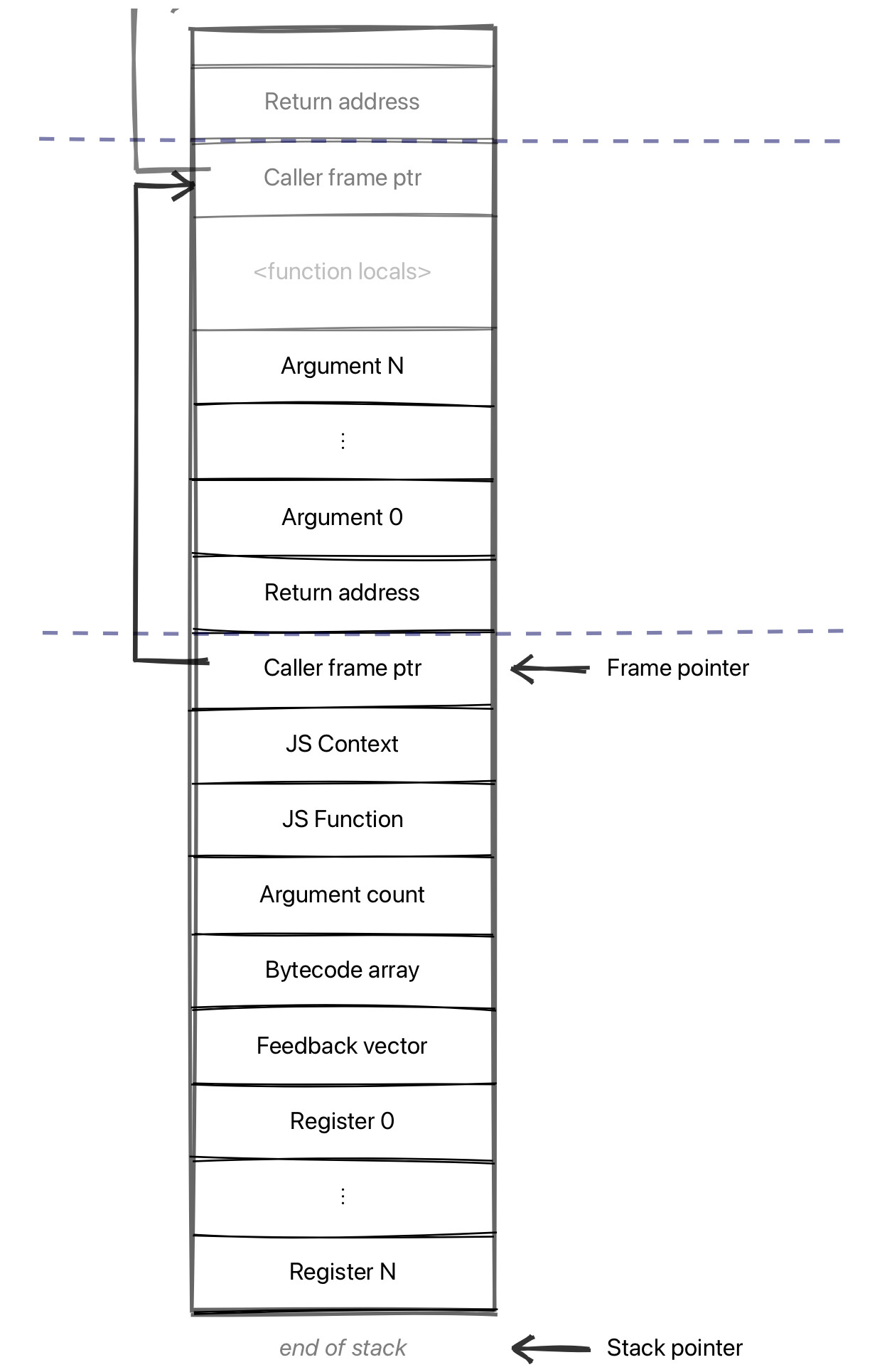
一个 V8 Sparkplug 堆栈框架
交给内置代码
实际上,Sparkplug 很少生成自己的代码。JavaScript 语义很复杂,即使执行最简单的操作也需要大量代码。由于多种原因,强制 Sparkplug 在每次编译时内联重新生成这些代码都是不好的:
由于需要生成大量代码,这将明显增加编译时间,
这会增加 Sparkplug 代码的内存消耗,并且
我们必须重新实现用于 Sparkplug 的一堆 JavaScript 功能的代码源,这可能意味着会有更多的错误和更大的受攻击面。
因此,大多数 Sparkplug 代码只是调用“内置代码”,即嵌入二进制文件中的小段机器码片段,以完成那些脏活儿。这些内置代码要么就是解析器用的那些,或者至少与解析器的字节码处理程序共享大部分代码。
实际上,Sparkplug 代码基本上只是内置代码的调用和控制流:
你现在可能会想,“那么,这一切到底有什么意义?Sparkplug 不是在做与解析器相同的工作吗?”——你的疑问是有道理的。在许多方面,Sparkplug 只是解析器执行的一个序列化,它调用相同的内置函数并维护相同的堆栈框架。但这样做也是值得的,因为它消除(或更准确地说是预编译)了那些不可移动的解析器开销,例如操作数解码和下一个字节码分派。
