
本文摘选自电子工业出版社出版、李金洪编著的《深度学习之TensorFlow工程化项目实战》一书的实例 13:用 TF-Hub 库微调模型以评估人物的年龄。
实例描述
有一组照片,每个文件夹的名称为具体的年龄,里面放的是该年纪的人物图片。
微调 TF-Hub 库,让模型学习这些样本,找到其中的规律,可以根据具体人物的图片来评估人物的年龄。
即便是通过人眼来观察他人的外表,也不能准确判断出被观察人的性别和年纪。所以在应用中,模型的准确度应该与用人眼的估计值来比对,并不能与被测目标的真实值来比对。
一、准备样本
本实例所用的样本来自于 IMDB-WIKI 数据集。IMDB-WIKI 数据集中包含与年龄匹配应的人物图片。
因为该数据集相对粗糙(有些年纪对应的图片特别少),所以需要在该数据集的基础上做一些简单的调整:
补充了一些与年龄匹配的人物图片。
删掉了若干不合格的样本。
整理后的图片一共有 105500 张。
读者可以直接使用本书配套的数据集,将该数据集(IMBD-WIKI 文件夹)放到当前代码的本地同级文件夹下即可使用。
二、下载 TF-Hub 库中的模型
安装 TF-Hub 库后,可以按照以下步骤进行操作。
1. 找到 TF-Hub 库中的模型下载链接
在 GitHub 网站中找到 TF-Hub 库中所提供的模型及下载地址,具体网址如下(国内可能访问不了,请读者自行想办法):https://tfhub.dev/
打开该网页后,可以看到在列表中有很多模型及下载链接,如图 1 所示。
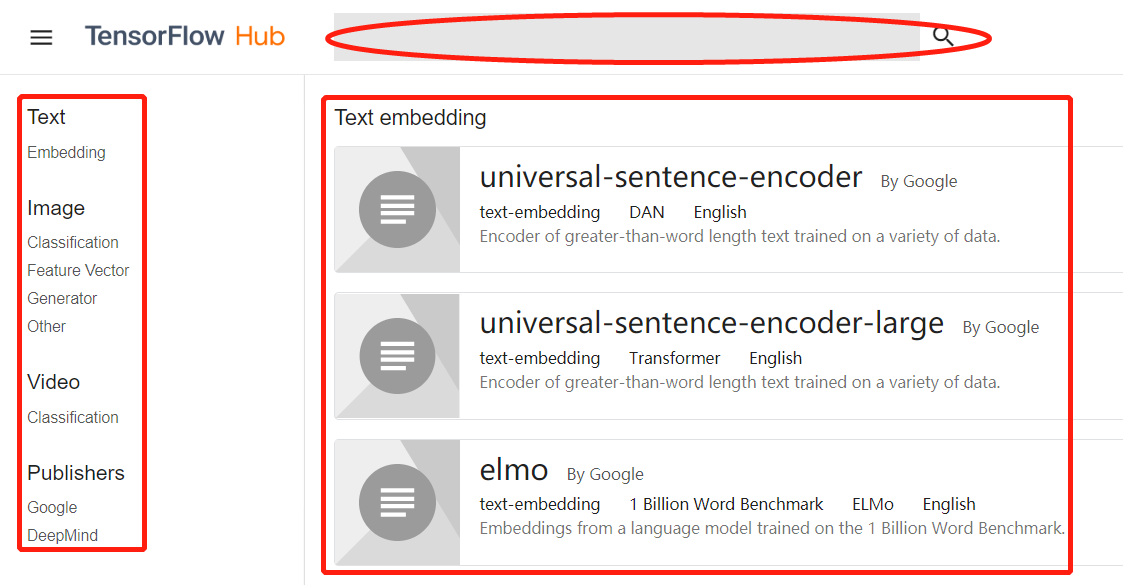
图 1 预训练模型列表
在图 1 可以分为 3 部分,具体如下:
最顶端是搜索框。可以通过该搜索框搜索想要下载的预训练模型。
左侧是模型的分类目录。将 TF-Hub 库中的预训练模型按照文本、图像、视频、发布者进行分类。
右侧是具体的模型列表。其中列出每个模型的具体说明和下载链接。
因为本例需要图像方面的预训练模型,所以重点介绍左侧分类目录中 image 下的内容。在 image 分类下方还有 4 个子菜单,具体含义如下:
Classification:是一个分类器模型的分类。该类模型可以直接输出图片的预测结果。用于端到端的使用场景。
Feature_vector:一个特征向量模型的分类。该类模型是在分类器模型基础上去掉了最后两个网络层,只输出图片的向量特征,以便在预训练时使用。
Generator:一个生成器模型的分类。该类别的模型可以完成合成图片相关的任务。
Other:一个有关图像模型的其他分类。
2. 在 TF-Hub 库中搜索预训练模型
在图 1 中的搜索框里输入“mobilenet”并按 Enter 键,即可显示出与 MobileNet 相关的模型,如图 2 所示。
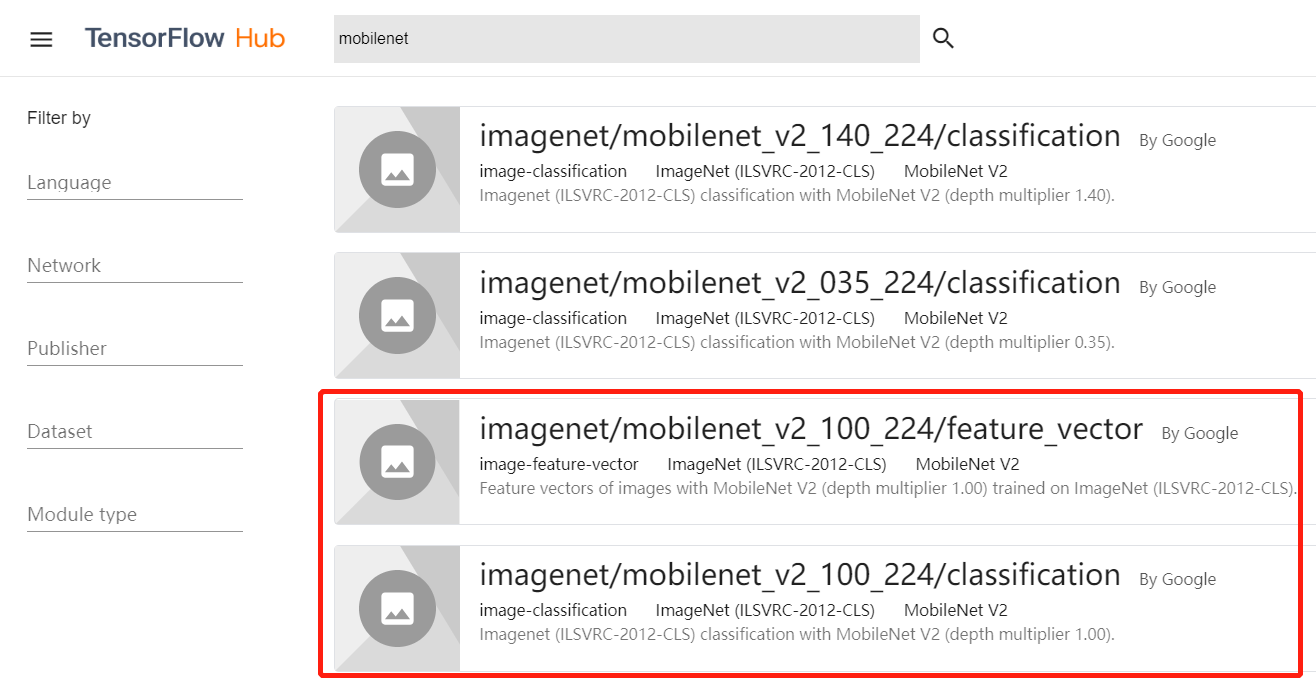
