

什么是监控?我认为,对不同的人,这意味着不同的东西。但是,对于这个概念,我们或多或少有一些一致的看法。当有人说监控时,我会想到:

但显然,有些人会想到别的事情。这些人显然是错的,让我们继续。当我读了某个白痴写的一篇 10000 字的博文后,我就不再那么迟钝了。我把监控看作是一个注视你的东西的过程,就像一个保安坐在某处一张堆满摄像机的桌子前一样。有时他们会睡着——这是监控系统宕机。有时他们会因为甜甜圈送到而分心——这是升级停机。有时摄像机在循环播放——看着那个画面,我不知道去哪里,但是可能有人在偷你的东西。还有,你有火警警报器。你不需要人来触发它。同样的道理,当门被打开的时候,那可能连接到警报器上了。也许没有。或者,警报器 1984 年就坏了。
我知道你是怎么想的。我的观点是,监控任何应用程序与监控其他任何东西没有太大区别。有些事情你可以自动化。有些事情你做不到。有些东西可以根据阈值告警。有时你会弄错这些阈值(尤其是在节假日)。有时,进一步的自动化设置不太值得,你只是需要使人更容易看明白。
这里我要讨论的是我们所做的事情。每个人的情况都不一样。什么是重要的,什么是“值得的”,对每个人来说都不相同。就像生活中的其他事情一样,需要权衡取舍做出许多决定。以下是我们到目前为止所做的决定。它们不完美。它们还在发展。当新的数据或优先事项出现时,我们将在必要时改变先前的决定。这就是大脑的工作原理。
数据类型
监控通常涉及多种数据类型,我对其做了如下分类:
日志:丰富而详细的文本和数据,但不是让人害怕的警告;
指标:遥测数据的标记数值——适用于警告,但缺少细节;
健康检查:运行正常?宕机?异常?非常具体,通常是为了警告;
性能分析:应用程序性能数据,用来查看事情耗费了多长时间;
其他具体用例的复杂组合,无法归入任何一类。
日志
让我们聊下日志。你几乎可以记录任何东西,包括信息消息、错误、流量、电子邮件(小心 GDPR)等。
听起来不错。我可以记录任何我想要的东西!有什么需要注意吗?这是一种权衡。你是否曾经运行过具有大量控制台输出的程序?在没有输出的情况下运行相同的程序速度更快,不是吗?日志记录有一些开销。首先,通常需要为日志本身分配字符串。这就涉及内存和垃圾收集(对于.NET 和其他一些平台)。当你在某处记录日志时,这通常意味着磁盘空间。如果我们遍历一个网络(在某种程度上是局部的),这也意味着带宽和延迟。
刚刚,我只在电子邮件处提到了GDPR……GDPR 是记录上述所有数据时都要考虑的。记录的任何东西都要保留并且合规。这是另外一项需要考虑的成本。
假设这些都不是大问题,而我们想要记录所有的东西。好吧,我们就可以拥有太多的好东西。当你需要查看日志时会发生什么?会需要更多地挖掘。这会使发现问题变得更加困难和缓慢。对于所有的日志记录,都是在你认为需要的记录与最终需要的记录之间进行权衡。你会弄错。一直都会。当出现问题时,你会发现新添加的特性没有正确的日志记录。你最终会明白的(可能在遇到问题之后)…并添加相应的日志。这就是生活。改进并继续前进。不要老是想着它,只要吸取教训并从中学习。以后,你将在代码评审等方面对此进行更多的思考。
那么我们记录什么呢?这取决于系统。对于我们构建的任何系统,我们总是会记录错误。我们使用了StackExchange.Exceptional,这是我维护的一个开源的.NET 错误日志程序。它记录在 SQL Server 里,可以在应用程序内或通过 Opserver 查看(稍后我们将详细讨论)。
对于像Redis, Elasticsearch和SQL Server这样的系统,我们只是使用它们内置的日志记录和日志轮转机制将日志记录到本地磁盘。对于其他基于 SNMP 的系统,如网络设备,我们将所有这些转发到Logstash集群,通过前端的Kibana进行查询。Bosun在出现警告时也会查询上面的许多内容,以了解详细的信息和趋势,下面我们将深入地讨论这些内容。
日志:HAProxy
我们也记录经过HAProxy(我们的负载均衡器)的公共 HTTP 请求的最小摘要(只是顶级…没有 Cookies、没有表单数据等),因为当有人不能登录,账户合并,或任何其他上百个 Bug 报告进来时,能够看下是什么导致了他们的问题会非常有价值。我们是在 SQL Server 中通过聚簇列存储索引来实现的。根据记载,Jarrod Dixon在大约 8 年前第一次建议并开始了 HTTP 日志记录,我们那时都说他是个疯子,这是对资源的巨大浪费。没有人说他是对的。一种新的按月存储格式即将推出,但那是另外一个故事了。
在那些请求中,我们使用了我们很快就会谈到的性能分析,并把头信息和特定的性能数值一起发送到 HAProxy。HAProxy 捕获那些头信息并拆分成系统日志行,我们会转发并处理成 SQL。那些头信息包括:
ASP.NET 总毫秒数(包含下面这些);
SQL 计数(查询)&毫秒数;
Redis 计数(命中)&毫秒数;
HTTP 计数(发送的请求)&毫秒数;
标签引擎计数(查询)&毫秒数;
Elasticsearch 计数(命中)&毫秒数。
如果事情变好或变坏,我们可以很容易地查询并与历史数据进行比较。它还以我们从未想到的方式发挥作用。例如,当我们查看一个请求和运行中的 SQL 查询数量,它能告诉我们用户沿着代码路径走了多远。或者,当 SQL 连接池请求过多时,我们可以查看在特定时间内来自特定服务器的所有请求,看看是什么导致了这种争用。在这里,我们所做的就是跟踪 n 个服务的调用次数和时间。这超级简单,但也非常有效。
我们将系统日志监听以及保存成 SQL 的过程称之为“流量处理服务(Traffic Processing Service)”,因为我们计划每天发送报告。
对于每个请求,除了那些头之外,HAProxy默认的日志行格式还有一些其他的时间:
TR:客户端发送请求耗时(这在keepalive发挥作用时特别有用);
Tw:在队列中等待耗时;
Tc:等待连接到 Web 服务器耗时;
Tr:Web 服务器完全渲染一个响应的耗时。
另一个简单但重要的例子是 Tr 和 AspNetDurationMs 头(一个计时器会在请求开始时启动和结束时停止)之间的增量,它可以告诉我们在操作系统中耗费的时间,在 IIS 中等待线程的时间等等。
健康检查
健康检查就是检查健康状况。“这健康吗?”,对于这个问题通常有 4 个答案:
是:“一切正常!”
不: “@#$%!我们宕了!”
有点:“嗯,我想,从技术上讲,我们是在线的……”
不知道:“没有任何线索……他们没有接电话。”
按照约定,它们通常分别是绿色、红色、黄色和灰色。健康检查有一些一般用法。在任何分布式负载设置中,如一个服务器集群或一组服务器前的负载均衡器,健康检查是一种查看成员是否胜任某个角色或任务的方法。例如,在 Elasticsearch 中,如果一个节点宕机,它将重新平衡分片并在其他成员中加载……当节点恢复健康时,再次执行此操作。在 Web 层,负载均衡器将停止向宕机节点发送流量,并继续在健康节点之间进行平衡。
对于 HAProxy,我们使用内置的健康检查,它可以进行健康警告。到 2018 年底,当我写这篇文章的时候,我们还在使用 ASP.NET MVC5,并且正在向 .NET Core转换。一个重要的细节是,我们的错误页面是一个重定向,例如/questions 到/error?aspxerrorpath=/questions。这是.NET 旧基础设施工作机制的一个实现细节,但当与 HAProxy 结合时,这成了一个问题。例如,如果你有下面这样一个请求:
那么,它将收到一个 200-399 之间的HTTP状态码响应。(还请记住:它只发出 HEAD 请求。)400 或 500 将触发不健康,但我们的302重定向不会。浏览器*在重定向之后*将获得一个 5xx 状态代码,但 HAProxy 不会这样做。它只做最初的检查,而一个“健康”的 302 是它所看到的一切。幸运的是,你可以在同一个后端使用 http-check expect 200(或任何状态代码,或范围,或正则表达式——文档在这里)来更改它。这意味着我们的健康检查端点只允许 200。是的,它不止一次给我们带来伤害。
不同的应用程序有不同的健康检查端点,但对于stackoverflow.com来说是主页。我们已经讨论过几次要改变这一点,但事实是,主页检查了我们可能会检查不到的东西,而全面检查很重要。我的意思是,“如果多个用户点击同一个页面,它会发挥作用吗?”如果我们对数据库和某些缓存的访问进行健康检查,对我们知道需要保持在线的重要内容进行一致性检查,这很好,这比什么都不做要好得多。但是,假设我们在代码中放置了一个 Bug,而看似没有那么重要的缓存未能正确地重新加载,其结果就是需要为所有用户渲染顶部状态栏。现在,每一页都遭到了破坏。运行某些代码的健康检查路由不会被触发,但是,加载主视图的动作可以保证对大量依赖项进行评估,确保它们在进行检查时可以正常发挥作用。
我们在库中也有健康检查。最简单的形式就是心跳,如用StackExchange.Redis定期检查到 Redis 的套接字连接是否活动。我们使用相同的方法来查看套接字是否仍然打开,并且正在被 Stack Overflow 上的 WebSocket 消费者所使用。这是一种不常用的监控,但确实用了。
我们还有其他的健康检查,包括标记引擎服务器。我们可以通过 HAProxy(它会添加一个跃点)来平衡负载,但是,让每个 Web 层服务器直接知道每个标记服务器对我们来说是一个更好的选项。我们可以 1)选择如何分配负载,2)更容易地测试新构建,3)获得每个服务器的操作计数指标和性能数据。所有这些都在另一篇文章中介绍,但是对于这个主题:我们有一个简单的“ping”健康检查,每秒探测一下标记服务器,从它获取少量的数据,比如它最近一次从数据库更新的时间。
所以,就是这样。你完全可以通过健康检查来传达你想要的状态。如果它能带来一些好处,而且开销是值得的(如你正在运行另一个查询吗?),那就试试看吧。微软的.NET 团队一直致力于在ASP.NET Core中提供统一的健康检查方法,但我不确定我们是否会那样做。我希望我们能提供一些想法,并在我们开始做的时候进行统一……在这个过程中,我们会有更多的想法。
但是,请记住,健康检查通常会经常运行,很经常。它们的开销和可扩展性应该与它们运行的频率联系起来。如果你每 100 毫秒一次、每秒一次、每 5 秒一次或每分钟检查一次,那么检查什么以及评估多少依赖项(并花一些时间检查……)就非常重要。例如,100 毫秒一次的检查不能用 200 毫秒。那太过分了。
这里有另外一个需要注意的事项,健康检查通常可以反映几个级别的“运行(up)”。一个是“我在这里”,这是最基本的。另一个是“我准备好提供服务了”。后者对于几乎每个用例都更加重要。但是,对于机器,你不能那样说,你要用它们喜欢的方式。
在 Stack Overflow,有一个这样的实际例子:在将 HAProxy 后端服务器从 MAINT(维护模式)切换到 ENABLE 时,我们会假设后端一直处于运行状态,直到健康检查显示情况并非如此。但是,当从 DRAIN 切换到 ENABLE 时,我们会假设服务已经关闭,并且必须通过 3 次健康检查才能获得流量。当我们处理线程池增长限制和试图增加的缓存(如 Redis 连接)时,我们可能会由于健康检查的行为而遇到非常严重的线程池饥饿问题。其影响非常大。当我们从耗尽状态缓慢地增加时,大约需要 8-20 秒才能完全准备好为新构建的 Web 服务器流量提供服务。如果我们从维护状态开始,在服务器启动时,流量会涌入服务器,这个过程需要 2-3 分钟。健康检查和流量涌入似乎是很明显的细节,但它对我们的部署管道至关重要。
健康检查:httpUnit
我们有一个内部工具(同样是开源的!)是httpUnit。它是一个相当易于使用的工具,我们使用它来检查端点的法规遵从性。这个 URL 是否返回我们期望的状态代码?来点文本检查怎么样?证书有效吗?(如果无效,我们就无法连接。)防火墙允许这个规则吗?
通过不断进行这项检查并在失败时将其纳入警告,我们可以快速地识别问题,特别是从无效配置更改到基础设施的问题。在应用用户负载之前,我们还可以随时测试新的配置或基础设施、防火墙规则等。要了解更多细节,请参见GitHub README。
健康检查:Fastly
如果我们把视角从数据中心移开,我们需要看看是什么在访问我们。这通常是我们的 CDN 和代理:Fastly。Fastly 有一个服务的概念,当你把它看作负载均衡器时,它类似于 HAProxy 后端。Fastly 还内置了健康检查功能。在我们的每个数据中心中,为了保证冗余,我们都有两组 ISP。这里,我们可以在 Fastly 中进行配置,优化正常运行时间。
