

通用人工智能(Artificial General Intelligence,AGI,或称强人工智能,Strong AI)是具备与人类同等智慧、或超越人类的人工智能,能表现正常人类所具有的所有智能行为。它是人工智能研究的主要目标之一,同时也是科幻小说和未来学家所讨论的主要议题。“通用人工智能”这一术语于 1997 年被 Mark Gubrud 在一次关于全自动军事生产于操作的研讨会中使用。大约在 2002 年,该术语被 Shane Legg 和 Ben Goertzel 重新提及和推广。
GPT-3 是自然语言处理领域迄今为止发布出来最大的 Transformer 模型,超过之前的记录 —— 微软研究院 Turing-LG 的 170 亿参数 —— 约 10 倍。公众认为 GPT-3 有可能通往通用人工智能,本文作者将 GPT-3 与通用人工智能的关系,与能人和现代人的关系作类比,发表了他的观点。
GPT-3 是类人自然语言表现的良好开端。或许一个更好的类比应该是通用人工智能自然语言的“能人”[1]。能人物种与早期的南方古猿有所不同,脑壳稍大,脸部和牙齿较小。但是,能人物种却保留着一些类似猿类的特征 [1]。最重要的是,就我要做的类比而言,能人被认为是制造石器工具的第一个物种。
GPT-3 在我的类比中代表着自然语言人工智能的“能人”。下面是我的理由:
GPT-3 的“大脑”(参数)比之前的自然语言处理模型要大得多。
GPT-3 所使用的工具,例如,迁移学习和微调。
GPT-3 完成其他未受过训练的自然语言处理任务(制造工具)。
GPT-3 保留了 GPT-2 的大部分架构 [3,5]。
关键要点:GPT-3 为何如此特别?
GPT-3 是迄今为止 OpenAI 最大的自然语言处理模型(它于 2020 年 6 月对公众开放)。
GPT-3 有大约 1850 亿个参数。相比之下,人类大脑中约有 860 亿个神经元,每个神经元平均有 7000 个突触 [2,3]。
将苹果和橘子相比较,人类大脑拥有大约 60 万亿个参数,比 GPT-3 多 300 倍左右。注:如果自然语言任务需要 10% 的人脑容量,那么人脑的参数约为 GPT-3 的 30 倍。
据估计,GPT-3 的云计算时间成本在 400 万到 1200 万美元之间,需要几个月的时间来训练 [3,7]。那将是每年至少 1200 万美元的工资和员工福利。
GPT-3 使用了几个大型的文本语料库来训练,这些语料库共有约 5000 亿个标记(一个标记大概等于一个单词)[3]。
他们已到达了他们能够到达的最远距离!他们盖了一栋七层楼的高楼。大约有一栋楼那么高。