图 2 搜索 MobileNet 预训练模型
在图 2 右侧的列表部分,可以找到 MobileNet 模型。以 MobileNet_v2_100_224 模型为例(图 2 右侧列表中的最下方 2 行),该模型有两个版本:classification 与 feature_vector。
单击图 2 右侧列表中的最后下面一行,进入 MobileNet_v2_100_224 模型 classification 版本的详细说明页面,如图 3 所示。

图 3 NASNet_Mobile 模型 feature_vector 版本的详细说明页
在如图 3 所示的页面中,可以看到该网页介绍了 MobileNet_v2_100_224 模型的来源、训练、使用、微调,以及历史日志等方面的内容。在页面的右上角有一个“Copy URL”按钮,该按钮可以复制模型的下载,方便下载使用。
3. 在 TF-Hub 库中下载 MobileNet_V2 模型
下载 TF-Hub 库中的模型方法有两种:自动下载和手动下载。
自动下载:单击图 3 中的“Copy URL”按钮,复制下载的 URL 地址,并将该地址填入调用 TF-Hub 库时的参数中。具体做法见 5.5.3 小节。
手动下载:从图 3 所示页面中复制的 URL 地址不能直接使用,需要将其前半部分的“https://tfhub.dev”换成“https://storage.googleapis.com/tfhub-modules”,并在URL后加上“.tar.gz”。
以 MobileNet_v2_100_224(简称 MobileNet_V2)模型的 classification 版本为例,手动下载的步骤如下。
(1)单击 5-8 中的“Copy URL”按钮,所得到的 URL 地址如下:
https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/feature_vector/2
(2)将其改成正常下载的地址。具体如下:
(3)用下载工具按照(2)中的地址进行下载。
三、代码实现:测试 TF-Hub 库中的 MobileNet_V2 模型
为了验证 TF-Hub 库中的模型效果,本小节将使用与第 3 章类似的代码:将 3 张图片输入 MobileNet_V2 模型的 classification 版本中,观察其输出结果。
编写代码载入 MobileNet_V2 模型,具体代码如下:
代码 1 测试 TF-Hub 库中的 NASNet_Mobile 模型
在代码第 14 行,用 TF-Hub 库中的 load_module_spec 函数加载 MobileNet_V2 模型。该步骤是通过将 TF-Hub 库中的模型链接(Module URL=“https://tfhub.dev /google/imagenet/mobilenet_v2_100_224/classification/2”)传入函数 load_module_spec 中来完成的。