比如,NY 数据中心目前是我们的主数据中心,CO 是我们的备份数据中心。在这种情况下,我们希望尝试:
NY 主 ISP
NY 辅 ISP
CO 主 ISP
CO 辅 ISP
采用主辅 ISP 的原因与最佳传输选项、提交、溢出等有关。记住这一点,我们就可以在它们之间做出优先选择。通过健康检查,我们可以非常快速地从 #1 故障转移到 #4。假设有人在 #1 中切断了两个 ISP 的光纤或者BGP变得不可靠,那么 #2 会立即启动。我们可能会在它发生之前丢弃数千个请求,但是我们讨论的是秒级的事情,用户仅仅刷新页面可能就又回到业务中了。这很完美吗?不是。这是否比无限期地宕机要好?绝对啊。
健康检查:外部
我们也使用一些外部健康检查。监控一个全球性服务是很重要的。我们运行正常吗?Fastly 运行正常吗?我们在这儿运行正常吗?我们在那里运行正常吗?我们在西伯利亚运行正常吗?谁知道呢!?我们有许多供应商,有大量的节点,进行监控的话需要大量的设置和配置……或者我们可以给一些人支付少几个数量级的钱来把这项工作外包。我们使用Pingdom来实现这一点。当事情变糟时,它会提醒我们。
指标
指标是什么?它们可以有几种形式,但对我们来说,它们是有标记的时间序列数据。简而言之,这意味着你有一个名称、一个时间戳、一个值,在我们的情况下,还有一些标记。例如,单条记是下面这个样子:
名称:dotnet.memory.gc_collections
时间:2018-01-01 18:30:00(UTC)
值:129,389,139
标记:服务器:NY-WEB01,应用程序:StackExchange-Network
记录中的值也有几种形式可供采用,但一般情况下是计数器。计数器报告一个不断增长的值(通常在重启时重置为 0)。通过计数值随时间的变化,我们可以求出时间窗口中值的增量。例如,如果 10 分钟之前的值是 129,389,039,那么我们就知道,服务器上的进程在这 10 分钟内运行了 100 次 0 代垃圾收集。另一个情况是报告一个准确时间点的值,例如“这个 GPU 目前 87°”。那么我们用什么来处理指标呢?稍后我们会讲到Bosun。
警告
好了,我们怎么处理那些数据呢?警告!众所周知,“alert”是由“le rat”演变而来的一种变位词,意思是“向当局发出尖叫的人”。
这在几个层次上发生,我们会为遇到问题的团队进行定制,以便它们能以最佳的状态运行。对于 SRE(站点可靠性工程)团队,Bosun 是我们内部的主要警告源。要详细了解 Bosun 的警告机制,我建议你观看Kyle在LISA的介绍(大约从第 15 分钟开始)。一般来说,我们在会以下情况下会发出警告:
什么东西宕掉了或者直接发出警告(如 iDRAC 日志)
趋势与先前趋势不一致(例如 x 时间比平常少——这往往是假期期间的错误警告)
什么东西遇到了瓶颈(如磁盘空间或网络超负载)
什么东西超过了阈值(如某个地方创建的队列)
还有很多其他的小事情,这些是我一下想到的大类别。
如果有什么问题已经够糟糕了,我们就进入下一个阶段:唤醒某人。那是在事情变成真正的问题的时候。它们会直接进入PagerDuty并唤醒值班的 SRE。如果那个 SRE 不应答,它将很快升级到另一个 SRE。这种级别的事情有:
stackoverflow.com(或者其他任何重要的功能)进入离线状态(Pingdom 会看到)
很高的错误率
既然我们已经介绍了所有这些烦人的问题,让我们深入地研究下工具。
Bosun
Bosun是我们用于指标和元数据的内部数据收集工具。它是开源的。没有什么现成的东西能真正满足我们对指标和警告的需求,所以我们在大约四年前创建了 Bosun,它给我们提供了极大的帮助。我们可以随时添加我们想要的任何指标、新功能等等。它具有内部系统的所有优点,也有所有的成本。我待会再谈。它是用Go编写的,这主要是因为绝大多数指标集都是基于代理的。代理scollector(主要基于tcollector的原则)需要在所有平台上运行,为此,Go 成为我们的首选。“嘿,尼克,.NET Core 怎么样?”也许可以,但还不够。不过,这个故事越来越有吸引力了。现在,我们可以很容易地部署单个可执行文件,而 Go 还是领先的。
Bosun 后台使用OpenTSDB进行存储。它是一个构建在HBase之上的时间序列数据库,具有很高的可伸缩性。至少人们是这么告诉我们的。在 Stack Exchange/Stack Overflow,我们遇到的问题通常来自效率和吞吐量方面。我们使用少量硬件做了很多事情。在某些方面,这令人印象深刻,我们为此感到自豪。另一方面,对于那些设计运行方式不同的东西,它会产生扭曲和破坏。对于 OpenTSDB 的情况,从空间的角度来看,我们不需要很多硬件来运行它,但是 HBase 的设计方式使得我们必须给它配置更多的硬件(特别是在网络前端)。当处理的数据量比较少时,有一个 HBase 复制问题,我在这里不想深入讨论这个问题,因为这本身就是一篇文章了,而且是一篇很长的文章。
这是一件麻烦事,花费了我们大量的金钱,以至于我们试图使用 SQL Server 聚簇列存储索引作为 Bosun 的后台。我们已经实现了这一点,但对于某些基数的查询并没有产生非常显著的效果,并且会导致 CPU 使用率很高。Nexus 交换核心指标数据占用的总带宽比大多数其他指标加起来还多出 400 倍,像这样的事情并不可怕。大多数东西运行良好。在一台像样的服务器上,每秒记录 50-100k 的指标数据只需要大约 5%的 CPU——这不是问题。某些查询是痛点,我们还没有回到那个问题上……这是一个“可能”的问题,我们是否能解决它,需要多少时间。不管怎样,这也是另一篇文章。
关于 Bosun 的安装和配置,如果你想了解更多信息,则可以阅读 Kyle Brandt 这篇很棒的介绍其架构的文章。
Bosun:指标
对于使用.NET 的情况,我们使用BosunReporter发送指标,这是我们维护的另一个开源NuGet库。它看起来是下面这个样子:
差不多就是这样。我们现在有了一个流入 Bosun 的数据计数器。我们可以添加更多的标记——例如,我们把它正在哪个服务器上发生(通过主机标记)包含进去,此外,我们还可以在 IIS 中添加应用程序池,或者供用户访问的问答站点等等。更多细节请查阅BosunReporter README。很好玩。
许多其他的系统也可以发送指标,scollector 为 Redis、Windows、Linux 等提供了大量的内置收集器。我们用于关键监控的另一个外部实例是一个小型 Go 服务,它可以监听Fastly实时日志流。有时候,Fastly 可能会返回 503,因为它无法到达我们,或者因为其他什么原因,谁知道呢?我们和它们之间的任何东西都可能出错。可能是被切断的套接字,或者是路由问题,或者是无效的证书。无论原因是什么,我们都希望在这些请求失败且用户感觉到的时候发出警告。这个小服务只监听日志流,从每个条目中解析出一些信息,然后将聚合指标发送给 Bosun。目前,这还不是开源的,因为我不确定我们是否提到过它的存在。如果需要这样的东西,告诉我们,我们会考虑一下。
Bosun:警告
我非常喜欢 Bosun 的一个关键特性,它能够在设计时利用历史数据测试警告。这有助于了解它将在何时被触发。这是一项很棒的完整性检查。老实说,监控并不完美,它从来都不完美,也永远不会完美。很多监控都是从经验教训中学来的,因为出错的事情通常包括你从未想过会出错的事情……这意味着你没有从第一天起就监控和/或警告。警告通常是在出错后添加的。尽管你非常用心,进行了周密的计划,你还是会漏掉一些事情,并且在第一次事件之后添加警告。没关系。那是过去的事了。你现在所能做的就是把事情做得更好,希望这种情况不会再发生。不管你是提前设计还是事后回想,这个功能都很棒:
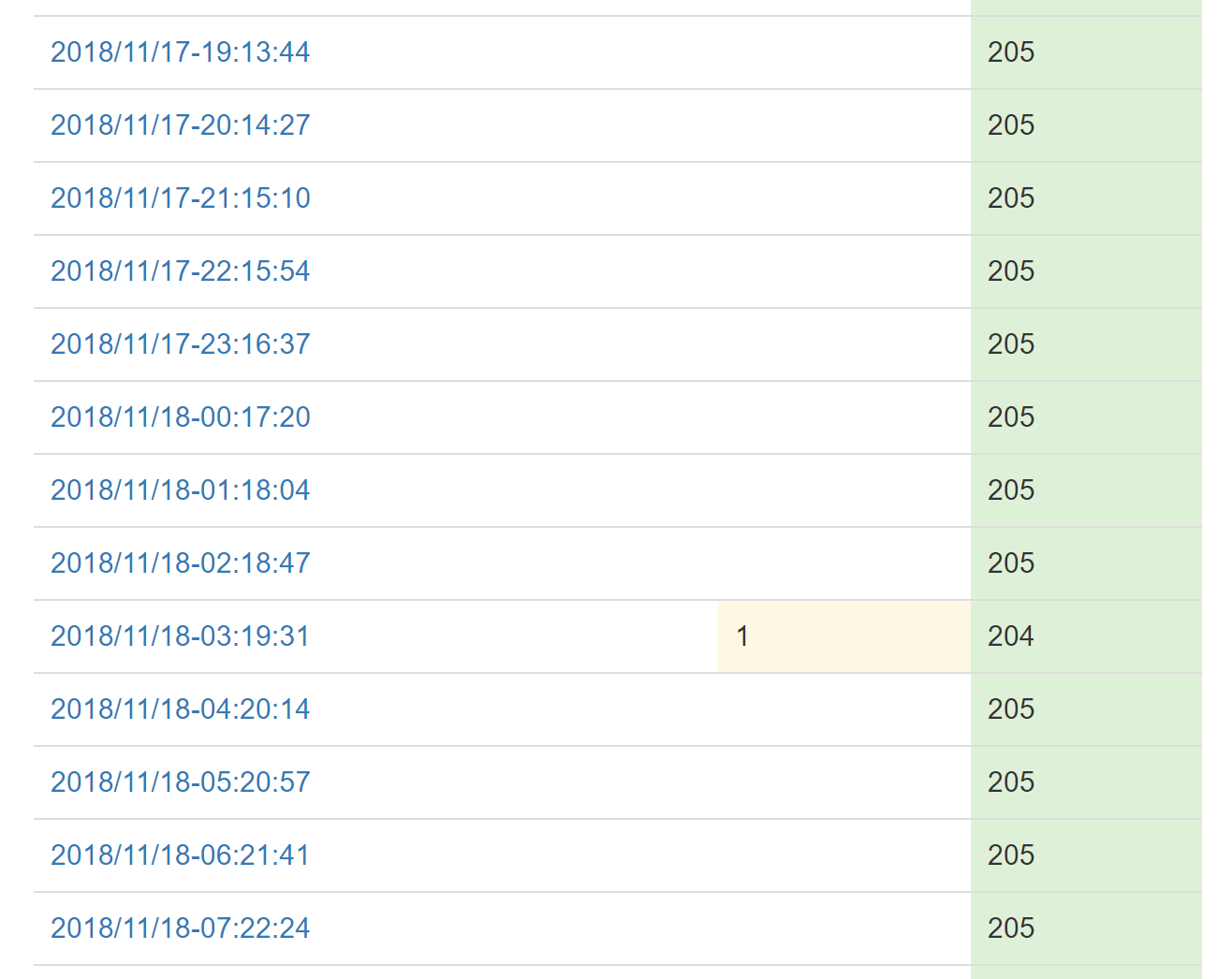
你可以看到,11 月 18 日有一个系统慢到足以触发警告,但其他的都是绿色的。在任何人得到通知之前,通过完整性检查确认警告是否是噪声?我喜欢这个特性。
然后我们有严重的错误,这些错误非常紧急,需要尽快解决。对于这些情况,我们会将它们发布到我们的内部聊天室。像创建Stack Overflow团队出现错误,或者计划任务失败了,就属于这样的情况。我们还有指标通过以下几种方式监控(通过 Bosun)错误:
从我们的异常错误日志(按应用程序汇总)
从 Fastly 和 HAProxy
如果我们在上述两种情况中的任意一种情况下发现了高错误率,那么一两分钟后,带有详细信息的消息就会出现在聊天中。(由于它们是基于聚合计数的,因此不能立即警告。)

这些带有链接的消息让我们可以快速深入地研究这个问题。网络出现了问题吗?我们和Fastly(我们的代理和 CDN)之间是否存在路由问题?是不是有一些糟糕的代码出了问题?有人踢到电源线了吗?是不是有人把两个入电器都插到同一个出现故障的 UPS 上了?所有这些都非常重要,我们希望尽快地进行深入研究。
另一种传递警告的方式是电子邮件。Bosun 有一些很好的功能可以帮助我们。电子邮件可能只是一个简单的警告。比方说,磁盘空间正在减少,或者 CPU 处于高位,而电子邮件中的一个简单图表就能说明很多问题……然后我们会有更复杂的警告。比如说,我们更改了共享错误存储中允许的错误阈值。很好,我们收到警告了!但是…是哪款应用呢?这是一次性的峰值吗?正在发生吗?这时,定义从 SQL 或 Elasticsearch 中查询更多数据的查询的能力就非常有用了(还记得所有那些日志记录吗?)我们可以在电子邮件中添加故障和详细信息。你可以更好地处理(甚至决定忽略)电子邮件警告,而无需进一步研究。下面是几天前 NY-TSDB03 的 CPU 突发事件的邮件示例:

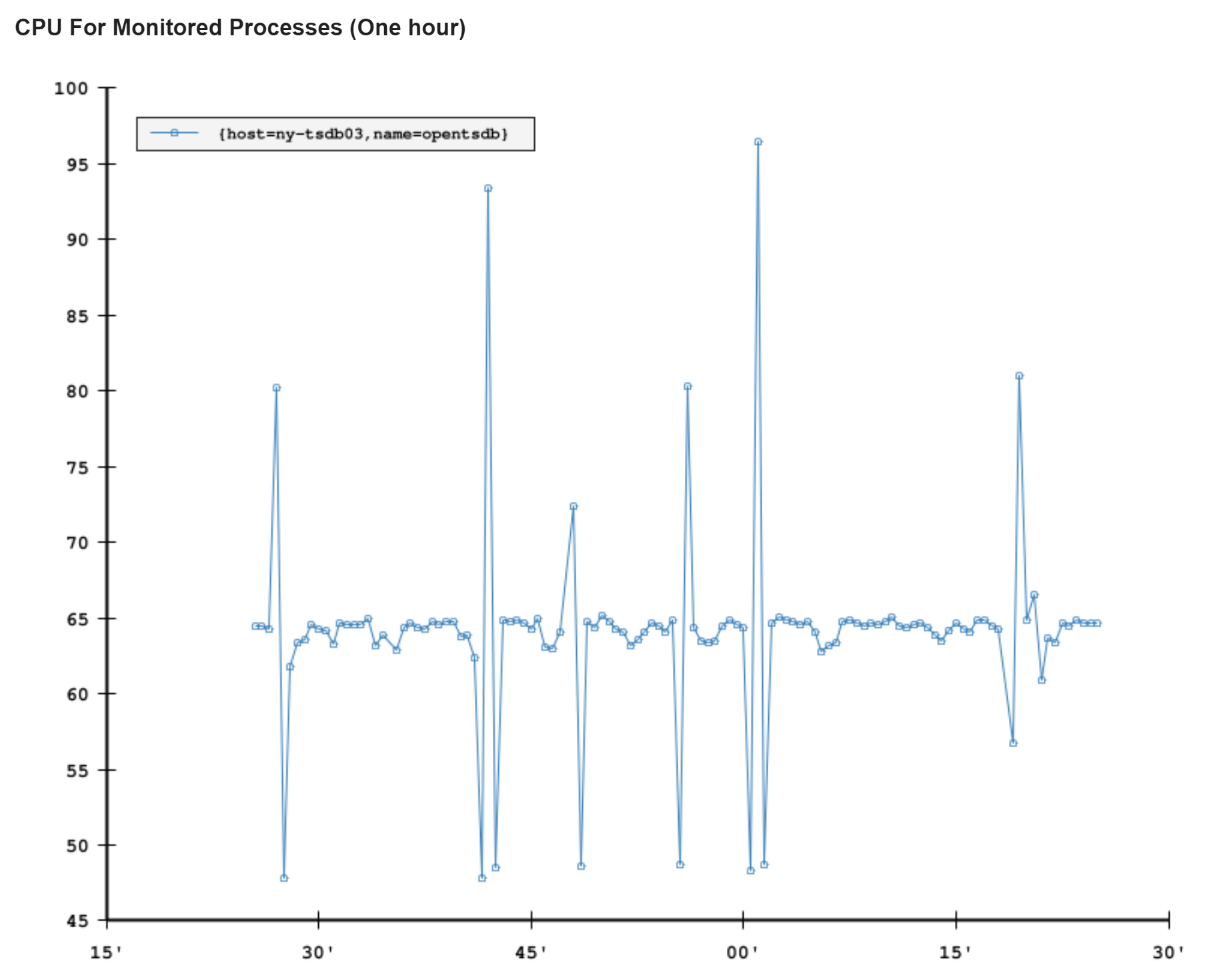
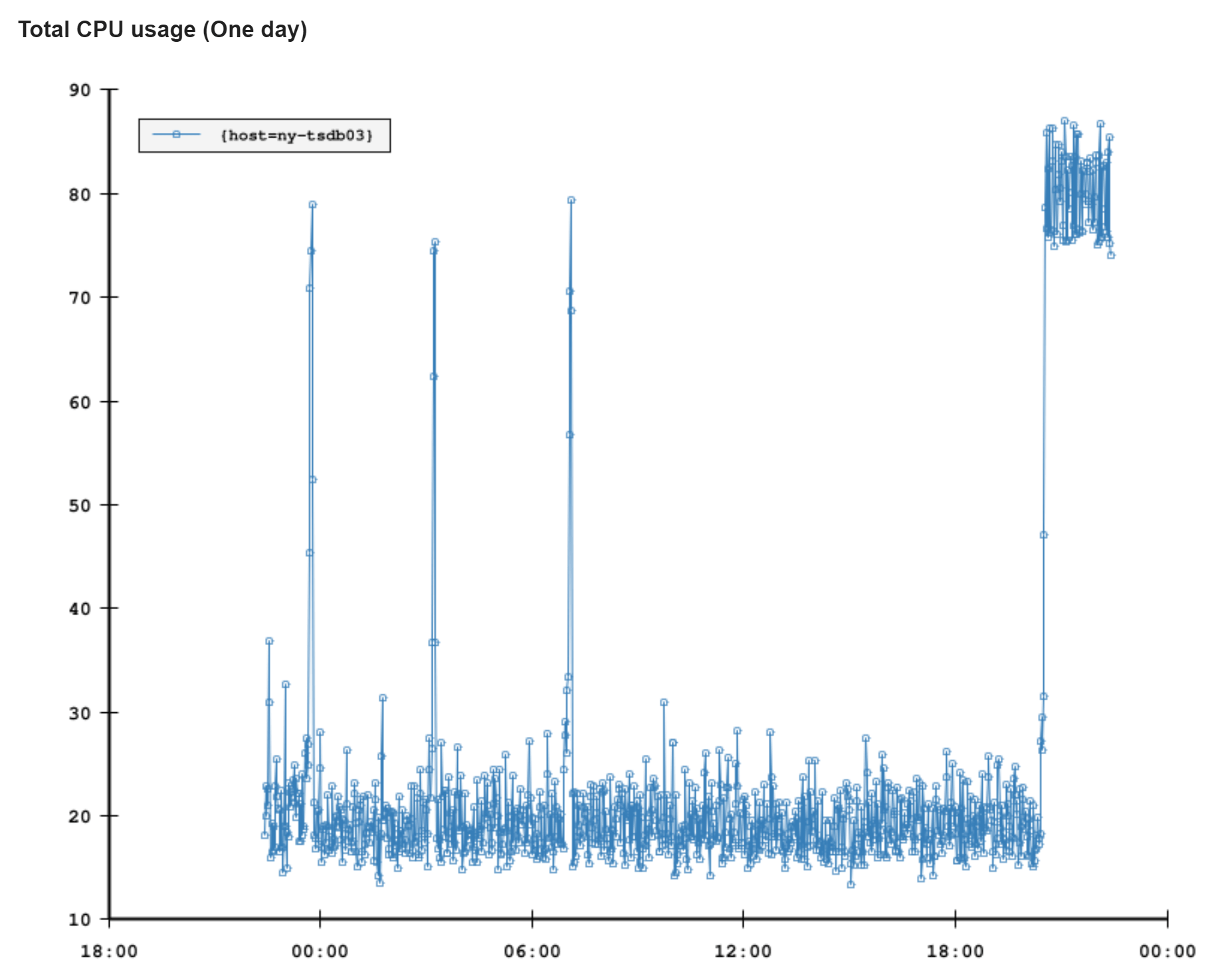
我们也包括了在这个有问题的系统上发生的与这个警告相关的最近 10 个事件,所以你可以很容易地识别一个模式,看看它们为什么被忽略,等等。它们没有出现在这封被我用作示例的电子邮件中。
Grafana
好的,警告很好,但我想看一些数据。毕竟,如果你看不到这些数据,那它们又有什么用呢?展示和可访问性很重要。能够快速地消费数据是很重要的。时间序列数据的图形可视化是一种很好的探索方法。当涉及到监控时,你必须(1)查看数据,或者(2)拥有非常可靠的 100%的警告覆盖率,这样就没有人需要查看数据。第二条是不可能的。当发现问题时,通常需要反过来查看问题是何时开始的。“我们怎么两个星期了都没有注意到这一点?!”这种情况并不像你想象的那么罕见。所以,历史视图是有帮助的。
我们在这里使用了Grafana。这是一款优秀的开源工具,我们为它提供了一个Bosun插件,这样,它就可以作为一个数据源。(从技术上讲,你可以直接使用 OpenTSDB,但这个可以增强功能。)关于 Crafana 的使用,我将依次用一些图片进行说明。
下面一个状态仪表板,显示 Fastly 的运行情况。因为我们借助它们实现 DDoS 保护和更快的内容交付,所以它们的当前状态在很大程度上也是我们的当前状态。
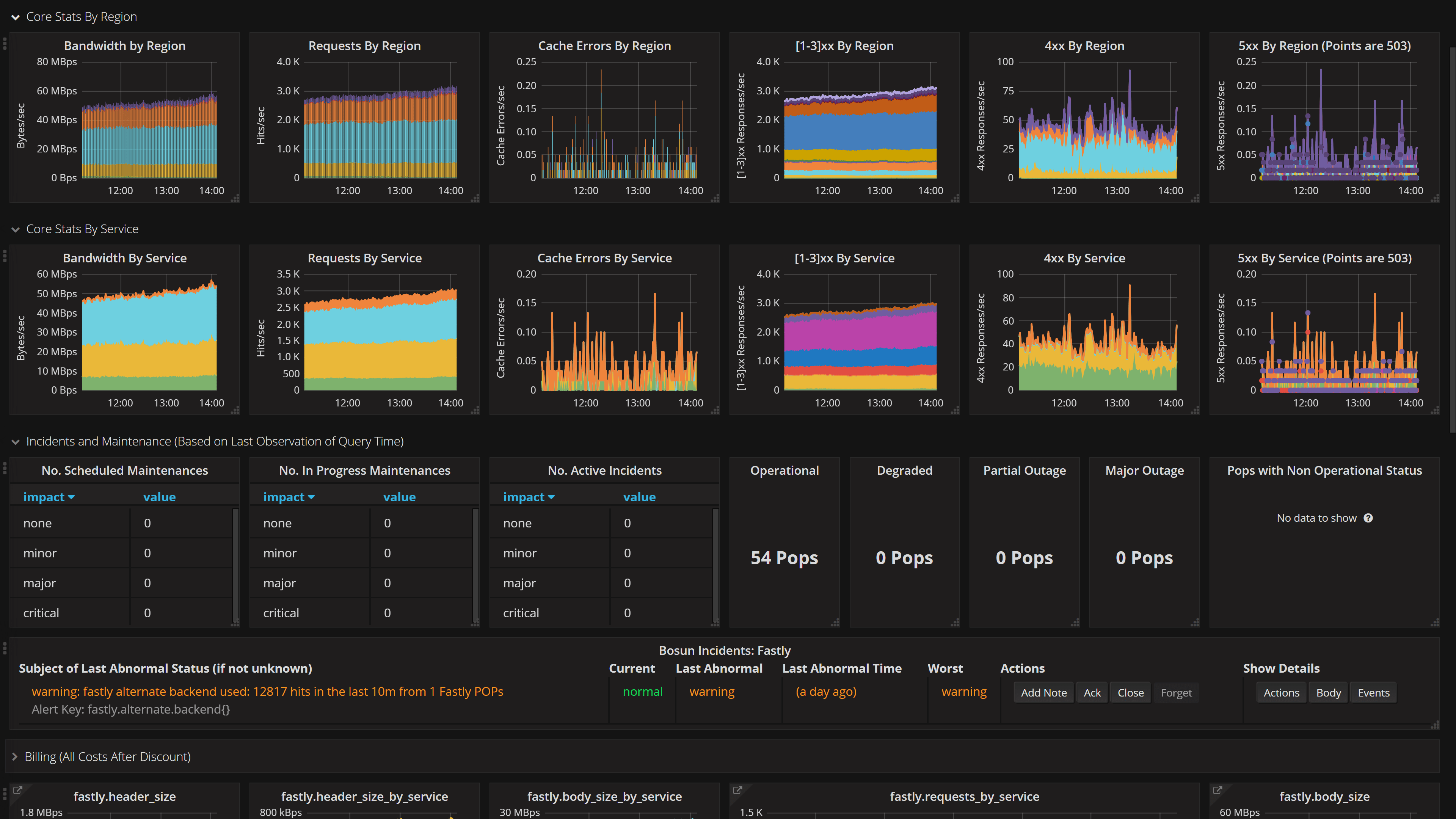
这只是任意一个我觉得很酷的仪表板。这是按来源国家划分的流量。它被分成了几个主要的大洲,你可以看到,当人们醒着的时候,流量是如何在世界各地周而复始地波动的。
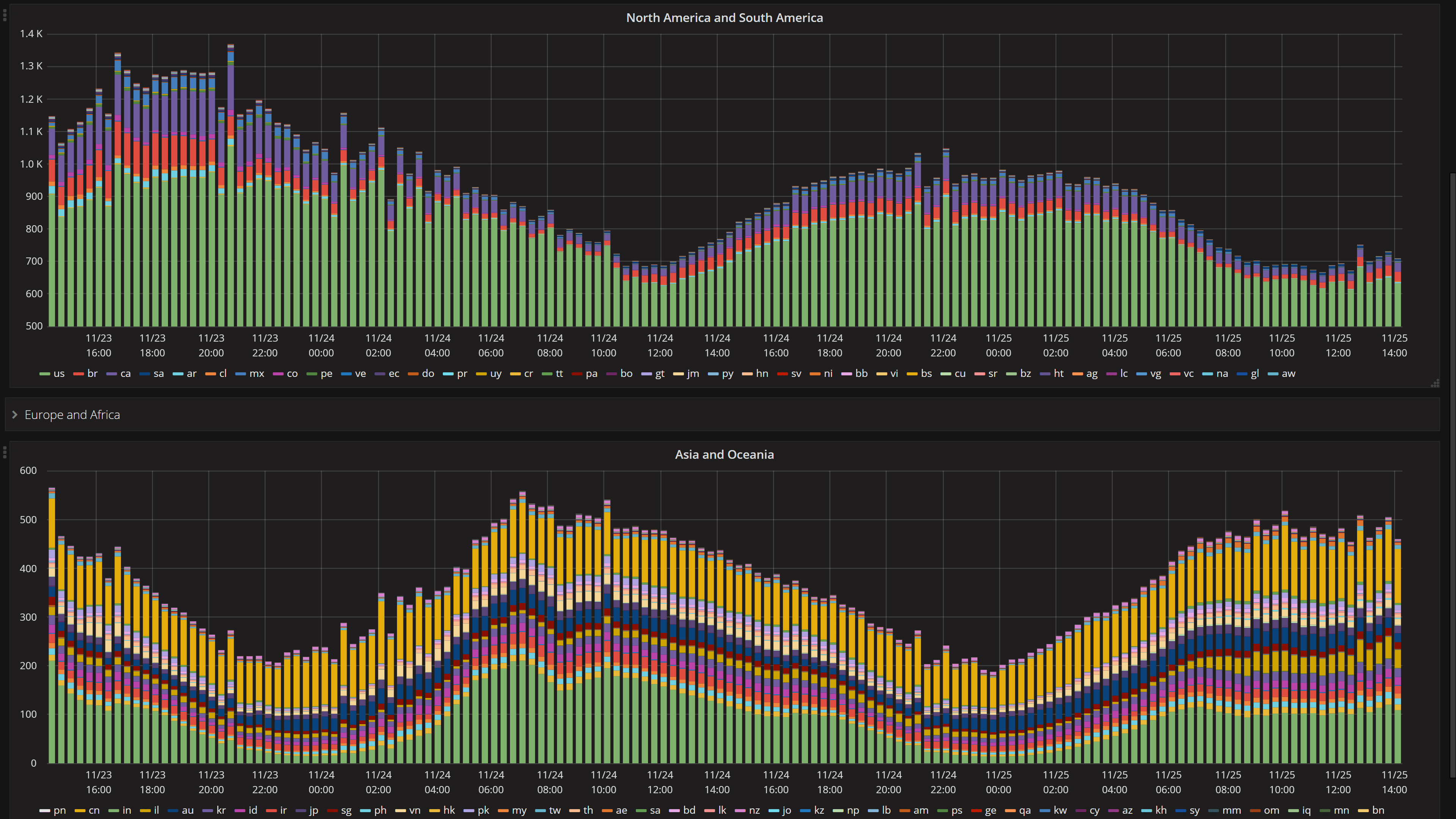
如果你在 Twitter 上关注我了,你可能会注意到.NET Core存在一些垃圾收集问题。不过,需要对这一点进行关注并不是一个新需求。下面这个仪表板我们已经使用很多年了:
注意:不要用上面的数字来做任何规模的衡量,这些截图是在假日周末拍摄的。
客户端计时
请注意,上面提到的所有内容都是服务器端的。你到现在还在考虑上面的内容吗?如果你是这样做的,那就太棒了。很多人直到这成为问题时才会进行这样的思考。但这一直都很重要。
重要的是要记住,你渲染网页的速度并不重要。唯一重要的是用户认为你的网站有多快。感觉有多快?这体现在客户体验的许多方面,从最初的页面绘制到内容闪烁(请不要闪烁或移动!)、广告呈现等等。
这里要考虑的因素有,例如,以下动作花了多长时间:
通过 TCP 连接?(HTTP/3还没到来)
TLS 连接协商?
