
关于本研究
许多人工智能研究项目的北极星一直在不断学习,通过简单的聆听和与他人互动来更好地识别和理解语言,就像婴儿学习他们的第一语言一样。这样做不但要分析别人所说的话,而且要从它们的表达上,比如说话者的身份、情绪、优柔寡断等,都有很多其他的线索。而且,要像人类一样全面理解一个场景,人工智能系统就必须能够区分和解释与语音信号重叠的噪声,如笑声、咳嗽声、咂嘴声、背景车辆或鸟鸣。
为了在音频中对这些类型的丰富词汇和非词汇信息建模打开大门,我们推出了 HuBERT,这是一种学习自监督语音表征的新方法。HuBERT 与 SOTA 方法在语音识别、语音生成、语音压缩的语音表征学习方面相匹配,甚至超过了 SOTA。
为了做到这一点,我们的模型采用了一种离线 k- 均值聚类方法,通过预测掩蔽的音频片段的正确聚类,学习了口语输入的结构。HuBERT 通过在聚类和预测步骤之间交替进行,逐步提高其学习的离散表征。
HuBERT 的简单性和稳定性将有助于自然语言处理和演讲研究人员,在其工作中更广泛地采用学到的离散表征。另外,HuBERT 的学习报告质量可以帮助轻松地部署到多种下游语音应用程序中。
工作原理
HuBERT 的灵感来自于 Facebook AI 的DeepCluster方法,它是一种自监督的视觉表征方法。谷歌的Bidirectional Encoder Representations from Transformers(BERT,即双向 Transformer 的 Encoder)方法等序列掩蔽预测损失的方法被用来表示语音的顺序结构。