——来自俄克拉荷马州堪萨斯城的歌词子集 [9]注:目前迪拜哈利法塔有 183 层高。[10]
GPT-3 站在前人的肩膀上
GPT-2 是一种基于 Transformer 的大型语言模型,拥有 15 亿个参数,在 800 万个网页的数据集上训练 [4,7]。GPT-2 将 GPT-1 的模型架构扩展了 10 倍左右的参数,并且训练了 10 倍以上的数据量。
GPT-2 最初的研究目标是,在 40GB 的互联网文本上进行无监督训练后预测句子中的下一个词 4,也许并不会感到意外。GPT-2 在 GPT-3 上为 OpenAI 在 GPT-3 上“大展拳脚”奠定了基础,我对此没有任何疑问。
GPT-2 模型和其他 SOTA(State-of-the-Art)自然语言处理模型仍不能从仅有的几个例子(称为小样本学习)或简单的描述任务的自然语言指令中执行新的语言任务 [3]。
GPT-3 将 GPT-2 的模型架构扩大了约 100 倍。如果按页数或作者人数计算,则是 5 倍的可观努力 [3,5]。
GPT-3 采用了 ULMFIT 的重要发现。在大型文本语料库上预训练自然语言处理模型,然后在特定任务上进行微调,在许多自然语言处理任务和基准方面都取得了很好的效果 [4]。
GPT-3 的研究人员指出,自然语言处理的性能(以交叉熵验证损失衡量)与自然语言处理模型的规模(参数数量)成正比 [3]。到目前为止,GPT-3 可以说是迄今为止最好的自然语言处理模型。
重新说明一下,因为这是一个关键的发现,研究人员通过 GPT-3 训练表明,扩大语言模型的规模可以显著提高任务不可知(task-agnostic)、小样本的性能,有时甚至 可以达到与之前 SOTA 方法相当的水平 [3]。
GPT-3 无需任何神经网络梯度更新,也不需要微调就可以应用 [3]。
GPT-3 论文的结论是,17.8 亿个参数的模型对于一些小样本的学习任务准确度不高 [3]。
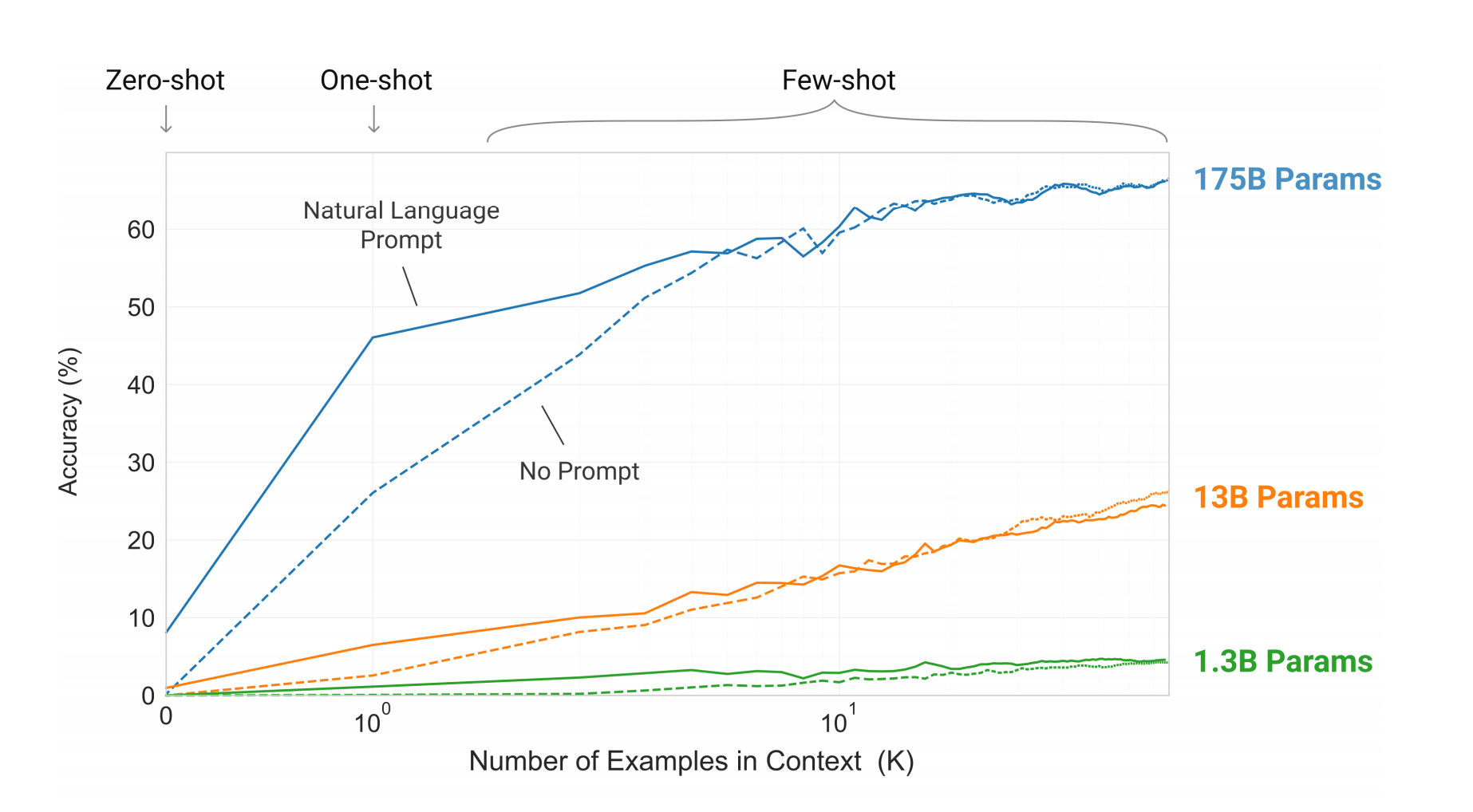
研究人员训练了一系列较小的 GPT-3 模型,这些模型从 1.25 亿个参数到 13 亿个参数不等。零次学习(Zero-shot Learning)、一次学习(One-shot Learning)和小样本学习性能之间的准确性差距随着模型参数大小而扩大。OpenAI 的研究人员坚称,他们的研究表明,更大的模型和更多的数据输入,将会成为适应性强的通用语言系统的成功之路。资料来源:[3] https://arxiv.org/pdf/2005.14165.pdf
GPT-3 是迄今为止最好的自然语言处理模型,因为它的规模最大?
