

3 月 27 日,ACM 宣布深度学习的三位缔造者——Yoshua Bengio、Yann LeCun 及 Geoffrey Hinton 获得了 2018 年度的图灵奖。与学术界相对应的,在工业界,人工智能大潮也正汹涌奔来。除了冲击人们的衣食住行医,人工智能也将成为企业转型的颠覆性力量,是企业抓住下一轮创新发展的重要机遇。
发布 | 才云 Caicloud
作者 | angao
1 行业背景
现如今,随着企业纷纷在机器学习和深度学习上加大投入,他们开始发现从头构建一个 AI 系统并非易事。
以深度学习为例。对于深度学习来说,算力是一切的根本。为了用海量数据训练性能更好的模型、加速整个流程,企业的 IT 系统需要具备快速、高效调用管理大规模 GPU 资源的能力。同时,由于算力资源十分昂贵,出于成本控制,企业也需要通过分布式训练等方式最大化 GPU 资源利用率。
面对这类新要求,基于 Kubernetes 的云原生技术为人工智能提供了一种新的工作模式。凭借其特性,Kubernetes 可以无缝将模型训练、inference 和部署扩展到多云 GPU 集群,允许数据科学家跨集群节点自动化多个 GPU 加速应用程序容器的部署、维护、调度和操作。
在 1.6 版本和 1.9 版本中,Kubernetes 先后提供了对 NVIDIA GPU、AMD GPU 容器集群管理调度的支持,进一步提高了对 GPU 等扩展资源进行统一管理和调度的能力。
但是,Kubernetes 作为新一代 AI 开发基础也存在缺陷。为训练任务分配算力资源时,它通常是随机分配容器所在节点的 GPU,而不能指定使用某类 GPU 类型。
虽然这对大部分深度学习模型训练场景来说已经足够了,但如果数据科学家希望能更灵活地使用更高性能的或某一类型的 GPU,Kubernetes 的能力就有些捉襟见肘了。
因此,在这篇文章中,我将介绍才云科技在这一点上的经验,谈一谈我们如何基于 Kubernetes 灵活实现 GPU 类型的调度。
2 社区方案
问题:原生 Kubernetes 如何让 Pod 使用指定类型的 GPU?****
假设集群中有两个节点有 GPU:节点 A 上有两个 Tesla K80,节点 B 上有两个 Tesla P100。Kubernetes 可以通过 Node Label 和 Node Selector,把 Pod 调度到合适的节点上,具体如下。
先给 Node 打上特定的 Label:
此时节点 A 如下:
当 Pod 想使用 NVIDIA Tesla K80 GPU 时,可以通过下面的方式:
上述做法貌似解决了问题,但它其实治标不治本。
试想一下,如果用户集群在同一个节点上挂载了多种 GPU,我们该如何实现筛选?如果用户在同一个节点挂载了多个显存不同的 NVIDIA Tesla K80,而且想使用大于 10GiB 显存的 GPU,我们又该怎么办?
Kubernetes 的 Node Label 和 Node Selector 是没法解决这些问题的。
在上游社区,很多开发者也经常围绕此类问题展开讨论,但一直没有实际可用的方案落地。尽管如此,社区还是提供了不少精彩见解,比如下面就是社区中讨论最多的一个方案,我们的方案也借鉴了其中的部分设计。
新增 ResourceClass API,用来匹配集群中的扩展资源,具体用法见下文介绍;
修改 Node API,在 NodeStatus 中增加字段描述扩展资源:
扩展资源通过 Device Plugin API 向 Kubelet 组件注册其信息,随后 Kubelet 组件可以通过接收到的扩展资源信息更新节点状态,即上一步中的 ComputeResources 字段;
