

导读: 召回几乎是所有推荐系统的基础模块,对应到电商的推荐中,它的作用是从海量的商品池中,筛选出一部分用户可能感兴趣的商品作为上层排序系统的候选集。因此,可以说召回效果的好坏直接决定了推荐效果的上界。
常见的有基于 user profile 的召回,基于协同过滤的召回,还有最近比较流程的基于 embedding 向量相似度的 topN 召回等等。方法大家都知道,但具体问题具体分析,对应到旅行场景中这些方法都面临着种种挑战。例如:旅行用户需求周期长,行为稀疏导致训练不足;行为兴趣点发散导致效果相关性较差;冷启动用户多导致整体召回不足,并且热门现象严重;同时,具备旅行特色的召回如何满足,例如:针对有明确行程的用户如何精准召回,差旅用户的周期性复购需求如何识别并召回等。
本次分享将介绍在飞猪旅行场景下,是如何针对这些问题进行优化并提升效果的。主要内容包括:⻜猪旅行场景召回问题、冷启动用户的召回、行程的表达与召回、基于用户行为的召回、周期性复购的召回。
01 飞猪旅行场景召回问题
1. 推荐系统流程
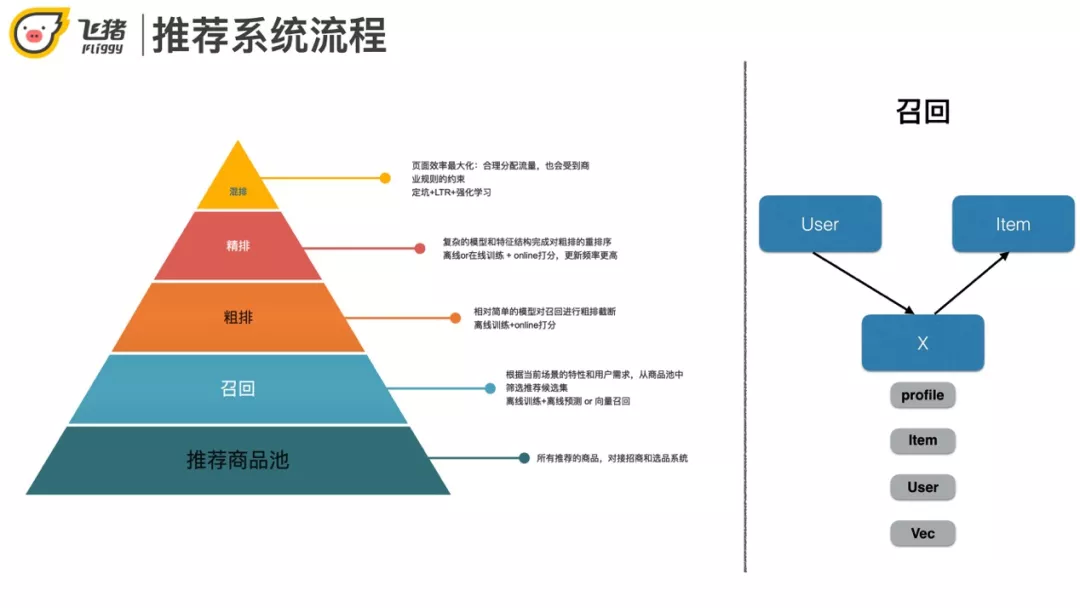
首先介绍推荐的整体流程。整体上分为 5 个阶段。从全量的商品池开始,之后依此是召回阶段,粗排/精排阶段,最后的混排模块根据业务实际情况而定,并不是大多数推荐系统必须的。粗排和精排在另外一次分享中已经介绍过了,本次分享主要介绍一下飞猪推荐系统的召回问题,召回可以说决定了推荐系统效果的上限。
下面说一下召回和粗排/精排的区别。从召回到粗排再到精排模块,商品的数据量是递减的,模型的复杂度会增高。具体会体现在输入特征数量和模型复杂度的增加,更新往往也会更频繁。对应的训练和上线的方式也会不同,拿召回来讲,出于性能的考虑,往往采用离线训练+打分或者离线训练得到向量表达+向量检索的方式,而排序阶段为了更好的准确率和线上指标,更多的是离线训练+实时打分,甚至在线学习的方式。
