
在好大夫在线每天的线上问诊中,包含了大量的各种医院报告单、化验单等图片,如何识别并格式化这些报告单数据,成了我们面临的一大难题。如果这些报告单仅以图片形式存储在服务器中,就难以发挥其在问诊过程中的重要价值,无法为问诊医生提供更准确的参考信息。本文将从实际业务需求、技术挑战、各种算法的尝试等方面,逐一探讨我们是如何解决这类问题的。
一、项目背景及挑战
1.1 项目需求背景
好大夫网站上,用户平均每天上传数万张图片,这些图片中大部分都是医学检查报告单(如血常规、肝功能等)。其中蕴含着大量的有价值的信息,但由于这些照片不是结构化的数据,导致无法进行索引和检索等一系列复杂功能。
一方面,医生有将报告单中的关键信息誊写到病历上的需求,这可以使医生能更加清楚明白地跟踪患者病情发展,但是这个过程太过于繁琐。
另一方面,无法提取报告单中的具体信息导致这部分医疗数据无法被利用起来。
“医学报告单结构化”项目便是在这个需求背景下成立了。该项目要求算法能读取出患者上传报告单中的文本信息,并将其组合成表格的形式,以便存储和利用(如图 1.1 所示)。

1.2 所用技术概述
本项目所用的技术都属于人工智能的范畴。图 1.2 展示了“人工智能”技术领域的三大分支,以及各分支的主要细分支。
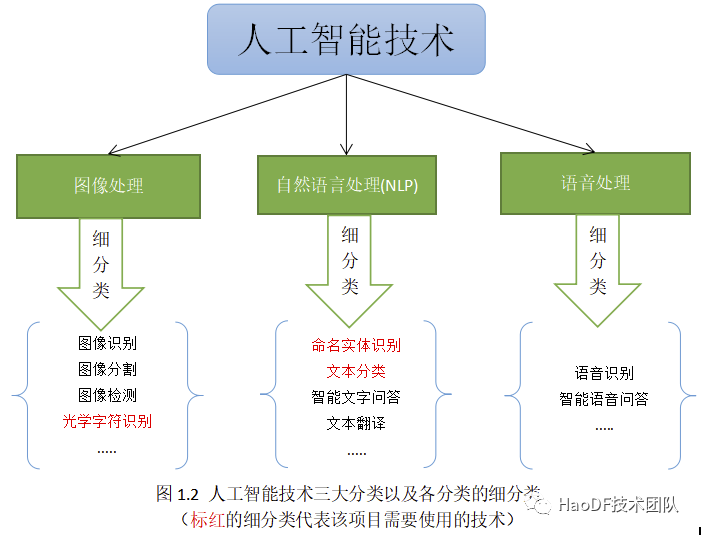
该项目同时涉及图像处理和自然语言处理两大人工智能技术分支。
首先,我们需要用到 OCR(Optical Character Recognition,光学字符识别)技术将图像转化为文字。OCR 技术是图像处理技术的一个分支,其通常包含“文本区域检测”和“文字识别”。
其次,需要用“文本分类”技术项将报告单分类为血常规、肝功能等一系列的类别,该技术是 NLP(Natural Language Processing,自然语言处理)的一个重要分支。
最后,需要用到 NER(Named Entity Recognition,命名实体识别)技术从识别出的文本中准确地提取“检查项名”、“项数值”、“项范围”等字段,该技术同样是 NLP 的一个重要分支。
1.3 项目面临的挑战
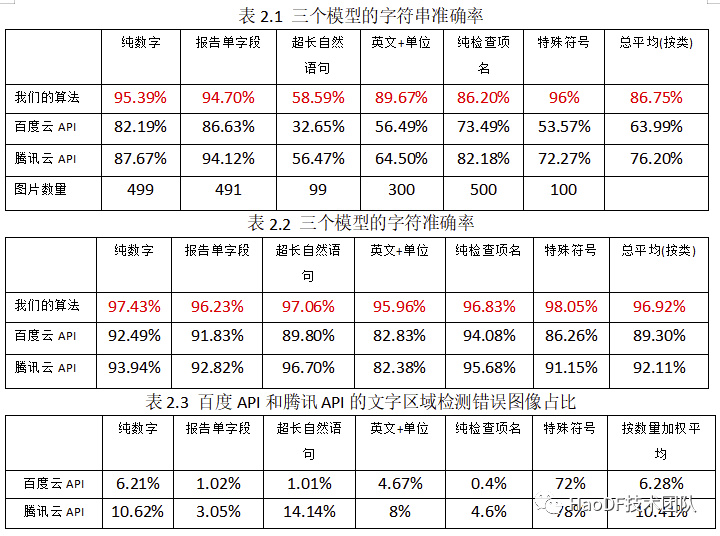
准确率方面。由图 1.3 可以看出,用户上传的报告单照片的干扰是非常大的,不仅有噪声的问题,还有文本倾斜,甚至文本弯曲。这些干扰会严重影响文字识别的准确率。为了评估报告单图像识别难度,我们整理了“好大夫在线医学报告单文本行数据集 v1.0”(如图 1.4 所示),是从报告单图像中切割出近 2000 个文本行切片,然后进行人工标记。将该数据集输入到百度通用 OCR 接口和腾讯 OCR 接口中进行识别,结果“字符串”准确率都没超过 85%(实验详细结果详见本文 2.2),远不能满足我们最终的要求。同时也可以看出该项目的难度之大。


执行速度方面。一天需要处理的报告单数量在 6 万左右,要在一天内处理完这些数量的报告单,则要求算法处理每张图像的平均时间不能超过 1.44 秒。否则很容易造成积压,影响用户体验。而百度和腾讯通用 OCR 接口处理每张报告单的速度均在 7 秒以上,远不能满足我们项目的需求。
