

背景
在上一篇文章《详解阿里99大促活动页内容识别技术实现》里,我们介绍了在淘宝 99 大促中,我们使用了怎样的算法模型去识别并完成自动化测试的。
样本问题的困难点
淘宝大促有近百个模块、上千个页面,模块间具有相似性,并且模块内部具备多种状态,如果想要准确识别每个模块类型,单模块的样本数量至少要达到万级,而人工标注成本高、效率低下、数据量少,纯靠人力是无法满足模型诉求的。基于此,今天,我来介绍下,模型识别背后的大批量数据样本生成的技术方案。
思路
总体技术方案如下,后面会分别详细讲:
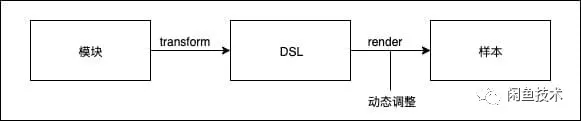
模型的样本要求
算法模型识别的输入是 99 大促的各个会场截图,输出是目标模块名称及其在截图中的坐标位置。
模型训练时,就是把模块渲染图、相应坐标位置与模块类型输入给模型,交给模型去进行监督学习。而模型需要的,就是各个模块大批量的图片样本。
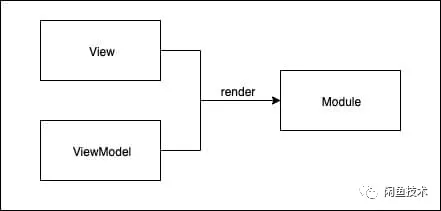
一个模块,是由 View 和 ViewModel 组合而成,而 View 是固定的,ViewModel 跟随会场场景不同,是动态变化的。
那么,如果我们能拿到描述模块的 View 的这一层 DSL,辅助以动态的 ViewModel 数据,再把 View 和 ViewModel 渲染成图片,那我们就可以生成无穷无尽的样本数据了。
DSL 描述 View
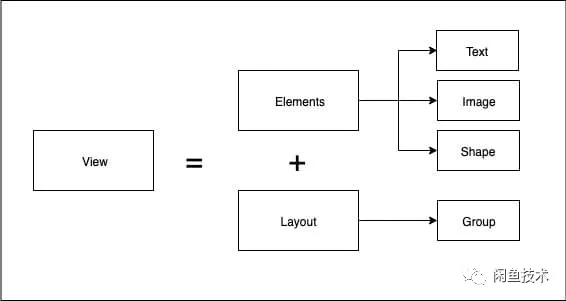
仔细梳理之后,View 拆分为原子级元素(Text、Image、Shape)和原子级元素的组合关系(Group),即与 HTML DOM 树状结构中的各层级容器嵌套与叶子节点类型是同样的逻辑。
基于节点类型和节点样式的 DSL,我们就能描述一个完整的 View 了。
其中,除了节点类型和节点样式之外,最外层的 moduleName 代表模块名称,id 是为了标记每一个子元素,frame 是每个子元素的坐标位置、辅助算法模型识别模块内部子元素,value 值只有 text 和 image 才有,对应相应的文本值还有图片链接。
获取模块 View 的 DSL
有 3 种方案可以获取到模块 View 的 DSL,分别是:
从代码仓库中获取;
从 sketch 视觉稿中生成;
从浏览器渲染好的页面中获取。
我最后选择了第三种方案,放弃第一个方案是因为代码写法千差万别,很多展现逻辑还包含在 js 代码中,并且还要处理各种 for 循环子 View、style 的映射关系等等,复杂度太高。第二个方案目前集团内已有技术方案 imgcook,这一块的准确率听说还不错,并且一直在持续优化,而最终选择第三个方案的原因是,能 100%准确地还原模块 DSL,并且只需要关注模块最终展现给用户时候的形态,不需要理会过程中开发者做得各种复杂业务逻辑,复杂度相对低很多。
技术方案
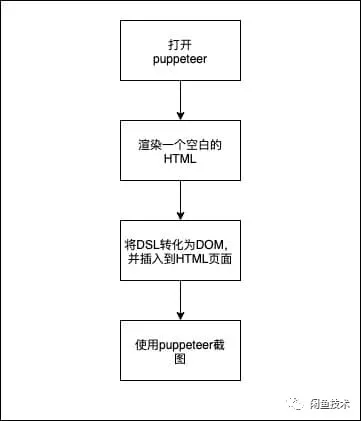
在开发流程上,每个模块在开发完成后,都会有对应的模块预览页面。我使用了 puppeteer 模拟真实浏览器,对模块的节点信息进行提取,并保存为规范的 DSL。
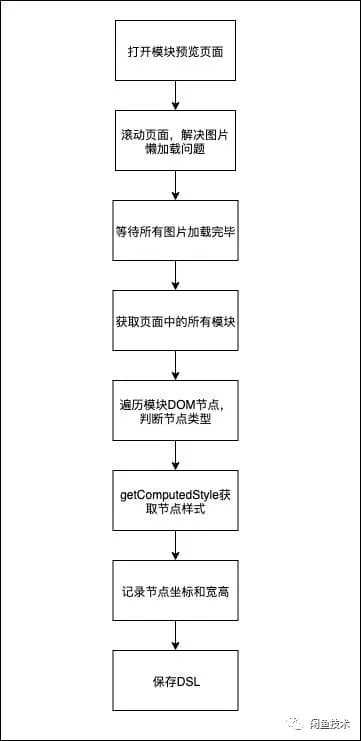