调度器根据 ResourceClass 的定义过滤选择合适的节点。调度器监听 NodeStatus.ComputeResources 的变化并缓存节点上 ComputeResource 的分配信息,以便 ResourceClass 匹配合适的节点。
相比 Node Label 和 Node Selector,社区的方案更成熟。但不难看出,这个方案虽然可以修改 Kubernetes 核心代码和核心 API,但作为一个倍受关注的技术问题的解决方案,它的进度非常缓慢,一直没有得出更进一步的结论。
3 才云科技:GPU 类型调度实现
为了尽快实现在 Pod 使用指定类型的 GPU,并把它集成到 Caicloud Compass 中,我们在上游社区方案的基础上提出了一种全新方案。
它充分利用了 Kubernetes 的扩展性和插件机制,并遵循最小侵入和方便移植的设计原则。但是,出于简化用户使用和降低开发维护难度等原因,它还是修改了 Kubelet 和 Scheduler 组件。
同时,由于我们采用了多调度器的实现方式,所以方案中对于 Scheduler 组件的修改不影响现有集群和之后的版本升级,而 Kubelet 组件采用了向后兼容式修改,不影响已经在集群中运行的应用。
该方案不仅支持 GPU 资源,还支持包括 Infiniband、FPGAs 等扩展资源,它依赖以下现有 Kubernetes 工作机制:
Scheduler Extender 机制
Device Plugin 机制
API Server 扩展机制(CRD)
Admission 扩展机制(ResourceQuota)
在 1.6 版本中,Kubernetes 可以通过 ThirdPartyResource(TPR) 创建自定义资源,但在 1.7 版本中,它推出了 TPR 的替代方法: CustomResourceDefinition(CRD)。
CRD 允许自定义一个资源类型,因此开发人员不再需要修改 Kubernetes 核心 API 或通过 API server aggregation 增加新资源,开发和维护难度大大降低。
在我们的方案中,我们通过 CRD 定义了两种资源:ExtendedResource 和 ResourceClass。ExtendedResource 描述了一种扩展资源,比如 NVIDIA GPU;ResourceClass 则定义了容器选择哪种扩展资源,它的使用方式和 Kubernetes 中的 Extended Resource(详见参考文献)类似,用户可以直接在容器中指定,就像使用 CPU 和 Memory 一样。
下面是才云方案的基本架构图:
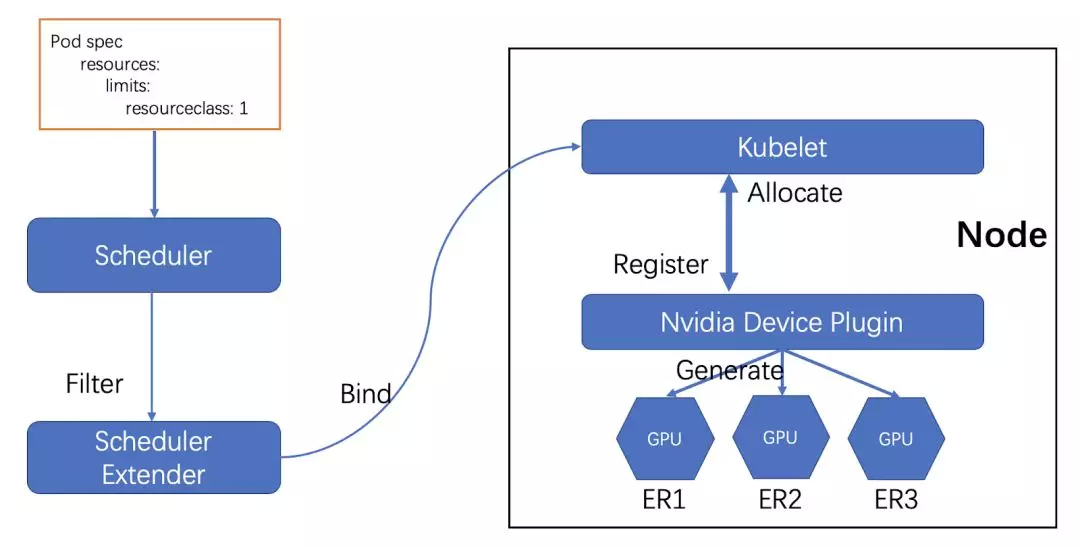
核心模块一:Scheduler Extender。Scheduler Extender 利用 Scheduler 组件的扩展性,负责调度容器中使用了 ResourceClass 资源对象的 Pod。它通过查询 ResourceClass 对象的定义过滤选择节点上的 ExtendedResource 资源,从而找到合适的节点并绑定,并将合适的 ExtendedResource 写到 Pod Annotation 中,供 Kubelet 组件使用。由于 Scheduler Extender 的扩展机制是通过 HTTP 的方式实现的,为了不影响集群的默认调度器性能,通过多调度器的方式为仅需要使用扩展资源的 Pod 提供调度,并且这种方式具有可移植性。
核心模块二:Nvidia Device Plugin。此组件仅针对 NVIDIA GPU 扩展资源,除了负责与 Kubelet 组件通信,它还负责创建和维护 ExtendedResource 资源对象。
那么,当同一节点上有多种不同类型的 GPU 时,这个方案是如何解决类型指定的呢?
