
注意:本文是“Kubernetes 资源管理与优化”系列文章的第 3 篇。在这篇文章中,我们将介绍如何使用机器学习来有效地管理 Kubernetes 资源。之前的文章介绍了Kubernetes资源类型和请求与限值。
随着 Kubernetes 成为应用程序容器编排的事实标准,有两个重要的问题摆在了我们面前:一个是优化策略,另一个是最佳实践。组织采用 Kubernetes 的其中一个原因是提升效率,并随着工作负载的变化向上或向下扩展;然而,Kubernetes 提供的细粒度控制在带来灵活性的同时,也带来了优化方面的挑战。
在这篇文章中,我们将介绍如何使用机器学习来自动优化这些资源,并随着工作负载的变化实现有效地扩展。
优化的复杂性
在很大程度上,优化 Kubernetes 应用程序就是确保代码尽可能高效地利用底层资源——即 CPU 和内存。也就是说,要用最低的成本和工作量保证性能满足或超出服务水平目标。
在创建集群时,我们可以在容器层面配置两种主要资源:内存和 CPU。也就是说,对于应用程序使用和请求多少资源,我们可以设置一个限值。我们可以将这些资源设置视为输入变量,而将性能、可靠性以及运行应用程序所使用的资源(或付出的成本)视为输出。随着容器数量的增加,变量数也会增加,集群管理和系统优化的总体复杂性也会呈指数增长。
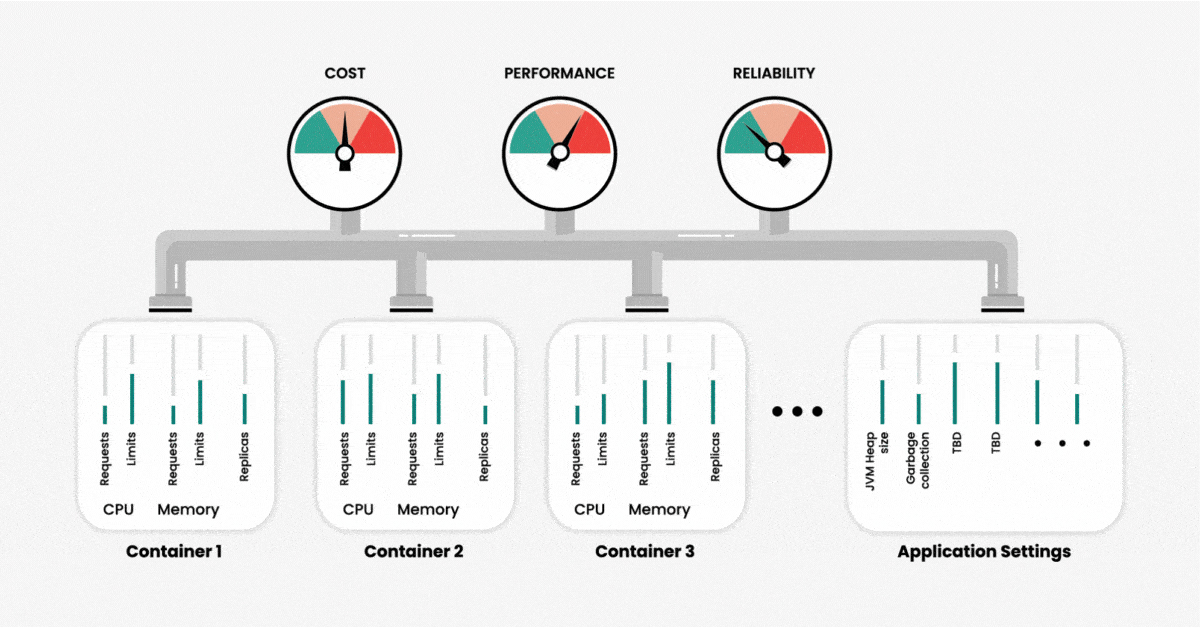
图 1:在考虑 Kubernetes 配置时,可以将资源设置视为变量,将成本、性能和可靠性视为输出结果。
不同资源的参数是相互依赖的,这使得问题进一步复杂化。修改一个参数可能对集群性能和效率产生意料不到的影响。也就是说,要想通过手动配置获得最佳性能几乎是一项不可能完成的任务,除非你有无限多的时间和 Kubernetes 人才。
如果在部署容器时没有设置自定义的资源值,那么 Kubernetes 会自动赋值。这里有一个问题是,为了避免下面两种情况,Kubernetes 对于资源会非常慷慨:因内存溢出(OOM)导致服务失败以及因 CPU 限制导致性能不合理地下降。然而,使用默认配置创建基于云的集群,会导致云成本徒高而性能却没有保障。
