

过去十年来,神经网络的训练速度得到了大幅提高,使得深度学习技术在许多重要问题上的应用成为可能。随着摩尔定律即将走向终结,通用处理器的的改进未取得明显成效,机器学习社区越来越多地转向专用硬件来谋求额外的加速。
GPU 和 TPU 针对高度并行化的矩阵运算进行了优化,而矩阵运算正是神经网络训练算法的核心组成部分。在高层次上,这些加速器可以通过两种方式来加速训练。首先,它们可以并行处理更多的训练样本;其次,它们可以更快地处理每个训练样本。我们知道,并行处理更多训练样本的加速是有限制的,但构建更快的加速器,还能继续加速训练吗?
遗憾的是,并非所有训练管道中的操作都是在加速器上运行的,因此,不能简单地依靠速度更快的加速器来继续推动训练速度的提升。例如,训练管道中的早期阶段(如磁盘 I/O 和数据预处理)涉及到的操作并不能从 GPU 和 TPU 中受益。随着加速器的改进超过 CPU 和磁盘的改进,这些早期阶段日益成为瓶颈,从而浪费加速器的容量,并限制了训练速度的提升。

图为代表了许多大型计算机视觉的训练管道示例。在应用小批量随机梯度下降(mini-batch stochastic gradient descent,(SGD))更新之前的阶段一般不会受益于专用硬件加速器。
考虑这样一个场景:代码从上游到加速器的时间是代码在加速器上运行时间的两倍,对于目前一些工作负载来说,这个场景已经很现实了。即使代码以流水线的方式并行执行上游和下游阶段,上游阶段的代码也会占据大量的训练时间,加速器将有 50% 的时间处于闲置状态。在这种情况下,构建更快的加速器来加速训练根本无济于事。也许,可以通过增加工作量和额外的计算资源来加快输入管道的速度。但这种努力很费时,并且还偏离了提高预测性能的主要目标。对于非常小的数据集,人们可以离线预计算扩展后的数据集,并在内存中加载整个经过预处理后的数据集,但这一做法对于大多数机器学习训练场景来说,行不通。
在论文《通过数据回传加速神经网络训练》(Faster Neural Network Training with Data Echoing)中,我们提出了一种简单的技术,可以重用(或“回传”)早期管道阶段的中间输出,以回收闲置的加速器容量。与其等待更多数据可用,倒不如我们只需利用已有的数据来保持加速器的繁忙状态。

左图:在没有数据回传的情况下,下游算力有 50% 的时间处于闲置状态。
重复数据以加快训练
假设有这样一种情况,对一批训练数据进行读取和预处理所需的时间,是对该批数据执行单个优化步骤所需时间的两倍。在这种情况下,在对已预处理的批处理进行第一个优化步骤之后,我们就可以重用该批处理,并在下一个批处理准备好之前执行第二个步骤。在最好的情况下,重复的数据和新数据一样有用,我们将会看到训练的速度提高了两倍。不过,在现实中,由于重复数据不如新数据有用,数据回传带来的速度提升略小,但与让加速器处于闲置状态相比,它仍然可以带来显著的速度提升。
在给定的神经网络训练管道中,通常有几种方法可以实现数据回传。我们提出的技术涉及到将数据复制到训练管道中某个位置的数据洗牌缓冲区(shuffle buffer)中,但是我们可以在给定管道中产生瓶颈的任何阶段之后自由地插入这个缓冲区。当我们在批处理前插入缓冲区时,我们称之为技术样本回传(technique example echoing);而当我们在批处理之后插入缓冲区时,我们称之为技术批处理回传(technique batch echoing)。样本回传会在样本级别上对数据进行洗牌,而批处理回传则对重复批的序列进行洗牌。我们还可以在数据扩展之前插入缓冲区,这样,每一份重复数据的副本都略有不同(因此更接近于新鲜样本)。在不同阶段之间放置数据洗牌缓冲区的不同版本的数据回传中,所能提供最大速度提升的版本取决于具体的训练管道。
跨工具负载的数据回传
那么,重用数据能有多大用呢?我们在五个神经网络训练管道上尝试了数据回传,这些训练管道涵盖了三个不同的任务:图像分类、语言建模和目标检测,并测量了达到特定性能目标所需的新鲜样本的数量。在超参数调优过程中,我们选择的目标与基线能够可靠达到的最佳结果相匹配。我们发现,数据回传让我们能够用更少的新鲜样本达到目标性能,这表明,重用数据对于降低各种任务的磁盘 I/O 非常有用。在某些情况下,重复数据几乎和新鲜数据一样有用:在下图中,扩展前的样本回传,几乎按重复因子减少了所需的新鲜样本的数量。
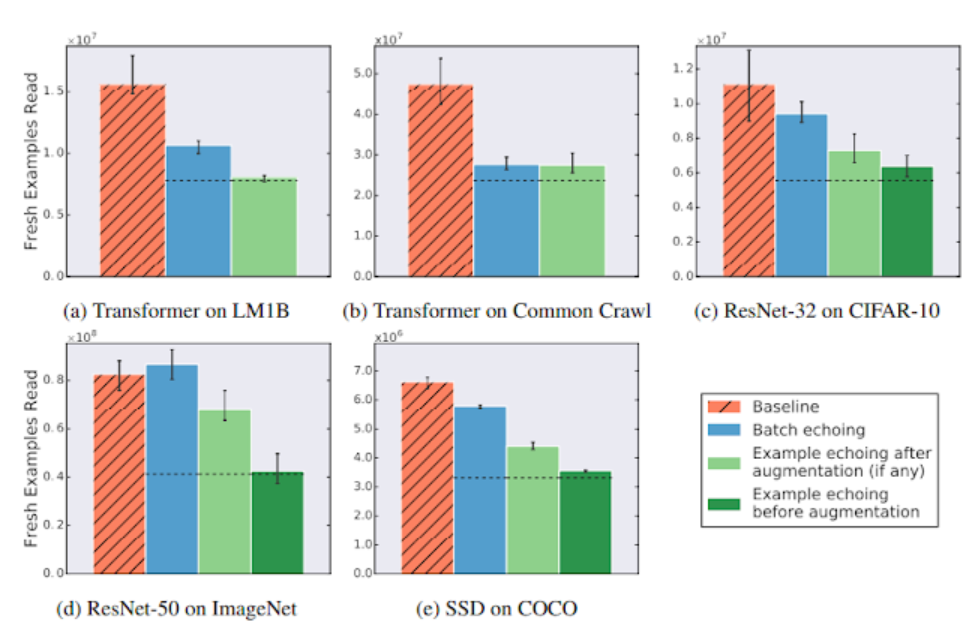
当每个数据项重复两次时,数据回传会减少或不改变达到目标样本外性能所需新鲜样本的数量。虚线表示我们所期望的值,假设重复样本和新样本一样有用。
缩短训练时间
当加速器上游的计算占用训练时间时,数据回传可以加速训练。我们测量了在训练管道中实现的训练提速,该管道由于来自云存储的流式传输训练数据的输入延迟而成为瓶颈,这对于当今许多大规模生产工作负载或任何人来说,通过网络从远程存储系统流式传输训练数据都是现实的。我们在 ImageNet 数据集上训练了 ResNet-50 模型,发现数据回传提供了显著的训练提速,在这种情况下,使用数据回传时,速度要快三倍以上。
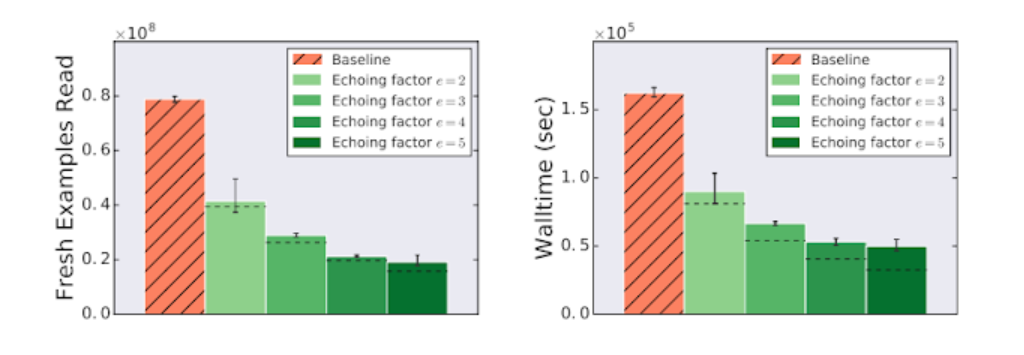
数据回传可以减少 ResNet-50 在 ImageNet 上的训练时间。在此实验中,从云存储中读取一批训练数据,比使用每批数据进行训练步骤的代码要长 6 倍。图例中的回传因子指的是每个数据项重复的次数。虚线表示如果重复样本与新样本一样有用且不存在回传开销时的期望值。
数据回传保持了预测性能
尽管人们可能会担心重用数据会损害模型的最终性能,但我们发现,在我们测试过的任何工作负载中,数据回传并没有降低最终模型的质量。
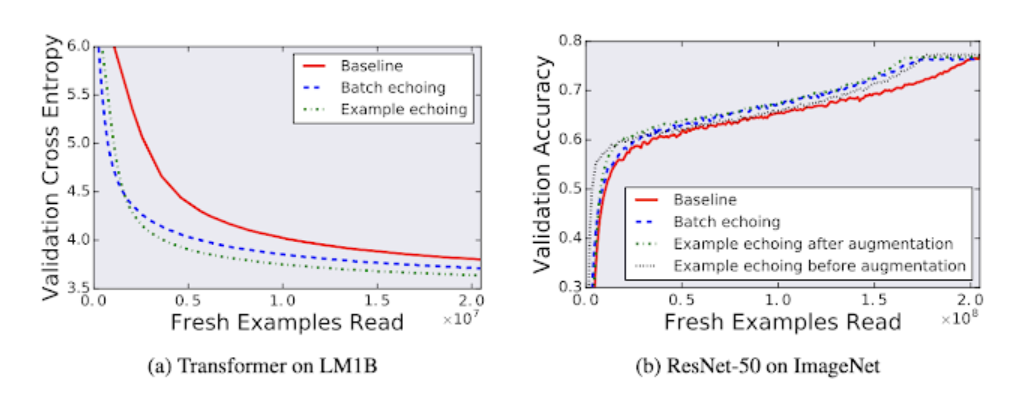
通过比较在训练期间获得最佳样本外性能的单个实验,无论有无数据回传,都表明重用数据并不会损害最终模型质量。此处的验证交叉熵(cross entropy)相当于对数困惑度(log perplexity)。
随着 GPU 和 TPU 等专用加速器的改进继续超过通用处理器,我们预计,数据回传和类似策略将会成为神经网络训练工具包中越来越重要的部分。
作者介绍:
Dami Choi,Google AI 学生研究员。George Dahl,高级研究科学家,供职于 Google Research。
原文链接:
https://ai.googleblog.com/2020/05/speeding-up-neural-network-training.html

加V:busulishang4668

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论