召回的本质其实就是将用户和商品从不同维度关联起来。常见的方法比如 content-base 匹配,或者 item/user based 的协同过滤,还有最近比较流行的向量化召回。向量化召回常用做法是用深度学习将用户和商品都表达成向量,然后基于内积或欧式距离通过向量检索的方式找到和用户最匹配的商品。
2. 飞猪推荐场景
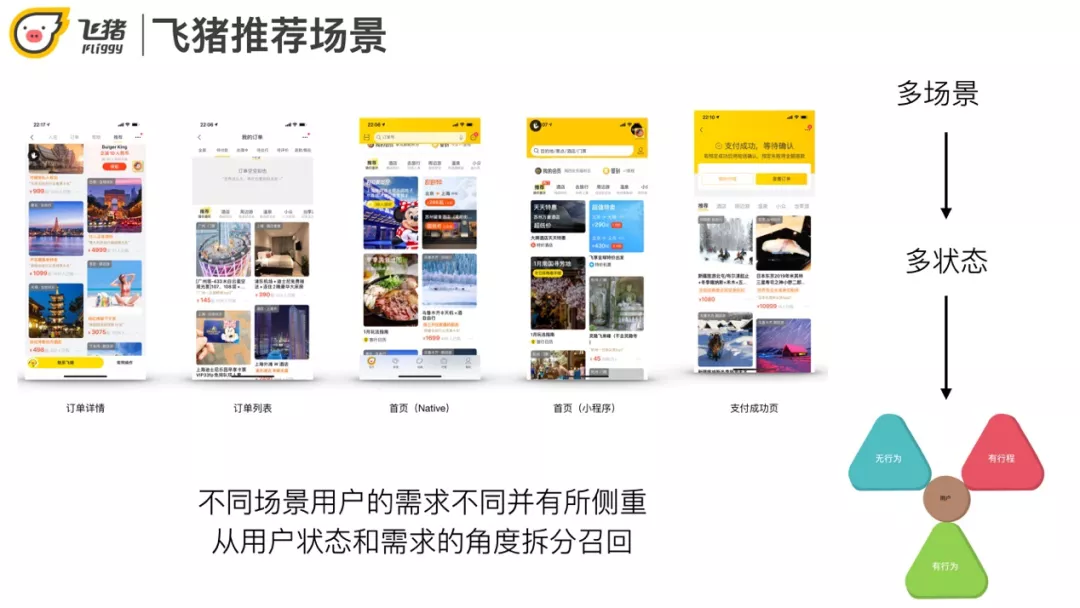
飞猪的推荐页面有很多,比如首页,支付成功页,订单列表页,订单详情页都有猜你喜欢。不同页面对应了不同的场景,用户在不同场景下需求不同,也有一定的交叉。比如首页偏重逛/种草,但支付完成后推荐一些与订单相关的商品会更好。
我们大致可以把用户分为三类:无行为、有行为,还有一种是飞猪场景下特殊的一类"有行程"。
3. 主要问题
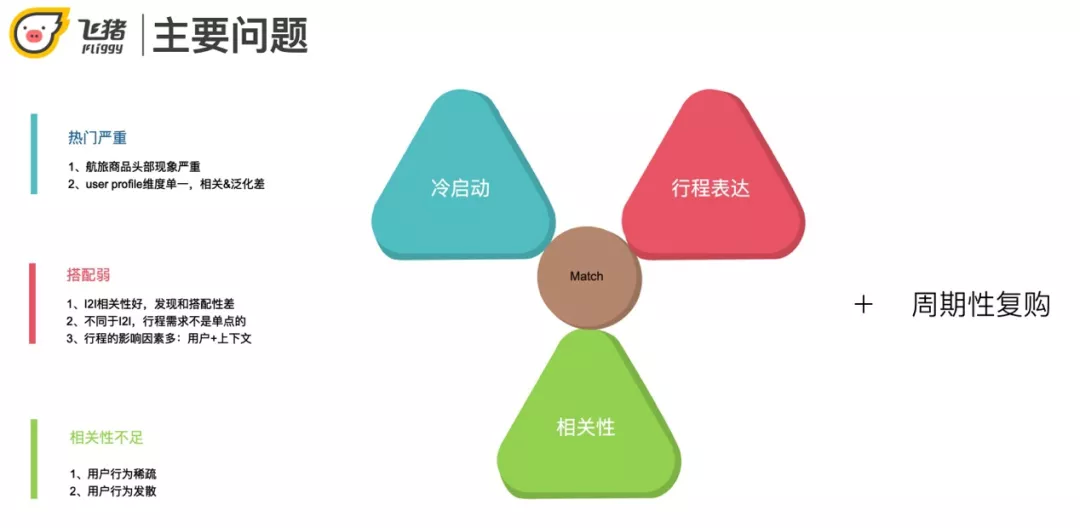
本次分享的主要内容就是针对这三类用户在推荐过程中存在的问题+周期性复购场景 ( 出差/回家 ) 的解决。
航旅场景下的召回存在以下问题:
冷启动:航旅商品的热门现象严重,user profile 缺乏。
相关性 vs 搭配性:航旅场景下要求搭配性比较高,传统的 I2I 只偏重相关性。但用户的行程需求不是单点的,比如买了飞机票还要看住宿。行程受上下文影响比较多,比如季节、用户近期行为等。
相关性不足:航旅用户的行为稀疏又发散,目前的召回结果噪音较多。
下面会对我们在优化过程中碰到的相关问题一一介绍。我们知道,召回处于推荐链路的底端,对召回常规的离线评估方式有预测用户未来点击的 TopN 准确率或者用户未来点击的商品在召回队列中平均位置等等。但是在工业系统中,为了召回的多样性和准确率,都是存在多路召回的,离线指标的提高并不代表线上效果的提升,一种常见的评估某路召回效果的方式就是对比同类召回通道的线上点击率,这种评估更能真实反映线上的召回效果,基于篇幅的考虑,后面的介绍主要展示了线上召回通道点击率的提升效果。