完成请求发送?
获得第一个字节?
获得最后一个字节?
页面的初步绘制?
发出页面资源请求?
渲染所有东西?
附加 JavaScript 处理程序?
这些对用户体验很重要。我们的问题页渲染在 18 毫秒以内。我觉得这太棒了。我甚至可能有偏见。但是,对于用户来说,如果要花很长时间才能打开,那么这就是废话。
那么,我们能做些什么呢?几年前,我根据我们的需要仓促构建了一个可以在浏览器中使用的客户端计时管道。其理念很简单:使用 Web 浏览器提供的导航计时API并记录时间。就是这样。还有一些完整性检查(你不会相信 NTP 时钟校正的数值,在渲染期间,它会从同步中产生无效的计时,导致时钟倒退)。对于 Stack Overflow(或我们网络中的任何问答站点)5%的请求,我们会请求浏览器发送这些计时。我们可以随意调整这个百分比。
要了解其工作原理,请访问teststackoverflow.com。下面是一个示例:

准确地讲,这并不是监控,但有点像。我们使用它来测试一些事情,比如,当我们切换到HTTPS时,连接时间在世界范围内对每个人的影响(这就是我最初创建计时管道的原因)。当我们添加DNS提供商时也使用了它,在经历过2016年的Dyn DNS攻击之后,我们现在已经有了多个提供商。
现在,我们有了一些数据。如果我们从 5%的流量中获得了这些数据,将其发送到服务器,放入 SQL Server 中一个庞大的聚簇列存储中,并在此过程中把部分指标发送到 Bosun,那么我们就得到了一些有用的东西。我们可以在配置前后进行测试,查看数据。我们也可以关注当前的流量状况并查找问题。在最后一部分,我们使用了 Grafana,如下图所示:
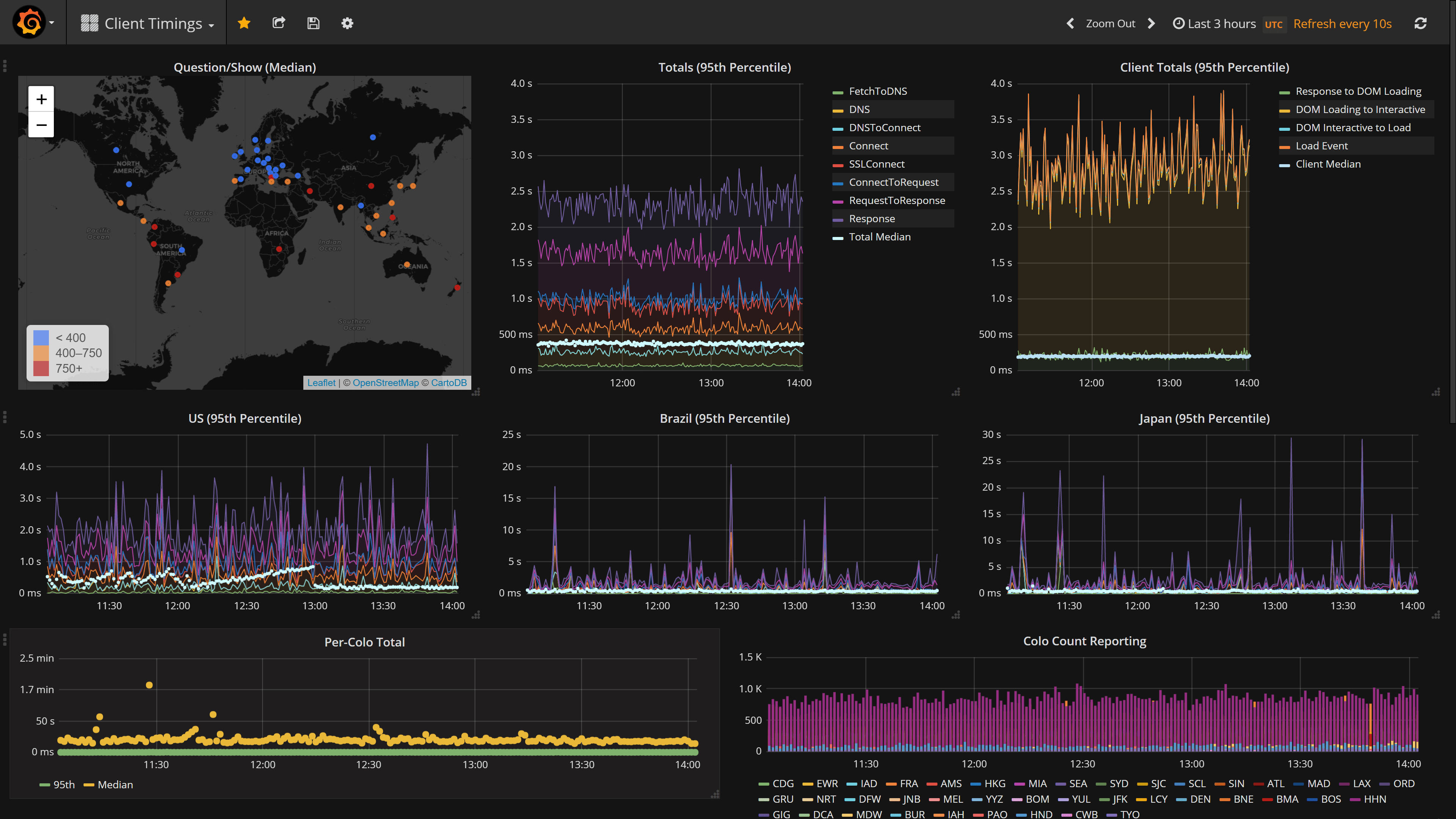
注意:这是一个 95 百分位视图,总渲染时间的中值是靠近底部的白点(大多数时间小于 500 毫秒)。
MiniProfiler
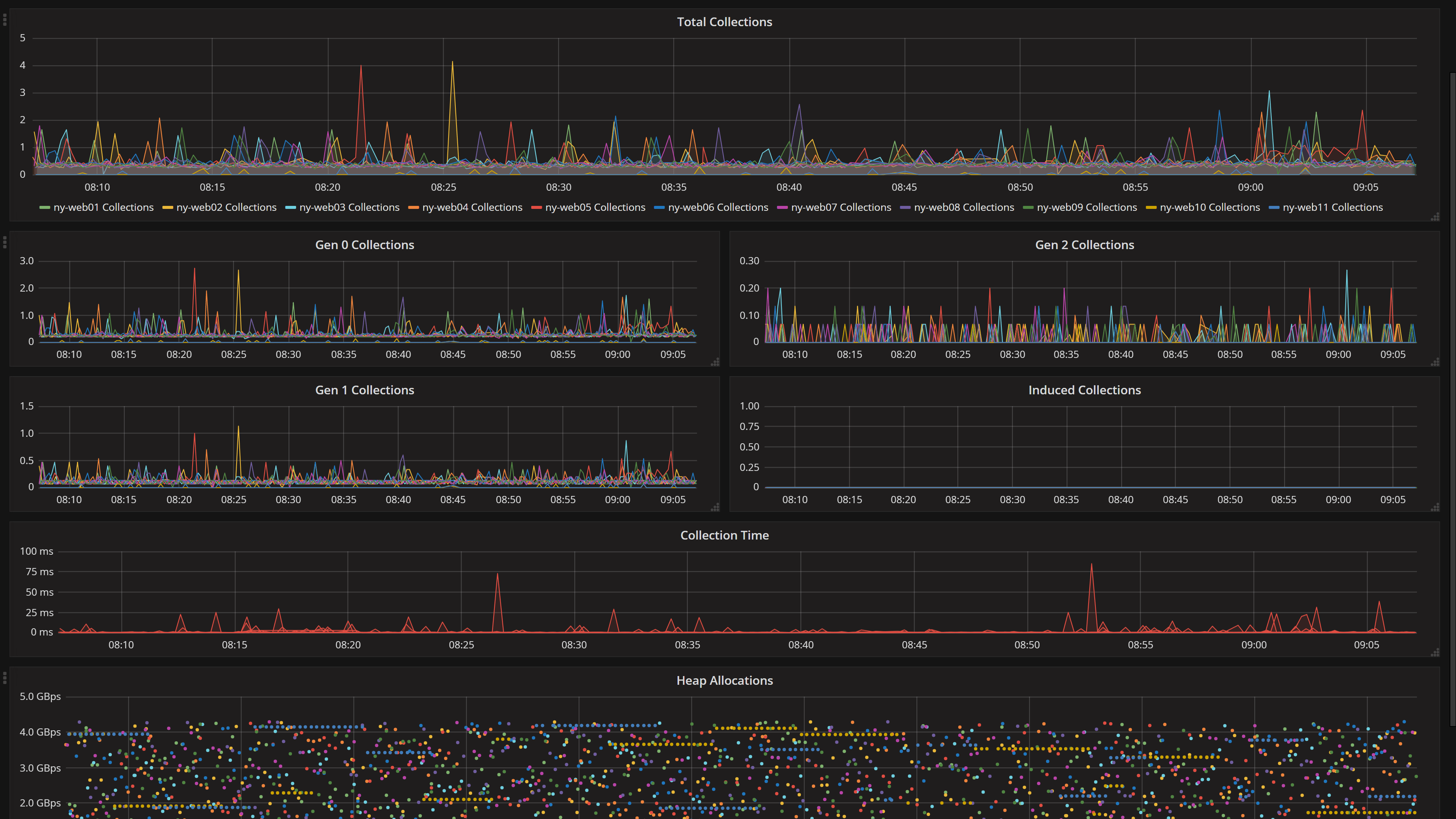
有时候,你希望捕获的数据比上面的场景更具体也更详细。在我们的情况下,我们在大约十年前就决定,我们想知道网页渲染每一个页面视图需要多长时间。对于任何东西,监控和查看同样重要。一个比较好的实现方法是,使它在你查看的每一个页面视图上都可见。于是,MiniProfiler诞生了。它有几种版本(项目略有不同):.NET、Ruby、Go和Node.js。我们在这里将看下我维护的.NET 版本:

在默认情况下,这是你能看到的所有数值,但是你可以展开它,以树的形式查看什么事情花费了多长时间。你可以点击到那里的连接,快速查看正在运行的 SQL 或 Elastic 查询,或发起的 HTTP 调用,或获取的 Redis 键等等,如下图所示:

注意:如果你正在想,这比我们所说的问题平均渲染耗时(甚至是第 99 百分点)要长得多。是的,这是因为我在这里多加载了很多东西。
