
对电子邮件服务的用户来说,邮箱容量早已不是值得关心的问题,几乎所有主流邮件服务商都提供了容量大到很少有人能用完的服务。然而对服务商来说,尽可能降低成本,提升系统,尤其是存储系统的使用效率总是很好的。考虑到很多用户会收到大量包含相同内容的邮件,如相同的邮件附件,或邮件内相同的图片,一些邮件服务商开始考虑采用去重技术将相同文件只保存一份,借此提高存储效率。
俄罗斯最受欢迎的邮件服务商之一 Mail.Ru,自行设计实现了一套邮件存储去重系统,在不影响性能的前提下,将包含 120 亿个邮件内嵌文件的存储系统占用量从原本的 50PB 缩减至 32PB。一起来看看他们的这套系统是如何实现的。
两年前,随着俄罗斯卢布汇率下跌,我们开始考虑缩减 Mail.Ru 邮件服务的硬件和托管成本。为了设法省钱,先来看看我们的邮件是由什么组成的。

索引和正文只占到总存储量的 15%,另外 85% 都是各种文件。因此有必要对文件(其实也就是邮件附件)进行进一步分析,并找出优化的方法。当时我们并没有使用文件去重技术,但是估计这种技术可将存储总量减少 36%,因为很多用户会收到相同的邮件,如网店的报价单,包含图像等内容的社交网络新闻邮件等。本文将介绍我们在 Albert Galimov 的监管下实现去重系统的方法。
元数据存储
文件总量越来越多,我们需要能快速识别重复内容。一种简单的做法是根据内容为文件生成名称。为此我们使用了 SHA-1 算法,文件的原始名称存储在邮件内容中,因此无须担心原始名称的问题。
收到新邮件后,系统会先获取该文件,计算出哈希值,然后将结果加入到邮件信息中。这是为了在发送邮件时轻松确定以后的存储系统中,每个文件对应着具体哪封邮件而必须采取的步骤。
试试看上传一个文件到存储系统,然后看看相同哈希值的文件是否已经存在。这就意味着我们必须将所有文件哈希都存储起来。就把这个存储叫做哈希 FileDB 吧。

同样的文件可以附加到不同邮件中,因此我们需要通过计数器记录包含同一份文件的邮件数量。
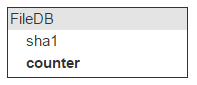
每当上传新文件,该计数器的数字会递增。所有文件中约有 40% 的文件会被删除,因此如果用户删除的邮件中包含已经上传至云端的文件,计数器的数字还必须递减。如果计数器归零,对应的文件才会被真正删除。
接下来我们遇到了第一个问题:有关邮件的信息(索引)存储在一个系统中,有关文件的信息则存储在另一个系统中。这可能会造成一个问题,例如请考虑下面的流程:
- 系统接到删除某封邮件的请求。
- 系统检查邮件索引。
- 系统容可以看到邮件有一个附件(SHA-1)。
- 系统发送删除该文件的请求。
- 因为程序崩溃,这封邮件并未实际删除。
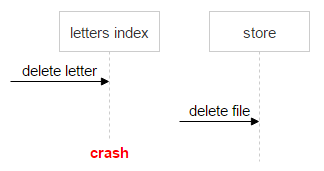
此时邮件依然位于系统中,但计数器的数字已经减小了“1”。当系统收到删除该邮件的第二个请求,计数器的数字继续减小,因此可能面临这样的局面:文件依然附加在某封邮件中,但计数器已经归零了。
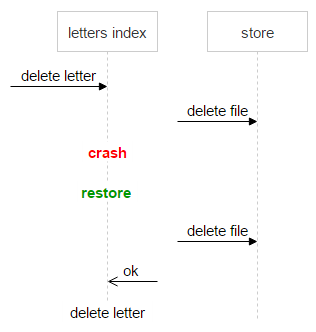
避免数据丢失是最基本的要求。我们不能让用户打开一封邮件后发现自己的附件丢了。也就是说,在磁盘上存储一些冗余的文件也没什么大不了的。我们只需要一种算法,能够明确地决定计数器的“归零”是否为正确的结果。所以我们额外建立了一个名为 Magic 的字段。
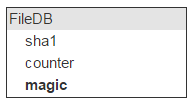
该算法很简单。除了文件哈希,我们还会在邮件中存储一个随机生成的数字。所有上传湖哦删除文件的请求都需要考虑这个随机数:对于上传请求,会将该数字添加至 Magic 数的当前值中;对于删除请求,则会从 Magic 数的当前值中减去这个随机数。
因此如果所有邮件增加或减少计数器数值的操作次数是正确的,Magic 数将等于“零”。否则文件不会被删除。
用一个例子来看看。有个名为 sha1 的文件,被上传了一次,邮件生成了一个随机(Magic)数,假设等于 345。

随后收到一封包含相同文件的新邮件。该邮件生成了自己的 Magic 数(123)并上传了文件。新的 Magic 数会与 Magic 数的当前值(345)相加,计数器的数字增加 1。因此现在 FileDB 中的 Magic 数值为 468,计数器数字为 2。
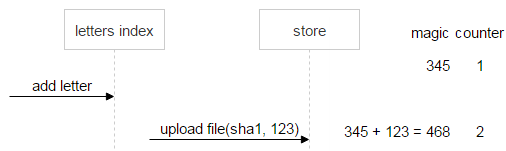
用户删除第二封邮件后,将从 Magic 数的当前值(468)中减去第二封邮件的 Magic 数,计数器数字也减 1。
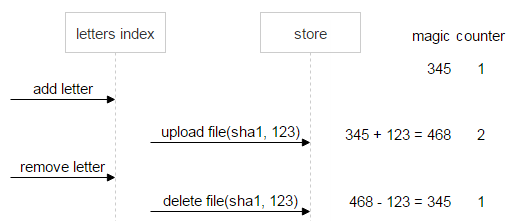
先看看正常过程。用户删除了第一封邮件,Magic 数和计数器数字都归零。这意味着数据是一致的,可以删除文件。

接下来,假设出错了:第二封邮件发送了两个删除请求。计数器归零意味着已经没有邮件链接至该文件,但 Magic 数此时等于 222,意味着出问题了:数据变得一致之前,文件不会被删除。
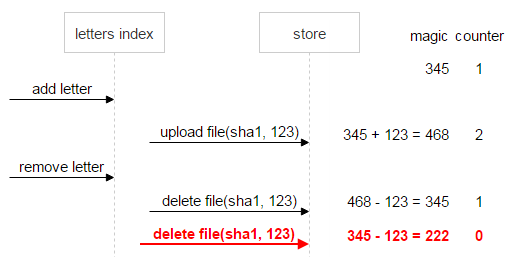
把这种情况进一步延展一下。假设第一封邮件也被删除了,此时 Magic 数(-123)依然意味着不一致。
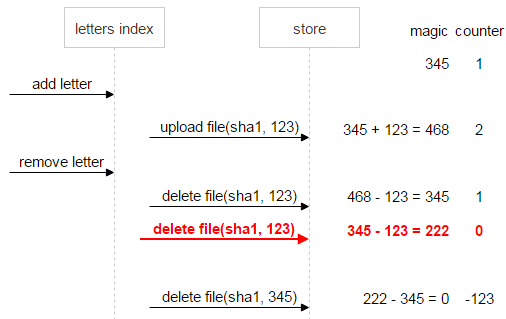
作为一项安全措施,一旦计数器归零但 Magic 数没有归零(本例中计数器归零时 Magic 数值为 222),文件将会添加“不要删除”标签。通过这种方法,就算在处理了一系列删除和上传操作,Magic 数和计数器都归零后,我们依然可以知道该文件有问题,不应删除。
重新回到 FileDB。每个项都有一组标志。无论用户是否主动使用,实际上都用得上(例如要将文件标记为不可删除)。
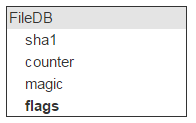
除了物理位置外,我们可以掌握文件的所有特性。物理位置是由服务器(IP)和磁盘决定的。服务器和磁盘可能个有两组。
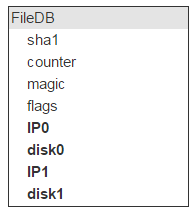