事实证明,解析器破坏了许多 CPU 优化工作:解析器从内存中动态读取静态操作数,从而迫使 CPU 停顿或推测值可能是多少。分派到下一个字节码需要成功的分支预测才能保持高性能,即使推测和预测正确,你还是要执行所有解码和分派代码,并且你还是会在各个缓冲区和缓存中浪费宝贵的空间。CPU 实际上本身就是一个解析器,只不过它是机器码的解析器。这样看来,Sparkplug 是从 Ignition 字节码到 CPU 字节码的一个“转译器”,将你的函数从在“仿真器”中运行移到了“原生”运行。
性能表现
那么,Sparkplug 在现实场景中的性能表现如何呢?我们用 Chrome M91 跑了一些基准测试,用了几个性能 bot,分别启用和关闭 Sparkplug 来观察其影响。
剧透:我们非常满意。
以下基准测试列出了运行多个操作系统的 bot。虽说系统和 bot 的名字差不多,但我们认为它并不会对结果产生太大影响。另外,不同的机器也有不同的 CPU 和内存配置,我们认为这是差异的主要来源。
Speedometer
Speedometer 是一个基准测试,它使用一些流行的框架构建一个 TODO 列表跟踪 Web 应用程序,并通过添加和删除 TODO 对应用程序进行性能压力测试,来模拟现实世界中网站框架的使用情况。我们发现它很好地反映了现实世界中的负载和互动行为,并且我们屡屡发现,Speedometer 的成绩提升反映在了我们的现实世界指标中。
使用 Sparkplug,Speedometer 得分提高 5-10%,具体取决于我们观察的 bot。
