James Turnbull,通过对日志管理项目情境中的 Logstash 实施细节的介绍,给了读者信服的理由去使用 Logstash 进行集中化的日志管理。 《Logstash》一书通过一个双面案例(two side case)从不同方面进行介绍,其低准入门槛适合小企业使用,其扩展能力使其也能满足大企业的需求。今年二月, James 在 Hangops 会议上谈到本书,“它主要面向那些以前没有见过 LogStash 的人,如系统管理员、开发人员、DevOps 以及运维人员。我希望此书读者对 Unix 或 Linux 有一定了解。”他继续说道,“另外,本书假定用户无任何关于 LogStash 的先验知识(Prior Knowledge)。”
日志管理简化过程中的问题
James 本人具有系统管理员和安全的相关背景。他先阐述了计算环境是如何使日志管理进化成为无法扩展的方式。
他介绍到,通常日志管理是是逐渐崩溃的——当日志对于人们最重要的时候,也就是出现问题的时候,这个渐进的过程就开始了。在这时,新管理员将通过一些传统工具对日志进行检查,如 cat、tail、sed、awk、perl 以及 grep。这种做法有助于培养在常用工具方面的优秀技能,但它的适用范围仅限于少量的主机和日志文件类型。考虑到现实中的可扩展性问题,团队也会逐步进化,使用如 rsyslog 和 syslog-ng 这样的工具进行集中化的日志管理。
James 介绍到,当用户通过这种方式着手处理扩展性问题时,其实并没有真正解决日志管理的问题——因为现在的日志事件仅仅考虑不同类型、不同格式以及不同时区,其数量就已经相当可观,并且基本上都缺乏合适的情境以方便理解它们。团队最后通过日志管理相关技术改造他们的计算环境,从而处理大量存储、搜索、过滤等等。不幸的是,最终,这种方式的问题凸显出来:不仅成本较高,而且造成了大量的浪费。和传统系统管理员使用的工具一样,LogStash 通过降低进入门槛,节省了大量时间,但其架构完全能够扩展以满足大型网络部署的要求。
LogStash 架构概述
LogStash 架构专为收集、分析和存储日志所设计。此外,LogStash 所实现的主要交叉用例之一是对所管理的日志事件进行查看 / 搜索。James 建议通过开源项目 Kibana 对事件进行搜索操作。本月早些时候,Jordan Sissel,LogStash 的创作者,在 Twitter 上发布了一条微博,内容为“LogStash 每日构建的最新版本中附带了 Kibana3 :java -jar logstash.jar kibana”,James 和 Jordan 都提到了 Kibana,因为它提供了用户友好的搜索界面,并与 Elasticstorage,即 LogStash 的搜索引擎进行了集成。以下是一些 Kibana 的截图,它们摘自于《LogStash》一书的第 3 章,各位读者还可以访问在线演示:

(点击图片放大)
除了查看日志外,它自身的组件架构支持通过代理对不同服务器的日志流进行管理,并最终传送至存储中。James 带领读者们,以 LogStash 开箱即用的配置为基础,对默认配置中的各个组件进行探索。LogStash 默认配置中使用的 Redis 是一个开源 Key/Value 数据库,用于在索引前队列化日志。它同时还使用 Elasticsearch 存储日志,并作为查看系统的后端。下图摘自第 3 章,展示了架构中各种组件类型,包括 Shipper、Broker、Indexer 以及 Viewer。
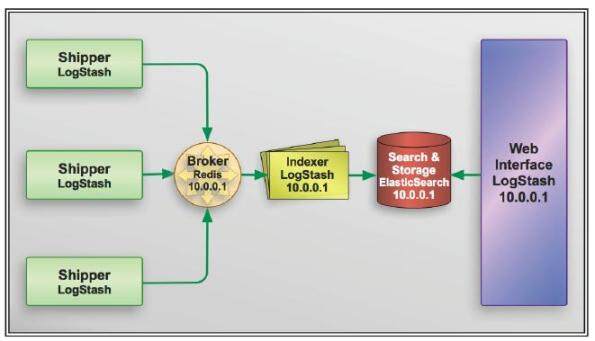
在这本书中,James 深入介绍了 LogStash 实例中的三个主要功能:事件输入、事件数据过滤以及事件输出。LogStash 的这三个功能是根据配置信息执行的,这些信息存储在简单易懂的“.conf”文件中。 “.conf”文件中有不同的配置节对应 LogStash 所使用的三种不同类型的插件 输入(input)、过滤器(filter)以及输出(output)。每个 LogStash 实例都是根据它在整体架构中的角色需求进行定制的。 比如下面是摘自本书第 3 章的某个 Shipper 的配置(包括一个输入和两个输出):
input {
redis {
host => "10.0.0.1"
type => "redis-input"
data_type => "list"
key => "logstash"
}
}
output {
stdout {
debug => true
}
elasticsearch {
cluster => "logstash"
}
}
开源的 LogStash 符合 DevOps 文化