当我们设法管理数个集群的多个参数时,问题会变得愈加复杂。为了提升环境的价值指标,机器学习系统会是一个很好的补充。
机器学习优化方法
基于机器学习的优化方法通常有两种,它们提供值的方式不同:一种是基于实验的优化,在非生产环境中进行,使用各种场景模拟可能的生产场景;另一种是基于观测的优化,在生产或非生产环境中进行,通过观测系统的实际行为来进行。
下面我们将分别介绍下这两种方法。
基于实验的优化
通过实验进行优化是一种强大而科学的方法,因为我们可以尝试任何可能的场景,度量输出成果,调整变量并再次尝试。由于实验是在非生产环境中进行的,所以我们只会受限于我们的场景想象力以及做实验的时间和精力。如果实验是手动进行的,则需要付出大量的时间和精力。这时就轮到机器学习和自动化发挥了。下面我们看下,在实践中基于实验的优化是如何进行的。
步骤 1:确定变量
要进行实验,我们首先必须确定优化哪个变量(也称为参数)。常见的参数有 CPU 和内存请求与限值、副本数量,以及特定于应用程序的参数,如 JVM 堆大小和垃圾收集设置。
有些 ML 优化方案可以扫描集群自动确定可配置的参数。扫描过程还可以获取集群参数的当前值或基线值作为实验的初始值。
步骤 2:设定优化目标
接下来,必须指定优化目标。换句话说,你希望最小化或最大化哪个指标?一般来说,目标涉及多个指标的平衡,如性能和成本。举例来说,你可能希望最大化吞吐量,同时又最小化资源成本。
有些优化方案允许你给每个优化目标增加权重,因为在某些情况下,性能可能比成本更重要,反之亦然。此外,你可能会希望指定每个目标的界限。例如,你可能会希望,在任何场景下,性能都不能低于特定的阈值。这种保护性设置有助于提高实验速度和效率。
以下是选取合适的指标作为优化目标时一些需要考量的因素:
如果容器化应用程序是基于事务的,则应最小化响应时间和错误率。在这种情况下,理想状态是最大化速度,资源使用率则不那么重要。
如果应用程序仅供计算使用,则应最小化错误率。我们会希望优化执行效率。
如果应用程序是用来处理数据的,则速度可能就是次要的。应优化成本。
当然,这里只是举了几个例子。确定合适的优化指标需要开发人员和负责业务操作的人员之间进行沟通,确定组织的主要目标,然后看下技术如何帮助我们达成这样的目标以及需要做什么。最后,制定一份计划,聚焦可以充分平衡成本与效能的指标。