在链接里可以找到该模型文件的名字:mobilenet_v2_100_224。TF-Hub 库中的命名都非常规范,从名字上便可了解该模型的相关信息:
模型是 MobileNet_V2。
神经元节点是 100%(无裁剪)。
输入的图片尺寸是 224。
得到模型之后,便将模型文件载入图中(见代码第 21 行),并获得输出张量(见代码第 23 行),然后通过会话(session)完成模型的输出结果。
运行代码后,显示以下结果:

在显示的结果中,可以分为两部分内容:
第 1 行是标签内容。
从第 2 行开始,所有以“INFO:”开头的信息都是模型加载具体参数时的日志信息。
在每条信息中都能够看到一个相同的路径:“checkpoint b’C:\Users\ljh\AppData\Local\ Temp\tfhub_modules\bb6444e8248f8c581b7a320d5ff53061e4506c19”,这表示系统将 mobilenet_v2_100_224 模型下载到 C:\Users\ljh\AppData\Local\Temp\tfhub_modules\ bb6444e8248f8c581b7a320d5ff53061e4506c19 目录下。
如果想要让模型缓存到指定的路径下,则需要在系统中设置环境变量 TFHUB_CACHE_DIR。例如,以下语句表示将模型下载到当前目录下的 my_module_cache 文件夹中。
提示 1:
如果由于网络原因导致模型无法下载成功,还可以将本书的配套模型资源复制到当前代码同级目录下,并传入当前模型文件的路径。具体操作是,将代码第 14 行换为以下代码:
在最后一条的 INFO 信息之后便是模型的预测结果。
提示 2:
如果感觉输出的 INFO 内容太多,则可以在代码的最前面加上“tf.logging.set_verbosity (tf.logging.ERROR)”来关闭 info 信息输出。
四、用 TF-Hub 库微调 MobileNet_V2 模型
在 TF-Hub 库的 GitHub 网站上提供了微调模型的代码文件,运行该代码可以直接微调现有模型。该文件的地址如下:
https://github.com/tensorflow/hub/raw/master/examples/image_retraining/retrain.py
将代码文件下载后,直接用命令行的方式运行,便可以对模型进行微调。
1. 修改 TF-Hub 库中的代码 BUG
当前代码存在一个隐含的 BUG:在某一类的数据样本相对较少的情况下,运行时会产生错误。需要将其修改后才可以正常运行。