02 冷启动用户召回
1. User 冷启动召回
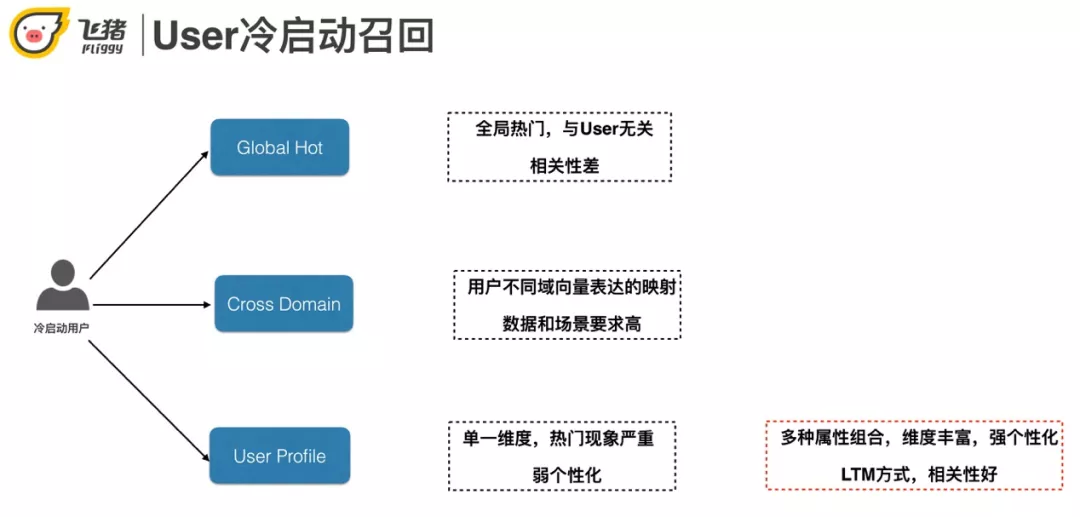
用户冷启动召回主要有以下几种方案:Global Hot、Cross Domain、基于用户属性的召回。
全局热门:缺点是和 user 无关,相关性差。
Cross domain:一种做法是基于不同域 ( 例如飞猪和淘宝 ) 共同用户的行为将不同域的用户映射到同一个向量空间,然后借助其他域的丰富行为提升本域冷启动用户的召回效果。
基于用户属性:单一属性的缺点是热门现象严重,个性化不足。我们采用了基于多属性组合的方法。
2. UserAttr2I
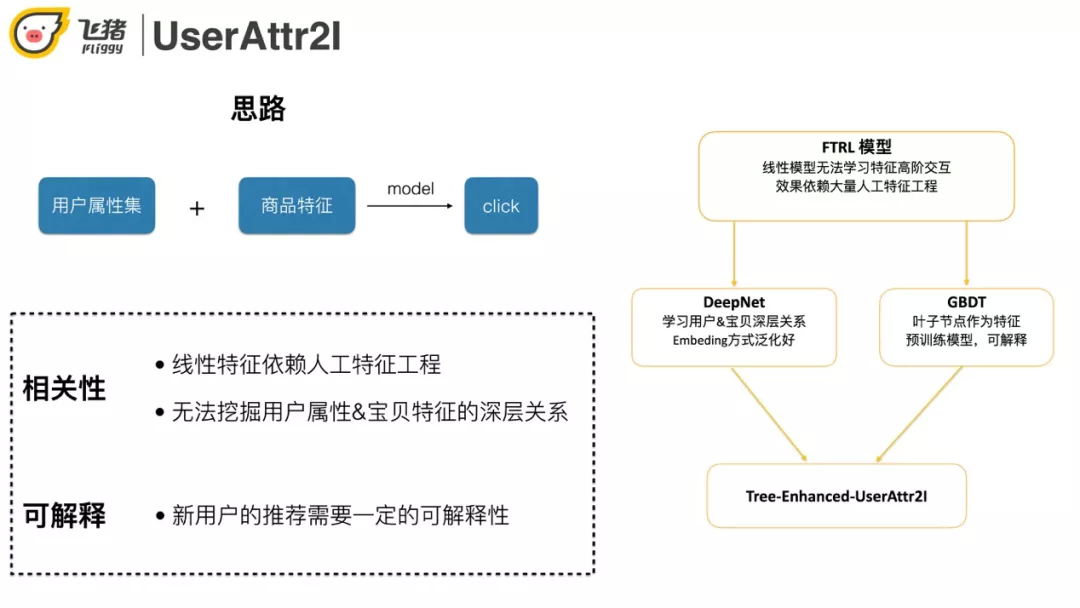
在这里介绍我们的方案 UserAttr2I,使用类似排序模型的方法,输入用户+商品的属性,预测用户是否会点击一个商品。
开始用线性 FTRL 模型,效果不是很好。原因是线性模型无法学习高阶特征,并且解释性比较差。针对这两个问题,通过 DeepNet 提高泛化性,同时用 GBDT 来做特征筛选。

下面对比双塔结构和深度特征交叉两种方案,优缺点如图所示。最终选择了第二种,原因是目标用户是冷启动,能用到的特征比较少。如果放弃挖掘用户和宝贝之间的关系会导致相关性比较差。模型结构如下:
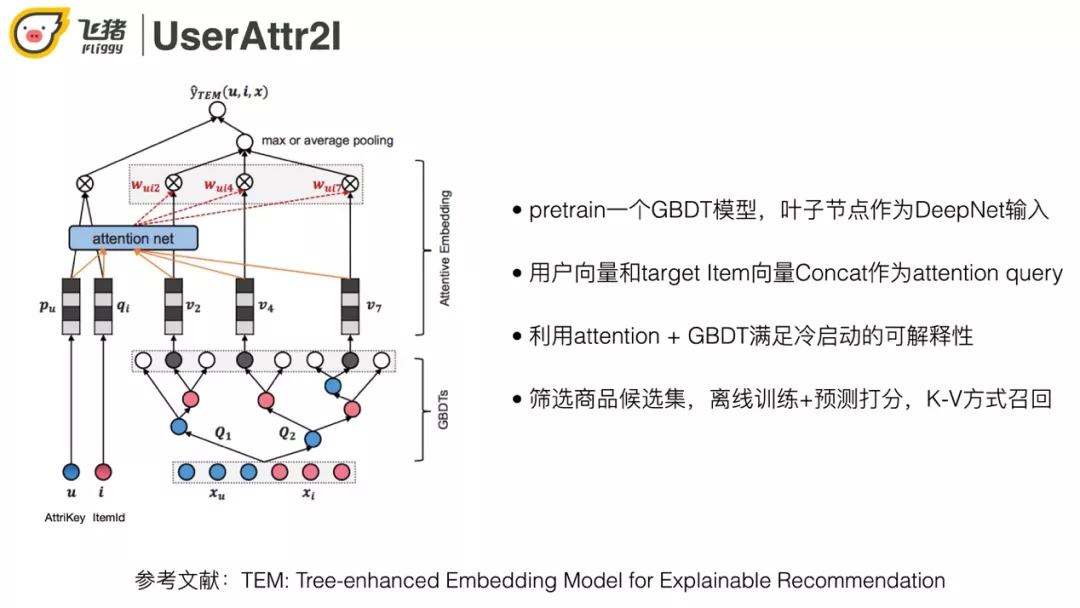
通过 attention 操作以及 GBDT 的叶子节点即可满足冷启动的可解释性。
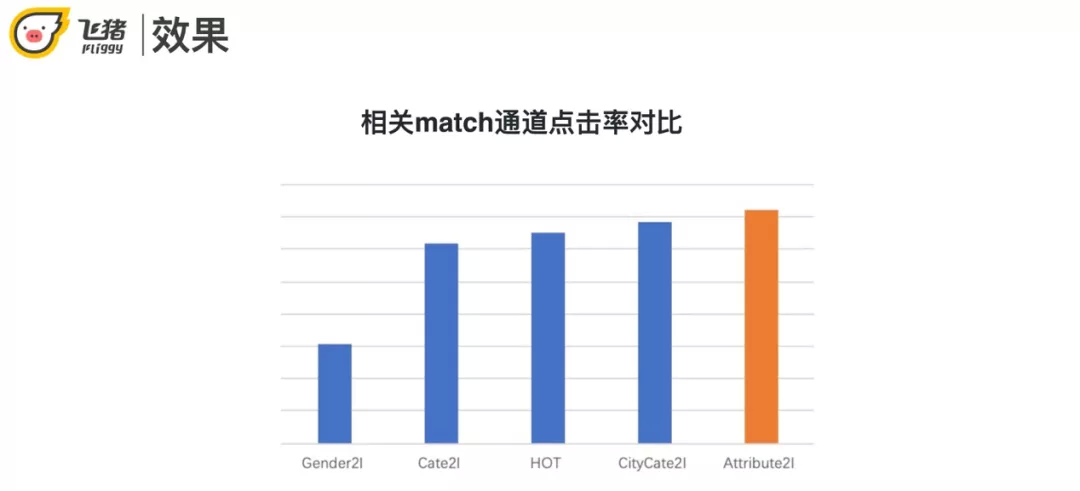
对比其他冷启动的召回方式,Attribute2I 的点击率最高。
03 行程的表达与召回