HuBERT 采用离线聚类的方法,为掩蔽语言模型的预训练产生噪声标签。具体地说,HuBERT 使用掩蔽的连续语音特征来预测预定的聚类分配。预测损失只应用于掩蔽区域,强迫模型学习未掩蔽的输入的良好的高层表征,以便正确地推断掩蔽目标。
HuBERT 可以从连续输入中学习声学和语言模型。首先,该模型需要将未掩蔽的音频输入编码为有意义的连续潜在表征,这就相当于经典的声学建模问题。其次,为了减少预测误差,该模型需要捕捉所学表征之间的长程时间关系(long-range temporal relations)。激励这项工作的一个关键见解是,从音频输入到离散目标的 k- 均值映射的一致性的重要性,而不仅仅是它们的正确性,这使得模型能够专注于对输入数据的顺序结构进行建模。举例来说,如果早期的聚类迭代不能区分 /k/ 和 /g/ 的声音,那么就会产生一种包含这两种声音的超聚类,预测损失将学习模型其他辅音和元音如何与这个超簇一起构成单词。因此,接下来的聚类迭代会使用新学习的表征来创建更好的聚类。实验表明,通过交替进行聚类和预测步骤,可使表征得到逐步改善。

HuBERT 在标准的 LibriSpeech 960 小时或 Libri-Light 60000 小时的预训练中,所有 10 分钟、1 小时、10 小时、100 小时和 960 小时的微调子集均达到或超过最先进的 wav2vec 2.0 性能。