步骤 3:确定优化场景
在基于实验的方法中,我们需要确定要优化的场景,并把这些场景构建到负载测试中。这可能是一个预期的用户流量范围,也可能是一个特定的场景,像零售假日的流量峰值。该性能测试将用于在实验过程中模拟生产负荷。
步骤 4:运行实验
一旦设定好实验的优化目标和可调优参数,就可以开始实验了。每个实验都包含多轮测试。在每一轮测试时,优化方案都会迭代执行以下步骤:
实验控制器使用第一次测试的基线参数在集群中运行容器化应用程序。
然后,控制器运行之前创建的性能测试,针对我们的优化场景将负载应用到的系统中。
控制器捕获要优化的指标,如持续时间和资源成本。
机器学习算法分析结果,然后计算生成一组新的参数,以供下一轮测试使用。
然后,根据配置实验时指定的测试轮数,重复这个过程。通常,实验会测试 20 到 200 轮不等,参数越多,测试轮数也会越多。
机器学习引擎使用每一轮测试的结果构建一个表示多维参数空间的模型。在这个空间中,它可以检查参数之间的关系。在每次迭代中,ML 引擎可以确定趋近指标优化目标的配置。
步骤 5:分析结果
虽然机器学习会自动推荐可以获得最佳结果的配置,但我们还是可以在实验完成后进行分析。例如,我们可以将两个不同目标的平衡过程可视化,看看哪个指标对结果的影响大,哪个影响小。
结果经常让人吃惊,那可能会引发重要的架构改进:例如,发现大量的小副本比小量的“重”副本更高效。
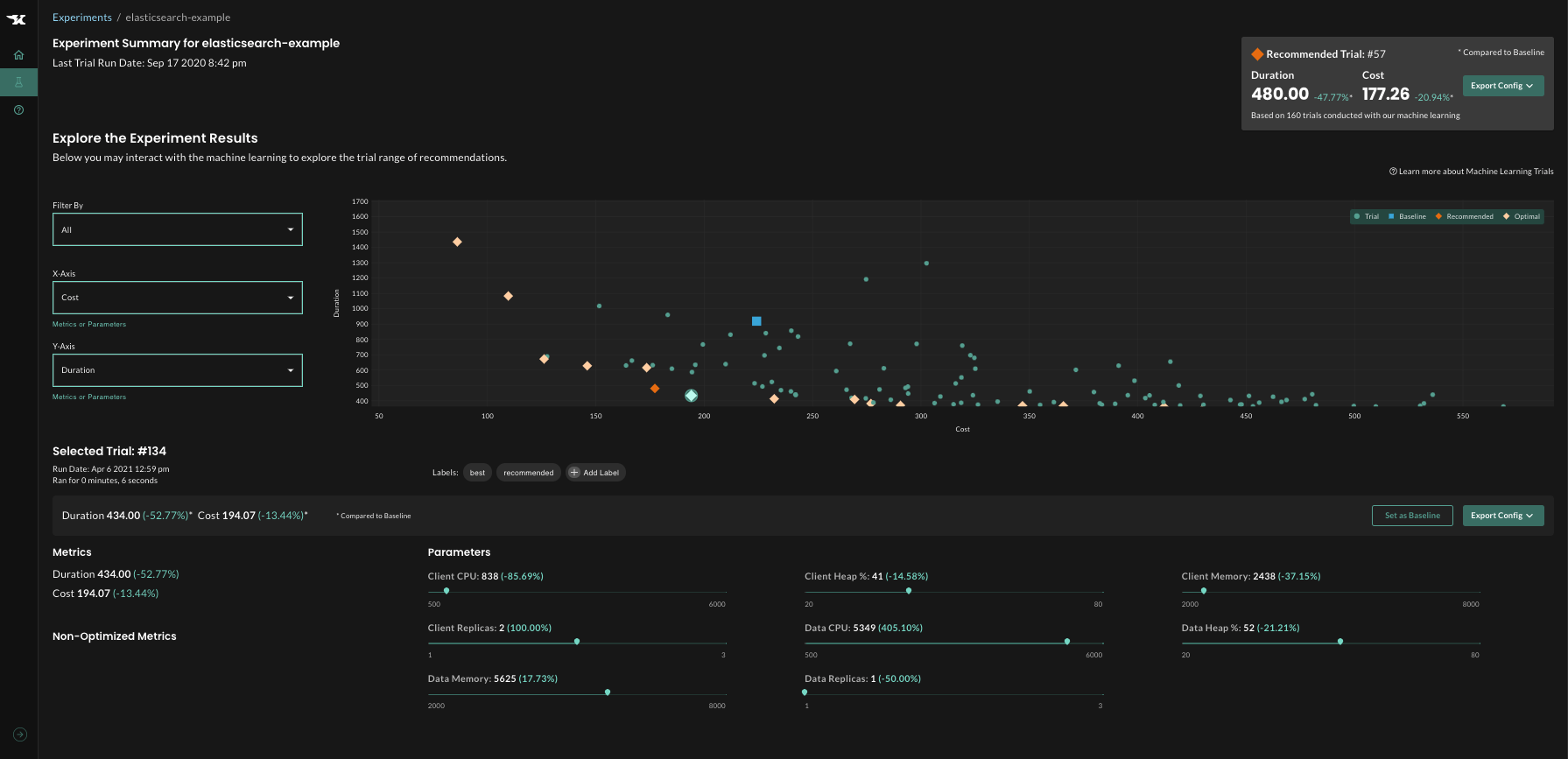
图 2:将实验结果可视化,通过分析充分理解系统行为。
基于观测的优化
虽然对于许多场景的分析来说,基于实验的优化已经很强大,但我们不可能预见所有情况。此外,用户流量大幅变化,某事某刻的最优配置在情况出现变化时可能就不是最优的了。Kubernetes autoscalers很有用,但它们以历史使用情况为基础,没有考虑应用程序的性能。
这就轮到基于观测的优化方案发挥作用了。让我们看下它的工作原理。
步骤 1:配置应用程序
在使用基于观测的优化方案时,应用程序配置可能包含以下步骤:
指定命名空间和标签选择器(可选),以确定要对哪些资源进行调优。
为要调整的 CPU 和内存参数指定保护值(最小和最大)。
