
进入全民短视频时代,人像视频的拍摄也正在迈向专业化。随着固化审美的瓦解,十级磨皮的网红滤镜被打破,多元化的高级质感成为新的风向标,“美”到每一帧是人们对动态视频提出的更高要求。
目前,大部分手机均可记录主流的 24fps、25fps、30fps、50fps 和 60fps(frame per second,FPS),以常见的 30FPS 为例,1 分钟的视频就需要处理 1800 帧左右,如何保证处理过程中帧与帧之间的效果连续性是算法面临的关键突破点。
事实上,传统磨皮算法是一般实时美颜算法设计的优先选项,其本质是由各类高通滤波算法和图像处理算法组合而成,通过滤波核的大小来实现人像的瑕疵祛除和肤质光滑,经过优化后也能够达到移动端的实时性能要求,但经传统磨皮算法处理后导致的五官与皮肤纹理细节缺失容易形成明显的“假脸”效果。

图 1:传统磨皮算法 VS 美图美颜算法

图 2:原图 VS 美图美颜算法
围绕用户更具个性化的“变美”需求,美图影像研究院(MT Lab)自研基于深度学习的实时视频美容方案。通过设计轻量的神经网络生成式模型,结合强大的模型优化推理框架(Manis)和千万级人像图库训练优势,实现对动态视频人脸的瑕疵修复与暗沉祛除,同时最大程度地保留了皮肤的真实纹理细节。


原视频 VS 美图实时美颜算法效果
对比之下美图的实时美颜算法既没有弱化面部结构,对细微瑕疵也进行了精细化处理,脸部皮肤呈现干净通透、清晰自然的高级质感。

传统磨皮算法 VS 美图实时美颜算法效果
此外,为了兼顾更好的使用感受,轻量级的网络能在低、中、高端不同档位的移动端产品上实现更大范围地部署,满足移动端的实时性能要求,平均 1 秒钟能够美化处理视频 142 帧,为更多用户带来更好的“变美”体验。
轻量级模型设计,提升生成效果
轻量级结构设计策略
在进行网络结构设计时,首要考虑如何实现效果和速度的均衡。因此在保证不损失过多效果的前提下,模型结构尽量遵循了并行度高的设计原则,轻量级结构设计(如图 3)的具体策略如下:
不使用大于 3x3 的卷积核,下采样也使用 stride=2 的 3x3 卷积替代,因为 3x3 卷积的计算速度远高于其他大核卷积。
模型中最大通道数不大于 64,以减少大尺寸 feature map 的计算量。
网络输入尺寸在不影响效果的前提下尽可能地缩小。同时,一定程度上减少输入宽度,而不是使用 1:1 的输入比例,因为人像两侧存在与美颜无关的背景区域,要避免增加额外的计算量。
上采样使用最近邻插值加 3x3 卷积替代反卷积和双线性插值,以便于加速。
非必要情况下尽量采用简单的单路架构,只在 stride=2 卷积后加入 Concate 分支,因为 Add 或者 Concate 操作虽然计算量很小,但是 MAC 很高;同时,网络不使用 ResBlock,以节省内存占用。
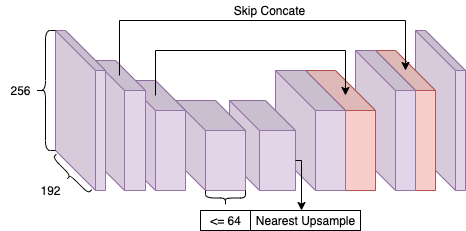
图 3:美图轻量级实时美化模型结构
模型生成效果提升方案
为了获得更好的实时生成效果,MT Lab 借鉴了 RepVGG 的重参数等价转换思路,来进一步优化轻量级模型的组件重组流程(如图 4)。
该流程在模型训练阶段,对每个 3x3 卷积增加并行的 1x1 卷积分支和恒等映射分支;而在模型实际推理阶段,则把对应的 1x1 卷积分支和恒等映射分支通过 padding 操作分别等价转换成特殊的 3x3 卷积,根据卷积的线形可加性,再将参数合并到主分支的 3x3 卷积里面。
这个方式相当于只增加模型训练阶段的网络消耗以提升网络生成效果,而在实际模型部署时增加的分支参数等价合并,并不会给网络增加任何额外的计算量。
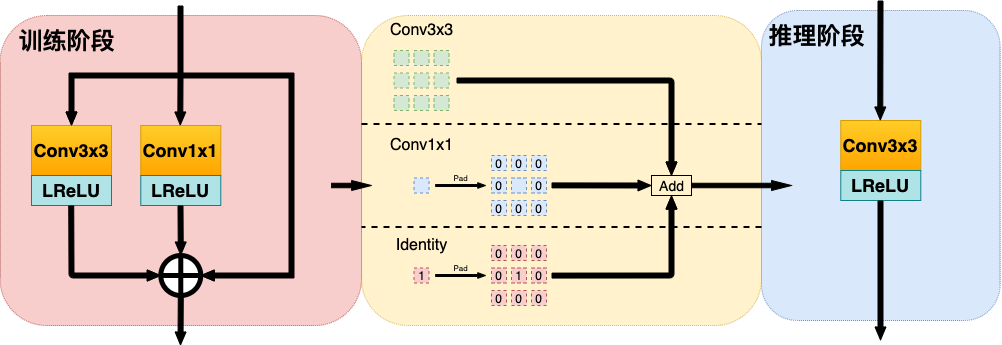
图 4:模型组件重参数优化流程
同时,为了大幅提升网络训练效率,除了使用常规的重建感知 Loss 和像素级 Loss 外,MT Lab 还借鉴对抗生成网络的思路,设计相应的判别 Loss 来监督网络,在微调(fine-tunning)阶段对实时美化网络进行修正,从而进一步优化模型的生成效果。