由于 MiniProfiler 的开销非常小,所以我们可以在每个请求上运行它。为此,我们在 Redis 中保留了每个 MVC 路由的性能分析样本。例如,对于任何路由,我们会保留给定时间内最慢的 100 条性能分析样本。这让我们能够看到哪些用户可能会点击我们没有点击的内容。或者,可能有匿名用户使用了不同的查询,而这个查询很慢……我们需要能够看到这些。我们可以看到 Bosun 中变慢的路由,HAProxy 日志中的点击率,以及需要深入研究的性能分析快照。所有这些都不需要查看任何代码,这是一个强大的概览组合。MiniProfiler 非常棒,但在这里,它也是一个更大的工具集的一部分。
以下是快照和聚合汇总示例:
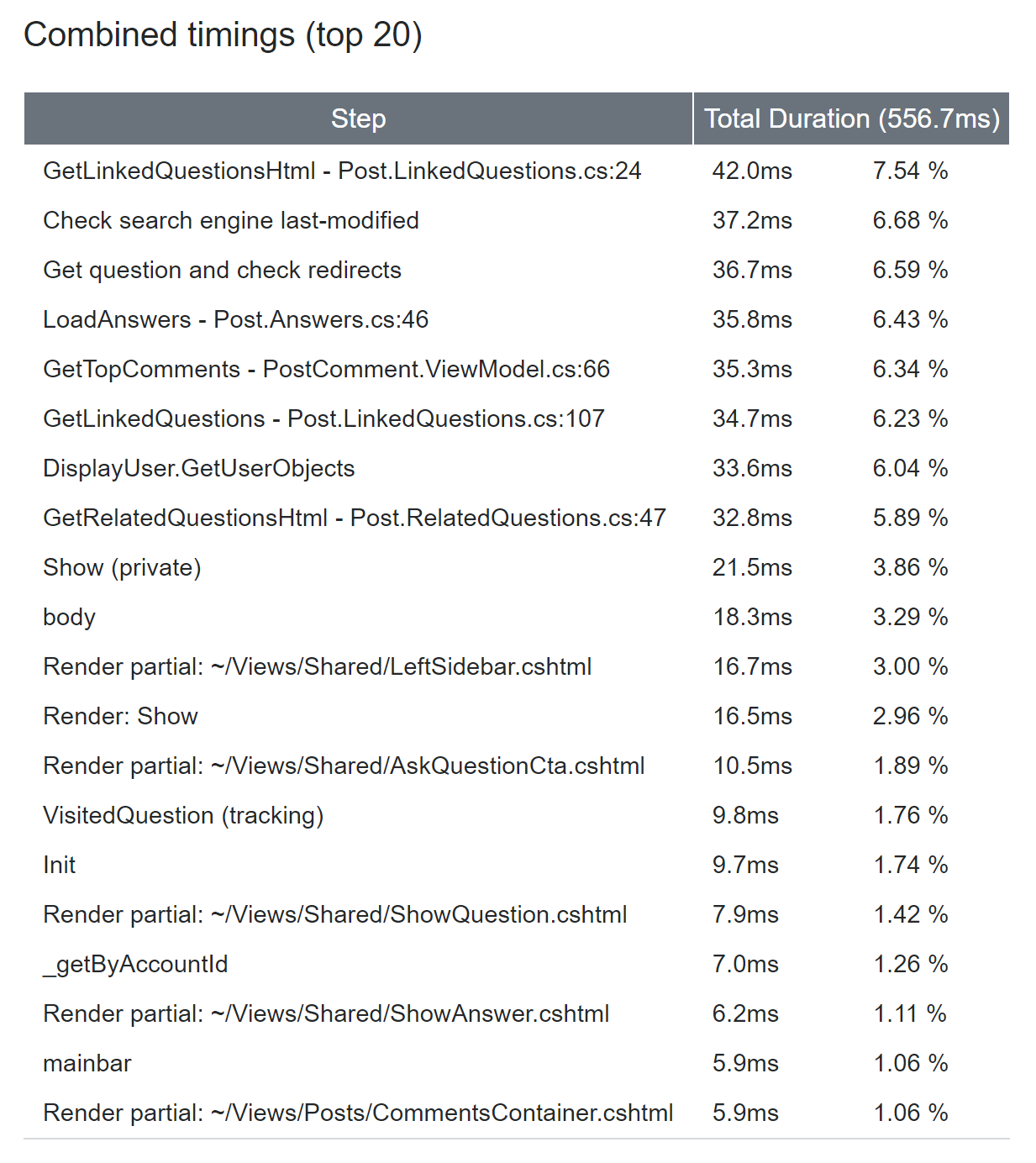
我们或许应该在库中加入一个这样的例子。我会尽快抽出时间来做这件事的。
MiniProfiler 由Marc Gravell、Sam Saffron和Jarrod Dixon创建。从版本 4.x 开始,我成了主要的维护者,但这些先生会对它的存在负责。我们在所有的应用程序中都使用了 MiniProfiler。
注意:看到截图中的那些 GUID 了吗?这是 MiniProfiler 生成的一个 ID,我们现在用它作为“请求 ID”,我们会把它记录到 HAProxy 日志中,对于任何异常,亦是如此。像这样的小东西有助于把世界联系在一起,让你更容易把事情联系起来。
Opserver
那么,Opserver是什么?这是一个基于 Web 的仪表板和监控工具,这是我在 SQL Server 的内置监控欺骗了我们之后开始创建的。大约 5 年前,我们遇到了一个问题,SQL Server AlwaysOn 可用性组在 SSMS 仪表板上显示为绿色(基于主服务器),但是副本已经好几天没有新数据了。这是一个监控出现严重问题的例子。当时的情况是 HADR 线程池耗尽,并停止更新处于“一切正常(all good)”状态的视图。这样的设计不一定是缺陷,但是当缓存/存储一个事物的状态时,需要有一个时间戳。如果它在时间段内没有更新,那就是一个红色警告。状态的一切都不可信。无论如何,进入 Opserver。它所做的第一件事就是监视每个 SQL 节点,而不是信任主节点。
从那时起,我就针对其他我们想在一个基于 Web 的快速视图中查看的系统添加了监控。我们可以看到所有服务器(基于 Bosun、Orion 或直接基于 WMI)。以下是 Opserver 现状的概要介绍。
Opserver:主仪表板
首页仪表板是一个服务器列表,显示了什么在运行。用户可以根据名称、服务标记、IP 地址、VM 主机等进行搜索。你还可以下钻,查看每个节点上 CPU、内存和网络的全时历史图。
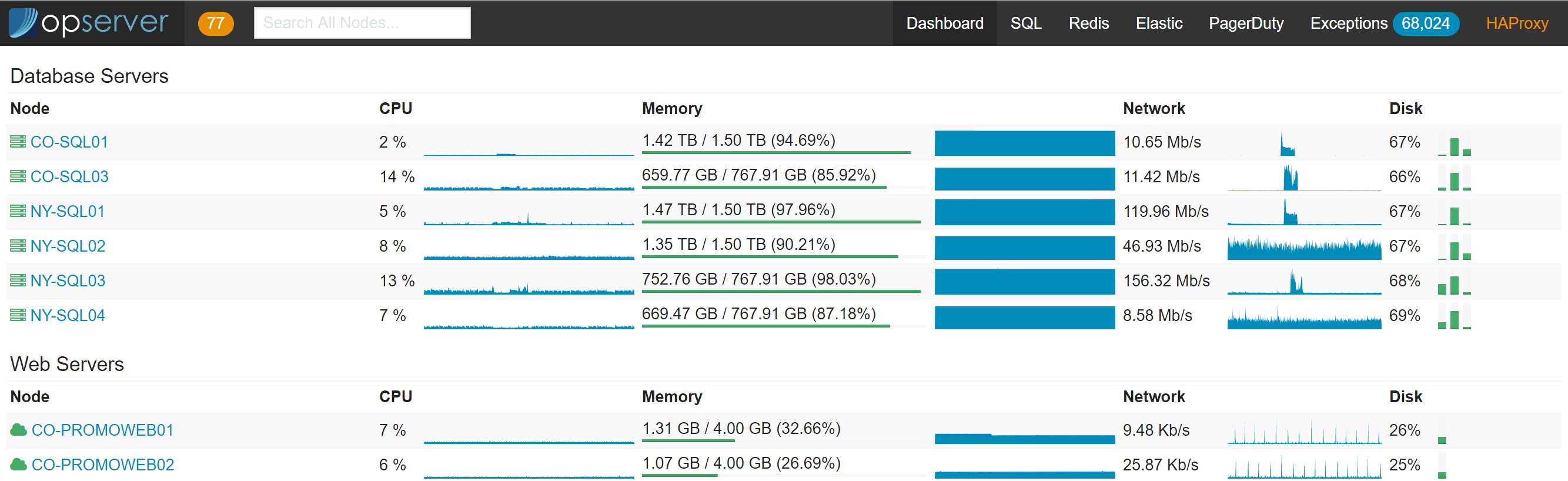
节点如下所示:
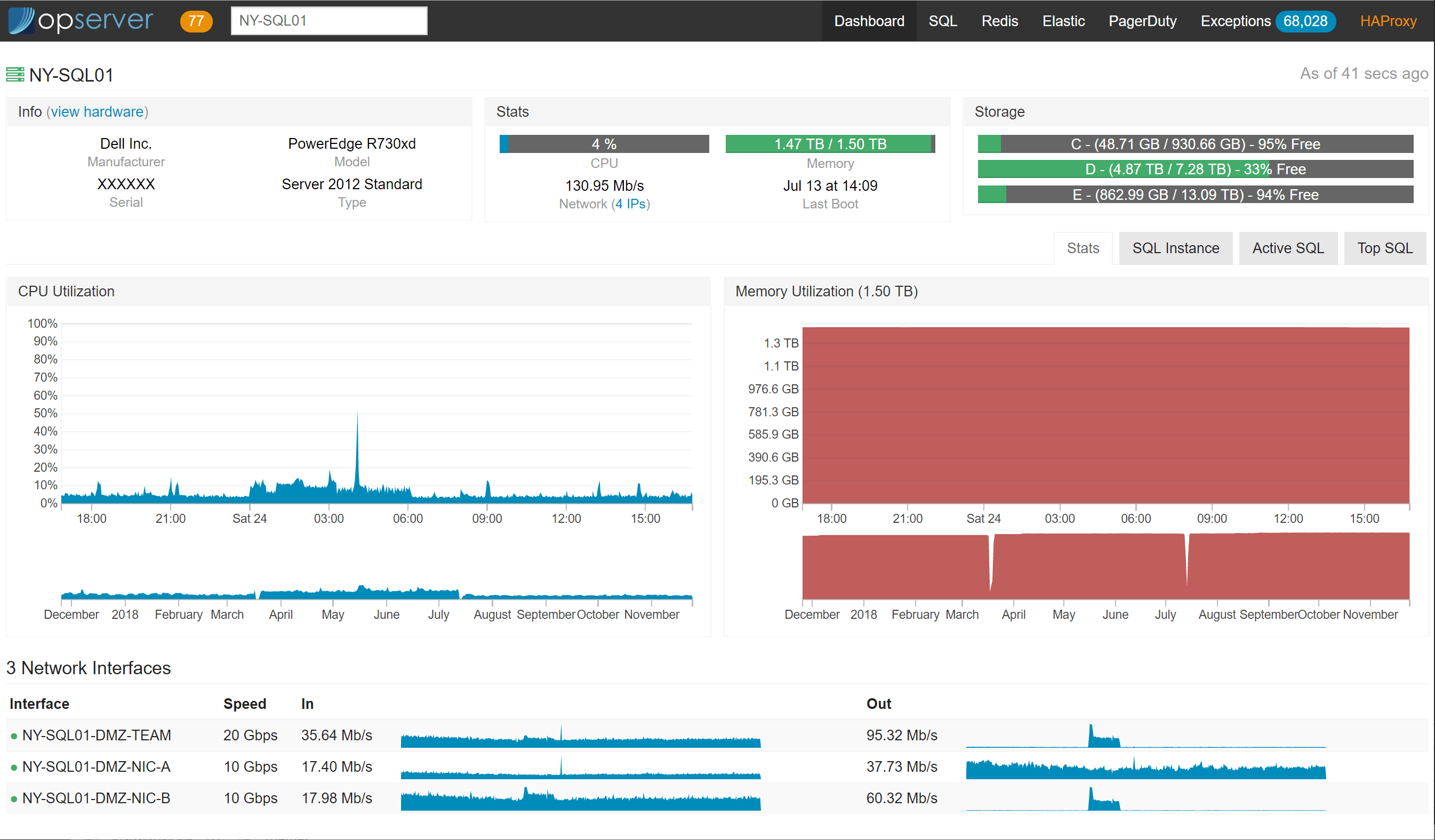
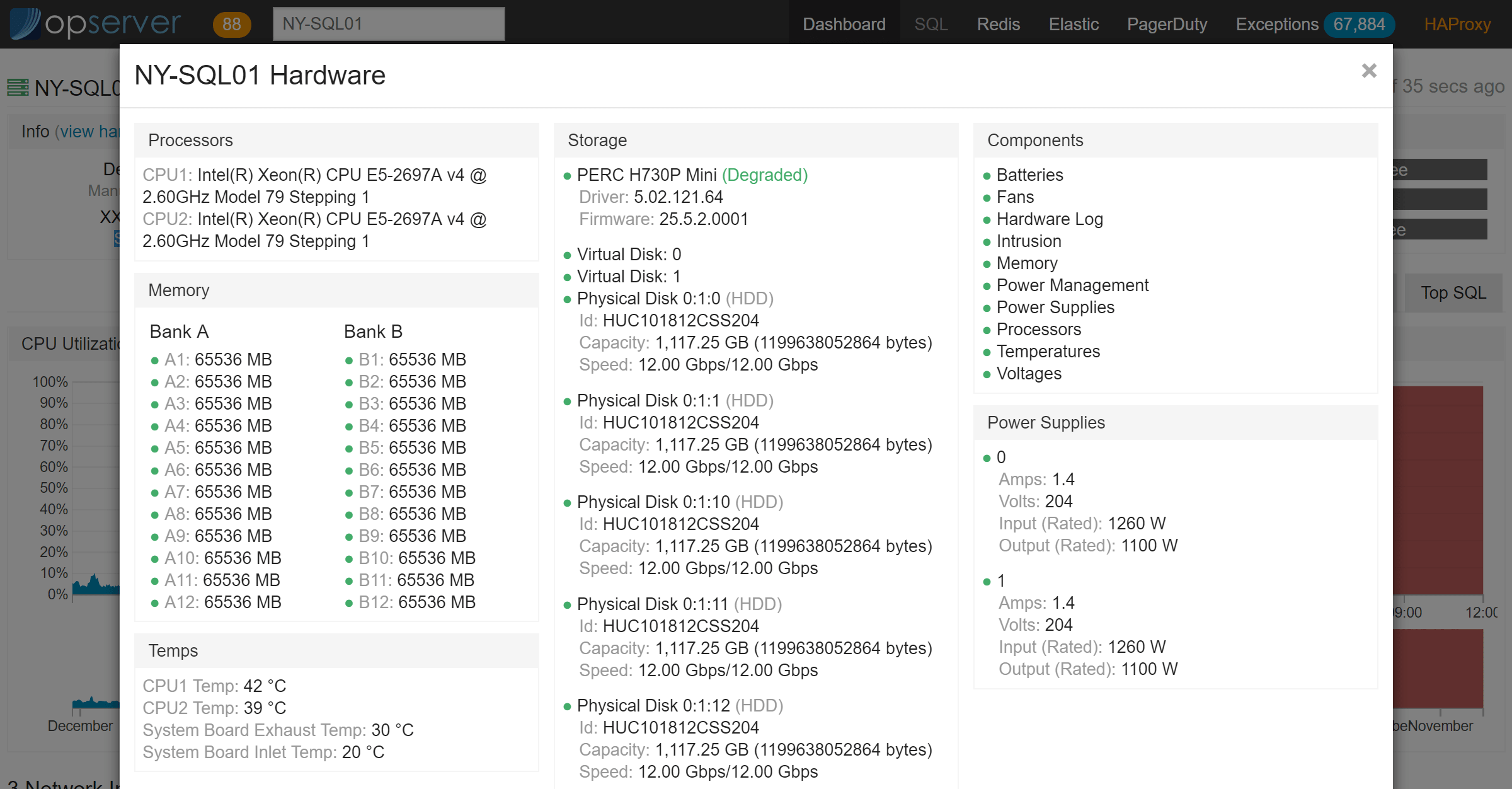
如果使用 Bosun,并运行 Dell 服务器,那么我们会像下面这样添加硬件元数据:
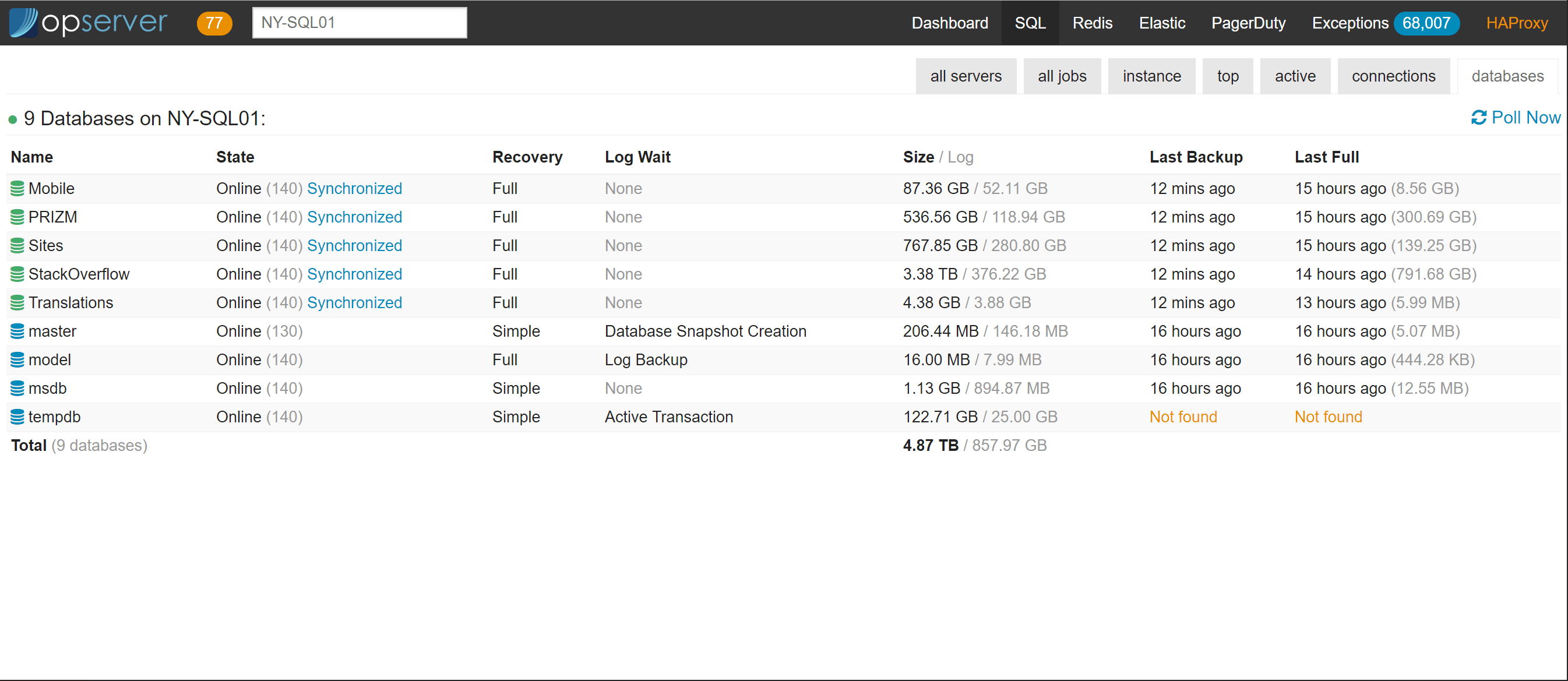