指定系统应该多久一次建议更新参数设置。
指定是根据建议自动部署还是经审批后部署。
步骤 2:机器学习分析
配置完成后,机器学习引擎将开始分析从Prometheus、Datadog或其他观测工具收集到的观测数据,了解实际的资源使用情况和应用程序性能趋势。然后,系统将按照配置时指定的时间间隔提供建议。
步骤 3:根据建议部署
如果你在配置时指定了自动实施建议方案,那么优化方案会使用建议的配置自动修改部署。如果你选择手动部署,则可以在决定是否同意部署之前查看建议,包括容器级的细节信息。
最佳实践
你可能已经注意到,基于观测的优化比基于实验的优化简单些。它能以较低的成本更快地提供建议值,但另一方面,基于实验的优化更强大,让你可以深入洞察应用程序,而这在基于观测的方法中是不可能的。
不过,这两种方法并非是不相容的:每种方法都有自己的优势,你可以同时使用两种方案来缩小生产和非生产之间的差距。下面是一些指导性原则,供参考:
由于基于观测的优化很容易实现,而且很快就可以看到改进效果,所以应该在你的环境里广泛部署。
对于比较复杂或关键的应用程序,更深入的分析会有所助益,可以使用基于实验的优化作为对基于观测的优化的补充。
此外,可以使用基于观测的优化识别需要通过基于实验的优化进行更深入分析的场景。
使用基于观测的方法不断验证和完善基于实验的实现,形成生产环境优化的良性循环。
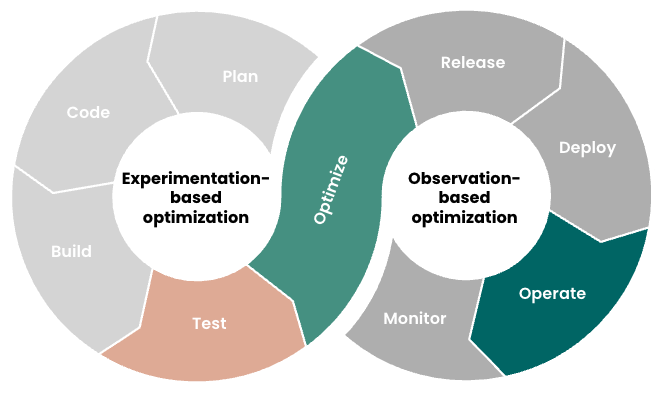
图 3:同时使用基于实验和基于观测的方法创建一个系统的、持续优化的良性循环。
小结
优化 Kubernetes 环境,实现效率最大化,扩展智能化,并达成我们的目标,需要:
在部署之前有一个最合理的应用程序和环境参数配置;
在部署后持续监控和调整。
对于规模较小的环境,这项工作很难。但对于在 Kubernetes 上大规模运行应用程序的组织来说,这项工作很可能已经超出了人工劳动的范围。幸运的是,机器学习可以提升自动化水平,在各个层面提供优化 Kubernetes 环境的有力洞察。
原文链接:
Using Machine Learning to Automate Kubernetes Optimization