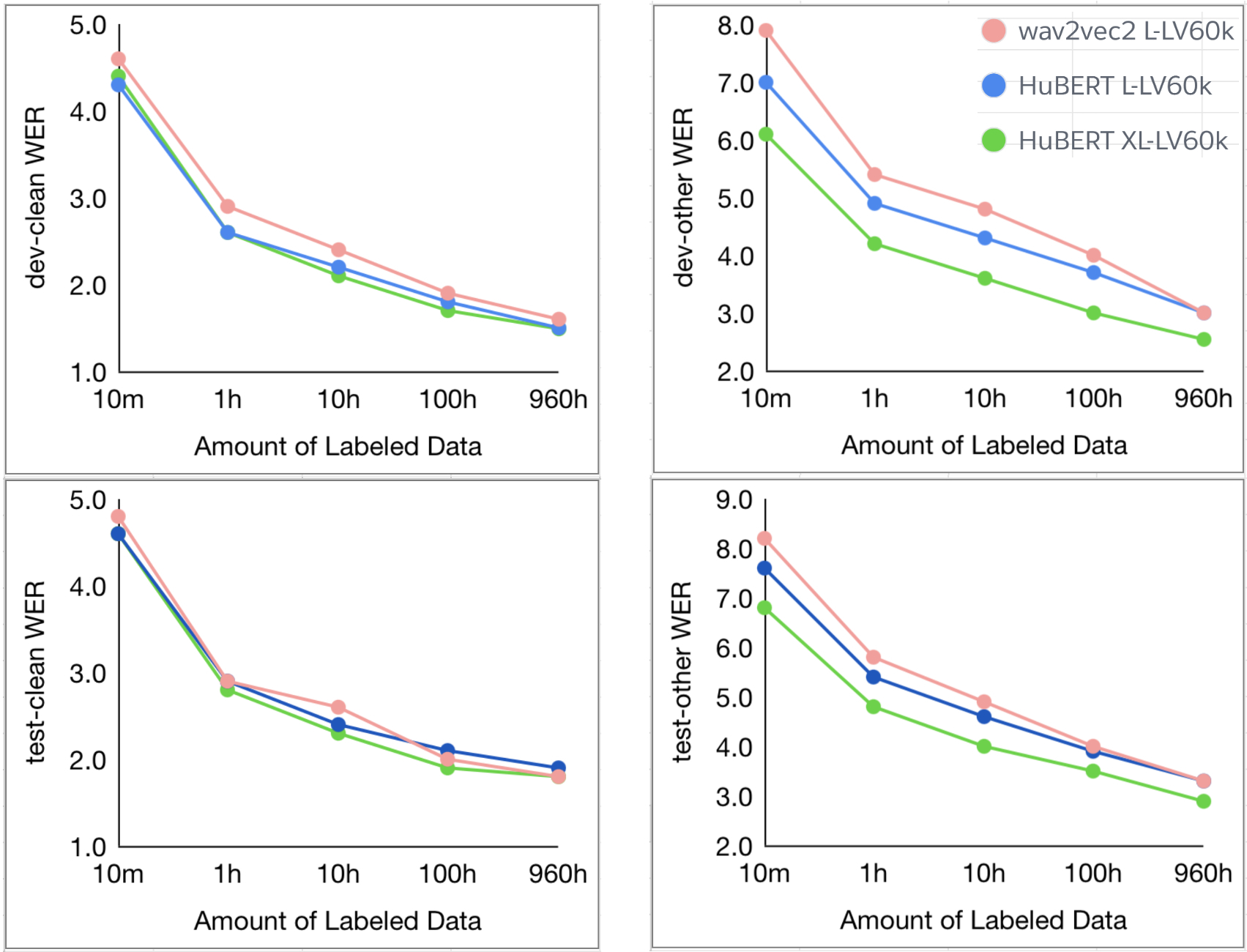
图中展示了 HuBERT 使用 LARGE(300M) 和 X-LARGE(1B) 两种规模的模型进行预训练的结果。X-LARGE 模型在预训练 60000 小时的 Libri-Light 数据时,显示了对 dev-other 和 test-other 评估子集的 19% 和 13% 的相对 WER 改进。
语音表征学习的显著成功实现了语音信号的直接语言建模,而无需依赖于任何词汇资源(无监督标签、文本语料库或词典)。这反过来又开启了非词汇信息建模的大门,例如戏剧性的停顿或紧急中断,以及背景噪声。
在生成式口语建模(Generative Spoken Language Modeling,GSLM)中,我们迈出了第一步,利用从 CPC、Wav2Vec2.0 和 HuBERT 中学到的语音表征来合成语音。单元语言模型通过训练离散的潜在表征,可以有条件、无条件地产生语音。在自动评估和人工评估中,HuBERT 生成的样本在质量上与基于字符的顶线监督的 LM 和生成相竞争。你可以在这里聆听由所有系统生成的有条件和无条件的样本:https://speechbot.github.io/。
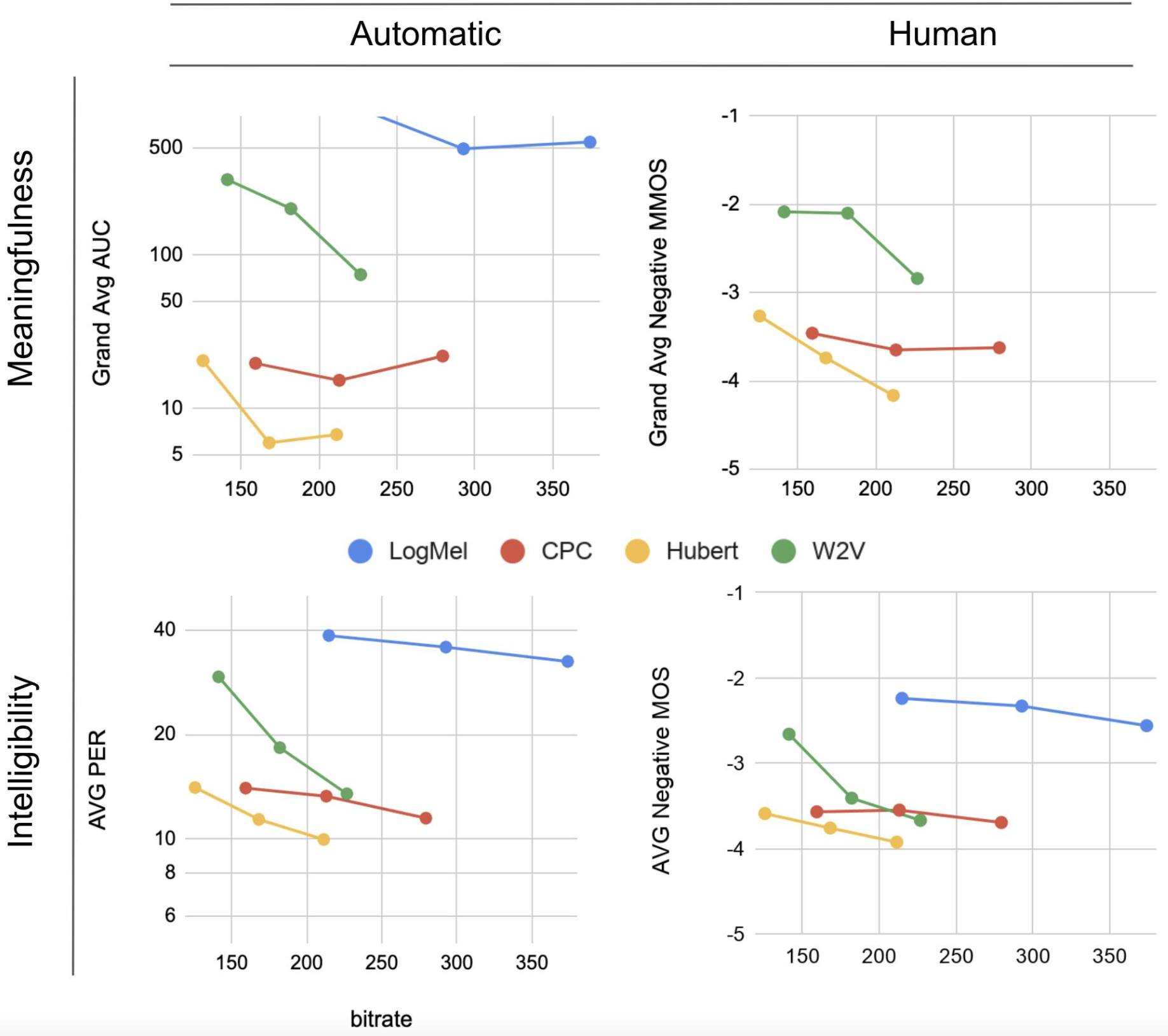
上面的图表展示了 HuBERT 的语言生成性能。