在“retrain.py”代码文件中的函数 get_random_cached_bottlenecks 里添加代码(见代码第 2 行,书中第 477 行),当程序在产生错误时,让其再去执行一次随机选取类别的操作(见代码第 15~25 行,书中第 515~525 行)。具体代码如下:
代码 retrain(片段)
2. 用命令行运行微调程序
将代码文件“retrain.py”与 5.5.1 小节准备的样本数据、5.5.2 小节下载的 MobileNet_V2 模型文件一起放到当前代码的同级目录下。在命令行窗口中输入以下命令:
也可以输入以下命令,直接从网上下载 MobileNet_V2 模型,并进行微调。
程序运行之后,会显示如图 5 所示界面。
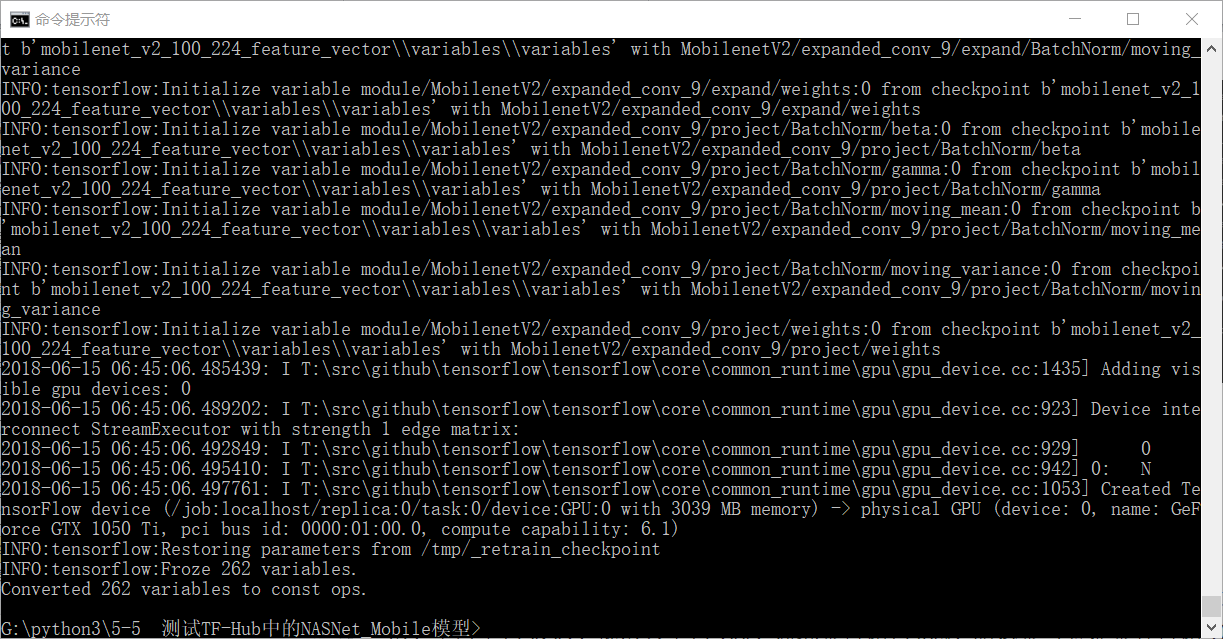
图 5 微调 MobileNet_V2 模型结束
从图 5 中可以看到,生成的模型被放在默认路径下(根目录下的 tmp 文件夹里)。来到该路径下(作者本地的路径是“G:\tmp”),可以看到微调模型程序所生成的文件,如图 6 所示。
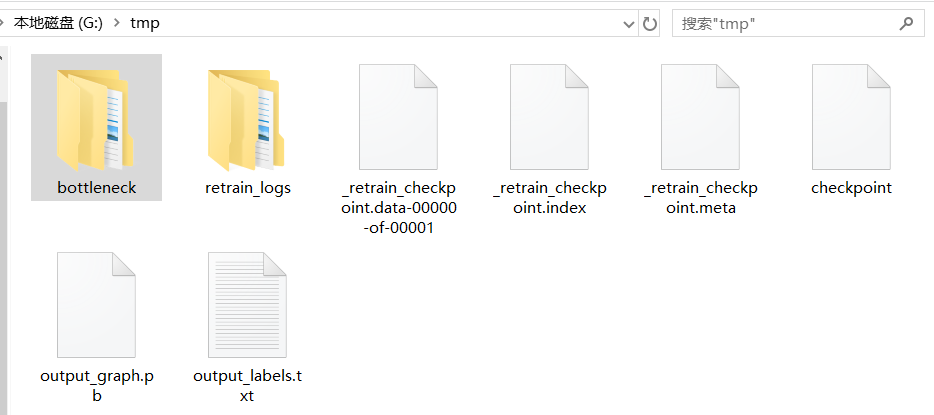
图 6 微调 MobileNet_V2 模型后生成的文件
在图 6 中可以看到有两个文件夹。
bottleneck:用预训练模型 MobileNet_V2 将图片转化成的特征值文件。
retrain_logs:微调模型过程中的日志文件。该文件可以通过 TensorBoard 显示出来(TensorBoard 的使用方法见 13.3.2 小节)。
其他的文件是训练后生成的模型。每个模型文件的具体意义在第 6 章会有介绍。
提示:
本实例只是一个例子,重点在演示 TF-Hub 的使用。因为实例中所使用的数据集质量较低,所以训练效果并不是太理想。读者可以按照本实例的方法使用更优质的数据集训练出更好的模型。
3. 支持更多的命令行操作
代码文件“retrain.py”是一个很强大的训练脚本。在使用时,还可以通过修改参数实现更多的配置。
本实例只演示了部分参数的使用,其他的参数都用默认值,例如:迭代训练 4000 次,学习率为 0.01,批次大小为 100,训练集占比为 80%,测试集与验证集各占比 10%等。
可以通过以下命令获得该脚本的全部参数说明。
五、代码实现:用模型评估人物的年龄
用代码文件“retrain.py”微调后的模型是以扩展名为“pb”的文件存在的(在图 6 中,第 2 行的左数第 1 个)。该模型文件属于冻结图文件。冻结图的知识在第 13 章会详细讲解。
将冻结图格式的模型载入内存,便可以人评估物的年纪。
1. 找到模型中的输入、输出节点
冻结图文件中只有模型的具体参数。如果想使用它,则还需要知道与模型文件对应的输入和输出节点。