数据数量方面。虽然服务器中储存了上亿张医学报告单照片,但都是没有被标记的数据。人工智能算法的完善是需要大量被标记的数据,数据质量越高,算法表现越好。但标记的过程需要大量人工成本。
硬件配置方面。考虑到项目投入的性价比问题,我们舍弃了一些运行负载非常高的算法。
二、应用的相关技术及难点
项目主体使用 Python,某些模块为了效率使用 C++语言编写成动态链接库供 Python 调用。在测试环境下,该项目检测一张报告单图像的时间平均 1.04 秒。该项目的整体程序框图如图 2.1 所示:
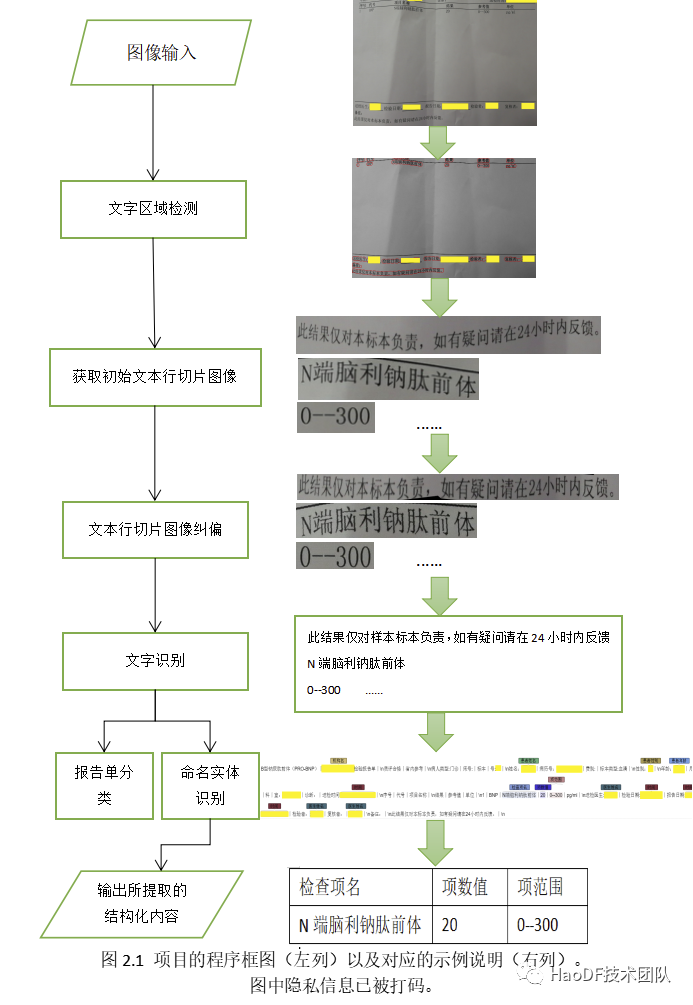
共分为:1)文字区域检测 2)文字识别 3)报告单分类 4)命名实体识别 5)结构化内容提取,这五个部分。
2.1 文字区域检测模块
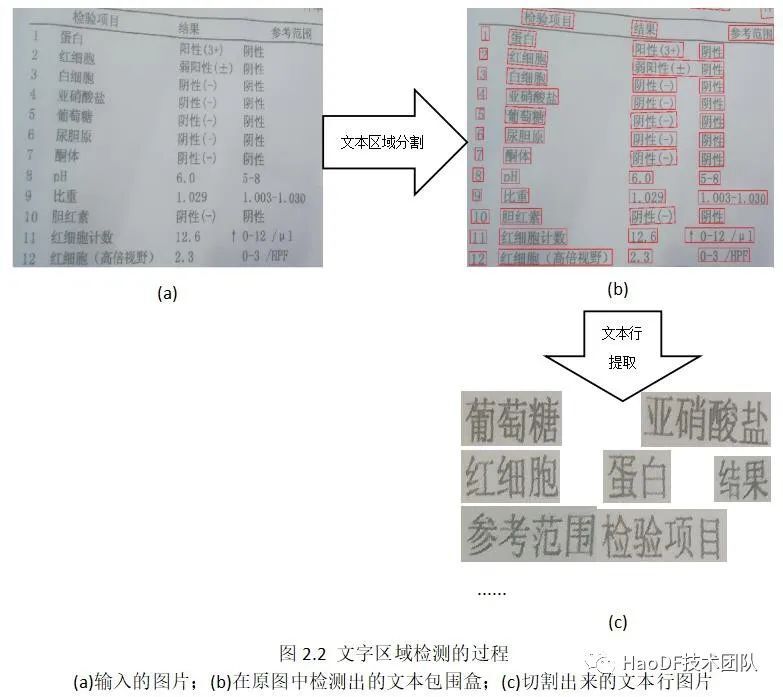
“文字区域检测”,是将图像中的每一行文本切割出来形成一条一条的文字切片,其具体过程如图 2.2 所示。目前流行的“文字区域检测”算法主要分为基于回归的方法和基于分割的方法:
第一版是基于一个开源项目修改而来,其采用的主体结构是 Yolo[1]文字区域检测+CRNN[2]文字识别。Yolo 文字区域检测算法属于基于回归的方法。第一版的 Yolo 文字区域检测算法在一般的医学报告单上面的效果是比较令人满意的,其文字检测效果不亚于市面上的一些付费 OCR 公共接口。
对于一般的文字区域检测算法,单独出现的’+’、’-’等符号通常是被视作噪声的。我们的 Yolo 文字区域检测算法也倾向于将这些符号视作噪声。这个先验知识在大部分医学报告单上是可行的。但仍然有占总数比例很小的一些类别的报告单(如尿常规、便常规等)上面会出现这些字符,而这些字符在这些类报告单上代表的却是非常关键的意义:如‘+’通常代表阳性,‘-’通常代表阴性(如图 2.3 所示)。为更好地处理这些类别的报告单,我们仍然需要一种效果更好、可以检测出这些不起眼的小字符的文字区域检测算法。

CVPR2019 的一篇论文所提出的 Craft 算法[3]进入了我们的视野。Craft 算法是一种基于分割的文字区域检测算法。在这里,我们先重点介绍 Craft 算法与 Yolo 算法在文字区域检测任务上的不同。
Yolo 文字区域检测使用固定宽度的小包围盒来覆盖检测到的文字区域以达到文字区域检测的目的。该算法先使用卷积神经网络提取图像高维特征,然后用回归的方法获取文字区域的候选小包围盒,最后使用非极大值抑制和循环神经网络来过滤这些小包围盒结果。由于使用了循环神经网络,因此该算法是将文字区域检测看作“序列处理”任务。这种方式对中长序列的文本区域检测非常有效。但报告单里单独出现的’+’、’-’等符号没有前后文字符,因此“序列处理”反而会降低算法对这些字符的检测。
Craft 算法则不将文字区域检测看作“序列处理”任务,而是将它看作图像分割任务。因此该算法对所有的文字序列的图像(无论长短)都一视同仁。Craft 算法会对图像中的所有像素进行二分类——文字区域像素和非文字区域像素。因此 Craft 算法更容易检测到单独出现的’+’、’-’等符号。
综上,我们选择了 Craft 算法替代原有的 yolo 算法。