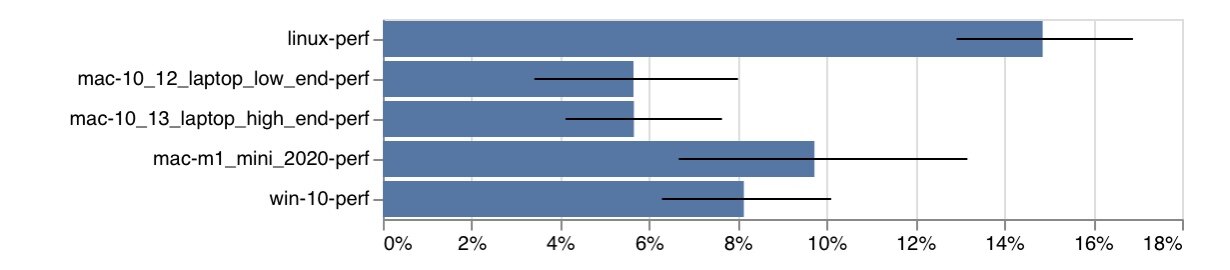
使用 Sparkplug 在多个性能 bot 中改善了 Speedometer 的得分中位数。误差线表示四分位间距。
浏览基准测试
Speedometer 是一个很好的基准测试,但它只反映了部分情况。此外,我们还有一组“浏览基准测试”,它们记录了一组真实的网站,我们可以重播这些内容、编写一些交互脚本,并更真实地了解我们的各种指标在现实世界中的表现。
在这些基准测试上,我们选择查看“V8 主线程时间”指标,其测试主线程(不包括流解析或后台优化的编译)在 V8 中花费的总时间(包括编译和执行)。这是在不排除其他基准噪声源的情况下查看 Sparkplug 自身回报的最佳方法。
结果各不相同,并且完全取决于机器和网站,但总体而言它们看起来不错:我们看到大约有 5-15%的改进。
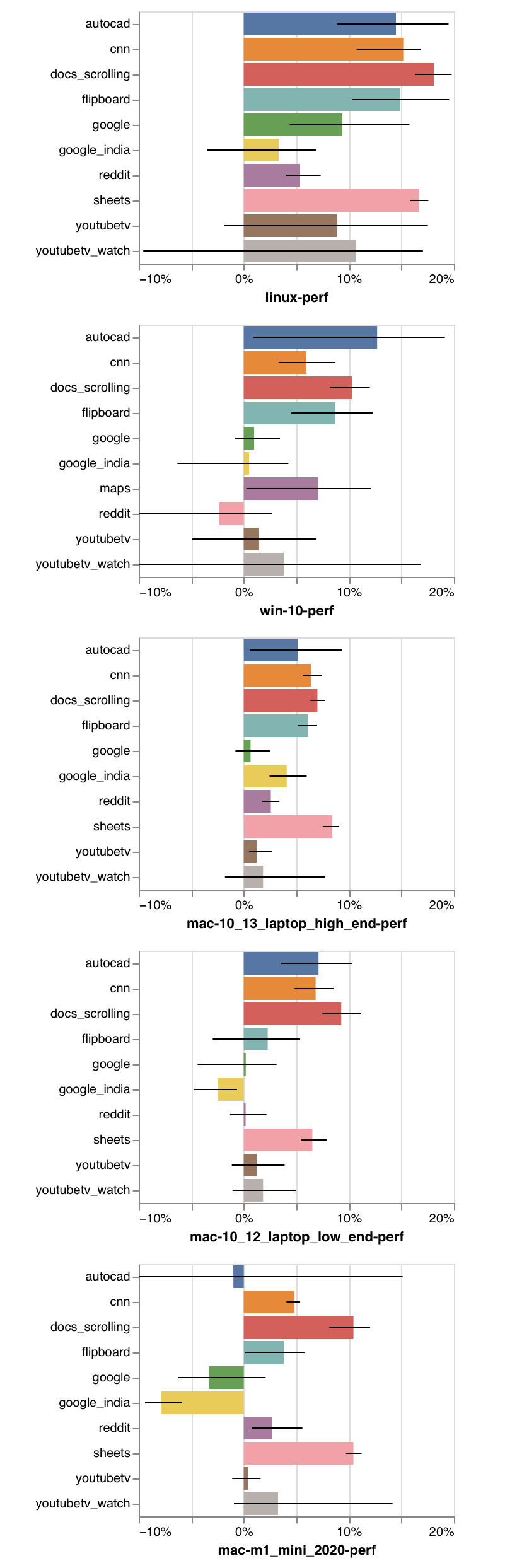
在我们的浏览基准测试中,V8 主线程时间得到了 10 个百分点的中位数改进。误差线表示四分位间距。
结论:V8 有了全新的超快速非优化编译器,可将 V8 在实际基准测试中的性能提高 5-15%。V8 v9.1 中已经在--sparkplug 标志后面提供了这一工具,并且随着 M91 的发布,我们将在 Chrome 中推出该编译器。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论