1. Order2I
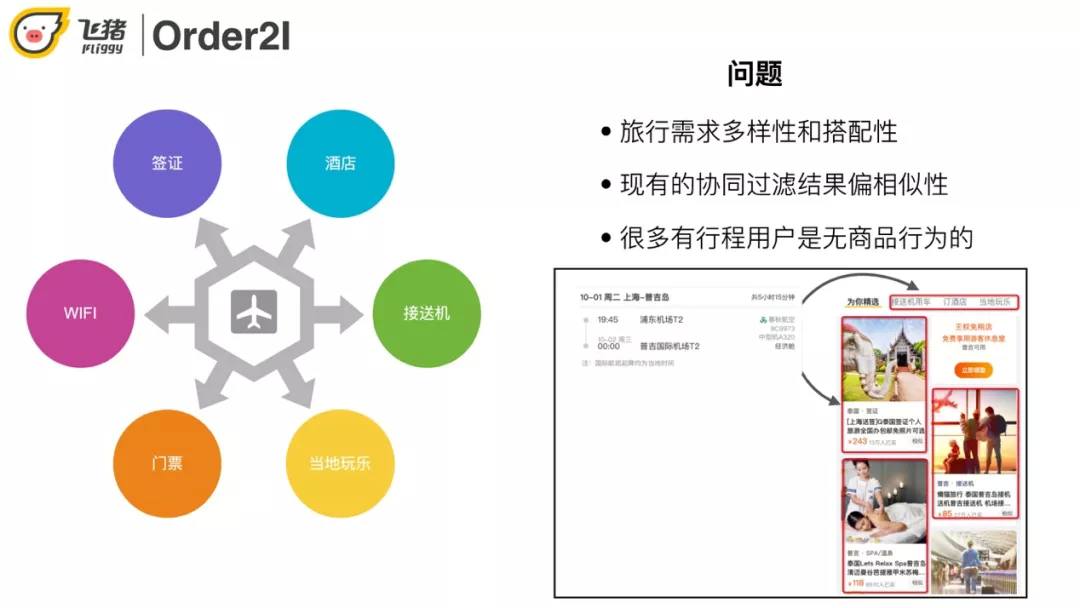
在飞猪场景下用户有类似如下的需求:买了去某地的机票,用户很可能需要与之搭配的签证/wifi/酒店等等,而协同过滤通常只能推出同类型商品,比如门票推门票,酒店推酒店。另外飞猪不像淘宝用户可能会经常逛,有比较丰富的历史行为信息可以供我们去分析和计算,飞猪用户通常是"买完即走"。

通过数据分析我们发现订单附近的行为数据和订单有较高搭配关系,我们通过 Graph Embedding 的方式学习订单和宝贝的 Embed,以此来学习搭配关系。
难点有以下几个:
如何挖掘反映搭配关系的数据集合
搭配的限制性比较强,如果仅仅基于用户行为构建图,由于用户行为噪音多,会造成较多 badcase
如果完全基于随机游走学习 Embed,最后的召回结果相关性差,因此需要行业知识的约束
数据稀疏,覆盖商品少,冷启动效果差
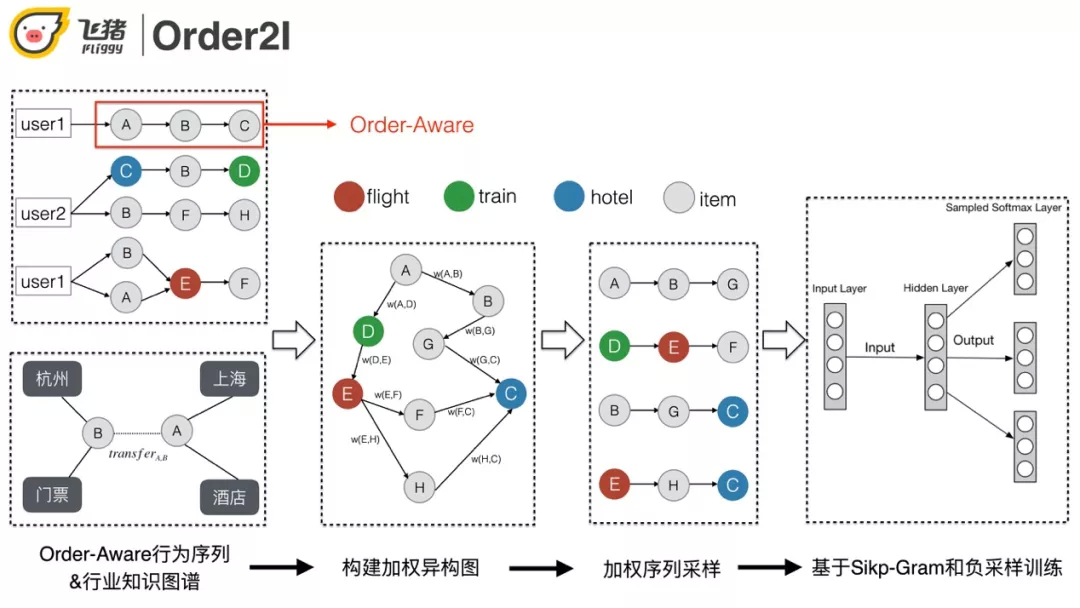
解决方案:
利用航旅知识图谱以及用户的行为序列进行加权异构图的构建 ( 机票/火车票节点利用业务线+出发地+目的地唯一标示、宝贝 &酒店利用其 id 唯一标示 )。之后的流程和传统的 Graph Embedding 类似。
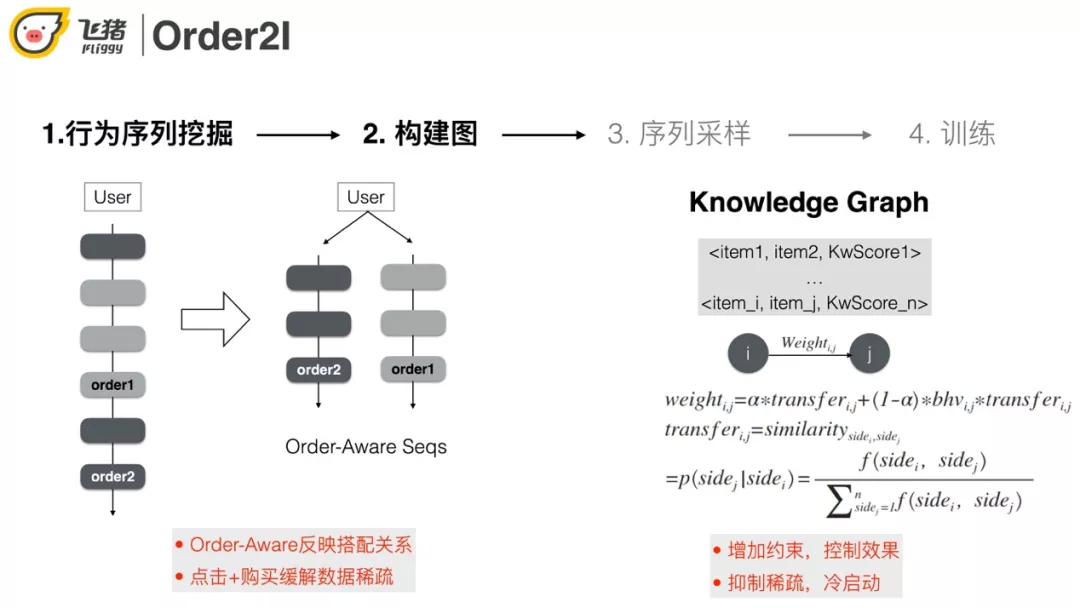
具体过程:
① 以订单粒度对用户的行为做拆分和聚合,同时加入点击行为缓解稀疏问题。
② 边的权重的计算同时考虑知识图谱和用户行为,这种做法一方面可以增加约束控制效果,另一方面也可以抑制稀疏,解决冷启动的问题。
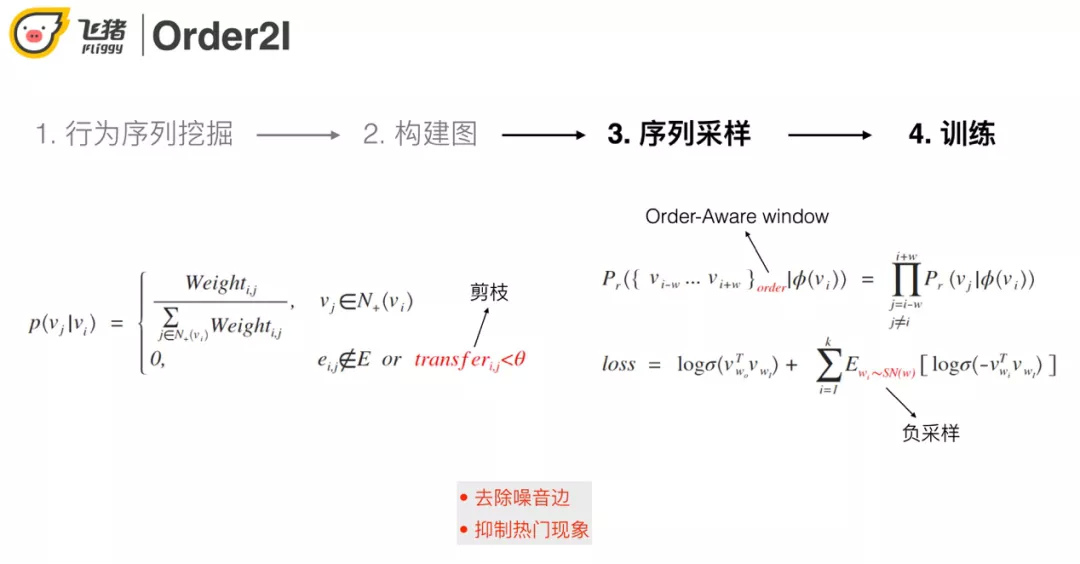
③ 序列采样过程中会基于转移概率进行剪枝操作,用来抑制噪声和缓解热门问题。
④ skip-gram+负采样训练。