Opserver:SQL Server
在 SQL Server 仪表板中,我们可以看到所有服务器的状态以及可用性组的运行情况。在任何给定的时间,我们可以看到每个节点有多少活动以及哪个是主节点(蓝色部分)。下面的部分是AlwaysOn可用性组,我们可以看到每个组的主节点是哪台服务器,副本滞后多少,以及备份了多少队列。如果事情变糟,一个副本不健康,就会出现更多的指示器,比如,显示哪些数据库有问题,主服务器上所有与 T-logs 相关的驱动器的空闲磁盘空间(因为如果副本继续宕机,它们将开始增长):
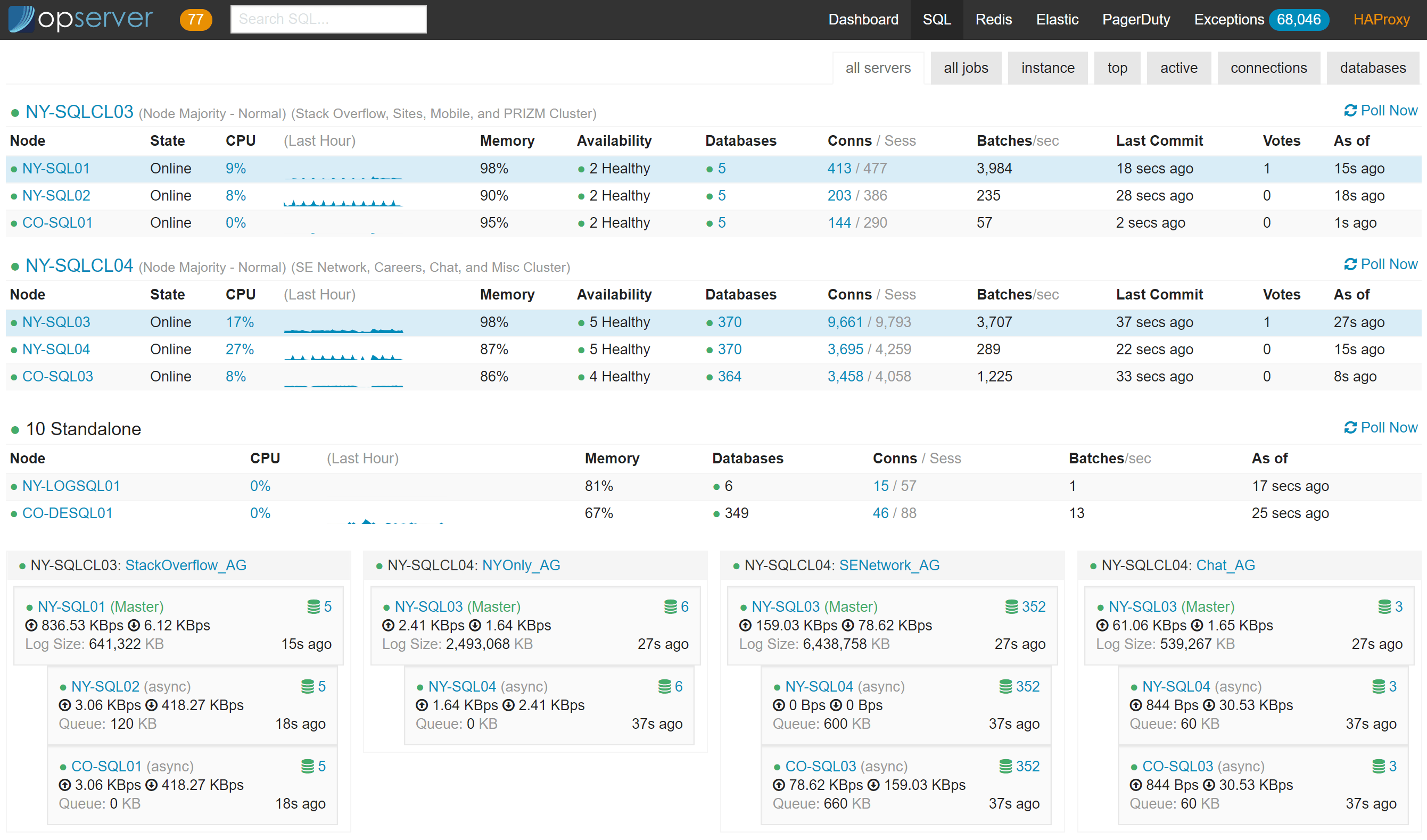
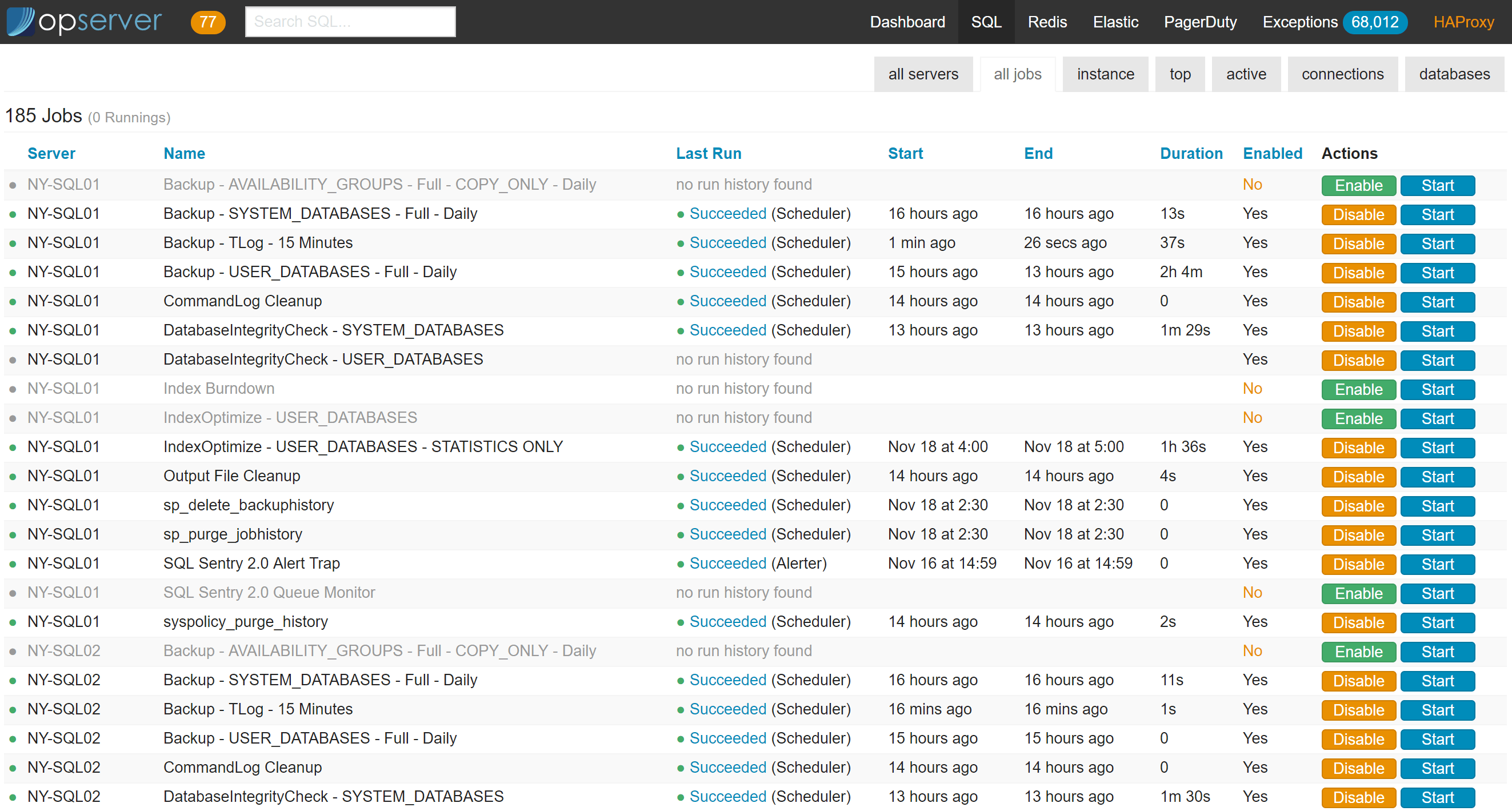
还有一个顶级的“所有作业(all-jobs)”视图,可以用于快速监控以及启用/停用:
在单实例视图中,我们可以看到该服务器的统计信息、缓存等,这些是我们随着时间推移发现的比较重要的指标。
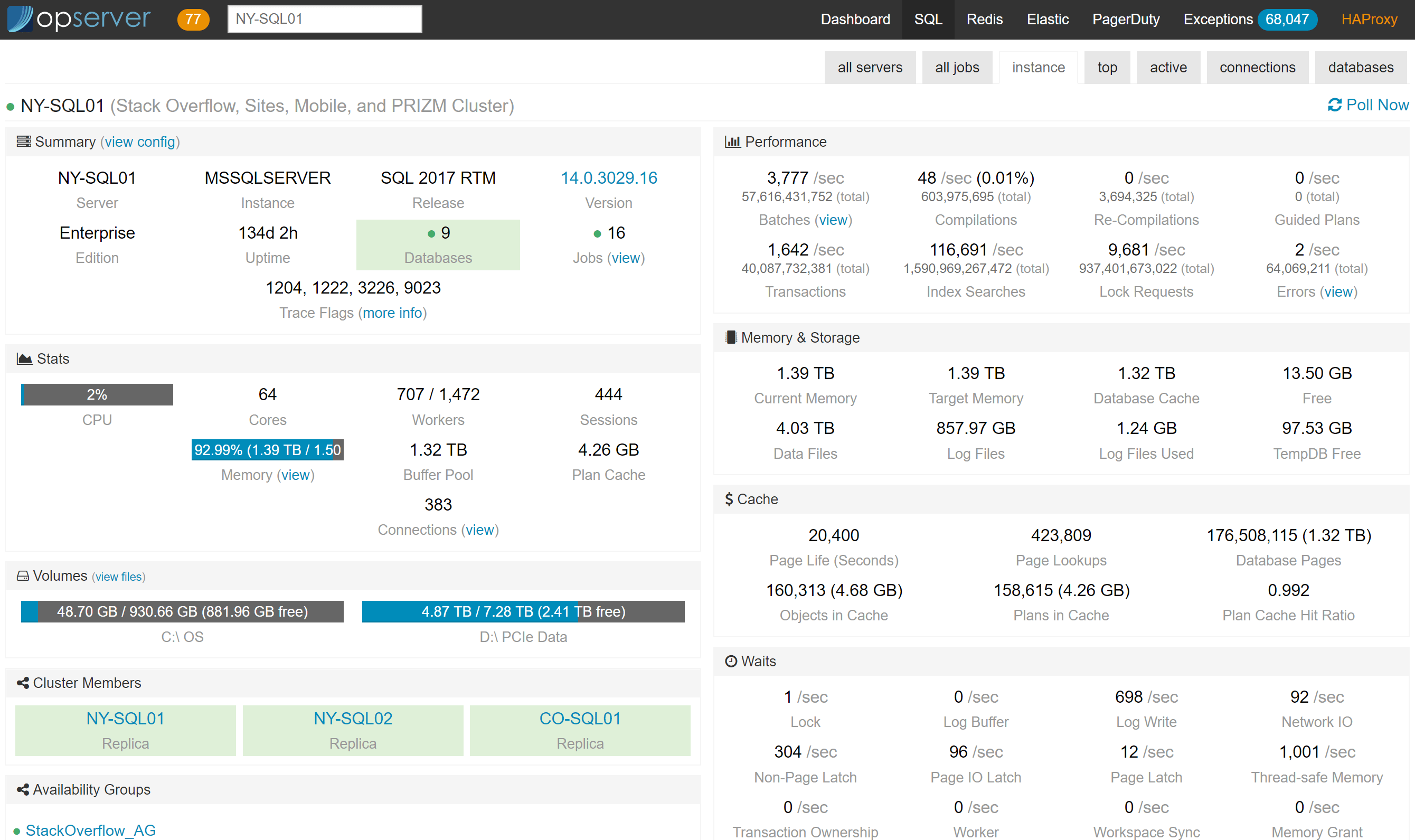
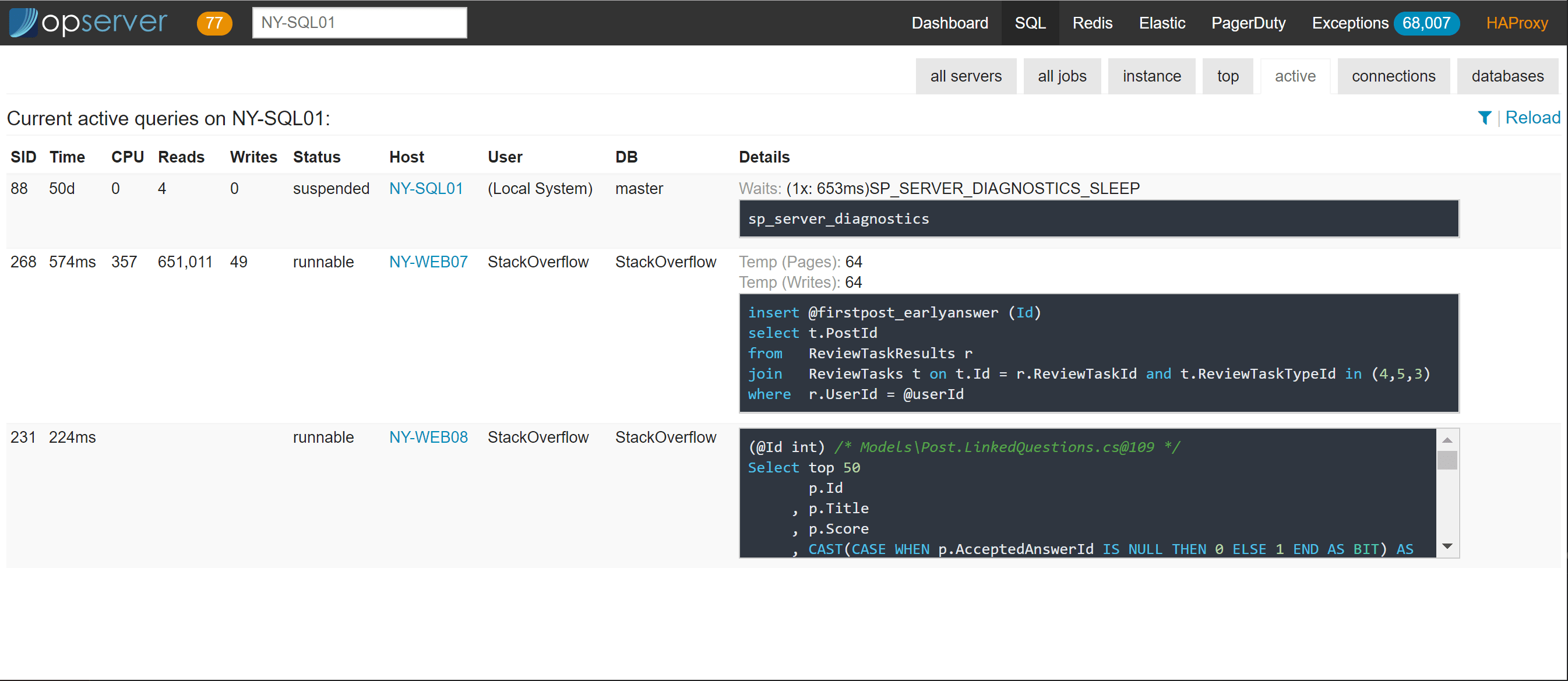
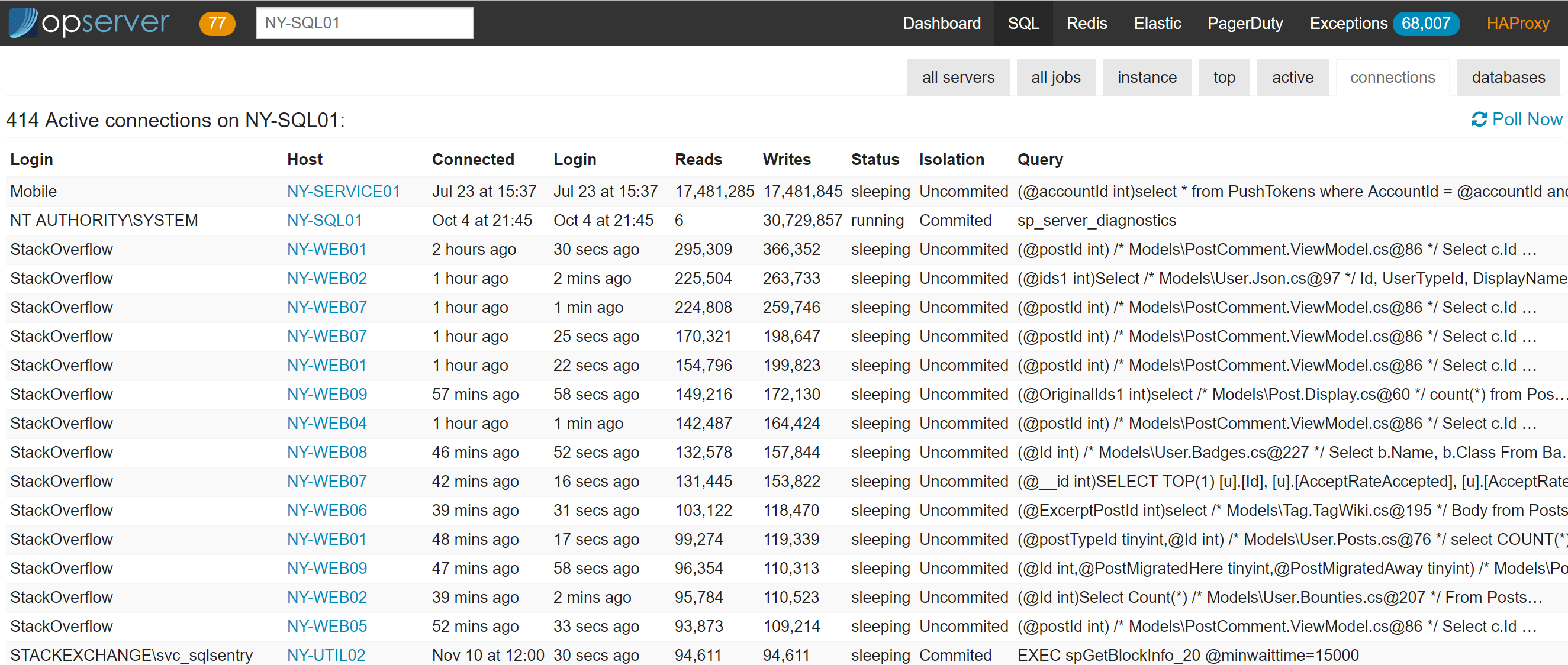
对于每个实例,我们还会报告顶级查询(基于计划缓存,而不是查询存储)、当前活动的查询(基于sp_whoisactive)、连接和数据库信息。
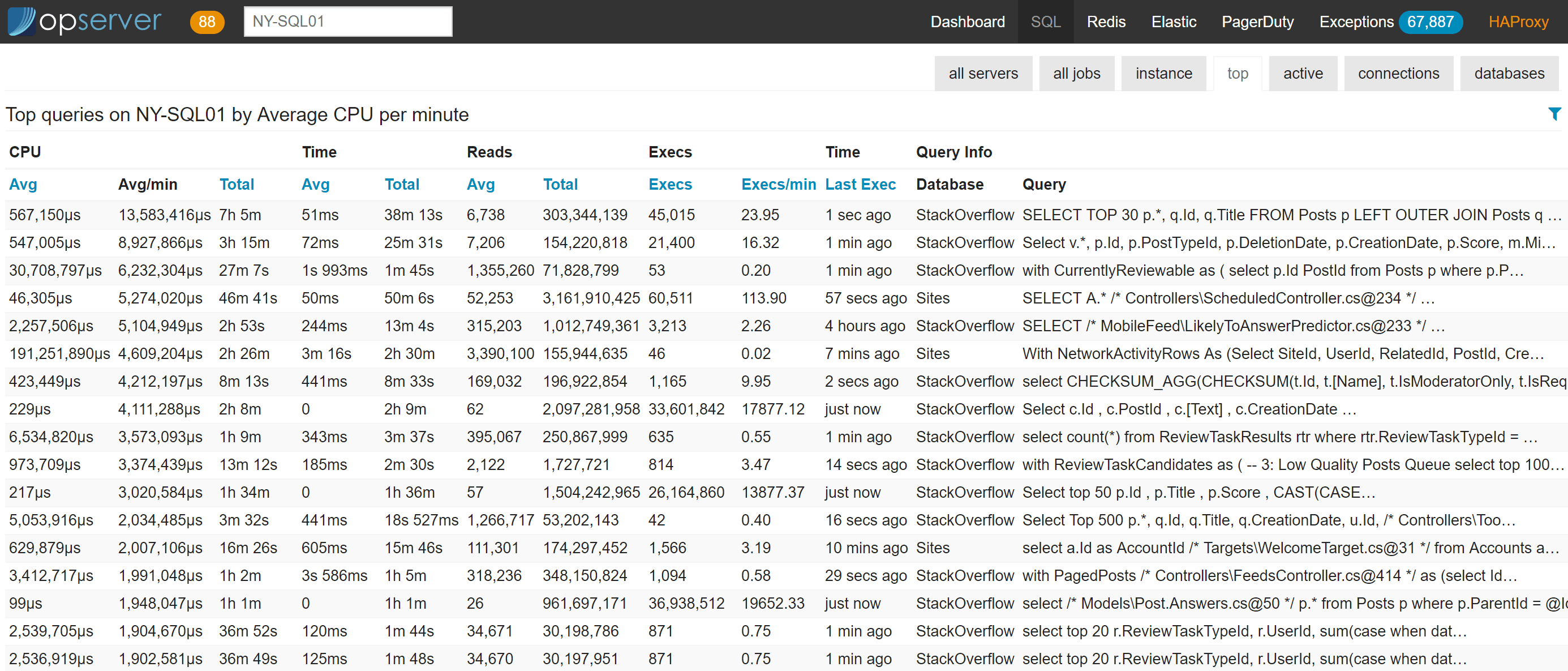
如果你想下钻查看一个顶级查询的详细信息,则可以看到类似下图所示的内容:
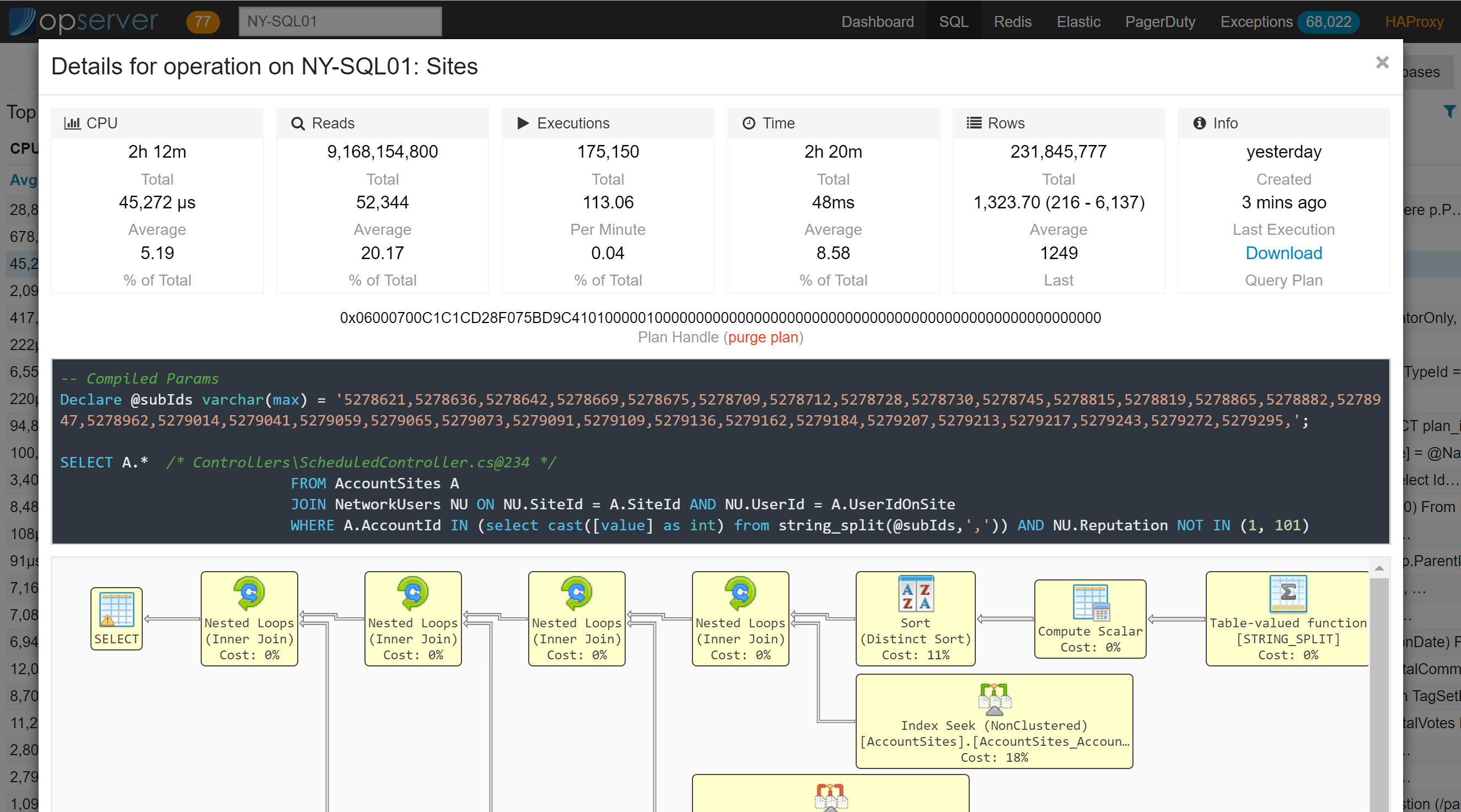
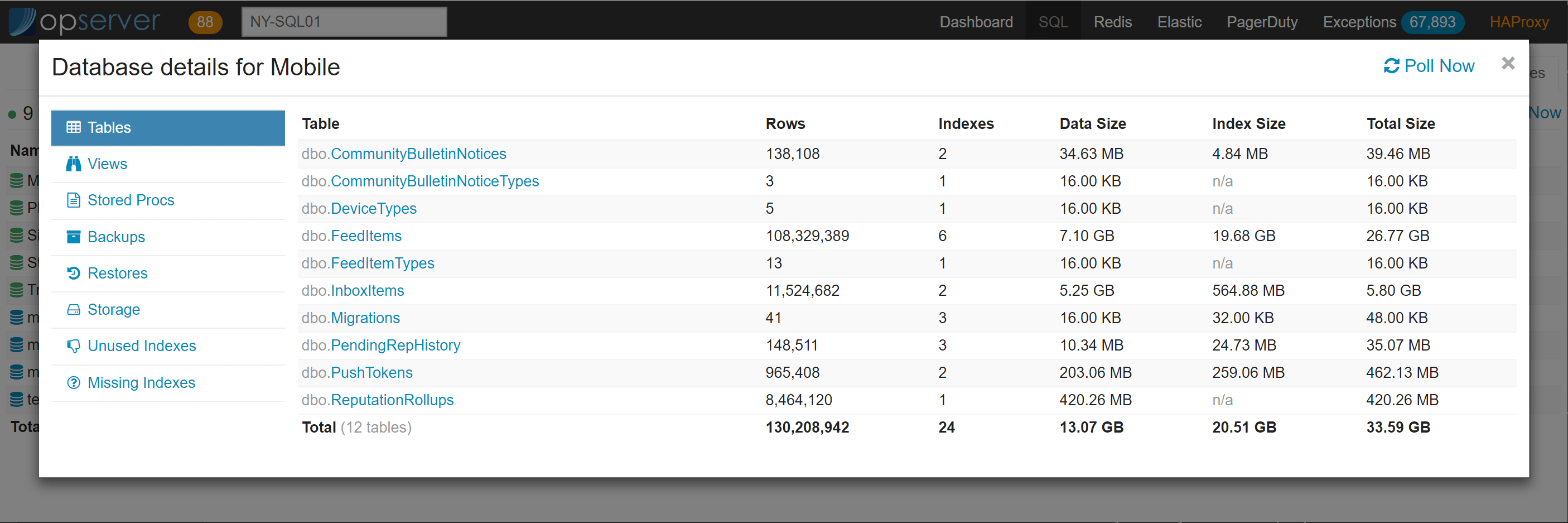
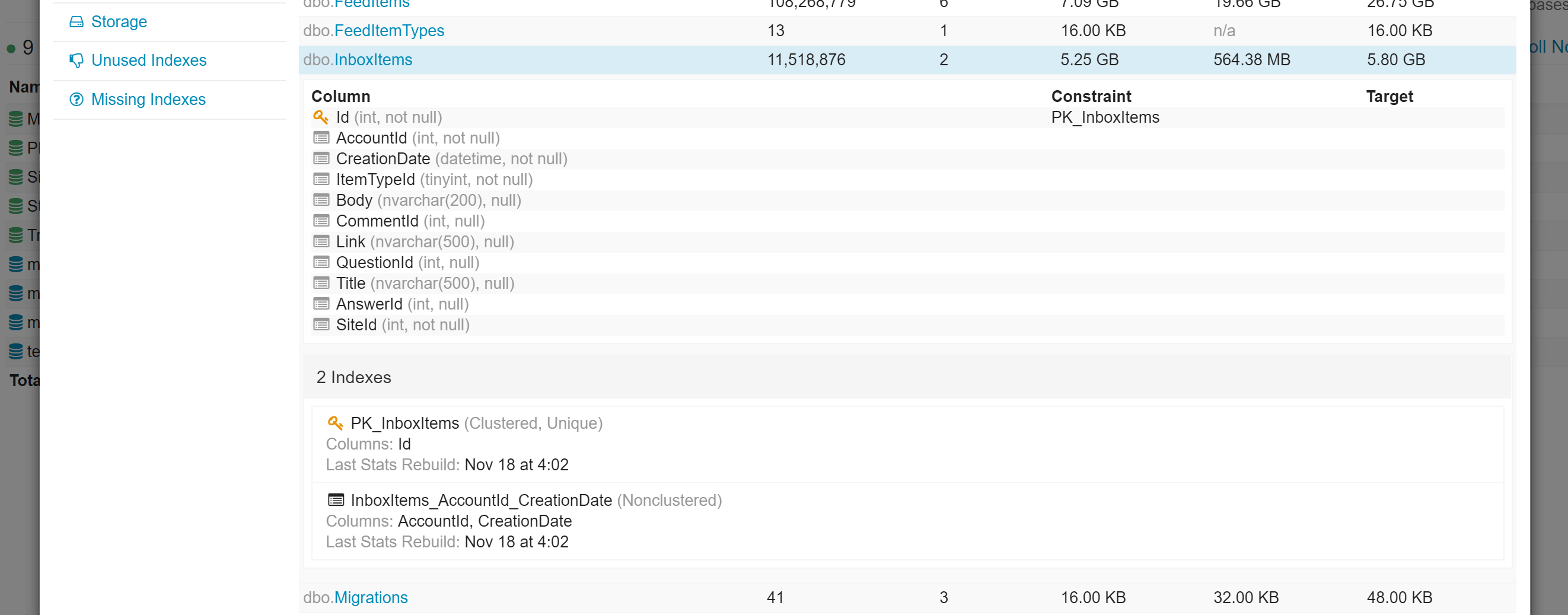
在数据库视图中,可以下钻查看表、索引、视图、存储过程和存储使用情况等信息。
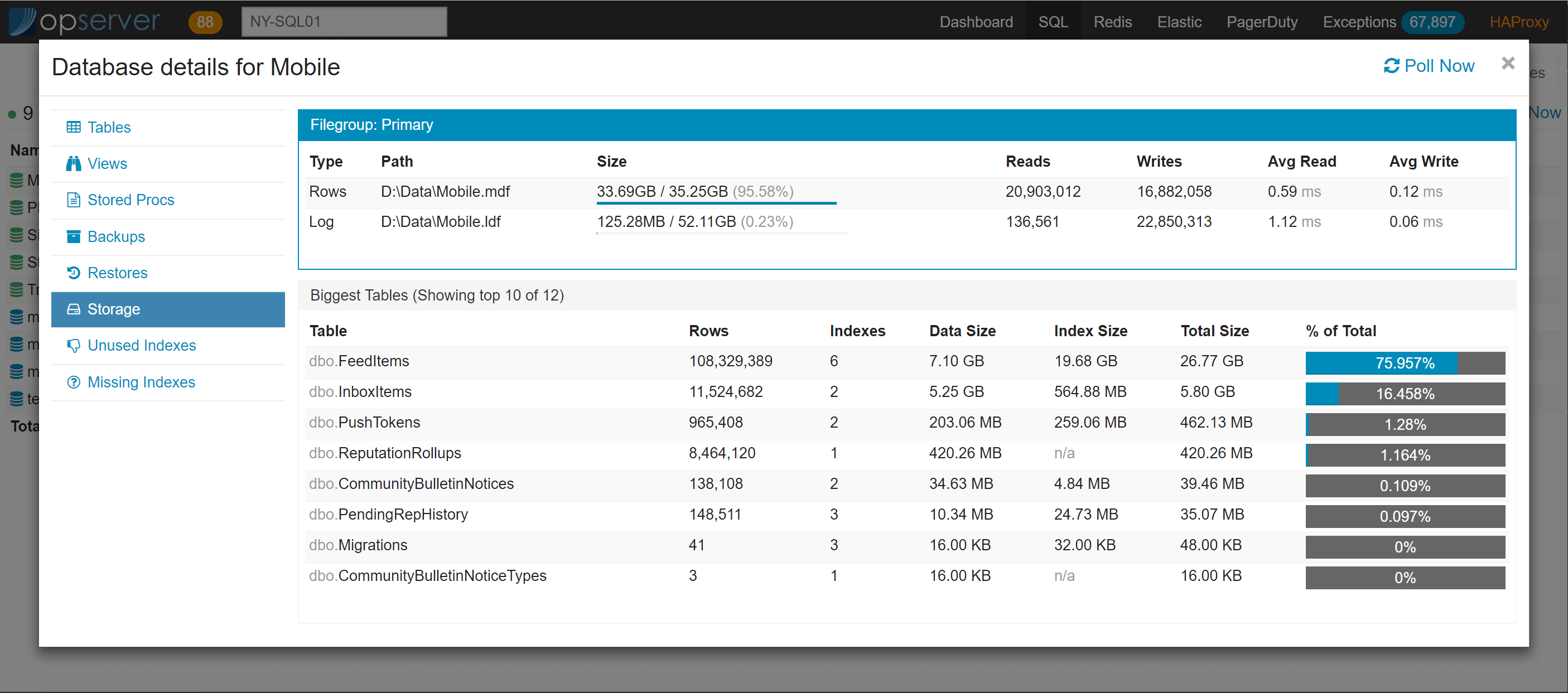
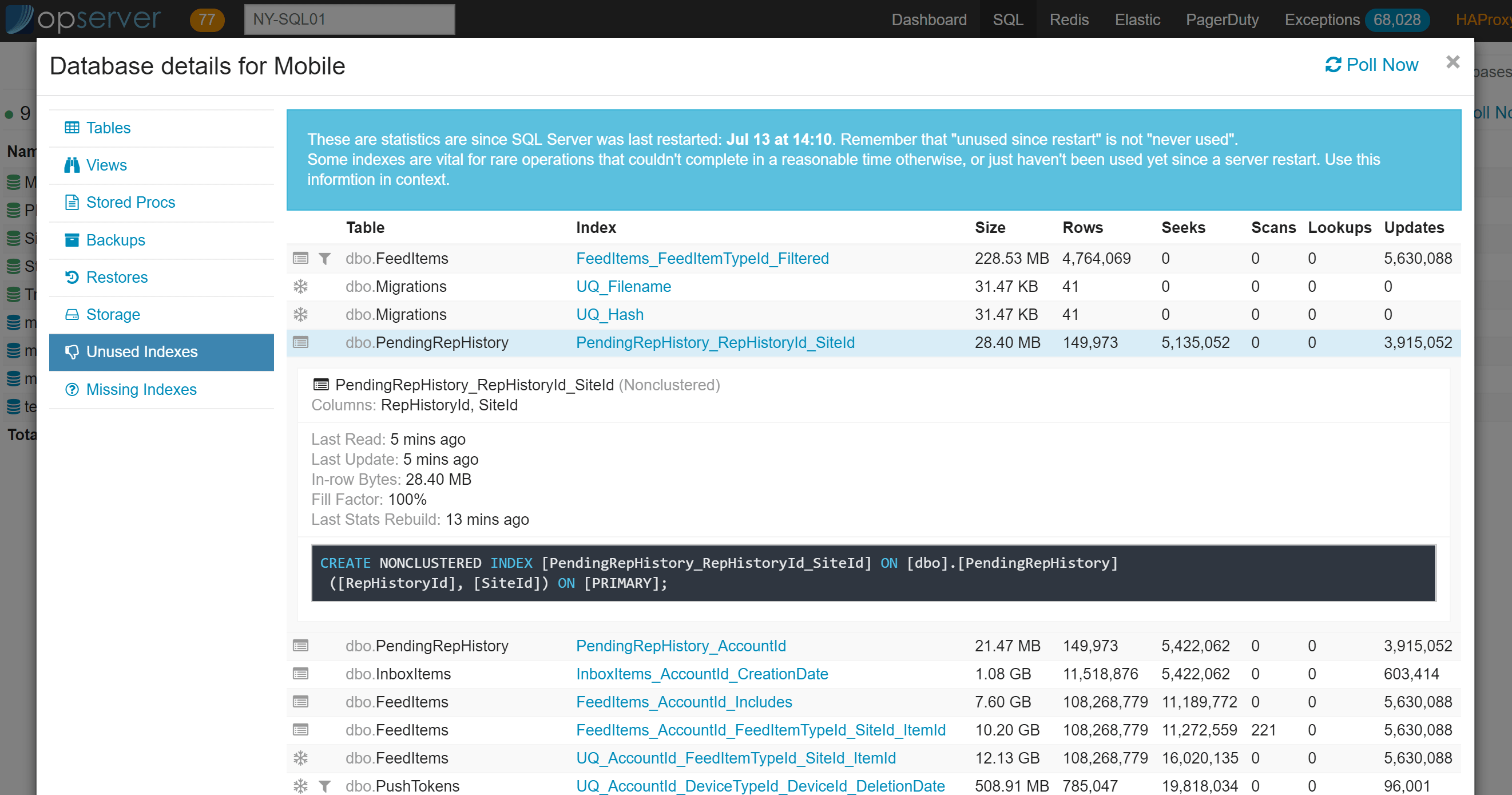
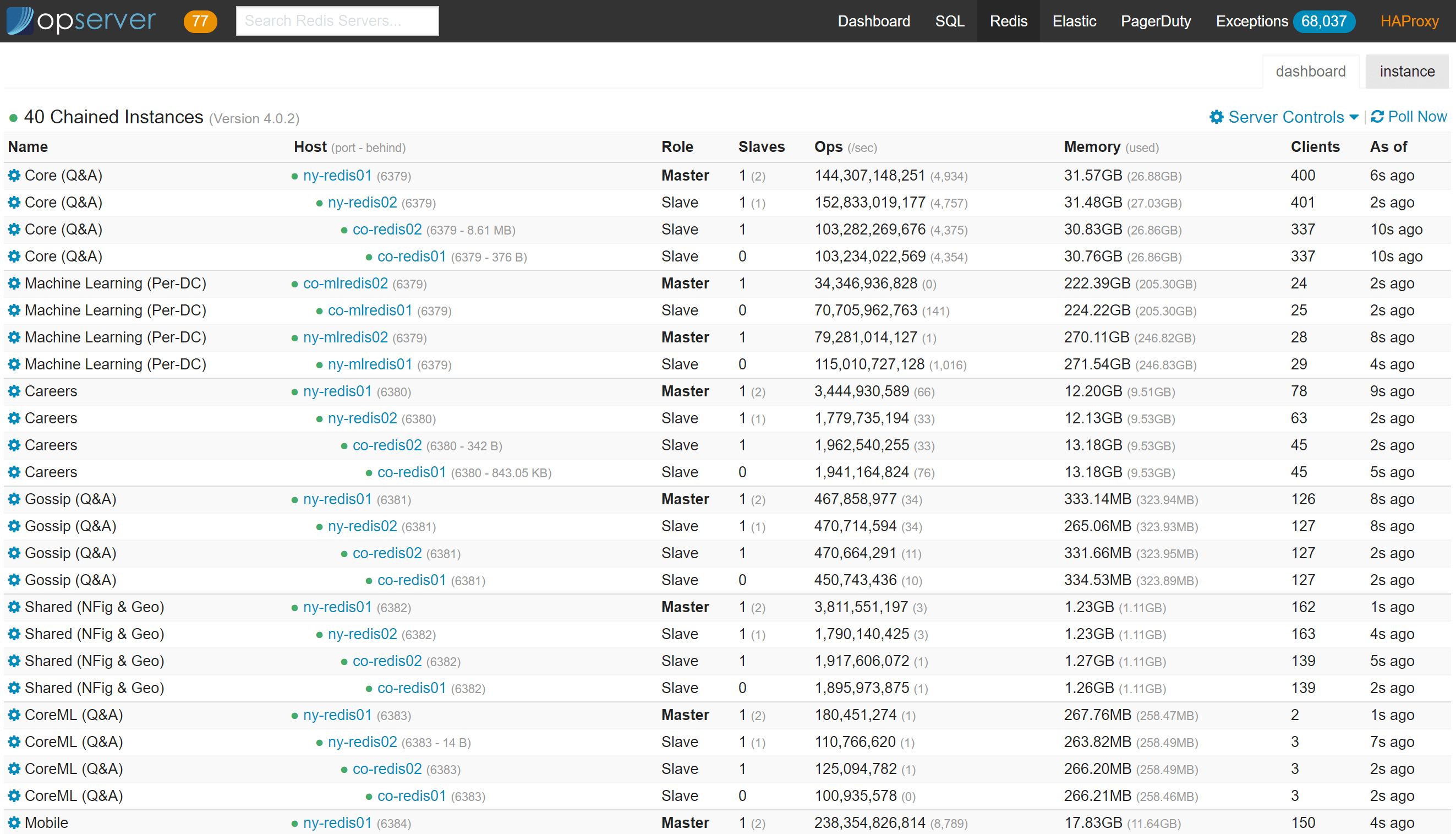
Opserver:Redis
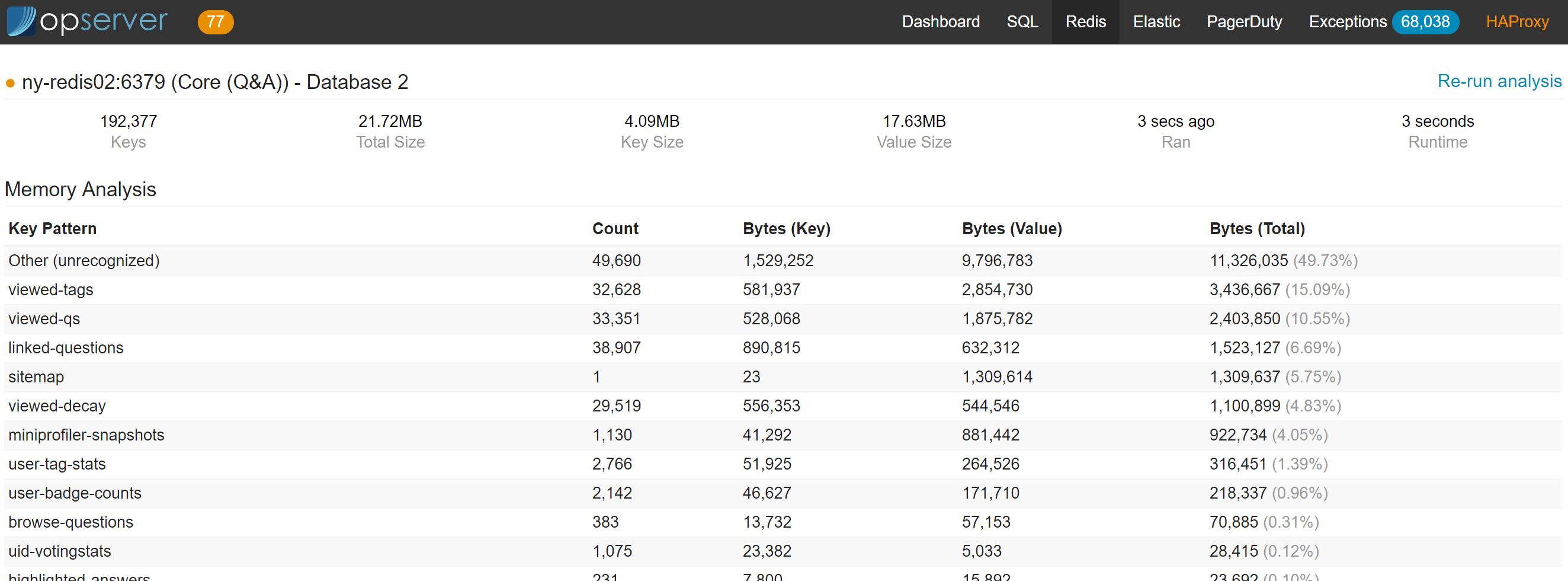
对于 Redis,我们希望看到主节点和副本节点组成的拓扑链以及每个实例的总体状态。
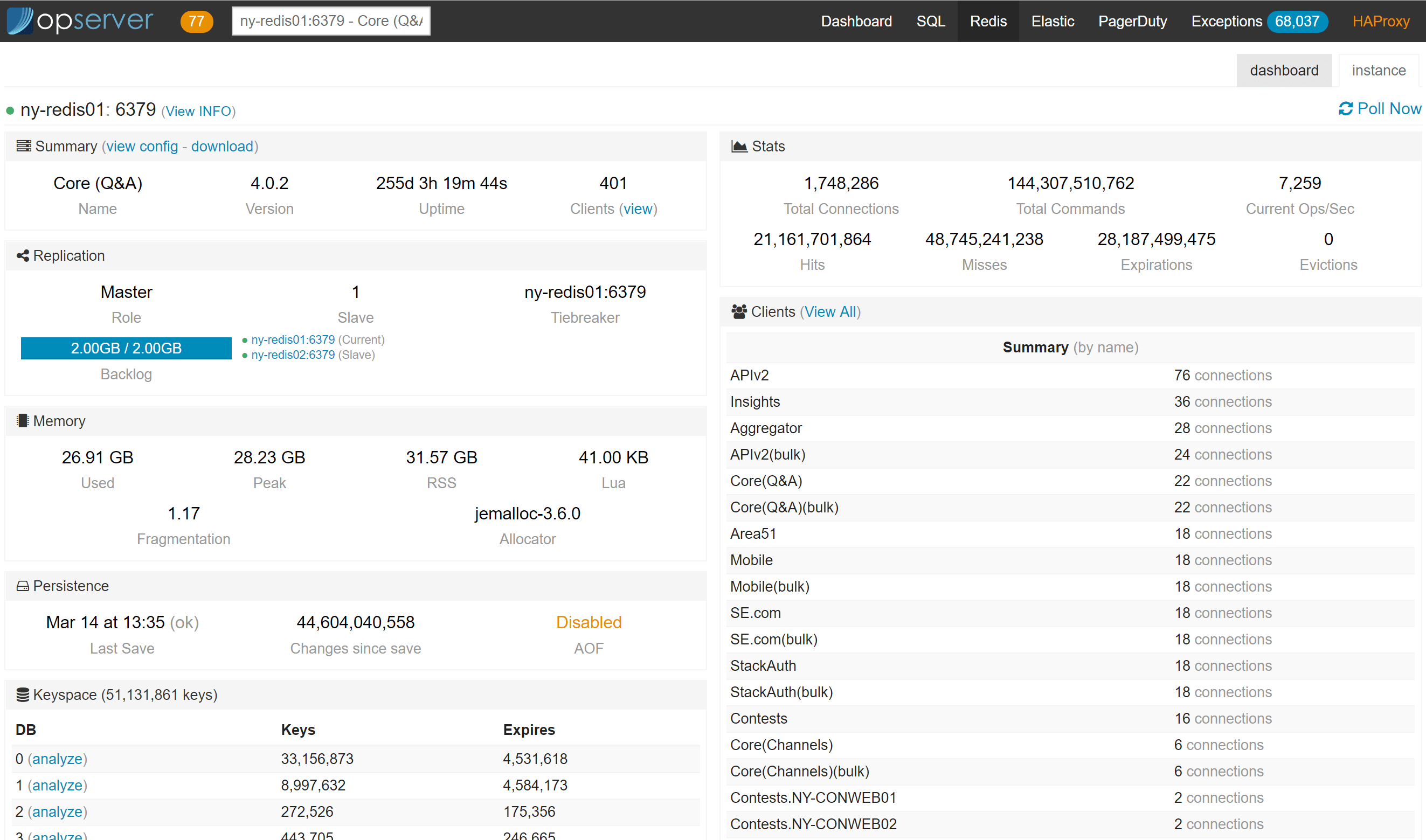
请注意,你可以终止客户端连接、获取活动配置、更改服务器拓扑并分析每个数据库中的数据(通过Regexes进行配置)。最后一个是重量级的KEYS和DEBUG OBJECT扫描,因此,我们在副本节点上运行它,或者可以强制在主节点上运行它(为了安全起见)。下面是一个分析结果示例:
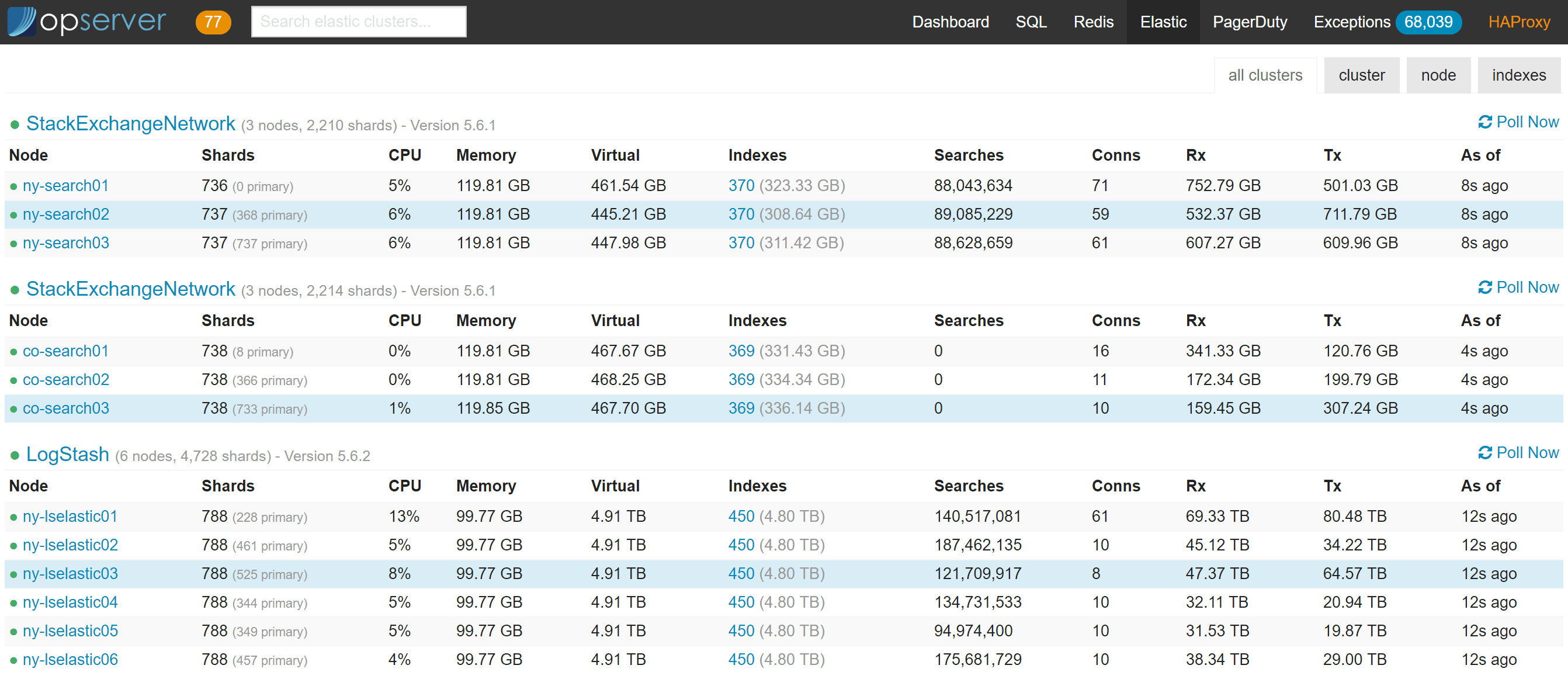
Opserver:Elasticsearch
