
DataTorrent 是一个实时的流式处理和分析平台,它每秒可以处理超过 10 亿个实时事件。
与 Twitter 平均每秒大约 6000 条微博相比,最近发布的 DataTorrent 1.0 似乎已经超出了需求,它每秒可以处理超过 10 亿个实时事件。他们在一个包含37 个节点的集群上进行了测试,每个节点256GB 内存、12 核超线程CPU。在CPU 达到饱和之前,DataTorrent 声称已经实现了线性扩展,而CPU 达到饱和时处理速度为每秒16 亿个事件。Phu Hoang 是DataTorrent 的联合创始人和CEO,他告诉InfoQ,在同样的硬件上,他们的解决方案在性能上比Apache Spark 要高“好几个数量级”。
DataTorrent 基于 Hadoop 2.x 构建,是一个实时的、有容错能力的数据流式处理和分析平台,它使用本地 Hadoop 应用程序,而这些应用程序可以与执行其它任务,如批处理,的应用程序共存。该平台的架构如下图所示:
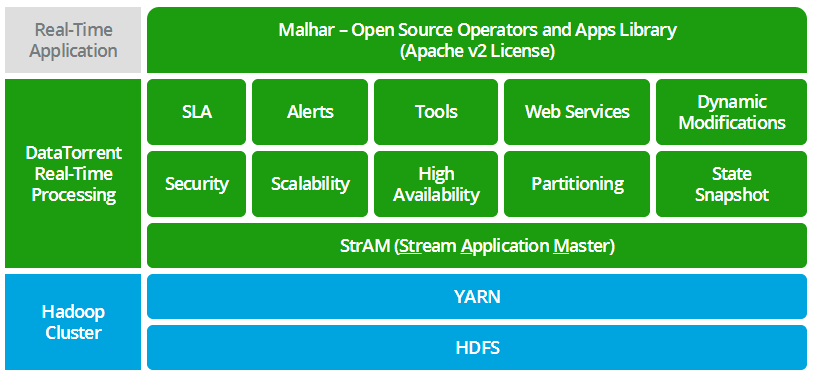
StrAM(Streaming Application Master)是一个本地的 YARN Application Master,负责管理将要在 Hadoop 集群上执行的逻辑 DAG(Directed Acyclic Graph),包括资源分配、分区、扩展、调度、Web 服务、运行时更改、统计、SLA 执行、安全等等。
在架构示意图的上层,用户应用程序作为已连接的算子和 / 或应用程序模板存在。算子的示例有 InputReceiver(模拟接收输入数据)、Average(针对指定维度的键计算数据平均值)、RedisAverageOutput(将计算好的平均值写入 Redis 数据存储)、SmtpAvgOperator(发送电子邮件警报)。这些算子是 Malhar 库的一部分,该库包含了超过 400 个这样的算子,并在 GitHub 上开源。用户可以根据需要编写其它算子。
我们问 Hoang,是什么使 DataTorrent 比 Spark 更快:
PH:DataTorrent 侧重于使企业能够通过流式处理实时采取行动,而 Spark 希望使 Spark 引擎适用于处理连续事件流,这就在架构上产生了两个重要的区别。性能和有状态的容错能力是两个重点关注的方面。
- 性能——作为一个本地 Hadoop 2.0 产品,DataTorrent RTS 从头开始设计和构建,它关注性能和高可用性,并最终实现了以亚秒级延时逐个处理事件。DataTorrent RTS 在启动时就将应用程序调度到 Hadoop 容器中,如果应用程序不需要更改,映射就固定不变,这样就不会引入任何调度开销。另一方面,Spark 基于 Hadoop 2.0 之前的版本构建,它利用 Spark 引擎以小批量或“迷你批量”高效地运行许多“map reduce”作业。这种设计策略要求现在的 Spark(通过 Application Master)必须将每个最小批调度到集群上,这意味着巨大的开销,降低了系统速度。
- 有状态的容错能力——按照设计,DataTorrent RTS 能够进行复杂的、有状态的高性能计算,并具有容错能力。这是企业的一项关键需求,在不丢失任何数据、任何状态的情况下从故障中恢复,这是一项必备的能力。这里,DataTorrent RTS 的设计中心是使用 Java 编程以及为企业开发人员 /ISV 解除容错能力设计的“负担”(也就是说,由 DataTorrent RTS 为开发人员处理)。Spark 确实也提供了容错能力,但只针对无状态处理。Spark 的设计中心是使用函数式语言 Scala,处理连续事件流的算子是无状态的。如果企业想向 Spark 添加有状态的处理,他们需要将那部分代码作为应用程序的一部分进行编写,这很难,而且会影响性能。
据 Hoang 说,经验证,DataTorrent 适用于“所有主要的 Hadoop 分发,既包括本地部署,也包括基于云的部署(前者如 Cloudera、Hortonworks、MapR,后者如 Amazon AWS 和 Google Cloud),这赋予了企业灵活性,使他们既可以更换 Hadoop 供应商,也可以无障碍地更改部署选项。”
虽然 DataTorrent 是一款商业应用程序,但它也带来了一个包含所有功能的免费层级,可以用于中小型应用程序。
查看英文原文:**** DataTorrent 1.0 Handles >1B Real-time Events/sec

暂无签名

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...










评论