这两个节点都可以在代码文件“retrain.py”中找到。以输入节点为例,具体代码如下:
代码 retrain(片断)
从代码文件“retrain.py”的第 6 行(书中第 305 行)代码可以看到,输入节点的张量是一个占位符——placeholder。
提示:
直接使用 print(placeholder.name)和 print(final_result.name)两行代码即可将输入节点和输出节点的名称打印出来。
将输入节点和输出节点的名称记下来,填入代码文件“5-6 用微调后的 mobilenet_v2 模型评估人物的年龄.py”中,便可以实现模型的使用。
更多有关张量的介绍可以参考《深度学习之 TensorFlow——入门、原理与进阶实战》的 4.4.2 小节。
2. 加载模型并评估结果
将本书的配套图片样例文件“22.jpg”和“tt2t.jpg”放到代码的同级目录下,用于测试模型。同时把生成的模型文件夹“tmp”也复制到本地代码的同级目录下。
这部分代码可以分为 3 部分。
样本文件加载部分(见代码第 1~34 行):这部分重用了本书 4.7 节的代码。
加载冻结图(见代码第 35~69 行):读者可以先有一个概念,在第 13 章还有详细讲解。
图片结果显示部分(见代码第 70~94 行):这部分重用了本书 3.4 节中显示部分的代码。
完整的代码如下:
代码 2 用模型评估人物的年龄
代码第 41 行,指定了要加载的模型动态图文件。
代码第 53 行,指定了与模型文件对应的输入节点“final_result:0”。
代码第 54 行,指定了与模型文件对应的输出节点“Placeholder:0”。
代码运行后显示以下结果:

输出结果可以分为两部分:
第 1 部分是标签的内容。
第 2 部分是评估的结果。
在第 2 部分中,每张图片的下面都会显示这个图片的评估结果,其中包括:在模型中的标签索引、该索引对应的标签名称。
本文摘选自电子工业出版社出版、李金洪编著的《深度学习之TensorFlow工程化项目实战》一书,更多实战内容点此查看。

本文经授权发布,转载请联系电子工业出版社。
系列文章:
TensorFlow 工程实战(一):用 TF-Hub 库微调模型评估人物年龄(本文)
TensorFlow 工程实战(二):用 tf.layers API 在动态图上识别手写数字
TensorFlow 工程实战(三):结合知识图谱实现电影推荐系统
TensorFlow 工程实战(四):使用带注意力机制的模型分析评论者是否满意
TensorFlow 工程实战(五):构建 DeblurGAN 模型,将模糊相片变清晰
TensorFlow 工程实战(六):在 iPhone 手机上识别男女并进行活体检测

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论