对于 Elasticsearch,我们通常希望在一个集群视图中进行查看,因为那是它的行为方式。下图中没有索引变为黄色或红色。当这种情况发生时,仪表板会新增一部分显示有问题的分片、它们正在做什么(初始化、重定位等),以及在每个集群中出现的次数,汇总显示有多少分片处于哪种状态。
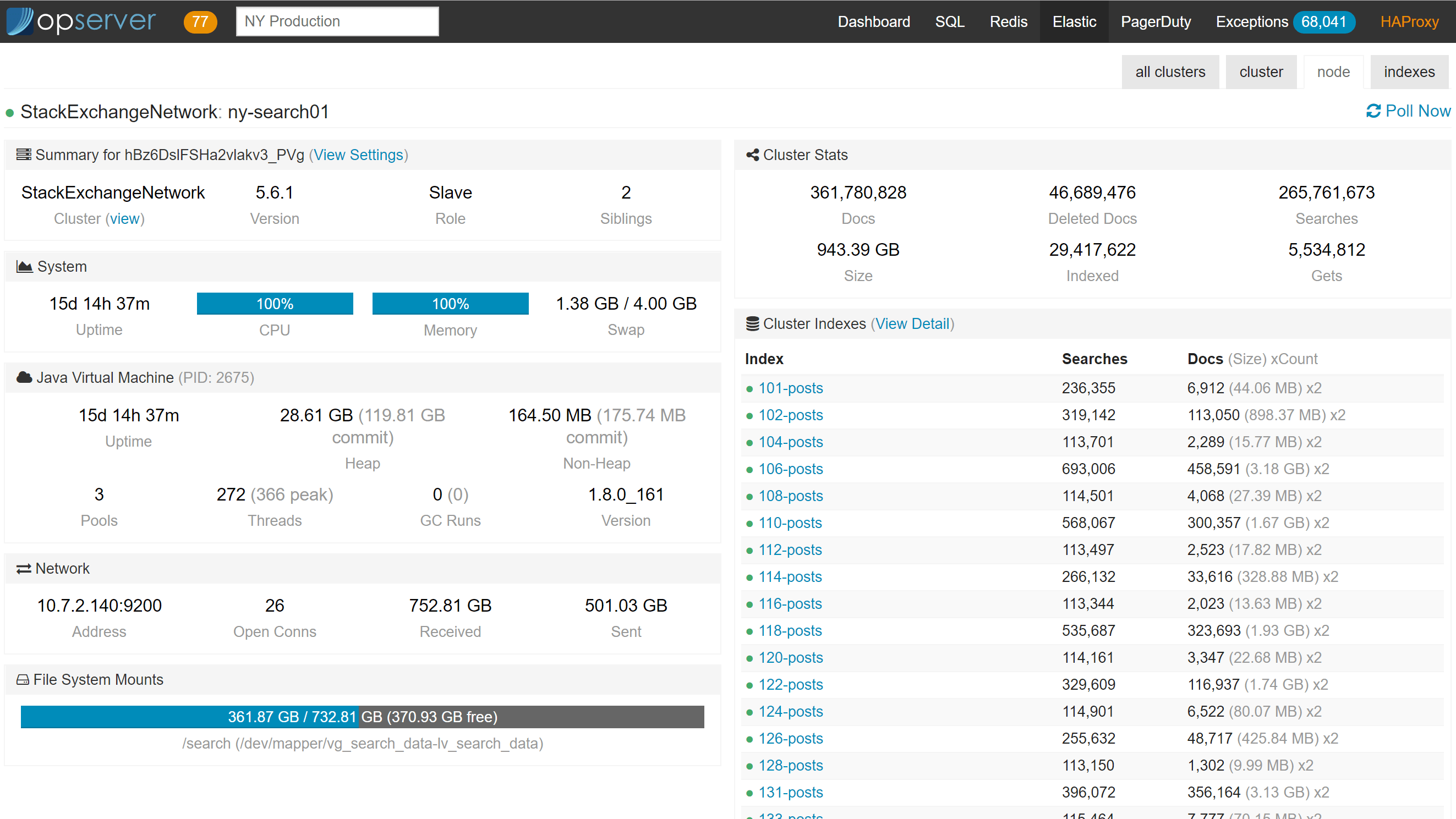
注意:上面的 PagerDuty 选项卡从 PagerDuty API 中提取数据并显值班信息,以谁为主,以谁为辅,你可以查看和声明事件,等等。(这部分数据不便于分享,所以这里没有提供截图)它还有一个可配置的原始 HTML 部分,向访问者提供关于做什么或联系谁的说明。
Opserver:异常
Opserver 中的异常是基于StackExchange.Exceptional的。在这一部分,我们将特别关注 SQL Server 存储提供程序。对于许多应用程序来说,Opserver 是一种共享单个数据库和表布局并让开发人员在一个地方查看其异常的方法。
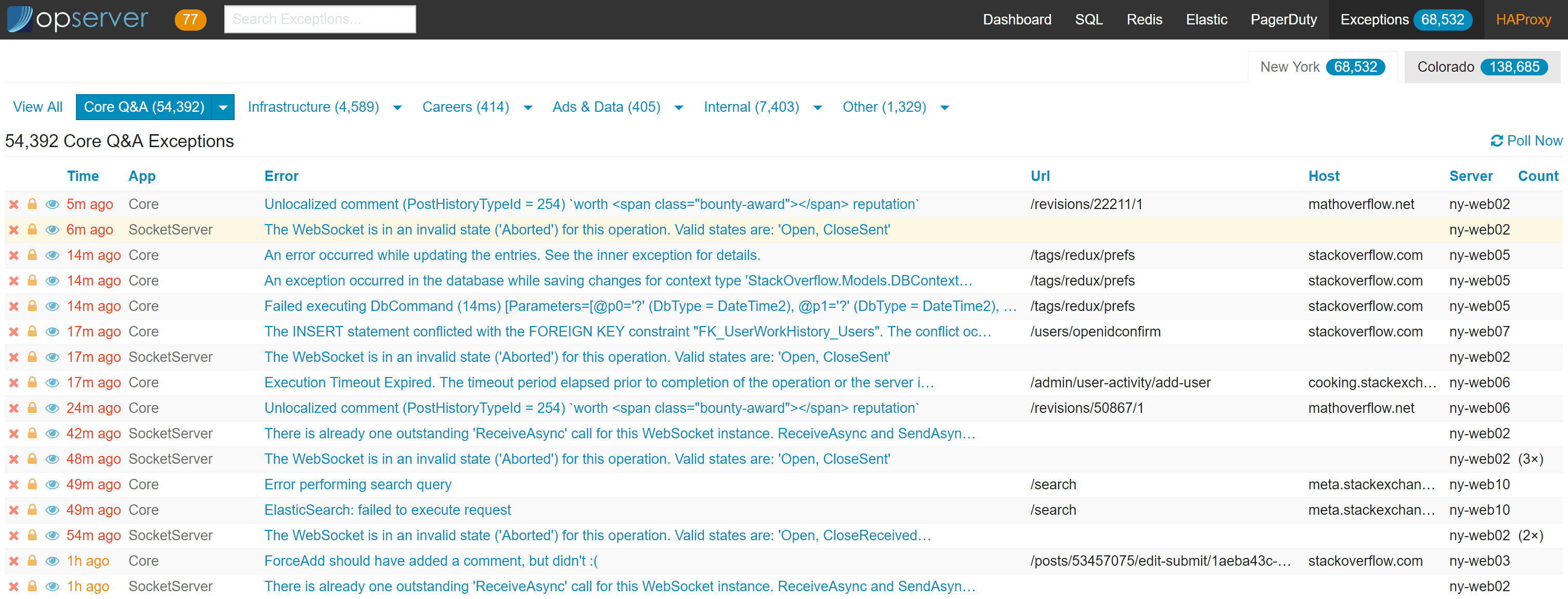
这里的顶层视图可以是应用程序(默认),也可以在组中配置。在上面的例子中,我们按团队配置应用程序组,这样团队就可以标记或快速点击他们负责的异常。在每个异常的页面中,可以看到如下详细信息:
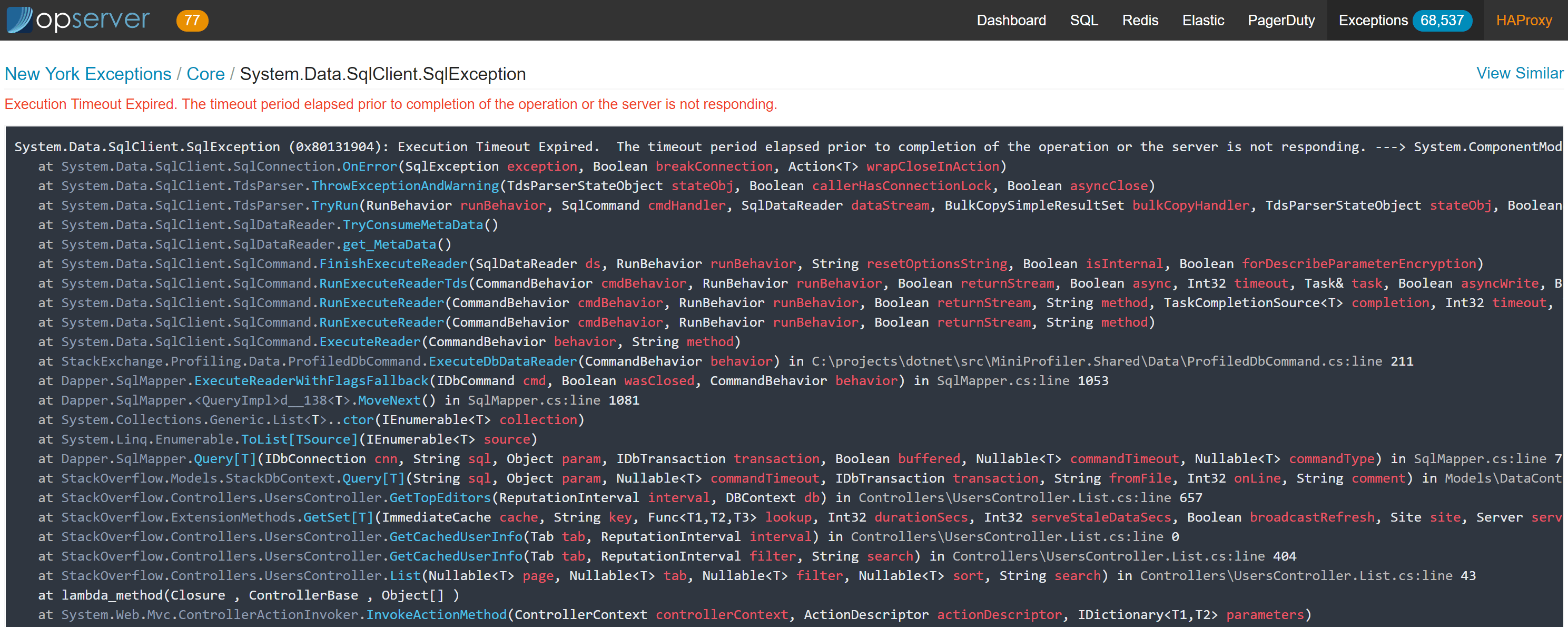
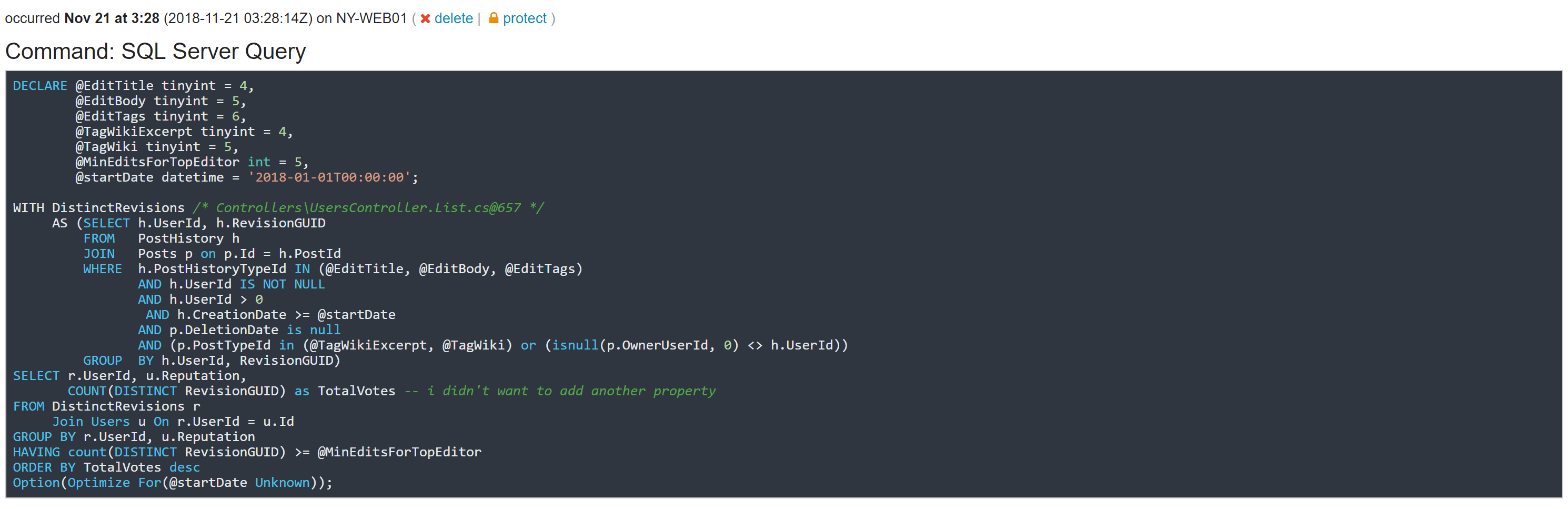
其中还记录了其他一些细节,比如请求头(有安全过滤器,因此我们不记录身份验证 Cookie)、查询参数和添加到异常中的任何其他自定义数据。
注意:你可以配置多个存储,例如,我们上面就配置了 New York 和 Colorado。这些是独立的数据库,允许所有应用程序登录到一个非常靠近本地的存储,并且仍然可以从一个仪表板访问它们。
Opserver:HAProxy
HAProxy 部分非常简单—我们只是显示 HAProxy 的当前状态并允许对其进行控制。主仪表板如下所示:
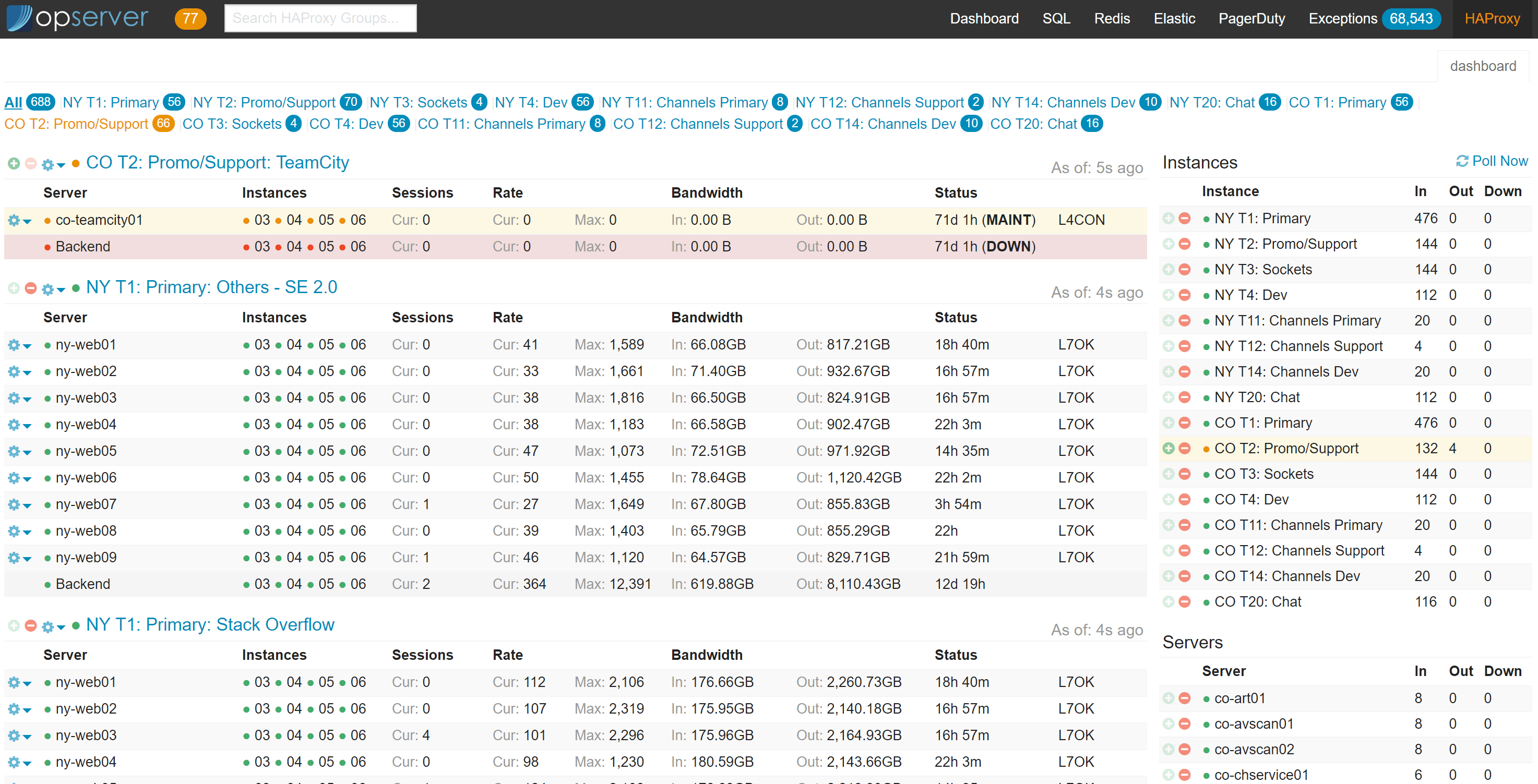
对于每个后台组、特定的后端服务器、整个服务器或整个层,它也允许一些控制。我们可以把一个后端服务器踢出轮转,或者让整个后端停止运行,或者,如果需要的话,我们还可以把一个 Web 服务器从所有后端中剔除,从而关闭它进行紧急维护,等等。
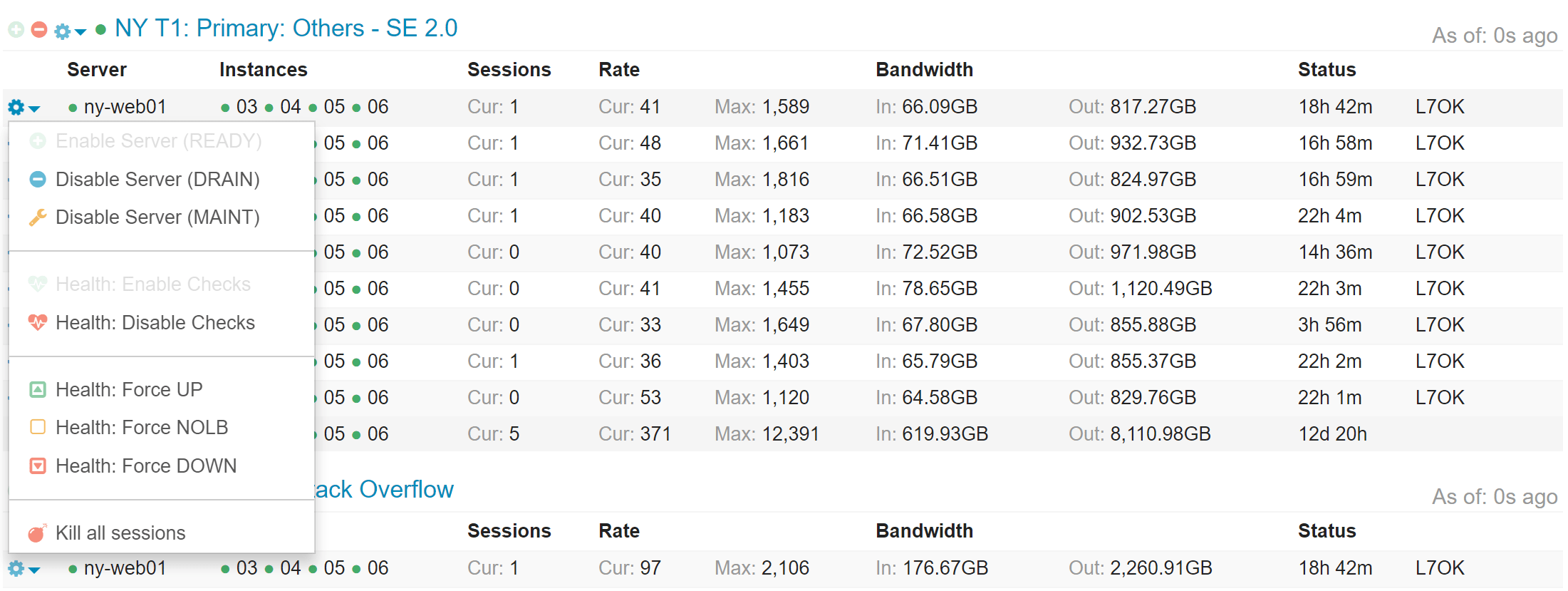
Opserver:常见问题
关于 Opserver,人们经常问我同样的问题,以下是对其中一部分问题的回答:
Opserver 本身不需要任何类型的数据存储(它是全配置的内存中状态) 。
将来进行功能增强的时候可能会发生,但现在还没有添加任何东西的计划。
只有仪表板选项卡和单节点视图是基于 Bosun、Orion 或 WMI——SQL、Elastic、Redis 等其他界面则没有任何依赖,Opserver 直接对它们进行监控。