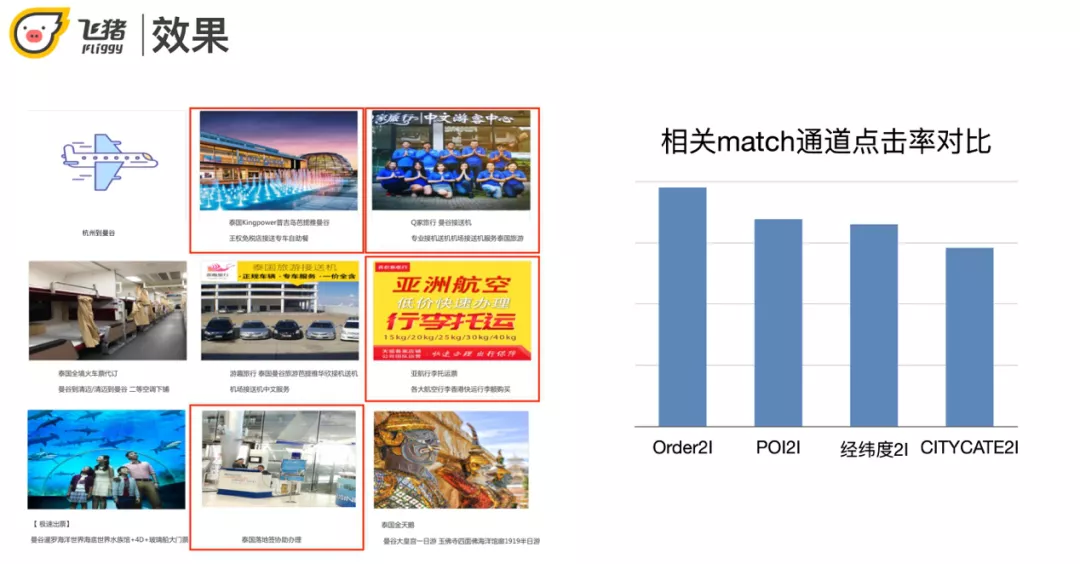
这里有一个具体的 case,用户订了一张去曼谷的机票,order2I 召回了曼谷的一些自助餐,落地签,热门景点等,体现了较好的搭配性。整体的指标上 order2I 的点击率也明显高于其他方式。
2. journey2I
Order2I 将订单进行向量化表达,从而进行召回。但是它还有一些问题:用户的某次行程可能由多个订单组成,甚至有的订单只是中转的作用,Graph Embedding 还是基于单个订单进行搭配的推荐;用户的某次行程不是一个出发地+目的地就能描述的,它不仅与行程本身属性 ( 例如出发/到达时间,目的地,行程意图等 ) 相关,还与用户的属性和偏好 ( 例如年龄,是否是亲子用户 ) 相关。因此行程既是 User-Aware 又是 Context-Aware 的。而 Order2I 学习的还是一种全局的整体偏好,与用户无关,不够个性化。因此我们尝试在行程的粒度做召回,综合考虑用户属性、行程意图、上下文等因素,更个性化的召回与用户这次行程以及用户自身强相关的的宝贝。

以行程为粒度,对多个订单做聚合,并且增加行程相关的特征。融入用户的基础属性特征和历史行为序列。丰富行程特征并引入 attention 机制。采用双塔模型离线存储商品向量,在线做向量化召回。模型结构如下:
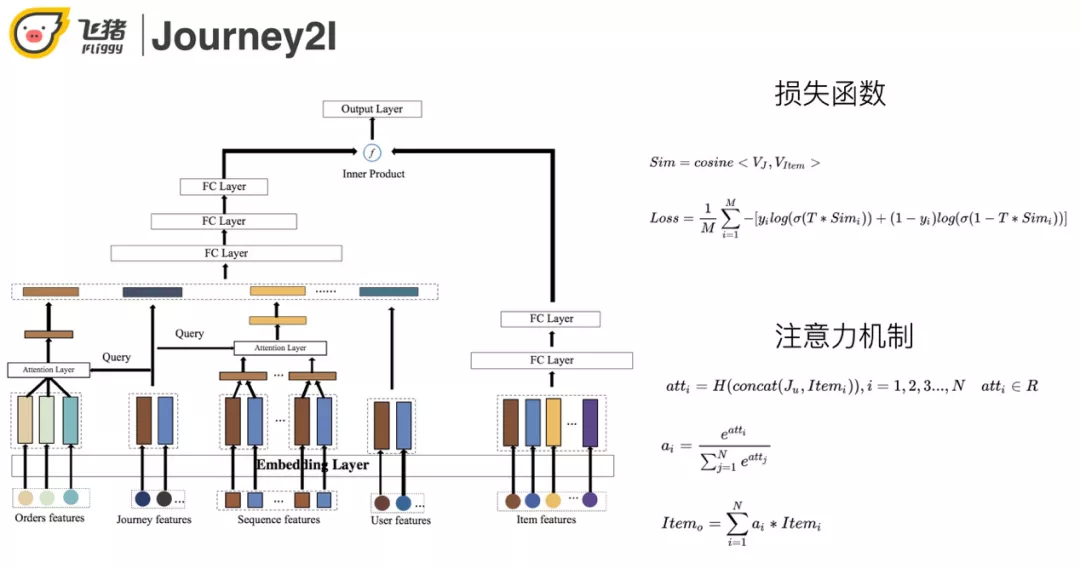
模型左边主要是利用行程特征对订单序列以及用户的历史行为序列进行 attention 操作,用于识别关键订单以及用户关键行为。在此基础上融合行程特征和用户属性特征学习用户该段行程的 Embed。模型右边是商品特征,经过多层 MLP 之后学习到的宝贝 Embed。两边做内积运算,利用交叉熵损失进行优化,这样保证召回的结果不仅与行程相关还与用户行为相关。
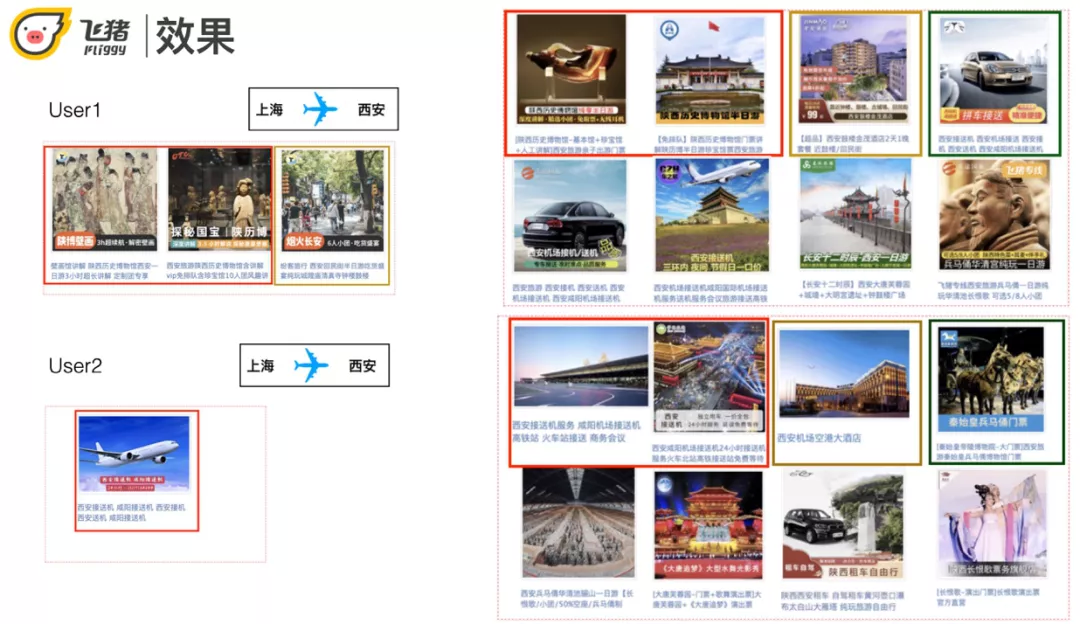
两个同样是上海到西安的用户。用户 1 点击了历史博物馆和小吃,不仅召回了与机票搭配的接送机,还召回了与行为行为相关的小吃街附近的酒店以及历史博物馆相关的宝贝。
用户 2 点击了一个接送机,除了召回接送机还召回了机场附近的酒店和热门的 POI 景点门票。可以看出基于用户的不同行为,召回结果不仅满足搭配关系还与用户行为强相关。
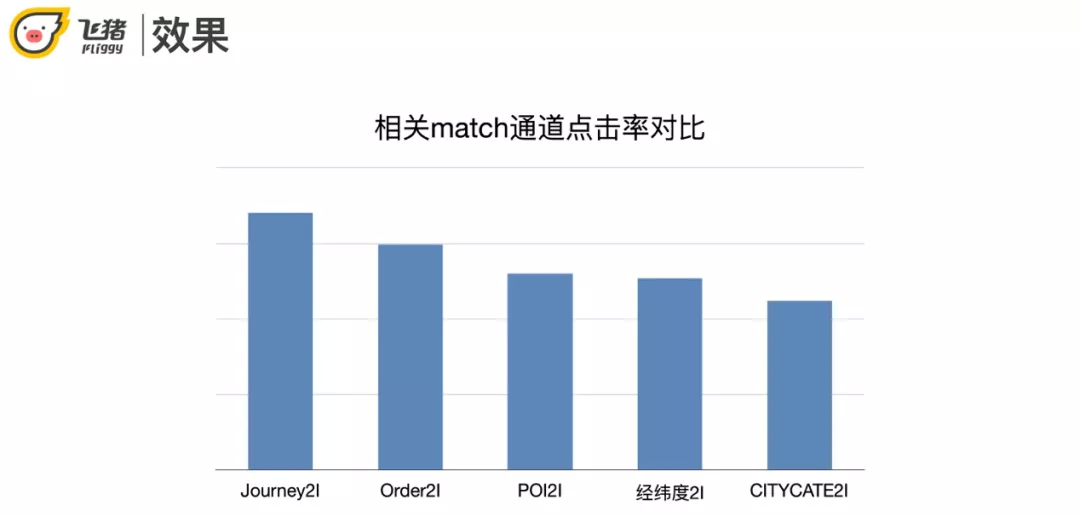
从指标来看 Journey2I 相对 Order2I 有进一步明显的提升。
04 基于用户行为的召回
1. Session-Based I2I
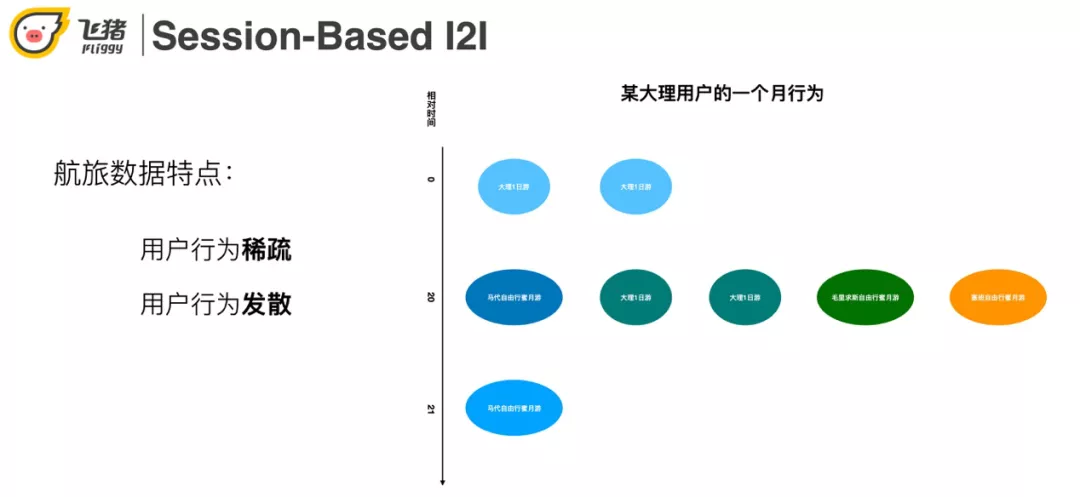
航旅用户的行为有稀疏和发散的特点。利用右图一个具体的用户实例来说明这两个特点:用户在第一天点击了两个大理一日游,第 20 天点击了一些马尔代夫蜜月相关的商品,第 21 天又点击了大理的一日游。稀疏性体现在一个月只来了 3 次,点击了 8 个宝贝。发散性体现在用户大理一日游和出国蜜月游两个 topic 感兴趣。
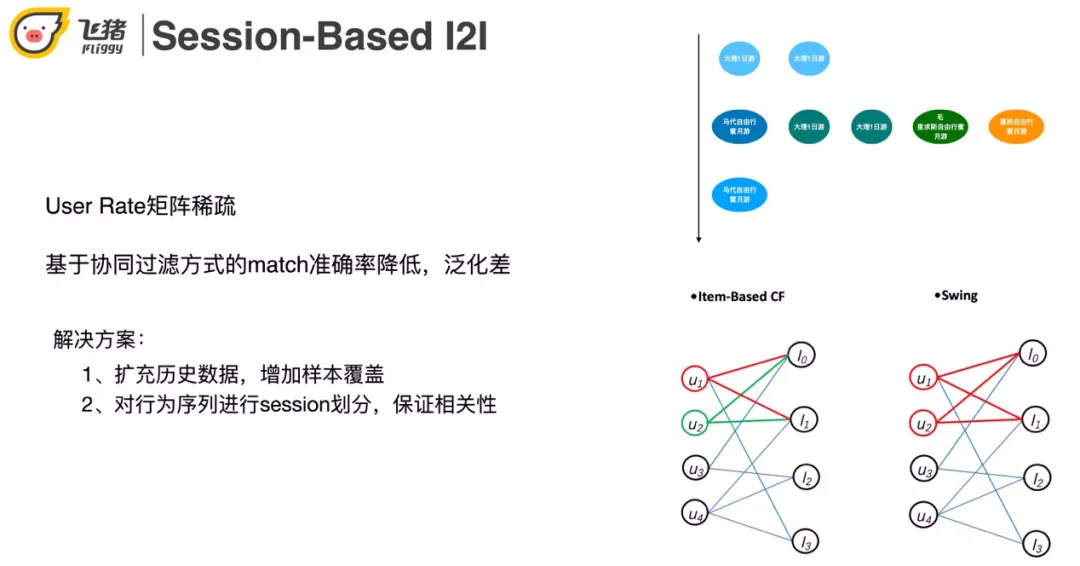
在用户有行为的情况下进行召回,我们常采用的方法是基于 User-Rate 矩阵的协同过滤方法 ( 如 ItemCF,Swing。ItemCF 认为同时点击两个商品的用户越多则这两个商品越相似。Swing 是在阿里多个业务被验证过非常有效的一种召回方式,它认为 user-item-user 的结构比 itemCF 的单边结构更稳定 ),但是由于航旅用户行为稀疏,基于 User-Rate 矩阵召回结果的准确率比较低,泛化性差。针对这两个问题我们可以通过扩充历史数据来增加样本覆盖。航旅场景因为用户点击数据比较稀疏,需要比电商 ( 淘宝 ) 扩充更多 ( 时间更长 ) 的数据才够。这又带来了兴趣点转移多的问题。在这里我们采用对行为序列进行 session 划分,保证相关性。
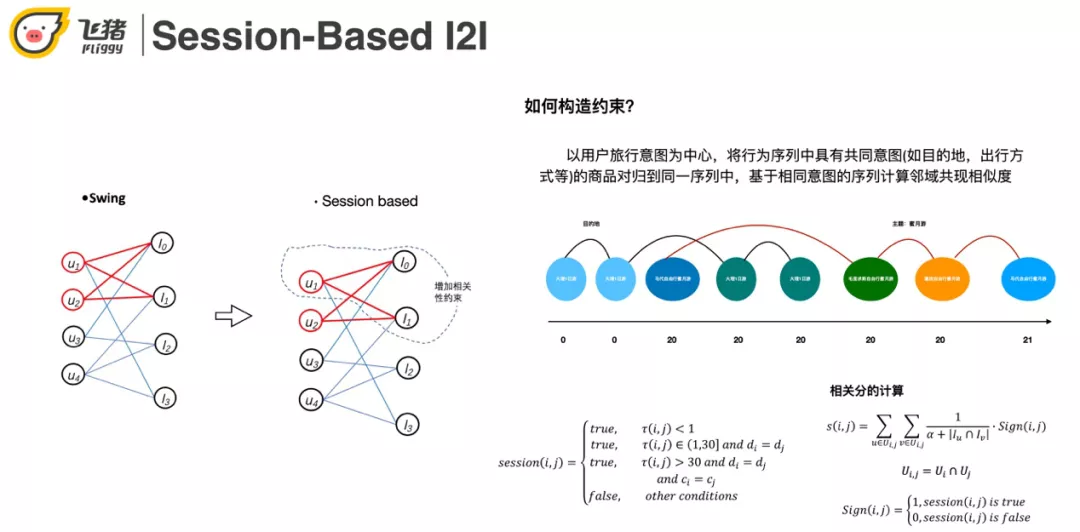
这里以 swing 为例讲解一下构造约束的方式。我们以用户的行为意图为中心,将表示共同意图的商品聚合在一个序列中,如上图对用户行为序列的切分。
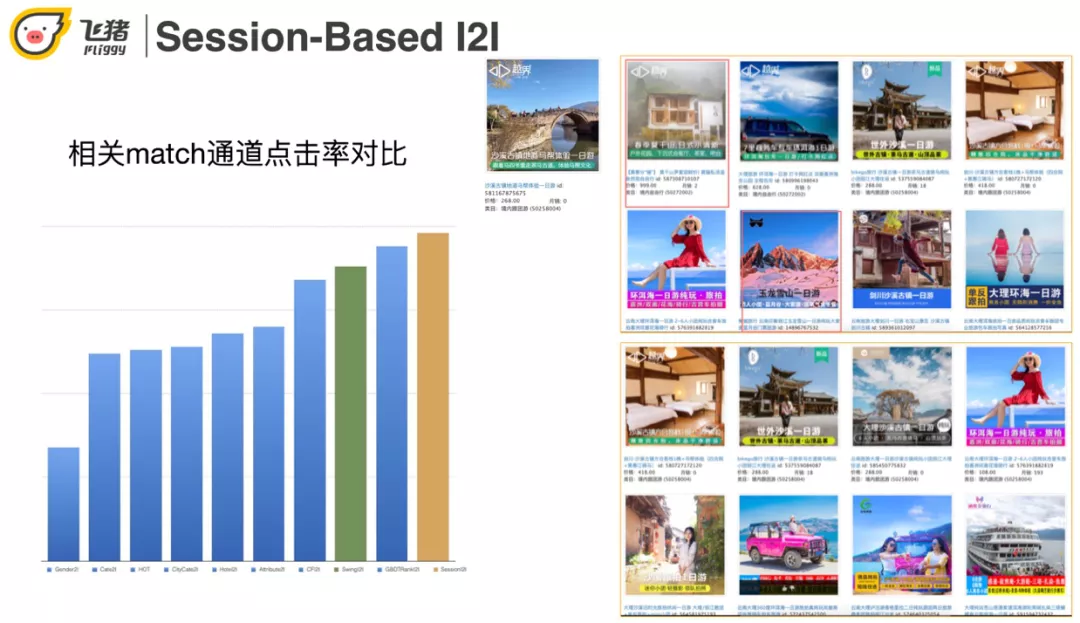
在这个 case 中,上面是传统 swing 的召回结果,下面是基于 session 的召回结果。当 trigger 是沙溪古镇一日游的时候,上面有一个杭州莫干山和玉龙雪山一日游,这两个不相关结果的出现是因为它们是热门商品,也称哈利波特效应。下面的召回结果就都是和沙溪古镇相关的了。从指标来看,session-based 召回比 swing 和 itemCF 都高。
2. Meta-Path Graph Embedding

基于 I2I 相关矩阵的优点是相关性好,缺点是覆盖率比较低。而 Embed 的方式虽然新颖性好但是相关性差。右边的 case 是 Embed 的召回结果,上海迪士尼乐园召回了一个珠海长隆的企鹅酒店和香港迪士尼。我们期望的应该是在上海具有亲子属性,或者在上海迪士尼附近的景点。
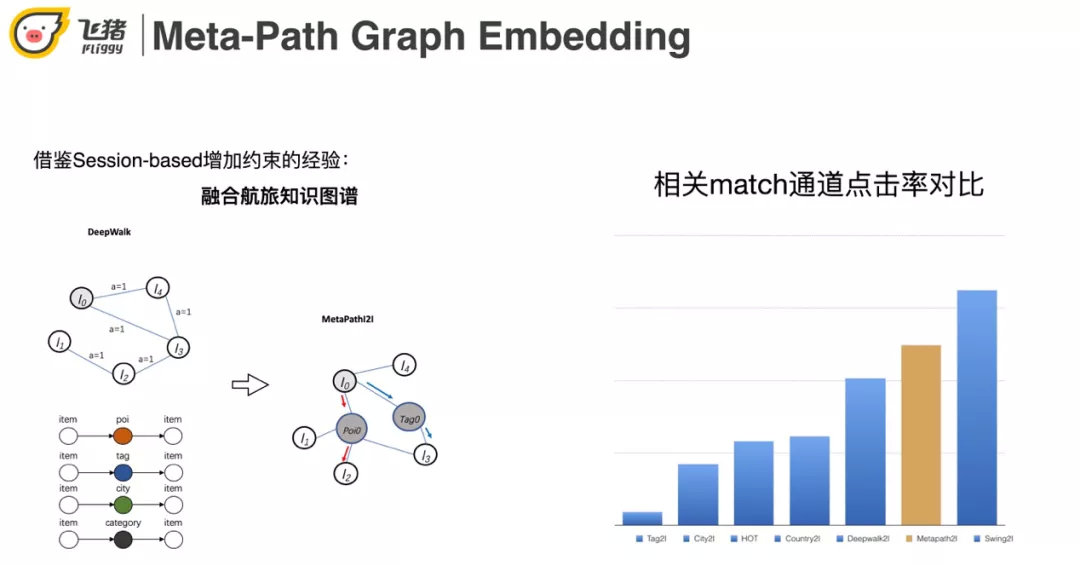
解决 Embed 相关性低的方式借鉴了 session-based 召回的经验,将航旅知识图谱融合,构建航旅特定的 Meta-Path。效果上看 meta-path 的效果是比 deepwalk 更好。
05 周期性复购的召回
复购场景的需求来自于:飞猪有大量的差旅和回家用户,该部分用户的行为有固定模式,会在特定的时间进行酒店和交通的购买,那么该如何满足这部分用户的需求?
1. Rebuy2I

我们的目标是在正确的时间点来给用户推出合适的复购商品,下面以酒店为例具体讲解 ( 其他的品类原理类似 )。

输入用户在飞猪的酒店历史购买数据,输出是用户在某个时间点对某个酒店的复购概率。当有多个可复购酒店时,按照概率降序排序。

常见做法有以下几种:
利用酒店本身的复购概率
基于用户购买历史的 Retarget
利用 Poission-Gamma 分布的统计建模

首先取用户对酒店的购买历史,利用矩估计/参数估计计算酒店的购买频次 ( 参数α和β )。接下来就可以调整每个用户的购买概率,k 是购买次数,t 是第一次购买距离最近一次购买的时间间隔。最后代入 Possion 分布计算复购概率,加入用户的平均购买周期来缓解刚刚完成购买的酒店复购概率最大的问题。
2. 效果
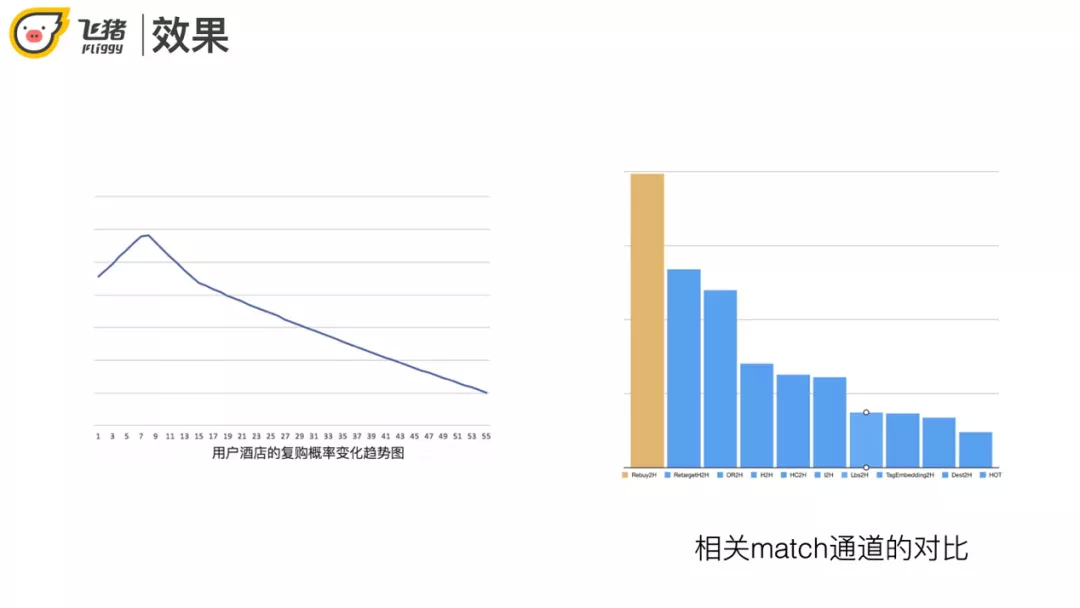
从左图可以看出在购买一段时间以后,复购概率达到最大值,之后递减。实际使用中复购单独作为一路召回,效果比前面提到的 retarget 和热门召回更好。
06 总结

最后总结一下做好召回的几个思路:
首先要基于业务场景,来发掘用户需求,发现自有场景的特点。接下来通过 case 和数据分析来发现问题,通过理解模型结构或者特征背后的动机进行针对性的改进。最后在召回和排序之间找到边界,效果和性能之间做好 trade-off。
今天的分享就到这里,谢谢大家。
07 问答环节
Q:Journey2i 的双塔模型如何负采样,正负比例如何控制?
A:关于召回的负采样是一个非常值得研究的问题。我们也做了很多尝试,例如我们曾经尝试过按照排序的套路用曝光样本做负样本,但是效果很差。然后也进行了全局负采样,效果要明显好于曝光的方式,但是负样本如何采也值得一提,采得太随机,你的负样本容易太 easy,模型的 auc 可能虚高,因此也要新增一些 hard 的样本,在 journey2i 中就是那些属于本次行程相关城市目的地的商品,但是用户不太可能购买的商品,具体的方式这里不展开介绍了。Facebook 在 KDD2020 中有篇论文也对召回的采样问题做了详细的介绍,推荐阅读。关于正负比例,我们的经验是没有绝对的答案,需要在优化过程中摸索,不过一般只要抽样方式 ok,正负比例的变化不会对最终结果有太大的影响。
Q:Journey2I 无法考虑交互特征,是否会有影响?
A:肯定会有影响。理论上讲,没有 Journey 和 target item 的交互特征,auc 和准确率肯定会打折扣,但是需要针对具体问题具体分析,做召回的优化和排序有个很明显的不同就是需要在性能、准确率、多样性上做 trade-off。
Q:meta-path,session-base 解决问题和出发点是什么?
A:session-base 解决的是扩充稀疏的数据后会带来兴趣发散的问题。举个极端的例子,有个用户每个月都出差,去到不同的地点。召回结果就会混合多个地点。Meta-path 解决的是相关性低的问题。
作者介绍:
斯辰,阿里飞猪算法专家
斯辰,阿里飞猪算法专家。本科毕业于华中科技大学,硕士毕业于浙江大学。毕业后先后在百度大搜和阿里巴巴飞猪事业部从事搜索推荐相关的算法研发工作。对于推荐系统有比较丰富的实战经验。
楼溪,阿里飞猪高级算法工程师
楼溪,阿里飞猪高级算法工程师。硕士毕业于电子科技大学,2018 年加入阿里巴巴飞猪个性化小组,主要参与飞猪交易链路的个性化推荐相关工作。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...












评论 1 条评论