LogStash 是个可自由使用的开源工具,适合在开源工具的生态系统中工作,它很有意义,因此 James 专门为它编写了一本书,因为他是一个自称“开源极客”。LogStash 生态系统中,在命令行下,所有的工具都是可安装的(Installable)、可配置以及可管理的管理的,是理想的自动化方案。在整本书中,Jame 明确地指出,在理想状况下,应当通过一套自动化配置管理系统来管理 LogStash 各个组件的安装、配置。然而,自动化配置的主题超出了本书的范围,所以作者退而求其次,通过对 LogStash 组件的介绍使大家理解如何对其进行安装和配置。如果配合对自动化的理解,读者就能够无缝构建出多种环境。通过这种方式,能够够灵活的适应项目不同阶段中各类环境的部署,如 Q&A、故障排除等,并支持持续交付。
安装 Java、LogStash、Redis 以及 Elasticsearch 等
James 逐步展示了安装 LogStash 的过程是多么的简单,它所依赖的组件也一样。同样,Jordan Sissel 提出了 LogStash 项目原则中的一条:“社区:如果新手的日子不好过,那么这就是个 Bug。”LogStash 依赖于 Java,所以要运行 LogStash,至少要安装 OpenJDK。大部分 Linux 发行版中都包含了 OpenJDK 可以通过包管理系统启用。比如在 Red Hat/CentOS 中,使用命令“sudo yum install java-1.7.0-openjdk”进行安装,而在 Debian/Ubuntu 中,命令则是“sudo apt-get install openjdk-7-jdk”。Jordan Sissel 以单一的 Jar 文件方式分发 LogStash,可以从 LogStash.net 主页上获取。在 OpenJDK 环境下,只需要在命令行上指定 Jar 文件地址以及配置文件地址就可以运行 LogStash 了。Redis 的安装就更加容易了,使用包管理系统安装,和 OpenJDK 安装类似,在 Debian/Ubuntu 系统中,使用命令“sudo apt-get install redis-server”,而在 Red Hat/CentOS 中则是“sudo yum install redis”。在 Redis 开始进行事件处理前,需要对“/etc/redis/redis.conf”中的一些配置设置进行修改,然后以服务的形式启动 Redis。Elasticsearch 和 LogStash 类似,只需要预先安装 Java。如需下载Elasticsearch ,对于Debian/Ubuntu 等Linux 系统,可以下载“.deb”安装包,而对于Red Hat/Centos 等的Linux 系统则是“.rpm”安装包。它也要对“/etc/elasticsearch/elasticsearch.yml”进行少量的配置后才能启动。
LogStash 组件:Shipper、Broker、Indexer
本书涵盖了 LogStash 的三种插件类型,并介绍了它们在 Shipper 和 Indexer 中的使用方法。James 展示了下述输入插件在 LogStash 的使用方法:文件、标准输入(stdin)、Syslog、Lumberjack 以及 Redis。对于那些无法安装 LogStash 的环境,也可以通过其他它选件发送事件,从而与 LogStash 集成,如 Syslog、Lumberjack、Beaver 以及 Woodchuck。在 LogStash 的输入输出插件之间,可能会存在交集,比如对于 Redis,就同时具有输入和输出两个插件。除了介绍两个主要的输出 Redis 和和 Elasticsearch 外,James 还介绍了通过集成其他系统进行输出,包括 Nagios、邮件告警、即时消息以及 StatsD/Graphite。这本书中介绍了 grok、date、grep 以及 multiline 等过滤器。James 向读者展示了使用通过过滤插件,实现对 Postfix 日志及 Java 应用程序日志的高效处理。在某些情况下,日志可以在输入到 LogStash 前进行过滤,比如 Apache 日志管理能够自定义日志格式,可以以 JSON 格式的进行记录,这样 LogStash 就可以在不使用内部过滤器插件的情况下,方便的进行处理。Redis,就是我们所指定的 Broker,用于进行事件流管理,在该角色中,LogStash 还支持其他的队列技术:AMPQ 和 ZeroMQ。搜索 / 存储的路由工作由 LogStash 的 Indexer 实例负责执行。
LogStash 的扩展
扩展 LogStash 要实现三个主要目标:弹性、性能和完整性。下图是摘自于本书第 7 章,它所描述的是对 Redis、LogStash 以及 Elasticsearch 的扩展:
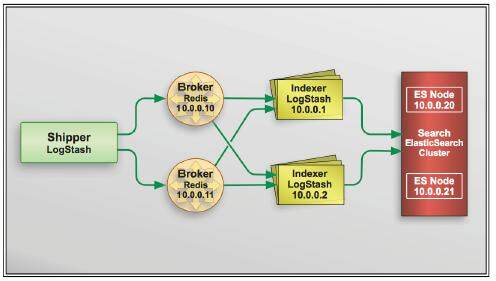
LogStash 不依赖 Redis 进行自身的故障转移管理,而是与此相反,LogStash 将根据预先配置的两个 Redis 实例,将事件发送到其中一个 Redis 实例中。如果该 Redis 实例变为不可用,LogStash 就会开始将事件发送到已配置的另一个 Redis 实例中。作为 Indexer,LogStash 可以轻松的实现扩展:通过创建多个实例,并不断地从所有可用的 Broker 拉取数据,并输出到 Elasticsearch。在这种设计中,事件只能传输到一个 Broker,所以从 LogStash 的 Indexer 传输事件到 Elasticsearch 的过程中,应当是没有重复事件的 。当用户安装多个实例并配置信息中设置有公用的配置时,Elasticsearch 能够方便的自行建立群集。它采用组播、单播技术或使用 EC2 插件,根据各个独立实例的配置设置自行建立群集。只要在网络允许的情况下,实例间将会自行通讯,将会自行建立群集,随后开始在群集节点之间分割数据。数据分区将会自动提供弹性和性能。
InfoQ同时就 LogStash 对 James Turnbull 进行了采访。
InfoQ:在 LogStash 集中化日志管理系统的成功的商业案例中,您认为效益和成本应该是什么样的情况?
James:LogStash 的好处和众多开源系统管理工具一样:较低的软件成本、开源、今后可扩展、快速的开发和 Bug 修复、拥有极好的社区开发解决方案、互相帮助以及帮助用户形成解决自身问题的发展蓝图。所需成本也和大多数开源工具差不多:没有商业支持、并非功能齐全的商业替代品、可能有较高的进入门槛,在实施时,同时要求用户有一定的技能并且官方提供了可用的文档(尽管现在用户有了一本很棒的书!)。
InfoQ 的:以 DevOps 为导向的技术团队为什么要选择开源工具 LogStash 系统,而不是选择像 Splunk 这样的商业工具?
James:对于 DevOps 团队而言,这种选择的主要驱动力是成本。 虽然 LogStash(及其控制面板 Kibana)的(还)不是 Splunk 的对手,但它们都是免费的,并能够迅速的获得功能和特性。但是使用 Splunk 需要支付一定的费用,很多规模较小的企业不一定能负担得起。当然,需要注意的是,虽然这个软件是免费的,但仍然会有实施成本,而与商业工具相比,很难说成本有多少。
InfoQ:在日志管理方面,有什么最简单易懂而且有用的用例吗? 如果对于企业中的不同角色有所不同,能请您介绍一些具体有哪些不同吗?
James:日志管理的最好用例是故障排除和监控。当用户的基础设施出现问题时,应用程序的日志数据往往是最好的信息来源。日志同时也是极好的数据源,可以用于监控基础设施的状态和时间,还可以用于构建指标以展示应用程序的运行状态。 这就是说,在企业中的不同团队关心的是日志管理用例的不同方面。比如,运营团队专注于故障排除以及能够提供性能数据日志。应用程序开发人员则很有兴趣使用日志输出来发现并修复错误。安全团队专注定位日志数据中突出显示的漏洞和安全事件。
关于书籍作者:
 James Turnbull是 6 本有关开源软件的技术书籍作者,并且是开源社区的长期成员。 James 编写了第一本(以及第二本)关于 Puppet 的书籍,并为 Puppet Labs 运营运维和专业服务。 James 经常在 OSCON、Linux.conf.au、FOSDEM、OpenSourceBridge、DevOpsDays 和其他一些会议上发表演讲。 他是 Linux Australia 前任总裁,曾是 Linux Victoria 前委员会成员,负责 2008 年的 Linux.conf.au 大会,并担任 Linux.conf.au 和 OSCON.Y 的委员会职位。
James Turnbull是 6 本有关开源软件的技术书籍作者,并且是开源社区的长期成员。 James 编写了第一本(以及第二本)关于 Puppet 的书籍,并为 Puppet Labs 运营运维和专业服务。 James 经常在 OSCON、Linux.conf.au、FOSDEM、OpenSourceBridge、DevOpsDays 和其他一些会议上发表演讲。 他是 Linux Australia 前任总裁,曾是 Linux Victoria 前委员会成员,负责 2008 年的 Linux.conf.au 大会,并担任 Linux.conf.au 和 OSCON.Y 的委员会职位。
查看英文原文: Interview and Book Review: The LogStash Book, Log Management Made Easy