身份验证既可以是全局的,也可以按选项卡进行(查看和管理是分开的),但是,内置的配置是通过组,也包含了活动目录。
关于管理员和查看者:查看者视图是只读的。例如,HAProxy 控制就不会显示。
所有的选项卡都不是必须的——每一个都是独立的,只有配置了才会显示。
例如,如果你希望只使用 Opserver 作为 Elastic 或异常仪表板,那么你那样做就好了。
注意:Opserver目前正在被移植到ASP.NET Core,因为我晚上有时间。这将使它可以在没有 IIS 的情况下运行,并有望很快在其他平台上运行。有些东西,比如从 Linux 上进行 SQL 服务器的 AD 身份验证,仍然有待解决。如果你希望部署 Opserver,请注意,部署和配置将发生巨大的变化(会更简单),所以你最好等一段时间。
接下来的打算
监控是一个不断发展的东西。我想,对每个人来说都是这样。但是,我只能介绍下我参与的计划,那么,我们下一步有什么打算呢?
健康检查的下一步工作
对于健康检查的改进,我已经考虑了一段时间了,但还没能抽出时间。你在监控什么东西时,真相的来源是一个值得关注的点。有两个问题,一个是这个东西是什么,另一个是这个东西应该是什么。后者由谁定义?我认为,我们可以在依赖方面做一些改进,让它的适应面更广(我真的希望有人已经在做类似的事情,如果是这样,请告诉我!)如果我们从健康检查中得出一个类似下面这样的简单结构会怎样?
这只是我的想法,但关键是 Dependencies。如果你问 Web 服务器,“嘿,伙计,最近怎么样?”它返回的不是一个简单的 JSON 对象,而是由它们构成的树?但是,每一层都是一样的,所以总的来说,我们有一个递归的依赖项列表。例如,一个包含 Redis 的依赖项列表——如果我们无法到达 2 个 Redis 节点中的 1 个,我们在列表中将有 2 个依赖项,一个的状态是 Healthy,另一个的是 Critical 或 Unknown,而 Web 服务器的状态是 Warning 而不是 Healthy。
这里的要点是:监控系统不需要知道依赖关系。系统本身定义并返回它们。这样,我们就不会陷入配置偏离,即被监控的东西与应该存在的东西不匹配。这通常发生在拓扑或依赖关系有变化的部署中。
这可能是一个糟糕的想法,但对于 Opserver(或任何脚本)来说,要获得健康读数以及健康读数的原因,这是一个很一般的想法。如果我们失去了另一个节点,就会有 n 个东西被破坏。或者,我们看到 n 个健康警告的共同原因。通过指向一些端点,我们可以得到所有事物的树形视图。你需要为自己的用例添加更多的数据吗?当然!它是 JSON,因此,只需要从对象继承并根据需要添加更多内容即可。这是一个很容易扩展的模型。我需要花点时间来做这个,也许它会有很多问题。或者读到这篇文章的人会告诉我,这已经完成了。
Bosun 的下一步工作
由于没有资源和其他需要优先处理的事项,Bosun 在很大程度上处于维护状态。我们没有做我们想的那么多,因为我们需要就最佳的前进道路进行讨论。是否有其他工具弥补了最初导致我们构建它的缺陷?SQL 2017 或 2019 是否已经大大改善了我们遇到问题的查询?我们需要花些时间对生态圈做些考察,评估一下我们想做的东西。这是我们想在 2019 年第一季度开展的工作。