注:2021 年 6 月 12 日,北京智源人工智能研究院(Beijing Academy of Artificial Intelligence ,BAAI)公布了有关其“悟道”人工智能系统的细节。据称有 175 万亿个参数。有报道称,“悟道”在文本分类、情感分析、自然语言推理、阅读理解等方面都超过了人类的平均性能水准。在 BAAI 提供诸如硬件使用、训练时间和训练数据使用等其他细节之前,我提醒读者注意上述公告。据说代码是开源的。
GPT-3 的第一个例子
GPT-3 能很好地完成需要立即推理或领域适应的任务,例如解读单词、在句子中使用一个新词或进行 3 位数的算术 [3]。
GPT-3 模型生成的新闻文章样本,人类评价者很难将其与由人类撰写的文本区分开。增加参数的数量增加了人类读者的困难程度,如下图所示。
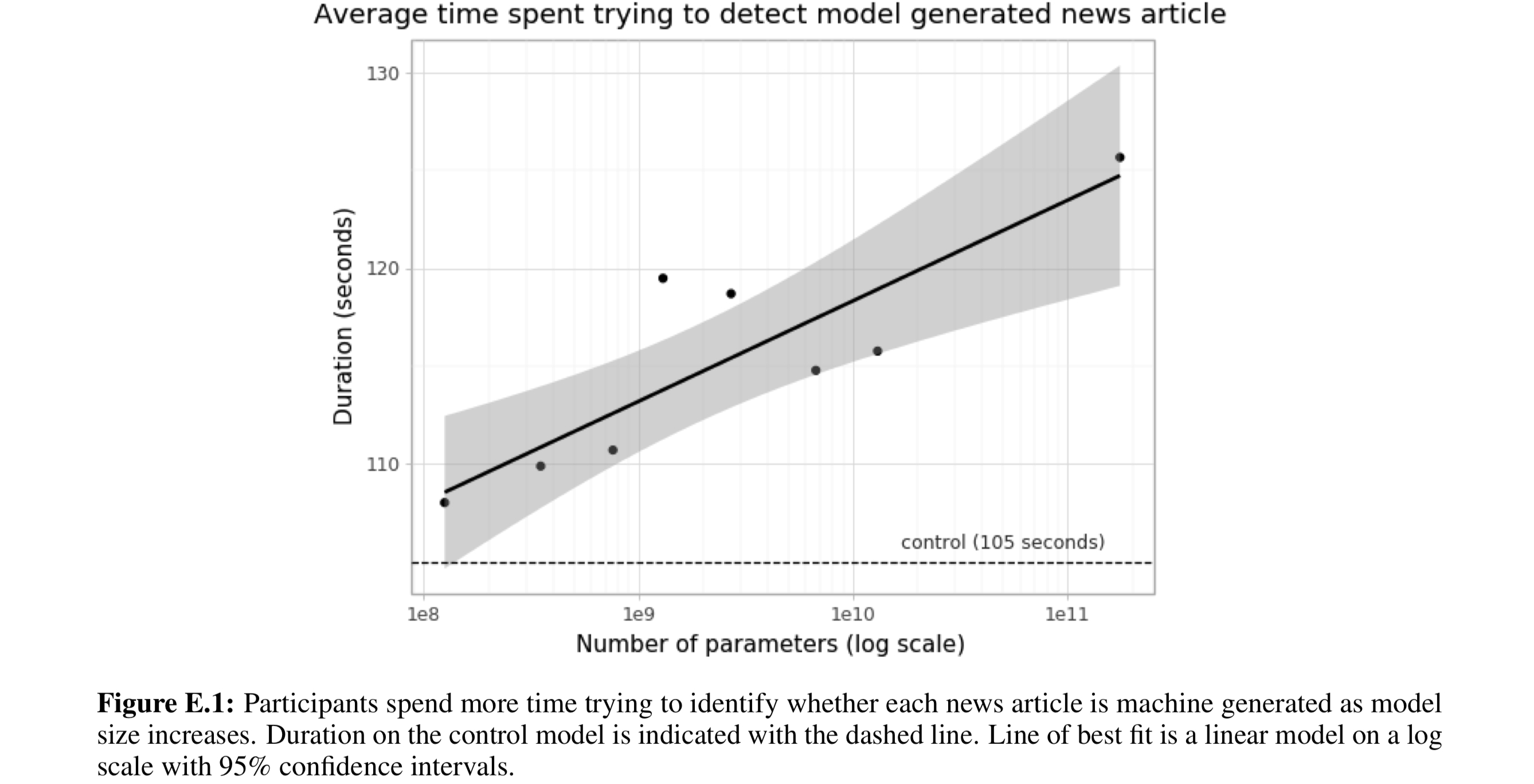
来源:[3] https://arxiv.org/pdf/2005.14165.pdf
GPT-3 以华莱士 - 史蒂文斯(Wallace Stevens)的风格创作了一首诗歌 [3]。我感到惊讶,我承认,有点害怕。

来源:[3] https://arxiv.org/pdf/2005.14165.pdf
2020 年 6 月,OpenAI 发布了其开发的用于访问不同 OpenAI 模型的API。该 API 运行预训练 GPT-3 模型系列,用于广泛的自然语言处理任务 [3]。GPT-3 模型不同于人工智能社区的常规做法,它的权重并不对外公布。
结论
OpenAI 长期宣称,与强化学习相结合的强大计算能力对于通向通用人工智能 (也就是能学习人类所能完成的任何任务的人工智能) 之路至关重要 [14]。
Yoshua Bengio 和 Yann LeCun 等人工智能 2.0 之父认为,通用人工智能无法从现有人工智能技术中建立起来。他们认为我们需要自监督学习(事实上 GPT-2 和 GPT-3 都是自监督的) 以及先进的神经生物学进展 [15]。
不过,人工智能 1.0 之父, Marvin Minsky 和 Andrew McCarthy 等人工智能的先驱们,都主张丰富的知识(数据)和常识推理专家组成的“社会”是通往通用人工智能的道路 [16]。
GPT-3 证明了扩展文本量(数据)、参数 扩展 (模型大小) 以及训练计算量的增加都将使专家们能够更准确地完成小样本自然语言处理任务(性能惊人)。
模型的架构、模型的大小和训练的计算量是否达到常识推理专家的要求?我们是否可以通过数据和常识推理来实现通用人工智能?
猜想:关于人工智能可能的未来