然而算法被选定后,一个更大的问题出现了:没有标记好的数据。Craft 算法的训练数据需要人工框定每一个字符的包围盒。根据预测,标记一张报告单图像大概需要 25 分钟。标记出一个满意的数据集需要 1000 人/天以上的工作量,代价实在太大。
牛津大学的 Gupta 学者的一些工作[4]引起了我们的注意。Gupta 认为完全虚拟生成的文本图像即可训练出非常好的文本区域检测算法。参考 Gupta 论文[4]里面的方法,我们创造了自己的虚拟报告单生成算法(限于篇幅,我会在下一次分享详细介绍该算法),能自动生成出一张完整的报告单,几乎达到以假乱真的程度。图 2.4 是一张没有加背景的虚拟生成的报告单示例。在给报告单加上人工设置的背景(如桌面等)后,我们就可得到最终被训练的数据。

最终训练出的 Craft 算法在其他字符检测效果没有退步的前提下,大大提升了该模块算法检测单独出现的’+’/’-’等小字符的能力。新旧两种算法的对比结果如图 2.5 所示:

获取文字区域后,由于存在弯曲文本和倾斜文本,所以我们需要对这些文本行图片进行纠偏。参考算法[5]和算法[6],我们设计了一套文本纠偏算法用于该任务(限于篇幅,我会在后面的分享再详细叙述该算法的细节和实现)。该算法对倾斜和弯曲文本图像的纠偏效果如图 2.6、图 2.7、图 2.8 所示:



2.2 文字识别模块
“文字识别”的任务是将切下来的文本行切片转换为文字。本项目一直使用的是 CRNN 算法[2]进行文字识别处理。训练数据集为人为收集的报告单字段随机自动生成的图片。我们尝试过使用注意力机制的 DAN 算法[7],但公司机器扛不住它的负载。
在“好大夫在线医学报告单文本行数据集 v1.0”上,我们分别试验了我们的算法、百度 OCR 和腾讯 OCR 三种算法(如表 2.1 表 2.2 所示)。为公平起见,当百度云 OCR 接口和腾讯云 OCR 接口没有从图像中检测出正确的文字区域时,我们则跳过这些图片,不统计这些图片的错误。表 2.3 展示了百度云 OCR 接口和腾讯云 OCR 接口每一类的文字区域检测错误图片的占比:
2.3 报告单分类模块
“报告单分类”本质上是文本分类任务。
该模块最初的版本为我们和产品经理一起设计的关键字分类方法,其思想是提取文本检测结果中的关键字,根据关键字加权结果进行分类,我们将其称为“加权关键字分类算法”。“加权关键字分类算法”在一般情况下还是比较准确的。在项目初期,它为我们提供了较高质量的报告单分类图像数据。但这个版本的算法由于参数是人为设定的,因此噪声对算法的影响非常大。如“血常规”报告单在表头出现“肝功能”等分类权值非常大的字样就极易让算法误以为它是“生化、肝肾功”类报告单。因此我们仍然需要用一种效果更好,速度更快的算法去替代我们的“加权关键字分类算法”。
报告单分类模块我们调研了很多算法。舍弃了效果最好的 Bert 算法[8],主要是因为其运行速度较慢,占用内存资源太多。最终我们选择的算法是 FastText 算法[9]。
FastText 算法有几个优点:
1. 运行速度快,i7 十代的 CPU 下该算法处理一张图片的文本平均 15 毫秒;
2. 由于其只有 2 层全连接层,所以内存资源占用非常低;
3. 准确率较高,在 Thuctc 数据集[10]上的效果强于常用的 TextCNN[11]算法和 TextRNN[12]算法,弱于 Bert 算法[8]。相关实验结果详见网站[16]。
得益于之前设计“加权关键字分类算法”,我们可以获取较为可信的报告单图像分类数据集。人工过滤该数据集,并标记出 5000 多张图像后即可训练 FastText 算法。
在实际的实验中,我们将训练得到的 FastText 算法在随机选取的近 500 张报告单图像的文本检测结果上进行分类测试,准确率为 92.2%,而“加权关键字分类算法”的准确率为 75.2%。
2.4 命名实体识别模块
命名实体识别(NER)的任务是抽取句子中的某类特殊名词。我们项目的“命名实体识别”模块任务如图 2.9 所示,需要从报告单文本中提取诸如“检查项名”、“项数值”、“项范围”等字段。

命名实体识别(NER)是一个经典的 NLP 问题。学术界最早倾向于用线性链条件随机场(CRF)[13]去解决“命名实体识别”任务的。线性链条件随机场将自然语言中的每一个字当成线性链中的一个一个节点,相邻的字在线性链中为相邻的节点。线性链条件随机场假设线性链中的任意一个节点的状态只与其相邻节点的状态相关。但在实际情况下,自然语言中字与字间的联系通常会跨越数个字,甚至数句话。线性链条件随机场显然无法很好的处理这些长距离逻辑关系。
近些年,学术界开始研究用深度学习的办法去解决“命名实体识别”任务。长短记忆单元(LSTM)[14]开始被人用作处理“命名实体识别”任务。长短记忆单元(LSTM)理论上可以将字与字之间的联系扩展到无限远的地方,这进一步提高了其处理 NER 任务的效果。然而百度研究院的黄志恒博士发现长短记忆单元(LSTM)虽然加强了算法对中长距离字间联系的感知,但是却在超短距离的字间感知上不如线性链条件随机场。于是黄博士将线性链条件随机场架设在双向长短记忆单元(BiLSTM)后面,创造了效果更好的 BiLSTM-CRF 算法[15]。
2018 年,一个里程碑式的算法——Bert[8]算法诞生了,它在 11 项自然语言处理任务上都取得了令人瞩目的成果。无论在前面提到的“文本分类”任务上还是当前小节的“命名实体识别”任务上,Bert 算法都是毫无疑问的王者。
公司有一个医患交流的命名实体识别数据集,该数据库有近 100 万被标记的字符。在该数据库上,我们进行过三种算法的测试:1)Bilstm-crf;2)Bert-crf;2)Bert-Bilstm-crf。
根据以往学者的建议,我们选择的算法都含有条件随机场(CRF)进行超短距离标签修正。最终三种算法效果最好的是 Bert-crf 算法,于是该模块所用的算法最初为 Bert-crf 算法。
提取 OCR 识别的文字结果后,我标记了 200 多万的字符数据,涉及 24 种标签,如表 2.4 所示:

表中(B)代表首部标签,(I)代表非首部标签。其他标记没有首部与非首部之分。患者性别由于通常为一个字,故只有首部标签,没有非首部标签。
Bert 也是一种基于注意力机制的算法。基于注意力机制的算法有一个明显的缺陷,即有最大处理长度,Bert 算法的最大处理长度为 512 字。然而有很多报告单如血常规、超声检查等,字数均在千字以上。血常规等表格式报告单行间联系不大,尚可用行分割处理。超声检查等两段式报告单前后联系极大,不能简单的以行为标准进行分割处理。