判别 Loss 设计流程(如图 5)先对训练数据标定出对应的斑痘、暗沉等瑕疵区域,作为瑕疵 mask。再使用参数多、结构深的大型网络训练出一个精准的瑕疵 mask 分割模型,作为实时美化模型的判别网络。
在训练实时美化网络时,固定判别网络的参数,将实时美化网络输出的结果作为判别网络的输入,同时用一张全“0”mask 作为监督,要求判别网络监督实时美化网络不能生成有瑕疵区域的结果,从而达到提升美化效果的目的。
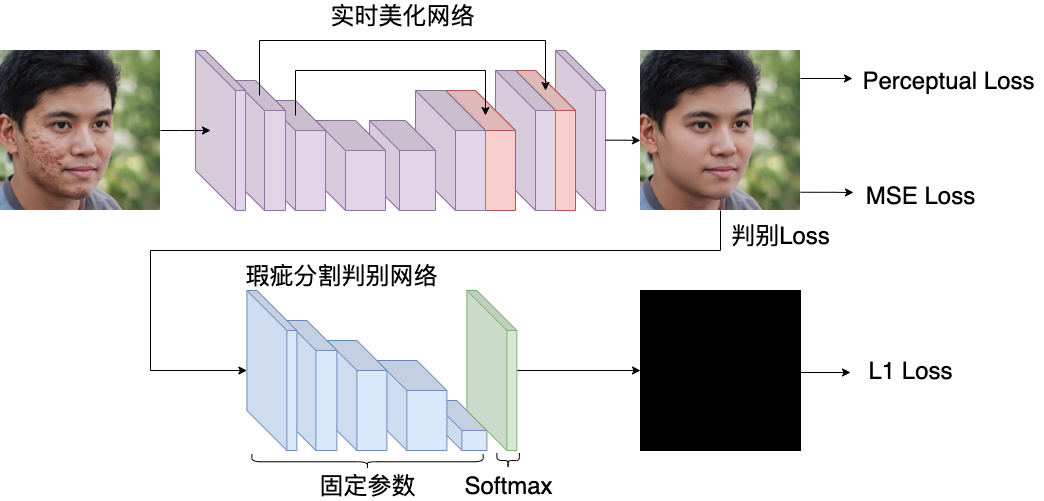
图 5:判别 Loss 设计流程
优化实时体验效果
众所周知,影响模型实时执行的因素包括图片帧率、分辨率和功耗。视频人像美化需要保持实时的高分辨率,模型的 FeatureMap 就会相应增大,再叠加美化模型内部的高计算量,导致整个推理过程帧率低且耗时长;同时,大量的图像前后处理增加了整体的效果耗时和设备功耗,实时处理难以长时间维持稳定。
MT Lab 基于自研的全平台 AI 推理框架 Manis,通过整合模型智能分发、纹理数据推理加速、效果叠加优化等多种技术方案,来完成美图美化模型在移动端 App 的顺利落地应用,为用户带来最优的实时效果体验。
基于算力配置定制化模型
为保证不同档位的移动端产品均能获得最佳体验效果,MT Lab 通过 Manis 的天枢平台系统为不同机型的设备能力下发定制的美化模型与 AI 配置,再通过 AI 推理框架(Manis)调度选择最优算力执行推理过程,从而既能保证低端算力设备达到实时效果,也能实现高端算力设备更优品质的画质表现。
模型分发流程以不同设备最优性能的实现为原则,在模型设计之前就与包括华为、MTK、高通、苹果在内的 AI 芯片厂商达成深度交流与合作,从而保证训练后的模型结构和参数完全符合 AI 芯片的计算特性。