我们假设有节点 A 上有两张 GPU,一张是 NVIDIA Tesla K80,另一张是 NVIDIA Tesla P100。那么这个节点上的 NVIDIA Device Plugin 会创建两个 ExtendedResource 资源对象,分别描述这两张卡的基本属性,如型号、显存、频率等。同时,它也会向 Kubelet 注册,把 A 节点上有两张 GPU 告知节点上的 Kubelet。
这时,如果用户想创建一个使用 K80 这张 GPU 的应用,他只需要创建一个 ResourceClass 资源,在 ResourceClass 中声明使用型号为 NVIDIA Tesla K80 的 GPU(比如通过 Selector 的方式声明),然后在容器中使用这个 ResourceClass 资源。
Kubernetes 默认调度器在经过一系列筛选过滤后,会调用 Scheduler Extender 的 Filter 方法,并将需要调度的 Pod 和过滤后的 NodeList 传递给 Filter,实现 ResourceClass 查找满足需求的 ExtendedResource,从而找到合适的节点;
当调度器找到合适的节点后,调用 Scheduler Extender 的 Bind 方法,将 Pod 和 Node 绑定,并将合适的 ExtendedResource 资源对象写到 Pod Annotation 中,供 Kubelet 组件使用。
当 Pod 和 Node 绑定后,节点上的 Kubelet 组件则开始创建容器,并通过 Pod Annotation 获取容器需要使用哪块 GPU 的信息,然后通过 Device Plugin API 调用 NVIDIA Device Plugin 的 Allocate 方法。
Allocate 方法参数是容器使用的 GPU DeviceID,它通过 DeviceID 查询 GPU 的信息作为环境变量,返回给 Kubelet 用以真正创建 Pod。
从上述流程中可以看出,当我们想使用特定类型的 GPU 或者某一类 GPU 时,我们只需声明该类型的 ResourceClass 资源对象,比如:
更进一步,我们可以通过实现一个 Controller 监听集群中的 ExtendedResource 资源,自动为一种类型的 ExtendedResource 创建一个 ResourceClass 对象,为用户提供一些默认规则的 ResourceClass 资源对象。
在实际生产集群环境中,我们不仅需要满足不同应用对资源的使用,更是要做到不同应用对资源使用的限制,以及对不同的 namespace 分配不同的资源。而在 Kubernetes 中,我们一般会通过 ResourceQuota 资源对象来限制不同 namespace 的资源,例如:
从上面的 ResourceQuota 定义里,我们可以看到 default 命名空间可以使用 5 块 NVIDIA GPU,但它并不限制具体该使用哪种类型的 GPU。
那么,我们该如何实现对 GPU 类型的限制呢?
首先,GPU 这类扩展资源使用是标量,所以我们对标量资源的限制只能做到整数个数的限制。
其次,从上述方案中,我们知道一种 ResourceClass 代表了一种类型的扩展资源,因此对扩展资源的限制其实就是对 ResourceClass 的限制。
这样理解之后,问题就很简单明了了。下面直接给出相应的 ResourceQuota:
4 展望未来
除了 GPU 类型调度,这个方案其实也可以解决 GPU 共享问题。这同样是上游社区的一个热门讨论话题。
ExtendedResource 资源中包含着 GPU 的频率、显存等信息,当多个容器想使用同一块 GPU 时,我们可以定义一个 ResourceClass 资源对象,在 ResourceClass 中声明使用多少显存(这里共享的是显存)。这样,应用部署时,我们只要在容器中声明使用该 ResourceClass 资源即可,之后 Scheduler Extender 会过滤符合条件的 ExtendedResource 对象,绑定到合适的节点上。
如果要实现资源共享,我们可能需要在 ExtendedResource 中记录显存的用量情况,供调度参考。当然,这里没有考虑到资源的隔离和限制的问题,这需要单独实现和更进一步的讨论。
以上就是我们在探索如何让 Pod 使用指定类型的 GPU 上得出的解决方案。如果你对这个主题感兴趣,或有新想法,欢迎留言一起讨论。
你也可以关注我们公司的公众号(Caicloud2015),之后我们还会分享一系列内部技术和开源软件,敬请期待!
参考文献
本文转载自公众号才云 Caicloud(ID:Caicloud2015)。
原文链接:
https://mp.weixin.qq.com/s/elt-P4ASilQuv9EfQdFTQw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论