我看到人工智能研究人员犯的最大错误就是假定他们很聪明,实际上和人工智能相比不见得如此。
——伊隆・马斯克(Elon Musk)[12]
六十到六十五年前,第一批计算机中的一台装满了一个房间。六十年后,一台和我脑袋差不多大小的计算机,其核心已经扩展到第一台计算机的 10 亿倍(也许更多)。试想一下,第一台可行的量子计算机填满了整个房间。六十年后,一个只有我脑袋那么大的量子计算机,其核心也扩展到第一台量子计算机的 10 亿倍左右,会不会是这样?
也许吧。
试想,一台量子计算机,其通用人工智能模型的规模是 GPT-3 参数的 10 亿倍,或者是人脑参数的约 300 万倍。
“我曾预言,在 2029 年,我们会通过图灵测试。”
——Ray Kurzweil [11]。
注:GPT-3 与通过图灵测试的 GPT-3 非常接近 [13]。
GPT-3 在某些方面给人留下了深刻的印象,但在另一些方面仍然低于人类的水平。
——Kevin Lackey
你觉得我们会有 Hawking-Musk 或者 Havens-Kurzweil 的噩梦 [11,12] 吗?这两种情况都可能发生,也可能都不发生。
我把赌注押在工具制造上。我怀疑我们会改变,或者我们应该改变这种行为。我觉得,在 NuralLink 项目的帮助下,伊隆・马斯克正在为我们的工具制造业打赌人工智能的未来潜力 [17]。
参考文献
[1]成为人类意味着什么?
[2]人类大脑的规模
[3]语言模型是小样本学习
[6]更好的语言模型及其含义
[7]OpenAI 的大型 GPT-3 模型令人印象深刻,但规模并非一切
[9] 音乐剧《俄克拉荷马》中的堪萨斯城歌词
[10]迪拜哈利法塔——Kevin Lackey
[11]未来比你想象的要好:Ray Kurzweil 对人工智能和发展的预测
[12]人类是生物引导加载程序的数字超级智能——伊隆・马斯克
[13]给 GPT-3 做图灵测试——Kevin Lacker 博客
[14]人工智能训练如何扩展——OpenAI Blob 文章
[15]自监督学习是人类级智能的关键
[16]我们是否处在通用人工智能的边缘?
[17]伊隆・马斯克的 Neuralink 是神经科学的“剧场”
作者介绍:
Bruce H. Cottman 博士,物理学家、机器学习科学家,软件工程师。热衷从新兴技术中推断未来。
原文链接:
https://towardsdatascience.com/how-close-is-gpt-3-to-artificial-general-intelligence-cb057a8c503d

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论