但每块磁盘会存储大量文件(我们的实例中,大约存储了 1,000,000 个文件),这也意味着这些记录可以通过 FileDB 中同一个磁盘对加以区分,那么也就没必要将其存储在 FileDB 中了。可以把它们放在一个单独的表:PairDB 中,随后通过磁盘对 ID 链接至 FileDB。
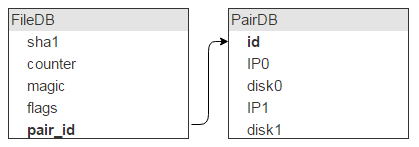
不言而喻,除了磁盘对 ID,我们还需要一个标志字段。先提起说一下,这个字段意味着磁盘是否被锁定(例如一个磁盘崩溃,需要从另一个进行复制,这样新数据才不会写入到这两个磁盘中)。
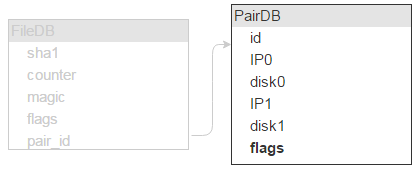
此外还需要知道每个磁盘有多少可用空间,因此也需要相应的字段。
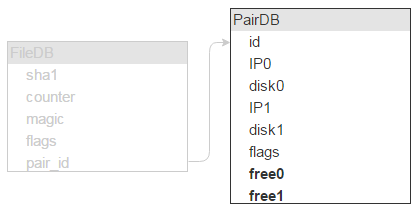
为了让一切尽可能快速运行,FileDB 和 PairDB 都必须位于内存中。我们原本使用了 Tarantool 1.5,但现在应该已经在使用最新版了。FileDB 有五个字段(长度分别为 20、4、4、4、4 字节),总长度 36 字节。此外每条记录都有一个 16 字节的头部,外加每字段 1 字节长度的指针,因此每条记录的总长度为 57 字节。

Tarantool 允许指定最小分配大小,因此与内存有关的开销可以接近于零。我们会为每条记录严格分配刚好够用的内存数量。我们共有 12,000,000,000 个文件,因此:
(57 * 12 * 10⁹) / (1024³) = 637 GB
但这还没完,还需要为 sha1 字段提供索引,因此每条记录的总长度需要额外增加 12 字节,因此:
(12 * 12 * 10⁹) / (1024³) = 179 GB
所以我们一共需要 800GB 内存。但是别忘了还要复制,因此所需内存数量需要翻倍。

如果使用装备 256GB 内存的服务器,这样的机器一共需要八台。
我们还可以评估 PairDB 的大小。文件的平均大小为 1MB,磁盘容量平均为 1TB,因此一块硬盘平均可存储大约 1,000,000 个文件,那么我们需要 28,000 块硬盘。每条 PairDB 记录描述了两块磁盘,因此 PairDB 包含 14,000 条记录,相比 FileDB 实在是微不足道。
文件上传
确定了数据库结构后,需要考虑与系统交互的 API 了。首先,我们需要确定 Upload 和 Delete 方法。但是别忘了还要去重:有一定概率打算上传的文件已经位于存储系统中,此时就没必要重新上传了。因此需要具备下列方法:
- inc(sha1, magic) — 负责计数器的递增。如果文件不存在则返回错误。别忘了我们还需要一个防止文件被错误删除的 Magic 数。
- upload(sha1, magic) —将可在 inc 返回错误后调用。意味着该文件不存在,需要上传。
- dec(sha1, magic) — 将在用户删除一封邮件后调用,并首先减小计数器的数字。
- GET /sha1 — 通过 HTTP 下载文件。