我们知道自己想要做一些事情,例如改进警告编辑体验以及 UI 的其他一些方面。我们只是需要权衡一些事情,弄清楚我们的时间用在什么地方最好。
指标的下一步工作
我们的应用程序对指标的利用还相当地不充分。我们知道这一点。这个系统主要是为 SRE 和开发人员构建的,但是,在向开发人员展示指标的所有优点和强大之处(包括指标多么容易添加)方面,我们做得不够好。我们在上个月的公司聚会上讨论过这个话题。添加指标的代价是如此之低,我们可以做得更好。对此,有各种不同的观点,但我认为,这主要是一个我们需要努力改善的培训和认识问题。
上面的健康检查……也许我们也可以很容易地集成来自 BosunReporter 的指标(可能只有在需要时),从而创建一个功能强大的 API 来检查服务的健康状况和状态。这将使得我们可以对我们通常推送的指标采用拉式模型。不过,它的代价要尽可能小,配置也要少。
工具汇总
我上面提供了多个我们构建和开源的工具。下面是一个供参考的列表。
Bosun:基于 GO 的监控和警告系统,主要由Kyle Brandt、Craig Peterson和Matt Jibson开发。
Bosun:Grafana插件:Grafana 的一个数据源插件,由Kyle Brandt开发。
BosunReporter:用于 Bosun 的.NET 指标收集器/发送器,由Bret Copeland开发。
httpUnit: 基于 GO 的 HTTP 监控,用于测试 Web 端点的合规性,由Matt Jibson和Tom Limoncelli。
MiniProfiler:基于.NET 的(还有面向 Node、Ruby 等其他语言的)轻量级性能分析工具,用于实时查看页面的渲染时间,由Marc Gravell、Sam Saffron和Jarrod Dixon开发,由Nick Craver维护。
Opserver:基于 ASP.NET 的监控仪表板,用于 Bosun、SQL、Elasticsearch、Redis、Exceptions 和 HAProxy,由Nick Craver开发。
StackExchange.Exceptional: .NET 异常日志工具,支持 SQL Server、MySQL、Postgres 等,由Nick Craver开发。
所有这些工具都有来自我们的开发人员和 SRE 团队以及整个社区的额外贡献。
接下来呢?本系列文章是为了介绍社区最想了解的内容。从Trello Board来看,缓存似乎是下一个最有趣的主题。因此,下次我们将学习如何在 Web 层和 Redis 上缓存数据,如何处理缓存失效,以及如何利用发布/订阅来完成各种任务。
查看英文原文:Stack Overflow: How We Do Monitoring - 2018 Edition

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论