清洗 window.getComputedStyle
通过 window.getComputedStyle 获取 DOM 节点的样式,会返回包含 280 个样式属性的对象,如果把每个 DOM 节点的所有 280 个样式属性都存储到 DSL 中,会造成两个问题:
DSL 文件冗余,且文件大小过大,解析耗时。
增加算法同学对 DSL 的理解和调整成本。
第一步,隐藏默认属性值;
大部分的样式属性都是默认值,我们首先把默认的样式属性剔除出去。
第二步,剔除无效属性;
开发者常用的样式属性在 20 个左右,有很多的样式是不具备实际效用的,把无效用的样式属性剔除掉,比如说:
第三步,transform 动态计算
通过 getComputedStyle 拿到的 transform 属性值是一个矩阵方法 matrix(),感兴趣的同学可以去学习理解下 2D 转换矩阵。我们使用 puppeteer 模拟浏览器设置的屏幕宽度是 750,也就是说,得到的 transform 值中 translateX 和 translateY 两个值是以 750 为基准换算得到的一个数字,假如想要在下面描述到的将 DSL 渲染成图时(算法同学期望能模拟各种各样的屏幕尺寸去生成样本),就必须将获取到的 transform 值换算成相应屏幕设备时的值。
通过以上 3 个步骤,最终得到的 DOM 节点样式属性个数一般维持在 20 个以内,能使输出的 DSL 精简非常多。
DSL 渲染成图片
同样的,我们能基于 puppeteer 去对页面做操作,也能使用它去把 DSL 渲染成目标模块页面,并截图。
首先,建立 DSL 与 HTML 标签的映射关系
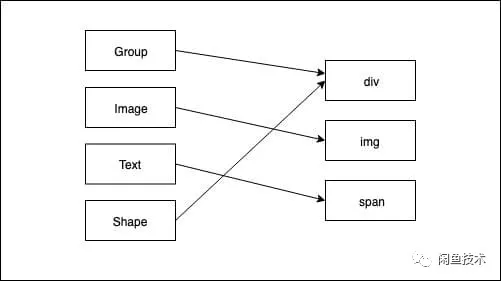
其次,如果是 DSL 类型为 Group,就递归遍历里面的所有子元素,以此类推。完整的渲染流程图如下:
ViewModel 动态数据
一个模块,应用到 99 大促、双十一等各种会场,背后样式都是一致的,只有对应的数据不同,动态的数据一般是商品图片和商品信息。
闲鱼有一亿多的商品数据,如果把这商品数据拿过来与 View 一起渲染成模块,每个模块就有了成千上万种展现形态,且贴合算法模型实际识别过程中的输入,既能满足样本数量的要求,也能符合模型实际识别的场景,使模型准确率获得更大地提升。
效果
通过这样一条生成样本的通道,每个模块都能够提供给算法同学几万张质量很高的样本截图,使模型的准确率达到 98%以上。
展望
上述文章描述了如何批量生成样本来帮助解决算法模型对 99 大促和双十一会场中各个模块的识别。
目前,对模块 DSL 的动态调整依赖算法同学对模块的理解,eg.改变圆角 borderRadius 生成更多正向样本,或者增加噪声,eg.删除商品内容节点等生成负向样本,这些操作都需要算法同学对 DSL 进行定制化配置。在未来,我们希望尝试把这部分的工作也交给模型去处理,让模型对样本生成做决策,调整 DSL 的局部,并生成样式更加丰富和可靠的样本。
本文转载自公众号闲鱼技术(ID:XYtech_Alibaba)。
原文链接:
https://mp.weixin.qq.com/s/CvS4y73Q7hgIAfSzhxEuNg

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论