为了解决这个问题,我们设计了 Bert-rb(全称 Bert-roll-back)算法。Bert-rb 算法是 Bert 算法的一个衍生,其利用报告单的固有特性,智能对报告单进行分割处理(限于篇幅,我会在下次分享详细介绍其原理及实现)。将 Bert-rb 算法后面架设一个 crf 算法即得到最终我们用到的 Bert-rb-crf 算法。
将 Bert-crf 算法替代为 Bert-rb-crf 算法后,这个模块即拥有了理论上一次性处理无限长报告单文本的能力。
在实验中,Bert-rb-crf 算法处理超长两段式报告单的效果基本与不分割处理的 Bert-crf 算法的效果一致,而不分割处理的 Bert-crf 算法却只能处理最多 512 字符长度的文本。这表明了 Bert-rb-crf 算法的先进性和有效性。
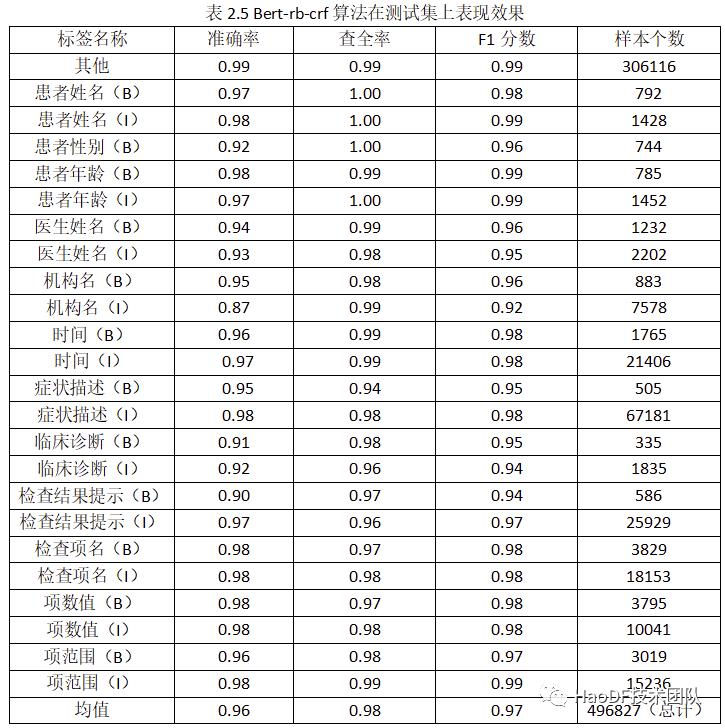
解决了算法问题,算法也就能在已经标记的 200 多万的字符数据上进行训练了,表 2.5 是 Bert-rb-crf 算法在标记的数据集的测试集上的表现。
2.5 结构化内容提取
获取报告单图像文本数据中的命名实体信息后,需要将这些信息组合成表格的形式。其思想非常简单,首先找“检查项名”,然后在“检查项名”的当前行和下一行寻找尚未被匹配到的“项数值”、“项范围”即可。
三、存在的问题
虽然该项目各个模块取得了喜人的成果。但不可否认该项目依旧存在一些问题。
比如文字区域检测模块的 Craft 算法缺乏“印章检测”功能,所以当报告单中文字上出现印章时会对“文字区域检测”的结果产生干扰。Craft 算法也喜欢将折线图误认为文字,令人欣慰的是,折线图上通常没有重要信息,错误识别对最终结果没有多大影响,还有就是某些纹理(如蓝色条纹毛衣等)依旧会对 Craft 算法造成干扰,幸运的是这些纹理上一般没有文字。文字识别模块的 CRNN 算法在报告单图像上的效果虽然超过市面上的某些云 OCR 接口,但是其依旧有不小的提升空间,这要求我们进一步利用现有的前沿技术,实现产品上的突破。
报告单分类的分类准确率仅有 92.2%,我们对这个结果不太满意,感觉应该能进一步提升至 95%以上,但这需要更多高质量数据集。
命名实体识别模块不能检测出“检查项单位”。最初没有标记这个命名实体,因为当时文字识别模块使用的还是通用文字识别模型,而“检查项单位”由于其包含很多希腊字母,所以没有经过特定训练的文字识别模型对这些字段的识别有许多错误,最终导致无法对这些错误的字段进行标记。但现在的文字识别模块对“检查项单位”的识别准确率已经大大提高,解决这个问题只需要投入更多时间即可。
参考文献:
1. Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
2. Shi B , Bai X , Yao C . An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 39(11):2298-2304.
3. Baek Y , Lee B , Han D , et al. Character Region Awareness for Text Detection[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020.
4. Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2315-2324.
5. Ma K , Shu Z , Bai X , et al. DocUNet: Document Image Unwarping via a Stacked U-Net[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
6. Li Zhang, Chew Lim Tan. Warped Image restoration with Applications to Digital Libraries.[J]. 2005.
7. Wang T , Zhu Y , Jin L , et al. Decoupled Attention Network for Text Recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7):12216-12224.
8. Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
9. Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. arXiv preprint arXiv:1607.01759, 2016.
10. Sun M, Li J, Guo Z, et al. Thuctc: an efficient chinese text classifier[J]. GitHub Repository, 2016.
11. Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
12. Liu P, Qiu X, Huang X. Recurrent neural network for text classification with multi-task learning[J]. arXiv preprint arXiv:1605.05101, 2016.
13. Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[J]. 2001.
14. Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
15. Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
16. https://github.com/649453932/Chinese-Text-Classification-Pytorch
作者简介:
张健琦:好大夫在线机器学习工程师,专注于 AI 图像处理与自然语言处理方面的工作。发表过关于图像处理方面的论文:WePBAS: A Weighted Pixel-Based Adaptive Segmenter for Change Detection。