一起来深入看看上传过程中会发生什么事。在实现该接口的守护进程中,我们选择了 IProto 协议。守护进程必须能灵活缩放至任意数量的服务器,因此不能存储状态。假设通过 Socket 收到了一个请求:

通过命令名称可以了解头部的长度,因此我们首先读取头部。随后我们需要知道 origin-len 文件的长度,并据此选择要将文件上传到的服务器。通过 PairDB 获取所有记录(几千条)并使用标准算法查找需要的对:选择长度与所有对的可用空间总量相等的片段,在这个片段中随机选取一点,并选择该点所属的对。
然而用这种方式选择对有一定的风险。假设所有磁盘均 90% 满载,随后添加了几块新磁盘。有很大可能性所有新文件会被上传至新增的磁盘。为避免这种情况,我们不应计算磁盘对的可用空间总和,而要计算该可用空间的方根。
至此已经选择了一个对,但我们的守护进程是流式的,如果开始将文件上传至存储,将没有回头路。也就是说,在实际开始上传文件之前,我们会首先上传一个很小的测试文件。如果测试文件成功上传,则会从 Socket 中读取文件内容,并将其上传至存储。否则会选择另一个对。SHA-1 哈希可以即时读取,因此可在上传的同时进行计算。
再看看从加载程序(Loader)将文件上传至所选磁盘对的情况。在包含该这些磁盘的机器上,我们设置了 Nginx 并使用了 WebDAV 协议。邮件抵达后,FileDB 还没有相应的文件,因此需要通过加载程序上传至磁盘对。
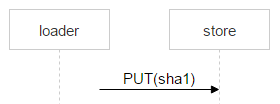
但这并不会妨碍到其他用户收到相同邮件:假设有两个收件人,需要注意,此时 FileDB 还没有拿到这个文件,因此将由另一个加载程序上传这个文件,并可能选择上传至同一个磁盘对。
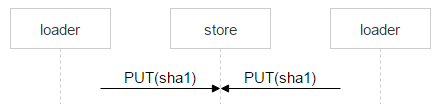
Nginx 通常会正确解决这种问题,但我们需要对整个过程进行控制,因此使用一个复杂的名称保存该文件。
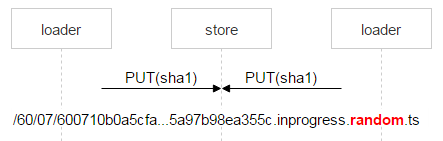
文件名中红色部分是每个加载程序放入的随机数。借此可确保两个 PUT 方法不会重叠,进而导致上传两个不同的文件。一旦 Nginx 响应了 201 (OK) 信息,第一个加载程序会执行一个原子级的 MOVE 操作,并指定文件的最终名称。
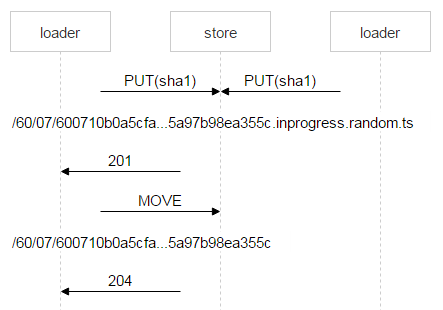
第二个加载程序完成文件上传操作并执行 MOVE 后,文件会被覆写,但这算不得什么大问题,因为文件始终都是那一个。文件位于磁盘上之后,会向 FileDB 加入一条新记录。我们所用的 Tarantool 版本被分为两个空间,我们目前只使用了 space0。
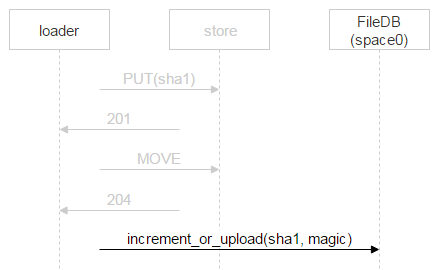
然而我们并不是简单地向 FileDB 新增一条记录,而是会使用存储过程让文件计数器数字增加,或向 FileDB 添加新记录。为什么这样做?当加载程序确定 FileDB 中不存在该文件,随后上传文件内容并通过处理给 FileDB 中新增加一条记录的全过程中,其他人可能已经上传了该文件并添加了对应的记录。上文的例子曾经考虑过这种问题:两个收件人收到了同一封邮件,因此两个加载程序开始上传文件,一旦第二个加载程序先行上传完成,将会通过处理向 FileDB 中添加新记录。
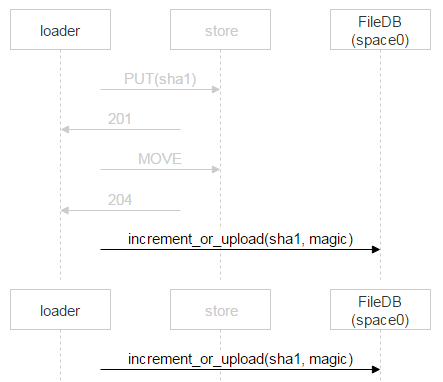
此时第二个加载程序会让文件计数器的数字增加。
然后再来看看 dec 方法。我们的系统有两个高优先级任务:可靠地将文件写入磁盘,以及从磁盘快速交付给客户端。文件的物理删除会产生一定的工作负载,导致这两个任务变慢。因此删除操作实际上是脱机进行的。Dec 方法本身可以让计数器减小。如果随后计数器和 Magic 数都归零,意味着已经没人需要该文件了,因此我们会在 Tarantool 中将相应的记录从 space0 移动至 space1。
decrement (sha1, magic){ counter-- current_magic –= magic if (counter == 0 && current_magic == 0){ move(sha1, space1) } } {1}
Valkyrie
每个存储都使用一个 Valkyrie 守护进程监视数据完整性和一致性,这些工作会针对 space1 进行。每个磁盘有一个守护进程实例,该守护进程会对磁盘上的所有文件进行迭代,并检查 space1 是否包含与特定文件对应的记录,如果有则意味着该文件需要删除。
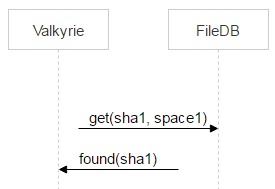
但在调用 dec 方法并将文件移动至 space1 之后,Valkyrie 可能需要花一些时间才能找到该文件。这意味着在两个事件之间的时段内,文件有可能被重新上传并重新移动回 space0。
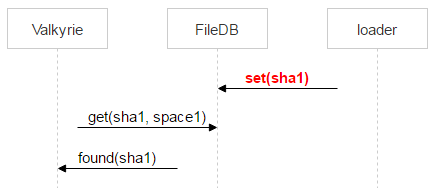
因此 Valkyrie 还会检查文件是否位于 space0 中。如果找到了,并且对应记录的 pair_id 指向运行了 Valkyrie 实例的磁盘对,记录会从 space1 中删除。
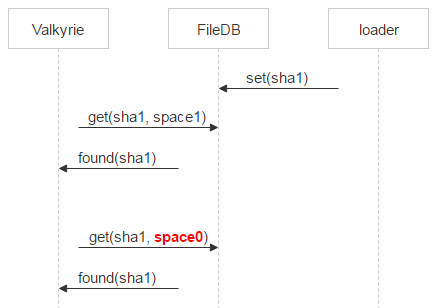
如果 space0 中未找到记录,那么即可考虑将文件删除。然而在向 space0 发送请求直到文件被物理删除,这期间依然有一定概率遇到该文件对应的新记录重新出现在 space0 的情况。此时我们会将文件隔离。
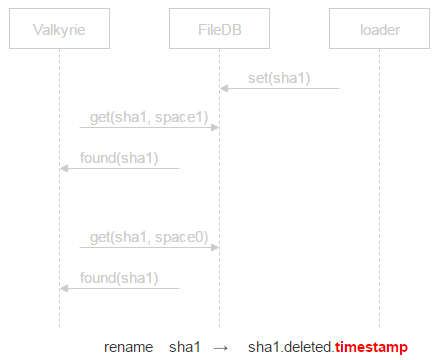
此时并不删除文件,而是在文件名中加入“已删除”标记和时间戳。这意味着我们会在时间戳对应的时间延后一个时间量(延后多久可由配置文件决定)后物理删除该文件。如果程序崩溃文件被误删除,用户还有机会找回文件。我们可以在不丢失任何数据的情况下恢复文件并解决这些问题。
还记得吗,上文提到共有两块磁盘,每块都运行一个 Valkyrie 实例。这两个实例并不同步,因此问题来了:什么时候把记录从 space1 中删除?
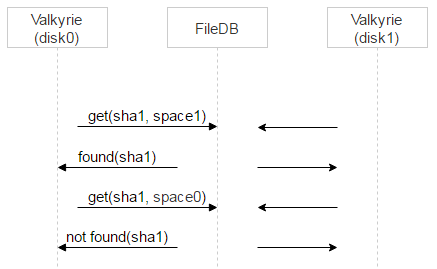
我们会做两件事。首先,对于有问题的文件,首先将一个 Valkyrie 实例设置为主,通过文件名的第一比特很容易做到:如果等于 0,disk0 是主,否则 disk1 是主。
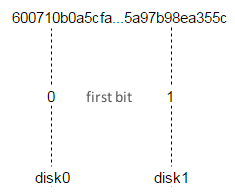
然后再引入一个延迟处理。上文提到过,当记录位于 space0 时,其中包含了用于检查一致性的 Magic 字段。当记录移动至 space1 后,并未使用该字段,因此我们用带包记录出现在 space1 中的时间设置了一个时间戳。借此主 Valkyrie 实例将立刻处理 space1 中的记录,从实例则会根据时间戳添加一定的延迟,等待片刻再处理并删除 space1 中的记录。
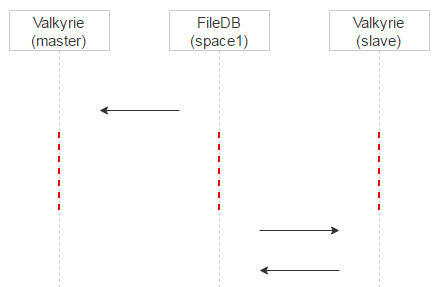
这种方法带来了另一个好处:如果主实例中的文件被错误地放入隔离区,只要查询主实例的日志就能确认。同时请求该文件的客户端可以回退(Fall Back)至从实例,用户依然可以获得所需的文件。
至此已经考虑过 Valkyrie 守护进程找到名为 sha1 的文件,并且该文件(可以考虑将其删除)在 space1 中有对应的记录。是否还存在其他可能的情况?
假设某个文件位于磁盘上,但 FileDB 中没有相应的记录。如果按照上述情况,主 Valkyrie 实例出于某种原因停止工作较长时间,就意味着从实例已经有足够的时间将文件放入隔离区并从 space1 中删除对应的记录。此时我们也会使用 sha1.deleted.timestamp 将该文件放入隔离区。
另一种情况:存在一条记录,但指向的是不同的磁盘对。这种情况可能出现在两个收件人收到同一封邮件并进行上传的过程中。请回忆一下上文提到的规划。
如果第二个加载程序将该文件上传到与第一个加载程序不同的磁盘对会怎样?space0 中计数器的数字会变大,但文件上传到的磁盘对会包含一些垃圾文件。我们需要确保这些文件可读取并且与 sha1 匹配。如果一切正常,此类文件可立刻删除。
另外 Valkyrie 可能会遇到某些被放入隔离区的文件。如果隔离时间已到,该文件依然会被删除。
接下来假设 Valkyrie 遇到一个正常的文件。它需要从磁盘读取,检查完整性并与 sha1 对比。随后 Valkyrie 需要查询第二个磁盘,看看是否存在相同文件。这里使用最简单的 HEAD 方法就够了:第二个磁盘运行的守护进程本身就能检查完整性。如果第一个磁盘上的文件损坏,则会立刻从第二个磁盘上复制。如果第二个磁盘不包含该文件,则可以从第一个磁盘上复制。
还有最后一种与磁盘问题有关的情况。如果系统监视过程中发现任何磁盘出现问题,有问题的磁盘会被置于维护(只读)模式,此时将通过第二个磁盘执行 UNMOVE 操作。借此可以有效地将所有文件分散在其他磁盘对的第二块磁盘上。
结果
回到开头处提到的问题,我们的邮件存储系统以前是这样的:
通过实现新的系统,存储占用总量缩减了 18PB:

现在邮件占用 32PB(25% 为索引,75% 为文件)。由于大幅缩减了 18TB,将来很长时间里都不用买新硬件了。
注:有关 SHA-1
目前在 SHA-1 碰撞方面有几个已知的范例。不过现有的这些碰撞范例仅针对内部的压缩函数(SHA-1 freestart 碰撞)。考虑到我们有 120 亿个文件,出现哈希碰撞的几率小于 10^-38。
但假设真的遇到这种情况。此时在通过哈希值请求文件时,我们会检查文件的大小和 CRC32 校验值与相应邮件上传时保存在索引中的值是否相同。毫无疑问,只有所请求的确实是当时伴随邮件上传的文件时,用户才能获得所请求的文件。
阅读英文原文: Efficient Storage: How We Went Down From 50 PB To 32 PB
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论