就语音压缩而言,我们最近的论文《来自离散解缠自监督表征的语音重合成》(Speech Resynthesis from Discrete Disentangled Self-Supervised Representations)是通过 HuBERT 实现 365bps 的比特率,而不是降低质量。你可以听一下 HuBERT 压缩音频的样本:https://resynthesis-ssl.github.io/。
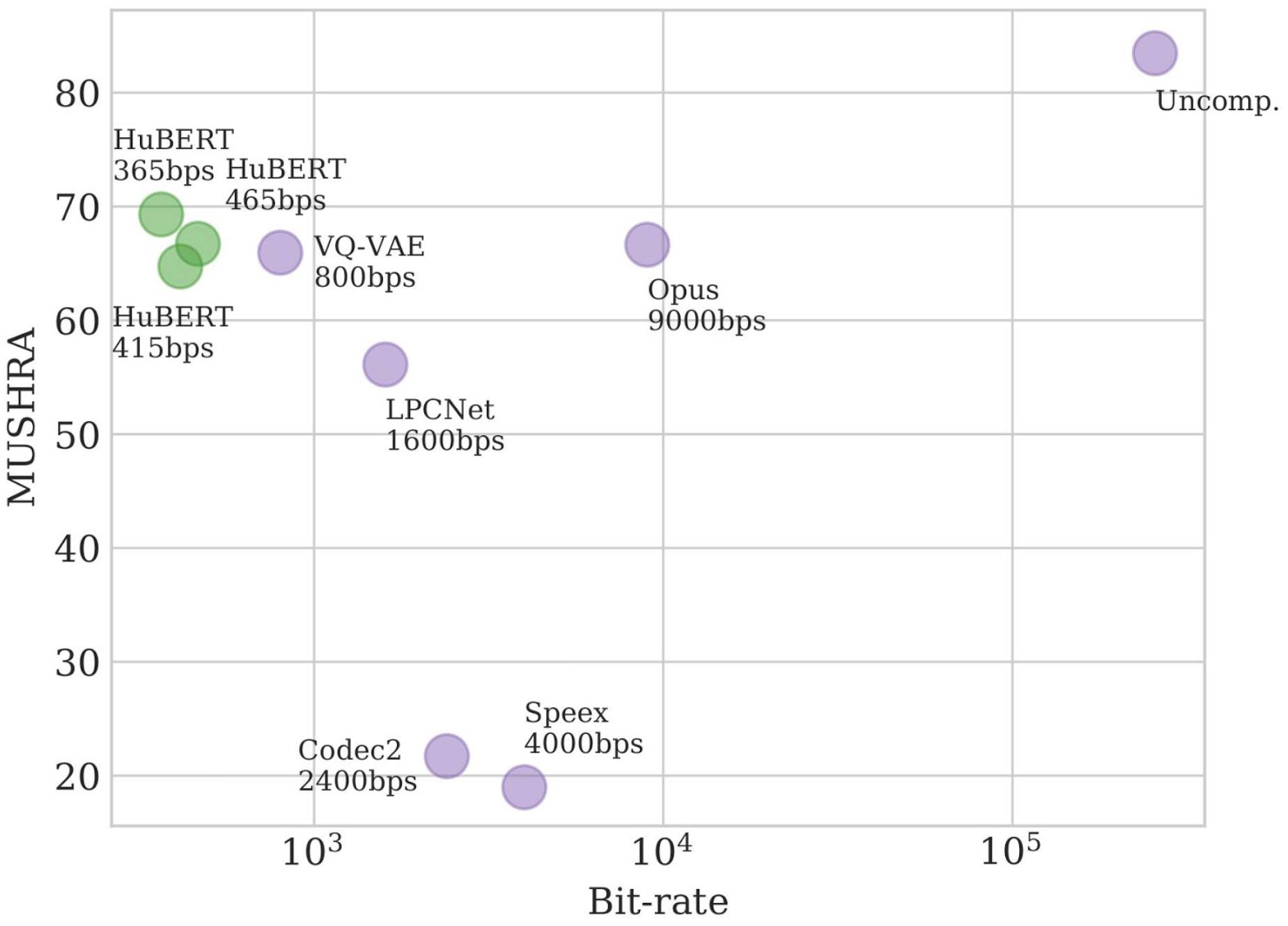
HuBERT 在多激励隐藏参考基准测试(Multi-Stimulus Test with Hidden Reference and Anchor,MUSHRA)中,仅次于未压缩的音频(256kbps)。
为什么重要
HuBERT 可以帮助人工智能研究界开发完全基于音频训练的自然语言处理系统,而非依靠文本样本。这样,我们就能以一种自发的口头语言充分表达出来,丰富现有的自然语言处理应用,从而使人工智能语音助理能说出与真人相同的细微差异和效果。学习语音表征而不依赖于大量的标记数据,对于工业应用和产品也是至关重要的,因为它们在新的语言和领域中的范围越来越广。这将有助于人工智能社区开发更加包容的应用程序,涵盖只用口语表达的方言和语言。
作者介绍:
Abdelrahman Mohamed、Wei-Ning Hsu,Facebook 研究科学家。Kushal Lakhotia,Facebook 软件工程师。
原文链接:




