

12 月 2 日,InfoQ 获悉,达摩院深度语言模型体系 AliceMind 发布中文社区首个表格预训练模型 SDCUP,该模型在全球权威表格数据集 WikiSQL、SQuALL 上取得了业界最优效果,且模型和训练代码均已对外开源。
开源地址:
https://github.com/alibaba/AliceMind

表格是应用普遍的结构化数据,也是智能对话系统和搜索引擎的重要答案来源。但传统表格查询需技术人员撰写专业查询语句,阻碍了表格查询的大规模应用。
新兴的表格问答技术,可将自然语言转换为查询语句,使用户能通过简单问句直接与表格数据库交互,具有广泛应用前景。
不过,由于表格内容复杂多样、涉及各行业专业知识,表格问答任务一直是自然语言处理领域的难题。此前,谷歌、微软、亚马逊等海外公司开展了相关探索,但在中文场景,该方向处于空白。
本次,达摩院对话智能团队提出了首个中文表格预训练模型 SDCUP,其基于“模式依存”方法,通过模型直接预测自然语言与表格结构内容的关键词映射,提升了表格问答的准确率。
具体而言,即参考语义依存分析方法对 Schema Dependency 任务建模,使用全连接网络获取每个节点作为父亲节点和作为孩子节点的语义表示,然后使用双仿射网络预测每个边存在的概率和该边关系类型的概率。同时,团队使用了模仿人类的“课程学习”方法减少数据噪声。
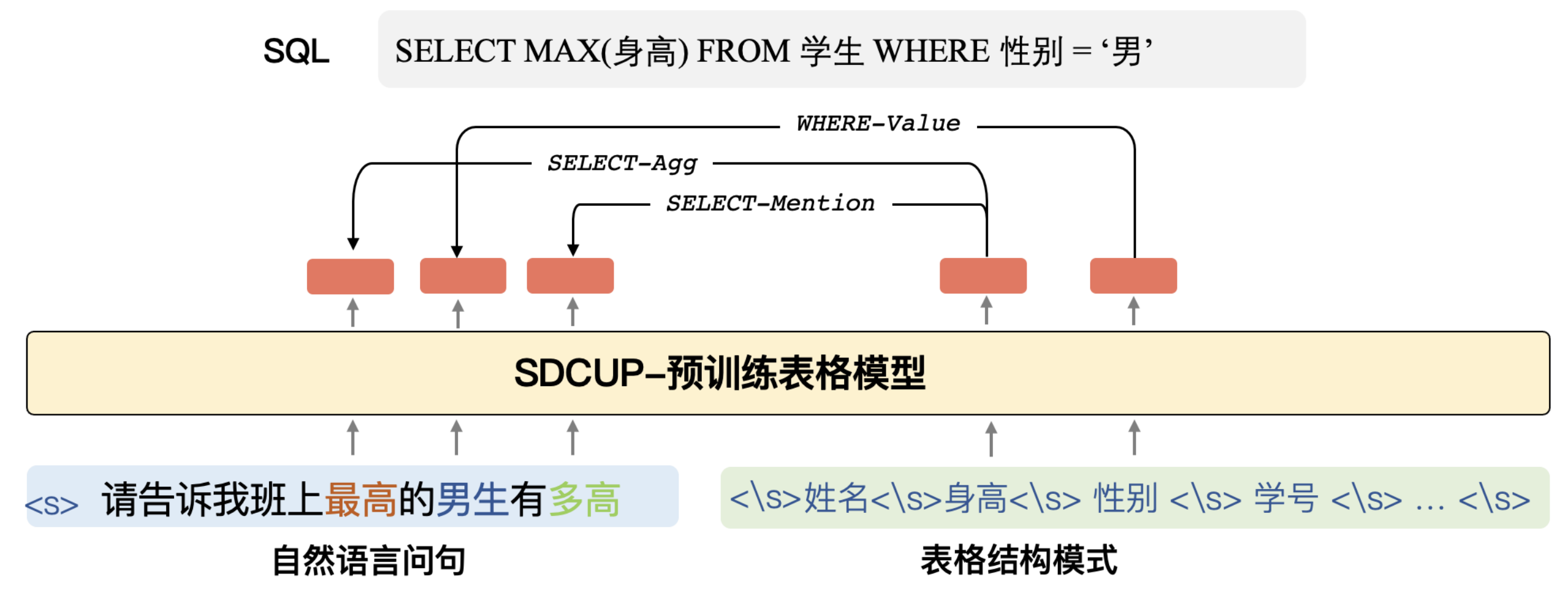
SDCUP 生成 SQL 示例
在耶鲁大学发布的业界最大规模的英文文本-表格数据集 WikiSQL,以及微软构建的英文文本-表格高难度预测任务 SQuALL 数据集上,SDCUP 模型均取得业界最优效果。在达摩院构建的表格问答中文数据集 TaBLUE 上,SDCUP 比同参数规模 BERT 模型效果提升约 3 个百分点。
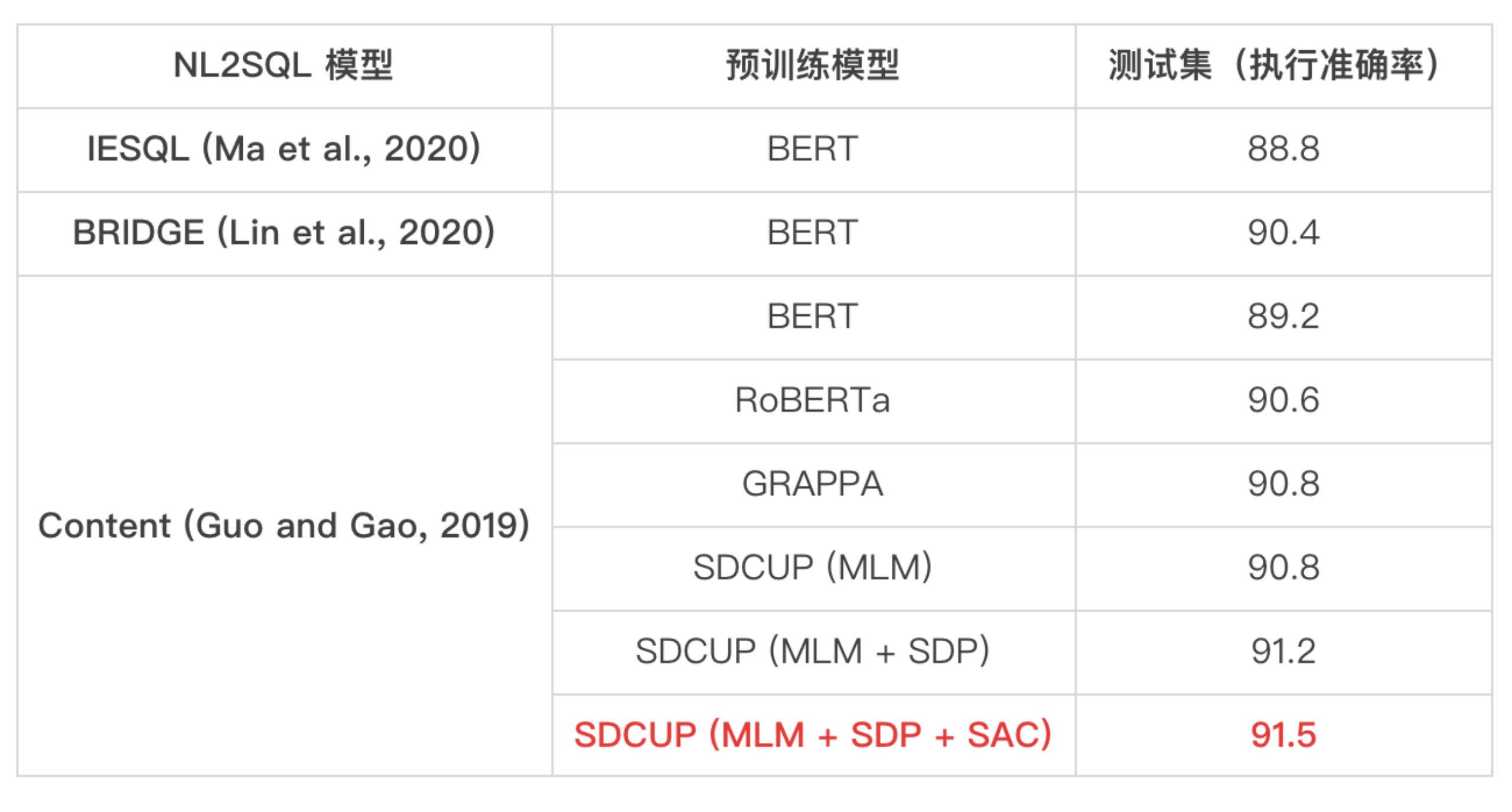
SDCUP 在 WikiSQL 数据集上取得业界最优效果

SDCUP 在 SQuALL 数据集上取得业界最优效果
达摩院资深算法专家李永彬介绍,SDCUP 模型是达摩院表格对话技术系列研发的一部分,后续将持续对外开源。其相关技术先后在四大国际公开数据集 WikiSQL、Spider、SParC、CoSQL 上取得第一。
据了解,该技术完成了产品化,已通过阿里云智能客服为政务、金融、零售等行业客户提供表格问答和数据库自然交互服务。

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论