GPU 推理方面,Manis 针对高通的 GPU 架构在纹理内存上的访存能力较优的特点,选择 GL texture 纹理推理计算方式;针对 MTK 设备在普通内存上的多种加速特性能力,选择 GL buffer 纹理推理计算方式;而针对支持 OpenCL 规范的共享特性的高通 GPU 设备,则通过 OpenCL 和 OpenGL 上下文关联,将 GL texture 与 CL texture、GL buffer 与 CL buffer 进行映射,实现 OpenGL/OpenCL 混合执行,再利用渲染和计算方式的优势,从而达到 AI 算法在 GPU 的最优调度。
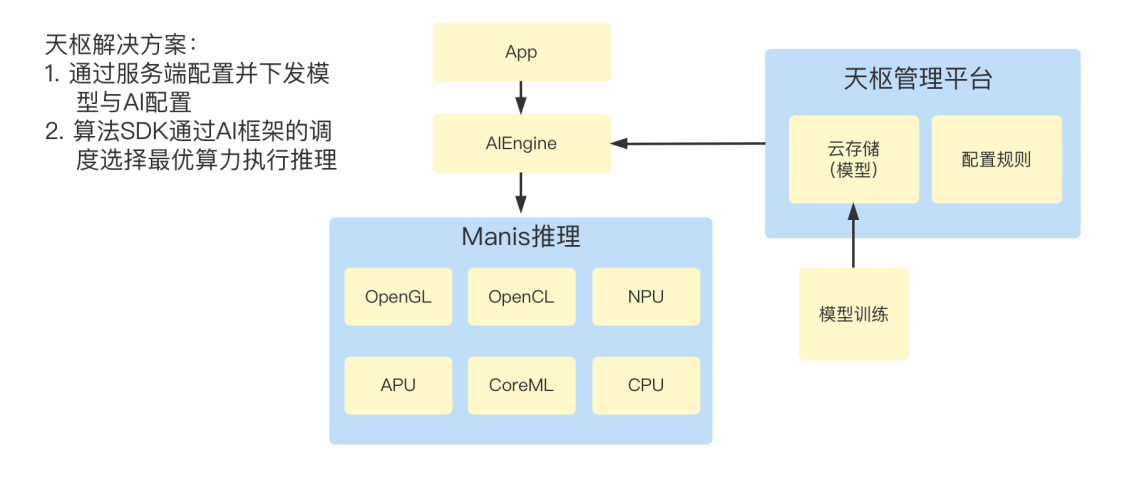
图 6:美图天枢解决方案模型分发流程
实时美化模型优化
事实上,CPU 和 GPU 数据交互同步是一件非常损耗性能的操作,功耗增加导致长时间的处理下容易出现掉帧现象。
对此,MT Lab 在人脸检测环节采用极速轻量的 CPU 推理,快速获取人脸区域,通过局部的数据操作,降低 FeatureMap 大小的同时保留关键特征图信息,避免大数据量下 GPU 带宽受限带来的性能掉点问题;在图像处理环节通过 GPU 数据流并发推理,弱化了高计算量带来的负面影响。最后,基于双通道数据流在局部区域上进行效果叠加优化,从而保证了视频中每帧数据的高分辨率,呈现高品质的实时画质。
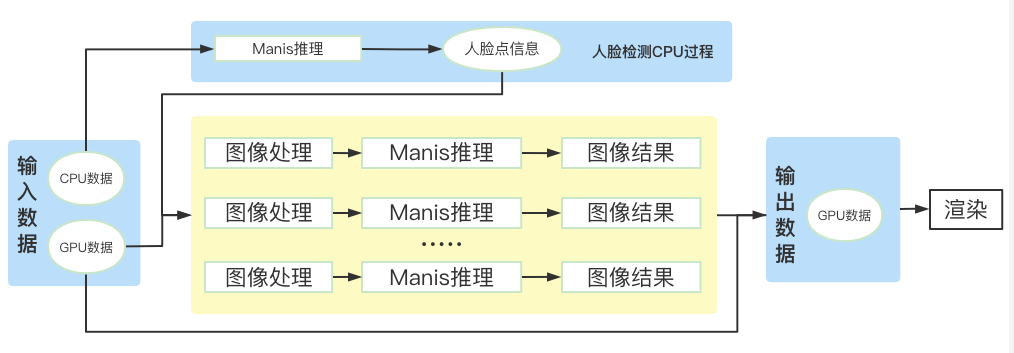
图 7:纹理数据流加速策略
美图优化加速器— —AI 推理框架 Manis
基于 Manis 的模型优化是视频美化算法得以顺利落地的核心环节,与此同时 Manis 还在美图产品应用场景中扮演着更为重要的角色。它既实现了移动端上极致性能优化,还服务于加速 AI 项目的落地生态打造。通过与主流开源框架的性能数据对比(如图 8),可以很明显地感受到 Manis 所具备的高水平推理能力与性能提升能力。
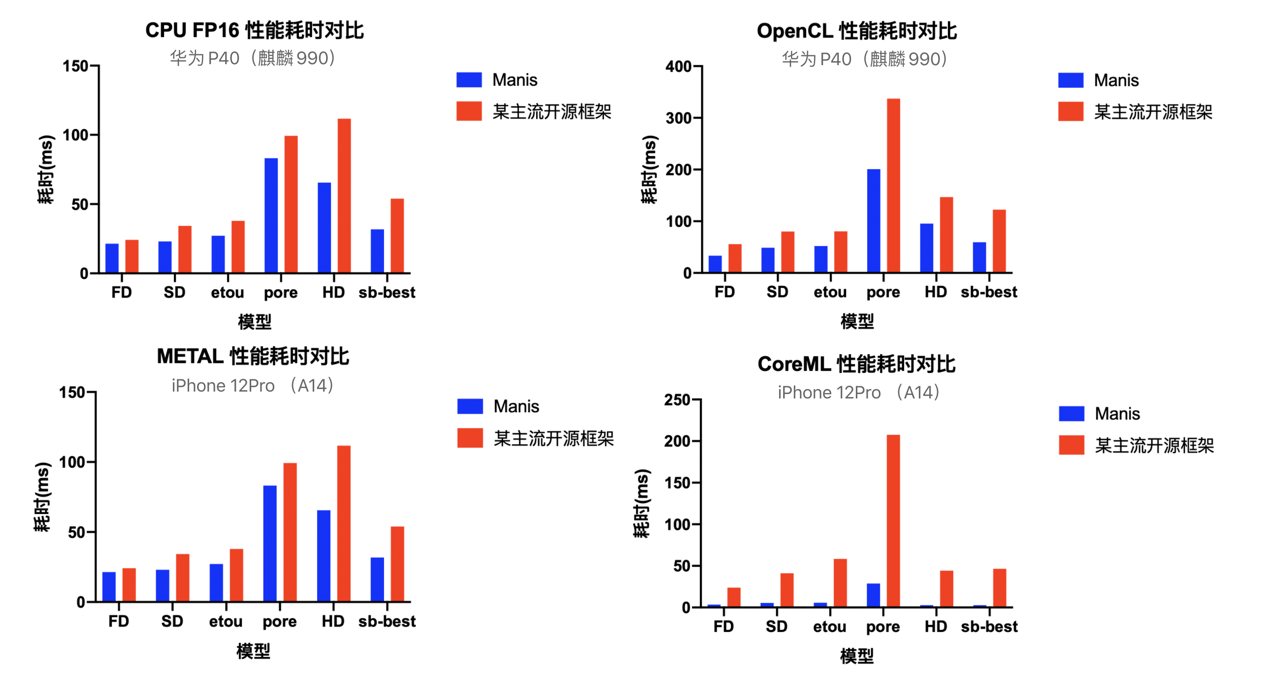
图 8:Manis 与某开源框架第三季度最新版本的性能数据对比
在实际应用中,Manis 包含 AI 服务、天枢系统、运维监控等在内的多项功能,主要通过以下三个体系模块来实现对算法的优化加速:
模型转换模块
可以快速实现各主流模型结构向 Manis 模型结构转换,以便算法顺利接入。同时,通过图优化技术简化模型结构,为各种执行设备如 CPU、GPU、AI 芯片添加优化控制手段,达到模型层面的性能优化。
模型测试模块
基于 Manis 在主流手机设备上的部署,能够在线测试输出模型在各种算力使用场景下的性能表现和评估信息,对模型算法进行快速验证,从而帮助模型不断迭代优化,同时缩短优化的开发周期。
模型推理模块
Manis 高度适配 CPU、GPU、DSP、NPU、ANE、APU 等多种硬件设备,其中 GPU 支持 OpenGL、OpenCL、Metal、CUDA 等多种技术方案,CPU 支持 fp32、fp16、bf16、int8 等多种精度方案。
其中,针对移动端设备的性能优化包括汇编级 CPU neon 优化、图优化、Auto-Tuning、多线程优化以及算子融合;针对移动端的精度优化包含 fp32/fp16 浮点计算方式、bf16 格式计算策略以及 8 位整型量化计算方案,能够结合推理的设备能力,进行动态图切分及混合精度计算,释放设备的最大算力。而针对类似实时美化这样的复杂应用,则采用定制化的优化策略,包括内存复用策略、内存池、模型共享以及数据排布优化。
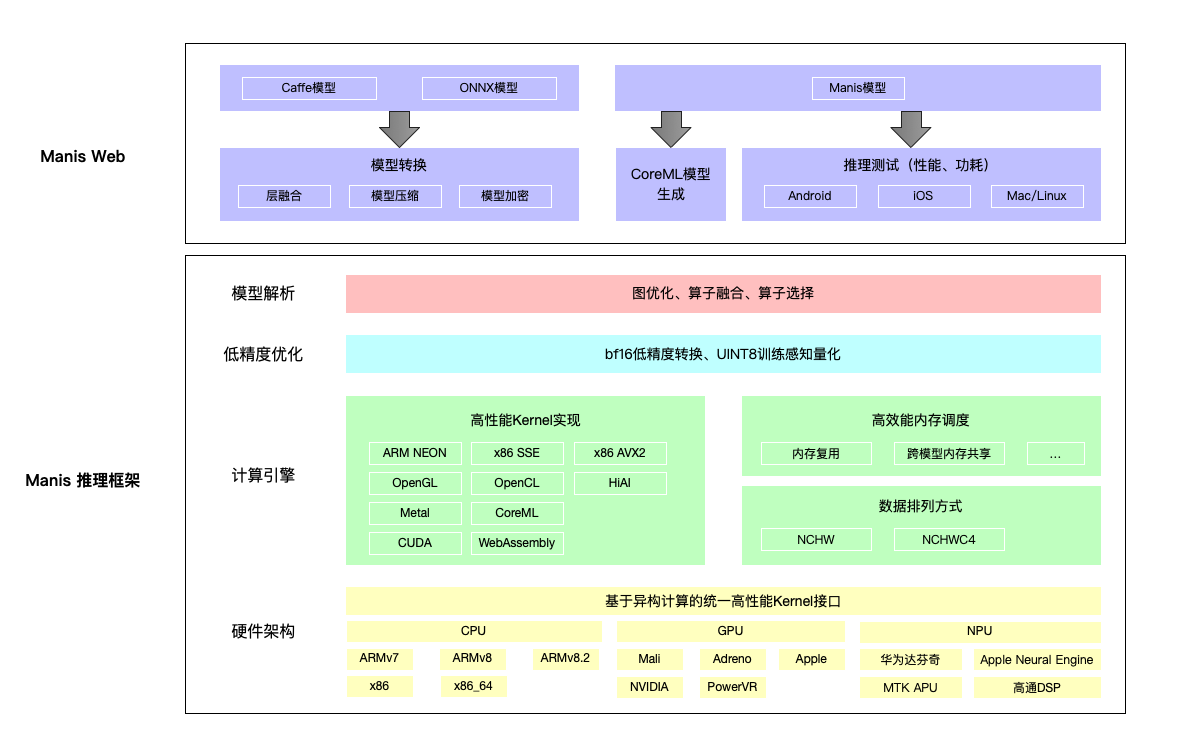
图 9:美图 AI 推理框架(Manis)架构图
目前,美图全部产品的应用落地场景都有着 Manis 的身影,它为美图核心 AI 算法在不同平台和硬件上实现了低延迟、低内存、低功耗的应用落地,未来 Manis 也会进一步迭代和优化,拓展实时化应用上的更优性能。




